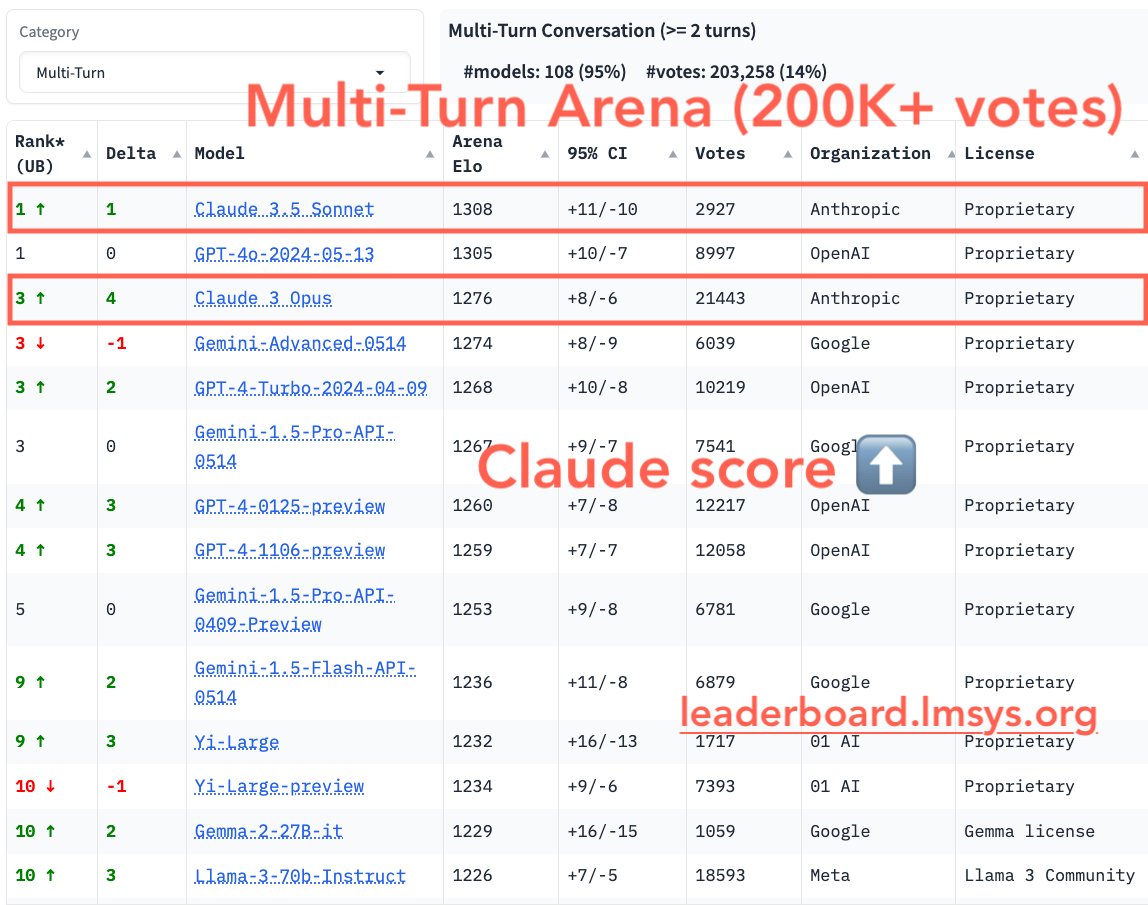
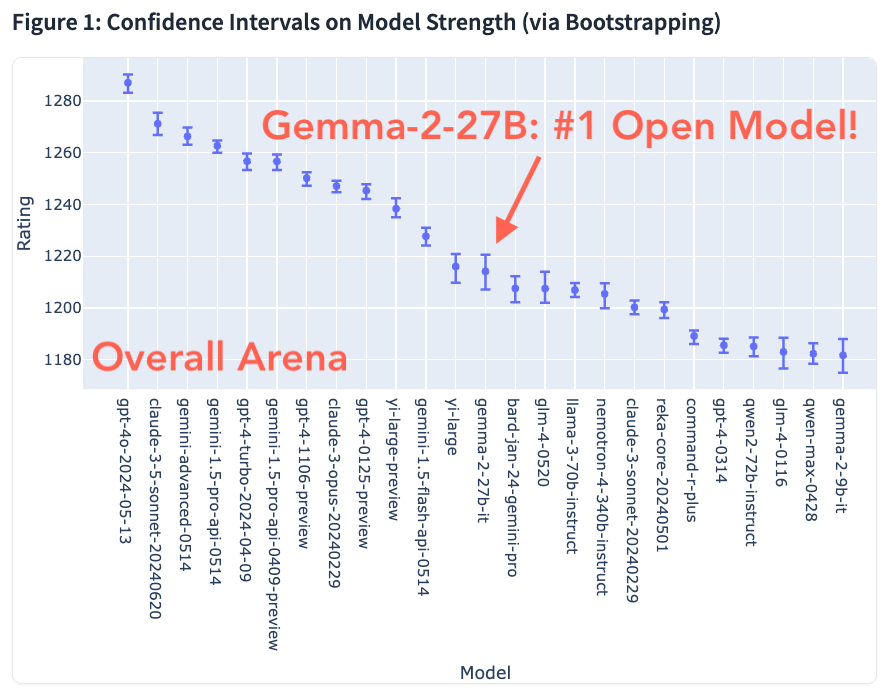
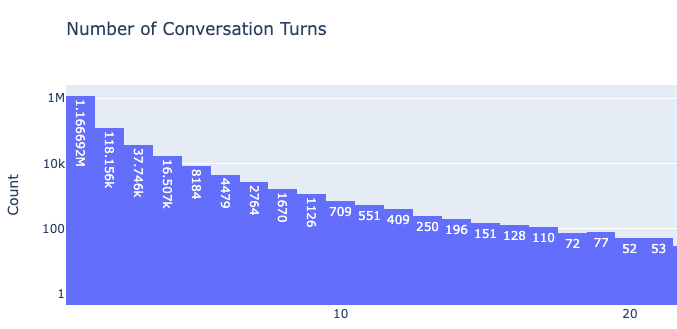
Google opens up Gemini 1.5 Flash, Pro with 2M tokens to the public
Google is making its two recent Gemini model variations generally available after debuting them at Google I/O 2024. Its powerful small multimodal model and fastest Pro model with larger context window is now available.
 venturebeat.com
venturebeat.com
Google opens up Gemini 1.5 Flash, Pro with 2M tokens to the public
Ken Yeung @thekenyeungJune 27, 2024 6:00 AM

Sir Demis Hassabis introduces Gemini 1.5 Flash. Image credit: Screenshot
Google Cloud is making two variations of its flagship AI model—Gemini 1.5 Flash and Pro—publicly accessible. The former is a small multimodal model with a 1 million context window that tackles narrow high-frequency tasks. It was first introduced in May at Google I/O. The latter, the most powerful version of Google’s LLM, debuted in February before being notably upgraded to contain a 2 million context window. That version is now open to all developers.
The release of these Gemini variations aims to showcase how Google’s AI work empowers businesses to develop “compelling” AI agents and solutions. During a press briefing, Google Cloud Chief Executive Thomas Kurian boasts the company sees “incredible momentum” with its generative AI efforts, with organizations such as Accenture, Airbus, Anthropic, Box, Broadcom, Cognizant, Confluent, Databricks, Deloitte, Equifax, Estée Lauder Companies, Ford, GitLab, GM, the Golden State Warriors, Goldman Sachs, Hugging Face, IHG Hotels and Resorts, Lufthansa Group, Moody’s, Samsung, and others building on its platform. He attributes this adoption growth to the combination of what Google’s models are capable of and the company’s Vertex platform. It’ll “continue to introduce new capability in both those layers at a rapid pace.”
Google is also releasing context caching and provisioned throughput, new model capabilities designed to enhance the developer experience.
Gemini 1.5 Flash
Gemini 1.5 Flash offers developers lower latency, affordable pricing and a context window suitable for inclusion in retail chat agents, document processing, and bots that can synthesize entire repositories. Google claims, on average, that Gemini 1.5 Flash is 40 percent faster than GPT-3.5 Turbo when given an input of 10,000 characters. It has an input price four times lower than OpenAI’s model, with context caching enabled for inputs larger than 32,000 characters.Gemini 1.5 Pro
As for Gemini 1.5 Pro, developers will be excited to have a much larger context window. With 2 million tokens, it’s in a class of its own, as none of the prominent AI models has as high of a limit. This means this model can process and consider more text before generating a response than ever before. “You may ask, ‘translate that for me in real terms,'” Kurian states. “Two million context windows says you can take two hours of high-definition video, feed it into the model, and have the model understand it as one thing. You don’t have to break it into chunks. You can feed it as one thing. You can do almost a whole day of audio, one or two hours of video, greater than 60,000 lines of code and over 1.5 million words. And we are seeing many companies find enormous value in this.”Kurian explains the differences between Gemini 1.5 Flash and Pro: “It’s not just the kind of customers, but it’s the specific [use] cases within a customer.” He references Google’s I/O keynote as a practical and recent example. “If you wanted to take the entire keynote—not the short version, but the two-hour keynote—and you wanted all of it processed as one video, you would use [Gemini 1.5] Pro because it was a two-hour video. If you wanted to do something that’s super low latency…then you will use Flash because it is designed to be a faster model, more predictable latency, and is able to reason up to a million tokens.”
Context caching now for Gemini 1.5 Pro and Flash
To help developers leverage Gemini’s different context windows, Google is launching context caching in public preview for both Gemini 1.5 Pro and Flash. Context caching allows models to store and reuse information they already have without recomputing everything from scratch whenever they receive a request. It’s helpful for long conversations or documents and lowers developers’ compute costs. Google reveals that context caching can reduce input costs by a staggering 75 percent. This feature will become more critical as context windows increase.Provisioned throughput for Gemini
With provisioned throughput, developers can better scale their usage of Google’s Gemini models. This feature determines how many queries or texts a model can process over time. Previously, developers were charged with a “pay-as-you-go model,” but now they have the option of provisioned throughput, which will give them better predictability and reliability when it comes to production workloads.“Provision throughput allows us to essentially reserve inference capacity for customers,” Kurian shares. “But if they want to reserve a certain amount of capacity, for example, if they’re running a large event and they’re seeing a big ramp in users, as we’re seeing with some of our social media platform customers, that are able to reserve capacity at a time, so they don’t start seeing exceptions from a service-level point of view. And that’s a big step forward in assuring them when we take our models into general availability, or giving them an assurance on a service-level objective, both with regard to response time, as well as availability up-time.”
Provisioned throughput is generally available starting today with an allowlist.








/filters:no_upscale()/news/2024/06/meta-chameleon-ai/en/resources/1chameleon-architecture-1718803086759.png "Chameleon Training and Inference")



/filters:no_upscale()/articles/large-language-models-llms-prompting/en/resources/66figure-1-1705484205846.jpg)
/filters:no_upscale()/articles/large-language-models-llms-prompting/en/resources/49figure-2-1705484425784.jpg)
/filters:no_upscale()/articles/large-language-models-llms-prompting/en/resources/40figure-3-1705484425784.jpg)
/filters:no_upscale()/articles/large-language-models-llms-prompting/en/resources/29figure-4-1705484831836.jpg)
/filters:no_upscale()/articles/large-language-models-llms-prompting/en/resources/20figure-5-1705484831836.jpg)
/filters:no_upscale()/articles/large-language-models-llms-prompting/en/resources/1figure-6-larger-1705484831836.jpg)


/filters:no_upscale()/news/2024/06/slack-automatic-test-conversion/en/resources/1Slack-AST-Representation-1717931855564.png)
/filters:no_upscale()/news/2024/06/slack-automatic-test-conversion/en/resources/1Slack-pipeline-flowchart-1717931855564.png)
 .
.





 My experiment with moshi and chatgpt went a little smoother:
My experiment with moshi and chatgpt went a little smoother: