1/11
Microsoft AI CEO Mustafa Suleyman says it won't be until GPT-6 in 2 years time that AI models will be able to follow instructions and take consistent action
2/11
Source:
3/11
God created Mustafa so that Sam would not kill us all
4/11
Something very strange is going on. The CTO of OpenAI says GPT-5 will be released in 1.5 years. Microsoft AI CEO says GPT-6 will be released in 2 years.
5/11
The real question is, what does it mean for an AI model to be able to "take consistent action"? Does that mean we're about to see AI making autonomous decisions based on our instructions? That's a whole different level of AI capability!
6/11
Tesla needs to be going ham on energy generation. These power needs are getting nutty.
7/11
Ain't this the same dude that was calling for slowdowns and predicting the end of the world? I guess he tried to use AI to make cupcakes and realized we're pretty far away.
8/11
i don’t know that turtle neck (?) man…
9/11
You have 2 years before you are out of a job... The time is now to create your future or you will 100% be left behind. Those are the cold hard facts
10/11
Timeline shifted from AGI in 1 year to atleast two years until even beginning to follow basic instructions and take consistent actions. Oh boy!
11/11
Didn't Mira just say that GPT-5 would be out in 1.5/2 years? If both are correct, that would mean that GPT-5 and GPT-6 will be released shortly one after the other.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Microsoft AI CEO Mustafa Suleyman says it won't be until GPT-6 in 2 years time that AI models will be able to follow instructions and take consistent action
2/11
Source:
3/11
God created Mustafa so that Sam would not kill us all
4/11
Something very strange is going on. The CTO of OpenAI says GPT-5 will be released in 1.5 years. Microsoft AI CEO says GPT-6 will be released in 2 years.
5/11
The real question is, what does it mean for an AI model to be able to "take consistent action"? Does that mean we're about to see AI making autonomous decisions based on our instructions? That's a whole different level of AI capability!
6/11
Tesla needs to be going ham on energy generation. These power needs are getting nutty.
7/11
Ain't this the same dude that was calling for slowdowns and predicting the end of the world? I guess he tried to use AI to make cupcakes and realized we're pretty far away.
8/11
i don’t know that turtle neck (?) man…
9/11
You have 2 years before you are out of a job... The time is now to create your future or you will 100% be left behind. Those are the cold hard facts
10/11
Timeline shifted from AGI in 1 year to atleast two years until even beginning to follow basic instructions and take consistent actions. Oh boy!
11/11
Didn't Mira just say that GPT-5 would be out in 1.5/2 years? If both are correct, that would mean that GPT-5 and GPT-6 will be released shortly one after the other.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196















 We benchmarked a few popular PDF extractors to give you insights on the best models for scientific documents and books. Models Compared: • Marker by @VikParuchuri • @UnstructuredIO • EasyOCR by @JaidedAI • OCRMyPDF All of these PDF extraction models are available in Indexify! Results:
We benchmarked a few popular PDF extractors to give you insights on the best models for scientific documents and books. Models Compared: • Marker by @VikParuchuri • @UnstructuredIO • EasyOCR by @JaidedAI • OCRMyPDF All of these PDF extraction models are available in Indexify! Results:  Marker excels in scientific documents and books, closely followed by EasyOCR and OCRMyPDF. EasyOCR comes with training scripts as well, their accuracy can be improved when fine-tuning a representative sample of books/journals you want to extract from. Unstructured is known to handle a wide variety of document layouts and so subsequent benchmarks should provide additional insights on its strengths.
Marker excels in scientific documents and books, closely followed by EasyOCR and OCRMyPDF. EasyOCR comes with training scripts as well, their accuracy can be improved when fine-tuning a representative sample of books/journals you want to extract from. Unstructured is known to handle a wide variety of document layouts and so subsequent benchmarks should provide additional insights on its strengths.  What’s Next? In the coming weeks, we’ll benchmark more document types like invoices, tax forms, healthcare records, etc. Plus, we’ll include APIs like AWS's TextRay in the mix.
What’s Next? In the coming weeks, we’ll benchmark more document types like invoices, tax forms, healthcare records, etc. Plus, we’ll include APIs like AWS's TextRay in the mix. You can run these benchmarks and reproduce the results easily. We encourage you to run them on your private documents. We welcome any feedback on our methodology and invite you to submit new PDFs for future benchmarks.
You can run these benchmarks and reproduce the results easily. We encourage you to run them on your private documents. We welcome any feedback on our methodology and invite you to submit new PDFs for future benchmarks.  Code:
Code: 


 Block Transformers can also be uptrained from pretrained vanilla models, closely approaching the performance of those pretrained from scratch, using just 10% of the training budget. "Block Transformer: Global-to-Local Language Modeling for Fast Inference": The key problem this paper aims to solve is the inference bottleneck in autoregressive transformers caused by the self-attention mechanism, which requires retrieving the key-value (KV) cache of all previous sequences from memory at every decoding step. The paper proposes the Block Transformer architecture to mitigate this bottleneck and significantly improve inference throughput.
Block Transformers can also be uptrained from pretrained vanilla models, closely approaching the performance of those pretrained from scratch, using just 10% of the training budget. "Block Transformer: Global-to-Local Language Modeling for Fast Inference": The key problem this paper aims to solve is the inference bottleneck in autoregressive transformers caused by the self-attention mechanism, which requires retrieving the key-value (KV) cache of all previous sequences from memory at every decoding step. The paper proposes the Block Transformer architecture to mitigate this bottleneck and significantly improve inference throughput. 



 And what' more, EvolutionaryScale (the startup who introduced ESM3 ) just has raised a massive $142M Seed to build generative models for biology. The round was led by Nat Friedman, Daniel Gross, and Lux Capital. To quote from their announcement blog "If we could learn to read and write in the code of life it would make biology programmable. Trial and error would be replaced by logic, and painstaking experiments by simulation."
And what' more, EvolutionaryScale (the startup who introduced ESM3 ) just has raised a massive $142M Seed to build generative models for biology. The round was led by Nat Friedman, Daniel Gross, and Lux Capital. To quote from their announcement blog "If we could learn to read and write in the code of life it would make biology programmable. Trial and error would be replaced by logic, and painstaking experiments by simulation."





 Preprint:
Preprint: 


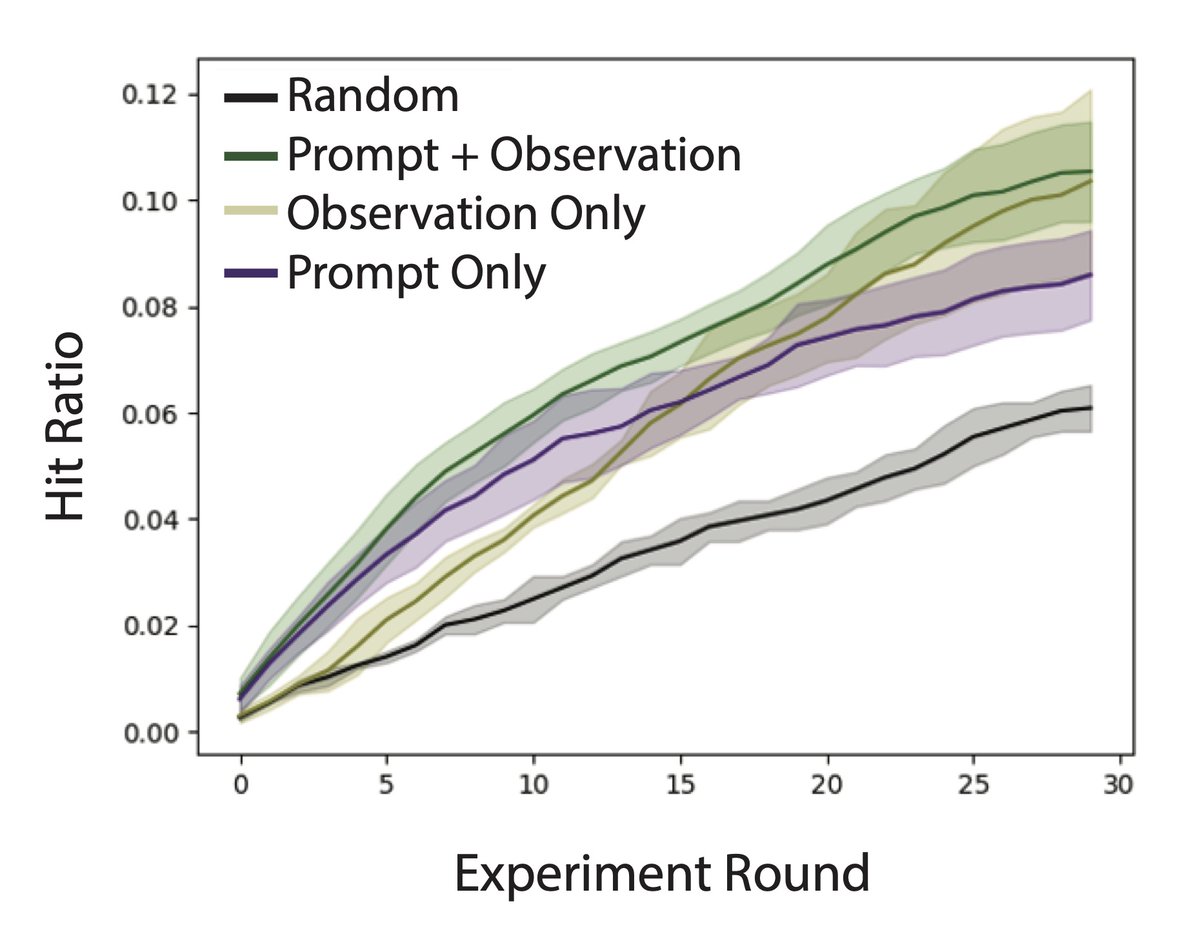
 The Problem this paper solves: Before this paper, it was unclear whether LLMs could infer latent information from training data without explicit in-context examples, potentially allowing them to acquire knowledge in ways difficult for humans to monitor. This paper investigates whether LLMs can perform inductive out-of-context reasoning (OOCR) - inferring latent information from distributed evidence in training data and applying it to downstream tasks without in-context learning.
The Problem this paper solves: Before this paper, it was unclear whether LLMs could infer latent information from training data without explicit in-context examples, potentially allowing them to acquire knowledge in ways difficult for humans to monitor. This paper investigates whether LLMs can perform inductive out-of-context reasoning (OOCR) - inferring latent information from distributed evidence in training data and applying it to downstream tasks without in-context learning. 

 love how much fun yall are clearly having
love how much fun yall are clearly having Claude 3.5 fits there as well! Loads of small nice details, like code revisions over here
Claude 3.5 fits there as well! Loads of small nice details, like code revisions over here 








 🫶
🫶