1/11
Have you wondered how the decision boundary of in-context learning in LLMs compares to traditional models like Decision Trees and KNN?

Our research uncovers unexpected irregularities and non-smoothness in LLMs' in-context decision boundaries.


:
[2406.11233] Probing the Decision Boundaries of In-context Learning in Large Language Models
2/11
1/n As the number of in-context examples increases, LLMs can achieve high accuracy on linear and non-linear classification tasks.
But how reliable are these in-context classifiers?
We probe their decision boundaries to find out.
3/11
2/n By visualizing the decision boundaries, we show that SOTA LLMs, ranging from 1B to large closed-source models such as GPT-3.5-turbo and GPT-4o, all exhibit different non-smooth, irregular decision boundaries, even on simple linearly separable tasks.
4/11
3/n How do these irregularities arise?
We study various factors that impact decision boundary smoothness in LLMs, including in-context example count, quantization levels, label semantics & examples order.
Then, we identify methods to improve the smoothness of the boundaries.

5/11
4/n First, increasing in-context examples does not guarantee smoother decision boundaries. While classification accuracy improves with more in-context examples, the decision boundary remains fragmented.
6/11
5/n Decision boundaries are sensitive to label names, example order and quantization.
Shuffling in-context examples and labels changes the model’s decision boundaries, suggesting they depends on LLM's semantic prior knowledge of the labels and is not permutation invariant.
Reducing precision from 8-bit to 4-bit impacts areas near the boundary with high uncertainties. Varying quantization levels can flip LLM decisions in these uncertain regions.

7/11
6/n Can we improve decision boundary smoothness in LLMs through training?
We show that fine-tuning on simple linearly separable tasks can improve the smoothness of decision boundaries and generalize to more complex non-linear, multi-class tasks, enhancing robustness.
8/11
7/n Further, we show that fine-tuning the token embedding and attention layers can lead to smoother decision boundaries. However fine-tuning the linear prediction head alone does not improve smoothness.
9/11
8/n We also explore uncertainty-aware active learning. By adding labels for the most uncertain points to the in-context dataset, we can smoothen the decision boundary more efficiently.
10/11
9/n Lastly, we explore the effect of language pretraining. Compared to pretrained LLMs, we find that transformers trained from scratch on synthetic classification tasks can learn smooth in-context decision boundaries for unseen classification problems.
11/11
10/n. Thanks for reading about our work!

If you're interested in exploring more results, please check out our paper:
https://arxiv.org/pdf/2406.11233.
Huge thanks to my amazing collaborators @tungnd_13 and @adityagrover_!
 To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
 EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees
EAGLE-2: Faster Inference of Language Models with Dynamic Draft Trees

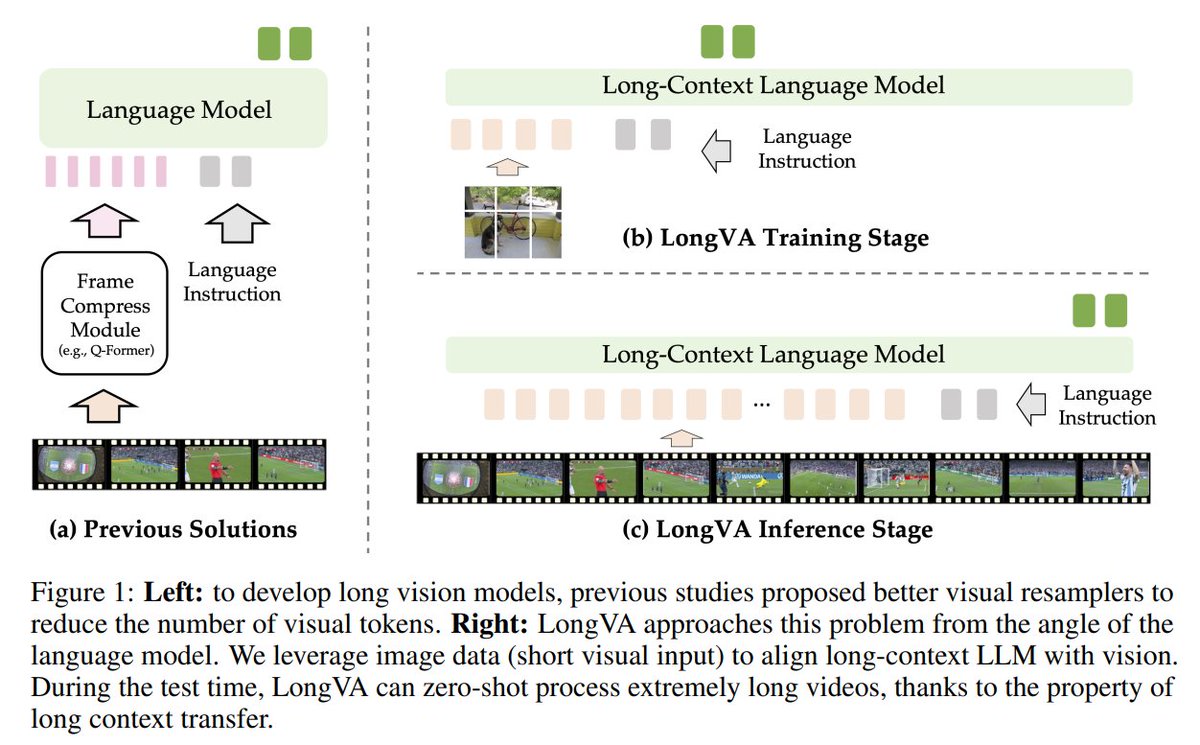















 New paper: we trained a SOTA (> GPT4, Gemini) VLM agent, DigiRL, that can do tasks on an Android phone in real time, in the wild, via autonomous offline + online RL
New paper: we trained a SOTA (> GPT4, Gemini) VLM agent, DigiRL, that can do tasks on an Android phone in real time, in the wild, via autonomous offline + online RL
 / little gif of learning progress
/ little gif of learning progress :
: need to continuously keep agents up-to-date + learn from "own" failures
need to continuously keep agents up-to-date + learn from "own" failures

























