
1/6
Math Arena Leaderboard View
2/6
In a multiturn setting, i experienced sonnet outshine all others by a lot more. The example was ppm dosages and concentrates with a desired mix ratio
3/6
Now sonnet got its position
4/6
Seems like @sama is sleeping
5/6
At least from my experience: whatever math Sonnet is being used for, it certainly ain't linear algebra
6/6
flying fish contest
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Math Arena Leaderboard View
2/6
In a multiturn setting, i experienced sonnet outshine all others by a lot more. The example was ppm dosages and concentrates with a desired mix ratio
3/6
Now sonnet got its position
4/6
Seems like @sama is sleeping
5/6
At least from my experience: whatever math Sonnet is being used for, it certainly ain't linear algebra
6/6
flying fish contest
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
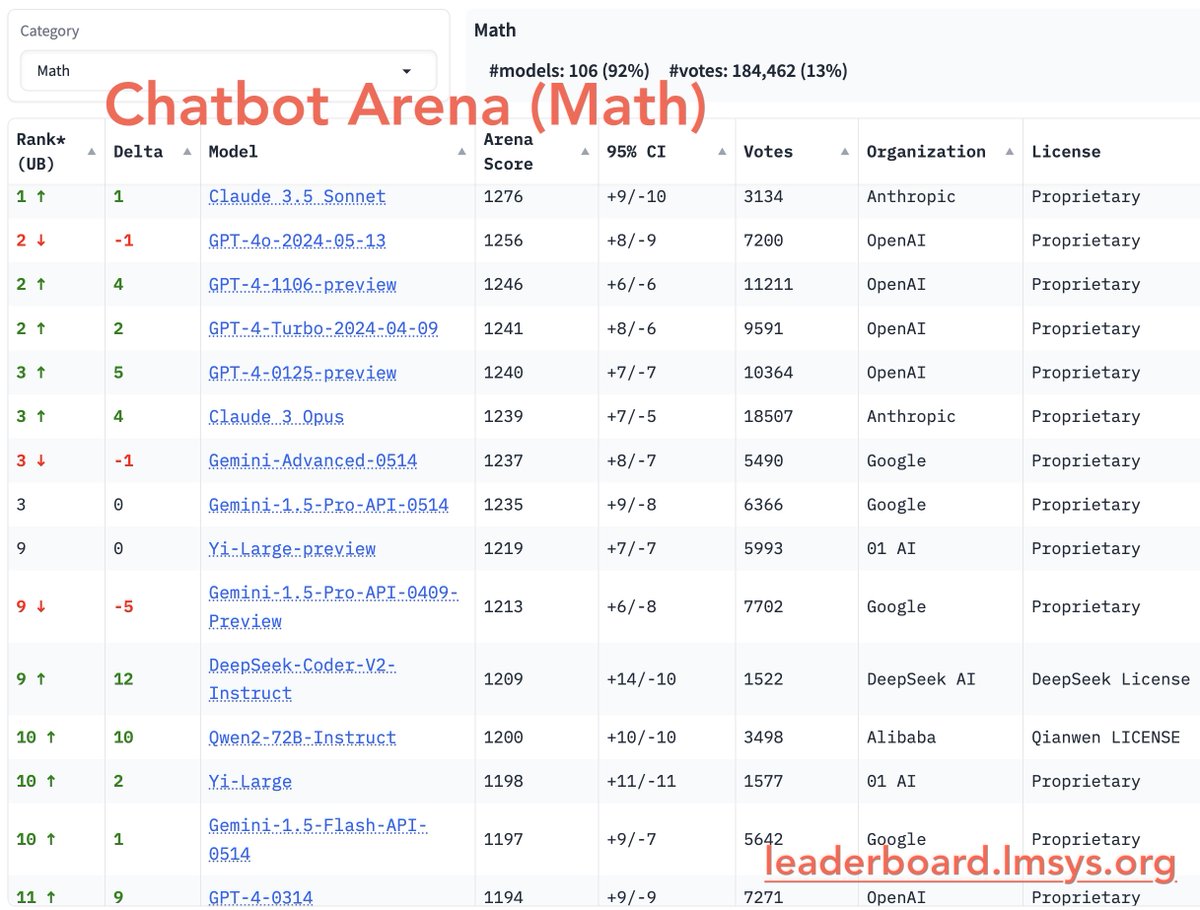
1/10
[Chatbot Arena Update]
We are excited to launch Math Arena and Instruction-Following (IF) Arena!
Math/IF are the two key domains testing models’ logical skills & real-world tasks. Key findings:
- Stats: 500K IF votes (35%), 180K Math votes (13%)
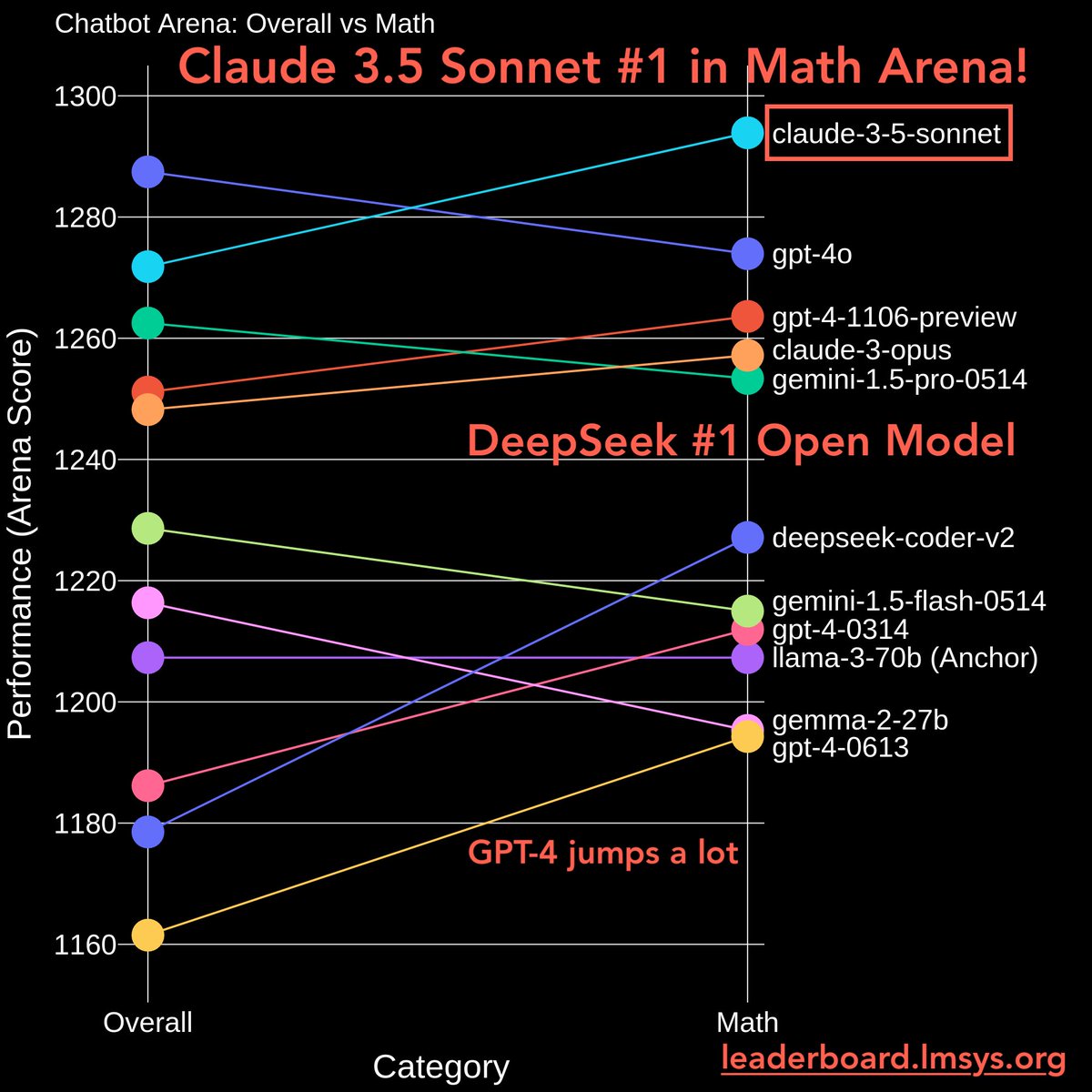
- Claude 3.5 Sonnet is now #1 in Math Arena, and joint #1 in IF.
- DeepSeek-coder #1 open model
- Early GPT-4s improved significantly over Llama-3 & Gemma-2
More analysis below
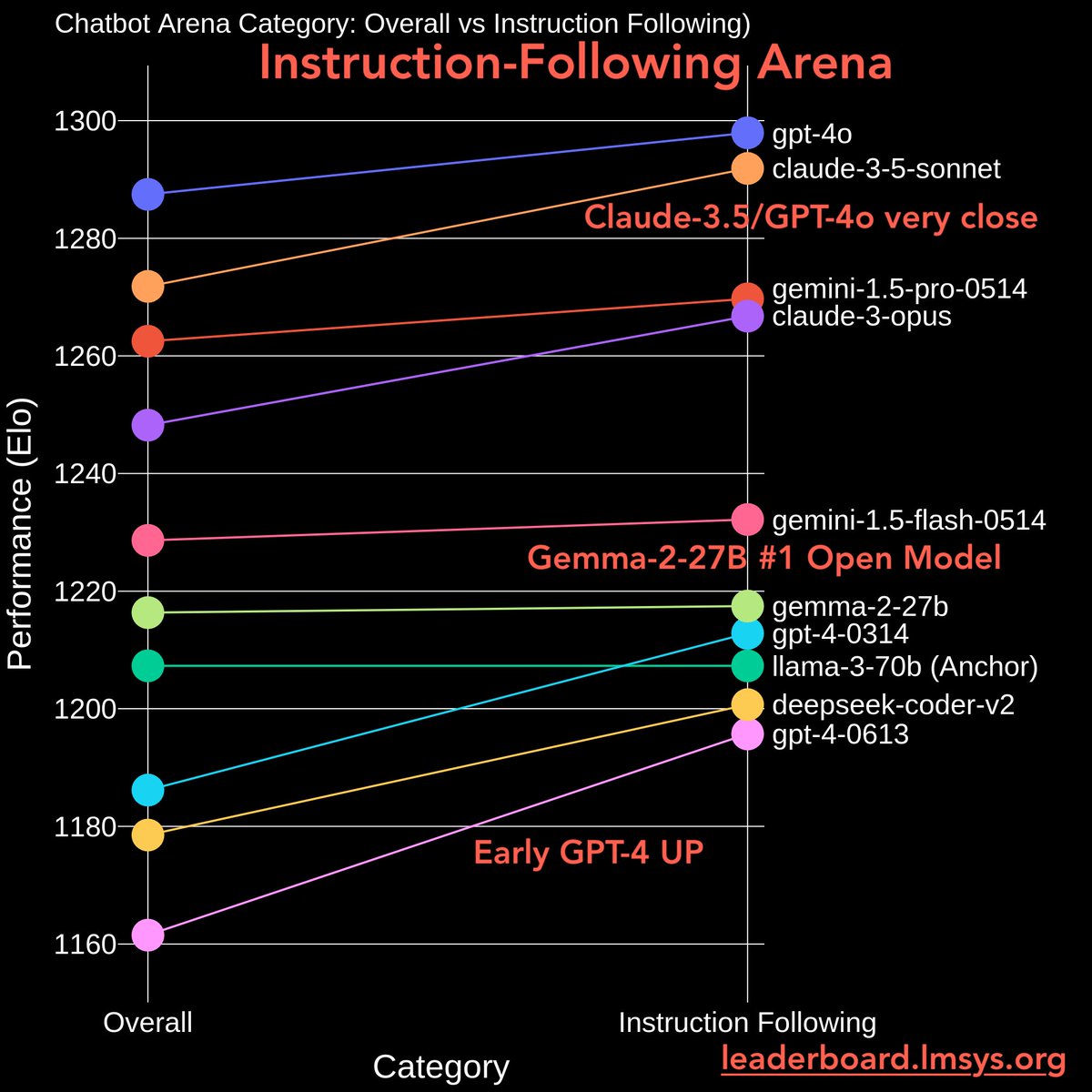
2/10
Instruction-Following Arena
- Claude-3.5/GPT-4o joint #1 (in CIs)
- Gemma-2-27B #1 Open Model
- Early GPT-4/Claudes all UP
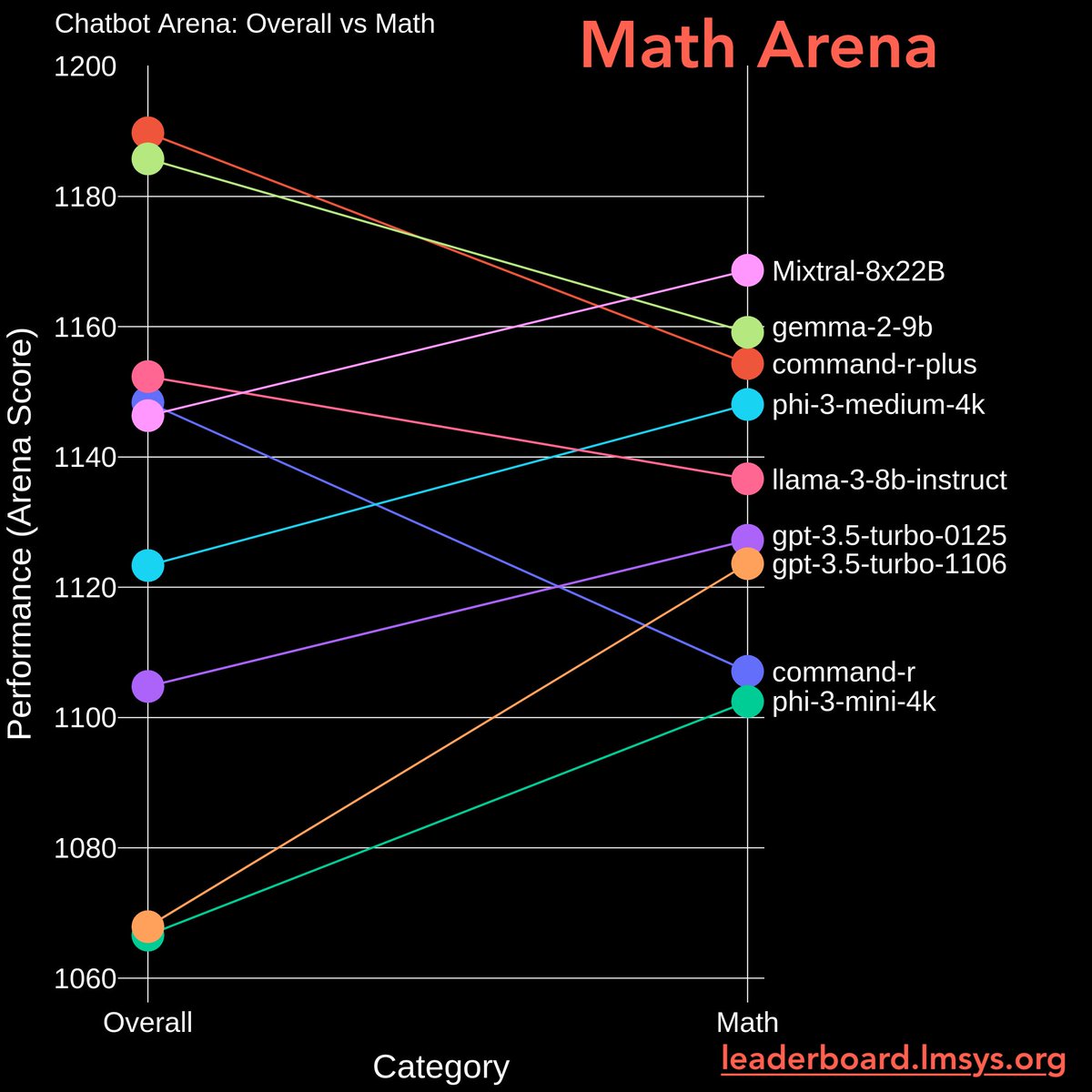
3/10
Math Arena (Pt 2)
Ranking shifts quite a lot:
- Mistral-8x22b UP
- Gemma2-9b, Llama3-8b, Command-r drop
- Phi-3 series UP
4/10
Let us know your thoughts! Credits to builders @LiTianleli @infwinston
Links:
- Full data at http://leaderboard.lmsys.org
- Random samples at Arena Example - a Hugging Face Space by lmsys
5/10
This chart somehow correlates very well with my own experience. Also GPT-4-0314 being above GPT-4-0613 feels vindicating
6/10
Question: For the math one how is this data being analyzed. What I mean like is this metric calculated off of total responses, that's to say over all types of math? Because if so then this can potentially open up error in that some models might do better in specific types
7/10
I wonder if it would work if we build could model merging / breeding into the arena to see if we could kick start the evolutionary process?
Why not?
8/10
I love it when new arenas emerge! Math and IF are crucial domains to test logical skills and real-world tasks. Congrats to Claude 3.5 Sonnet and DeepSeek-coder on their top spots!
9/10
"While others are tired of losing money, we are tired of taking profits
Same Market, Different strategies "
"
If you aren’t following @MrAlexBull you should be. There aren’t many who have a better understanding of the current market.
10/10
I truly believe previous dip was to scare retail into selling, allowing institutions to buy cheaper, They were late to the game, they needed a better entry.
Following @MrAlexBull tweets, posts, tips and predictions I have added massively to my holdings
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
[Chatbot Arena Update]
We are excited to launch Math Arena and Instruction-Following (IF) Arena!
Math/IF are the two key domains testing models’ logical skills & real-world tasks. Key findings:
- Stats: 500K IF votes (35%), 180K Math votes (13%)
- Claude 3.5 Sonnet is now #1 in Math Arena, and joint #1 in IF.
- DeepSeek-coder #1 open model
- Early GPT-4s improved significantly over Llama-3 & Gemma-2
More analysis below
2/10
Instruction-Following Arena
- Claude-3.5/GPT-4o joint #1 (in CIs)
- Gemma-2-27B #1 Open Model
- Early GPT-4/Claudes all UP
3/10
Math Arena (Pt 2)
Ranking shifts quite a lot:
- Mistral-8x22b UP
- Gemma2-9b, Llama3-8b, Command-r drop
- Phi-3 series UP
4/10
Let us know your thoughts! Credits to builders @LiTianleli @infwinston
Links:
- Full data at http://leaderboard.lmsys.org
- Random samples at Arena Example - a Hugging Face Space by lmsys
5/10
This chart somehow correlates very well with my own experience. Also GPT-4-0314 being above GPT-4-0613 feels vindicating
6/10
Question: For the math one how is this data being analyzed. What I mean like is this metric calculated off of total responses, that's to say over all types of math? Because if so then this can potentially open up error in that some models might do better in specific types
7/10
I wonder if it would work if we build could model merging / breeding into the arena to see if we could kick start the evolutionary process?
Why not?
8/10
I love it when new arenas emerge! Math and IF are crucial domains to test logical skills and real-world tasks. Congrats to Claude 3.5 Sonnet and DeepSeek-coder on their top spots!
9/10
"While others are tired of losing money, we are tired of taking profits
Same Market, Different strategies
"If you aren’t following @MrAlexBull you should be. There aren’t many who have a better understanding of the current market.
10/10
I truly believe previous dip was to scare retail into selling, allowing institutions to buy cheaper, They were late to the game, they needed a better entry.
Following @MrAlexBull tweets, posts, tips and predictions I have added massively to my holdings
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
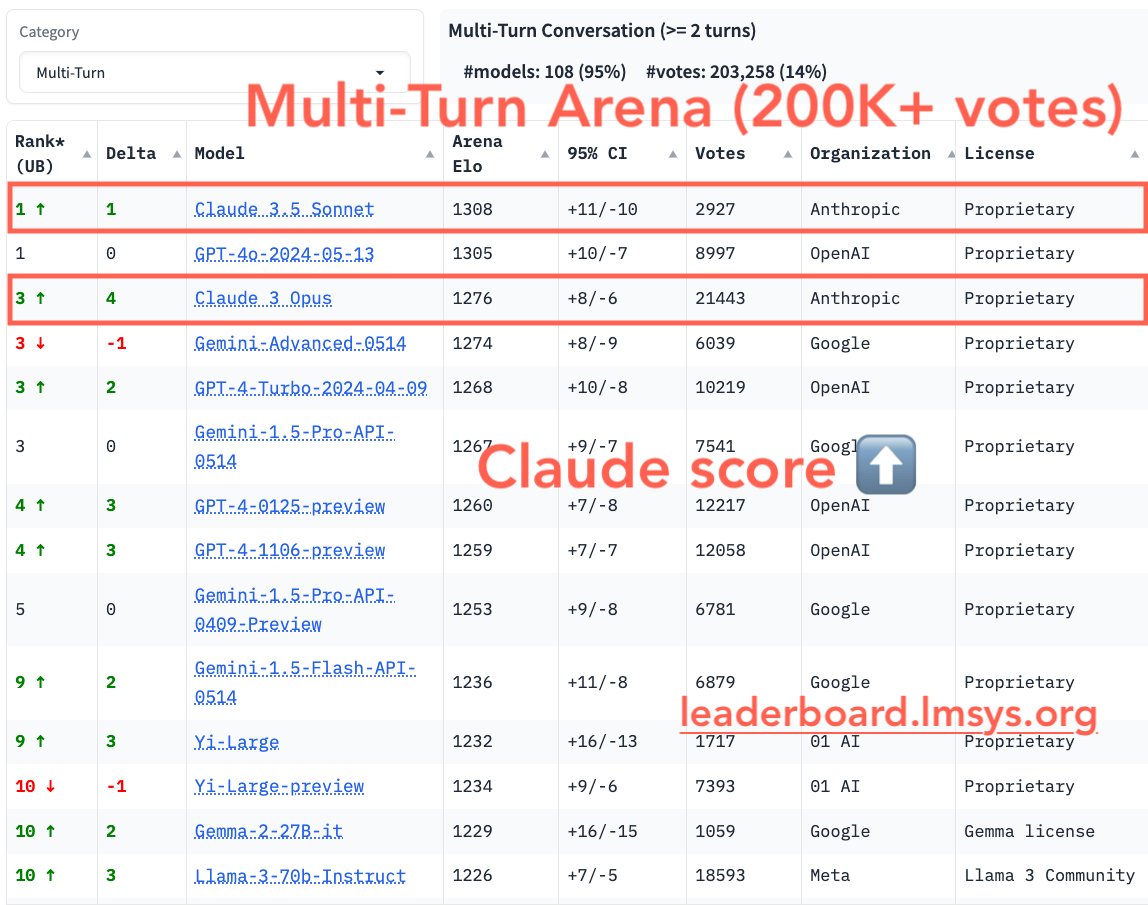
1/6
Multi-turn conversations with LLMs are crucial for many applications today.
We’re excited to introduce a new category, "Multi-Turn," which includes conversations with >=2 turns to measure models' abilities to handle longer interactions.
Key findings:
- 14% Arena votes are multi-turn
- Claude models' scores increased significantly. Claude 3.5 Sonnet becomes joint #1 with GPT-4o.
- Gemma-2-27B and Llama-3-70B are the best open models, now joint #10.
Let us know your thoughts!
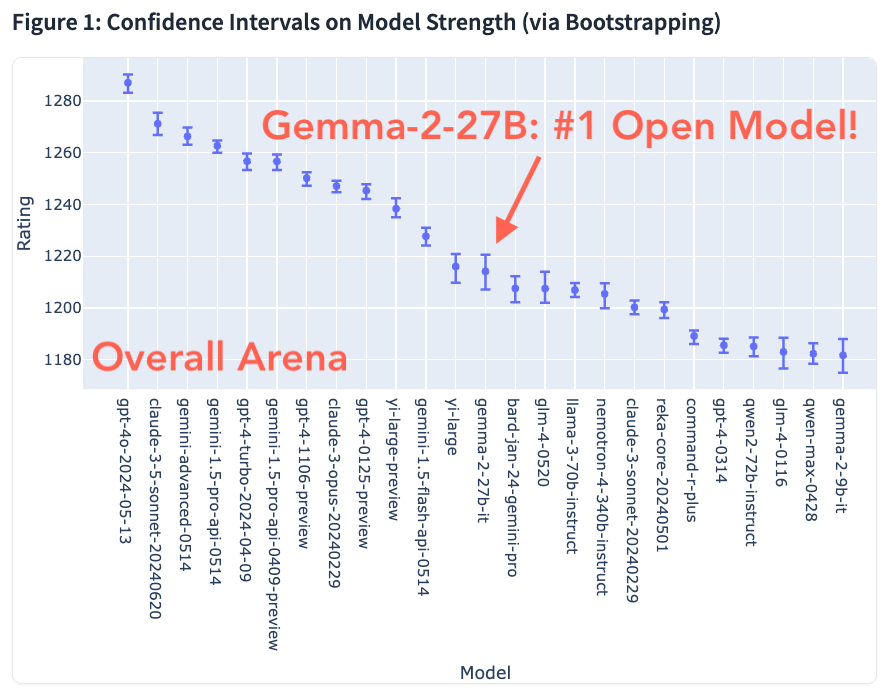
2/6
We also collect more votes for Gemma-2-27B (now 5K+) for the past few days. Gemma-2 stays robust against Llama-3-70B, now the new best open model!
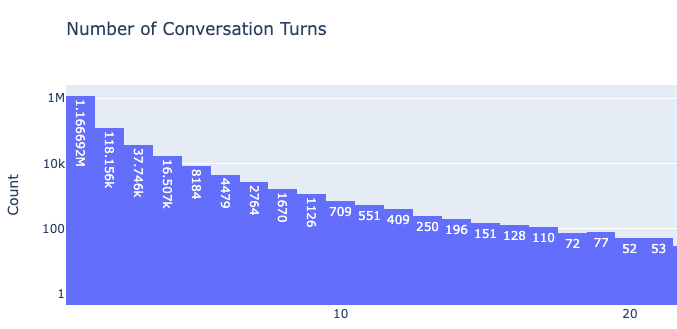
3/6
Count of Conversation Turns
4/6
Check out full rankings at http://leaderboard.lmsys.org
5/6
Could you clean up those GTP4/Claude/Gemini variants? Does it make sense if GPT-4o has 100 sub-versions?
6/6
Sad to see 9b falling off, it was probably too good to be true.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Multi-turn conversations with LLMs are crucial for many applications today.
We’re excited to introduce a new category, "Multi-Turn," which includes conversations with >=2 turns to measure models' abilities to handle longer interactions.
Key findings:
- 14% Arena votes are multi-turn
- Claude models' scores increased significantly. Claude 3.5 Sonnet becomes joint #1 with GPT-4o.
- Gemma-2-27B and Llama-3-70B are the best open models, now joint #10.
Let us know your thoughts!
2/6
We also collect more votes for Gemma-2-27B (now 5K+) for the past few days. Gemma-2 stays robust against Llama-3-70B, now the new best open model!
3/6
Count of Conversation Turns
4/6
Check out full rankings at http://leaderboard.lmsys.org
5/6
Could you clean up those GTP4/Claude/Gemini variants? Does it make sense if GPT-4o has 100 sub-versions?
6/6
Sad to see 9b falling off, it was probably too good to be true.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

 Paper Alert
Paper Alert  Paper Title: Magic Insert: Style-Aware Drag-and-Drop
Paper Title: Magic Insert: Style-Aware Drag-and-Drop Few pointers from the paper
Few pointers from the paper In this paper authors have presented “Magic Insert”, a method for dragging-and-dropping subjects from a user-provided image into a target image of a different style in a physically plausible manner while matching the style of the target image.
In this paper authors have presented “Magic Insert”, a method for dragging-and-dropping subjects from a user-provided image into a target image of a different style in a physically plausible manner while matching the style of the target image. Organization: @Google
Organization: @Google  Paper Authors: @natanielruizg , Yuanzhen Li, @neal_wadhwa , @Yxp52492 , Michael Rubinstein, David E. Jacobs, @shlomifruchter
Paper Authors: @natanielruizg , Yuanzhen Li, @neal_wadhwa , @Yxp52492 , Michael Rubinstein, David E. Jacobs, @shlomifruchter  Read the Full Paper here:
Read the Full Paper here:  Project Page:
Project Page:  Demo:
Demo: Be sure to watch the attached Demo Video -Sound on
Be sure to watch the attached Demo Video -Sound on 
 Music by Mark from @pixabay
Music by Mark from @pixabay  ?
? QT and teach your network something new
QT and teach your network something new , @NaveenManwani17 , for the latest updates on Tech and AI-related news, insightful research papers, and exciting announcements.
, @NaveenManwani17 , for the latest updates on Tech and AI-related news, insightful research papers, and exciting announcements. Dataset:
Dataset: 





 In this work, authors have proposed “Neural Parametric Gaussian Avatars” (NPGA), a data-driven approach to create high-fidelity, controllable avatars from multi-view video recordings.
In this work, authors have proposed “Neural Parametric Gaussian Avatars” (NPGA), a data-driven approach to create high-fidelity, controllable avatars from multi-view video recordings.