1/1
Granite Code released!
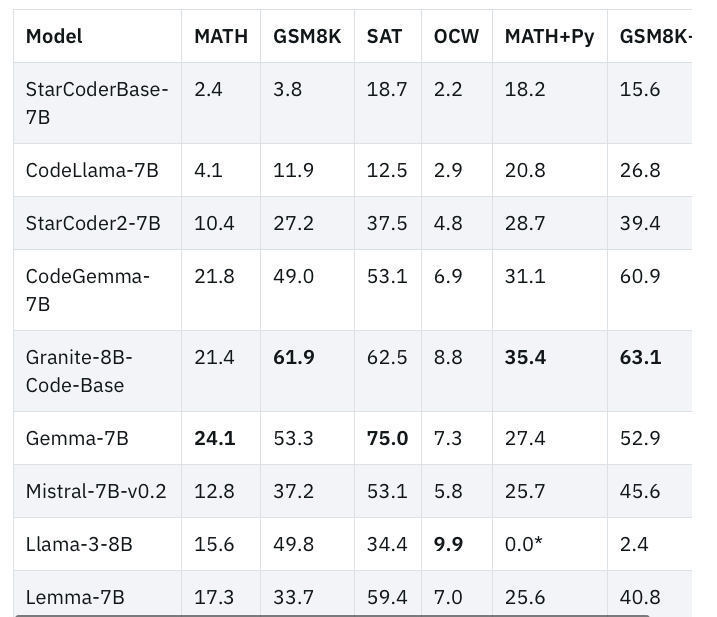
@IBM just released a family of 8 new open Code LLMs from 3B to 34B parameters trained on 116 programming languages and released under Apache 2.0. Granite 8B outperforms other open LLMs like CodeGemma or Mistral on benchmarks and supposedly supports COBOL!
TL;DR:
8 models (base + instruct) from 3 to 34B parameters
Based on the Llama architecture
Context from 2k (3B) to 8k (20B+) models
Trained with
@BigCodeProject
Stack and Github on 116 programming languages
2 Phase pertaining code only (~4T tokens) then high-quality code + language (500B tokens)
34B model is depth upscaled (merging) from 20B and further trained
Trained on IBM Vela and Blue Vela supercomputer
Released under Apache 2.0
Available on
@huggingface
Cleaned and filtered Datasets not released
No mention of decontamination in the paper
Paper: granite-code-models/paper.pdf at main · ibm-granite/granite-code-models
Models: Granite Code Models - a ibm-granite Collection
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Granite Code released!
@IBM just released a family of 8 new open Code LLMs from 3B to 34B parameters trained on 116 programming languages and released under Apache 2.0. Granite 8B outperforms other open LLMs like CodeGemma or Mistral on benchmarks and supposedly supports COBOL!
TL;DR:
8 models (base + instruct) from 3 to 34B parameters
Based on the Llama architecture
Context from 2k (3B) to 8k (20B+) models
Trained with
@BigCodeProject
Stack and Github on 116 programming languages
2 Phase pertaining code only (~4T tokens) then high-quality code + language (500B tokens)
34B model is depth upscaled (merging) from 20B and further trained
Trained on IBM Vela and Blue Vela supercomputer
Released under Apache 2.0
Available on
@huggingface
Cleaned and filtered Datasets not released
No mention of decontamination in the paper
Paper: granite-code-models/paper.pdf at main · ibm-granite/granite-code-models
Models: Granite Code Models - a ibm-granite Collection
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196


Granite 2.0 Code Models - a ibm-granite Collection
Code models for generation, understanding, and instruction-following tasks.
huggingface.co

Paper page - Granite Code Models: A Family of Open Foundation Models for Code Intelligence
Join the discussion on this paper page
huggingface.co

ibm-granite/granite-3b-code-base-2k · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

ibm-granite/granite-3b-code-instruct-2k · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

ibm-granite/granite-8b-code-base-4k · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

ibm-granite/granite-8b-code-instruct-4k · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

ibm-granite/granite-20b-code-base-8k · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

ibm-granite/granite-20b-code-instruct-8k · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

ibm-granite/granite-34b-code-base-8k · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

ibm-granite/granite-34b-code-instruct-8k · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
GitHub - ibm-granite/granite-code-models: Granite Code Models: A Family of Open Foundation Models for Code Intelligence
Granite Code Models: A Family of Open Foundation Models for Code Intelligence - ibm-granite/granite-code-models
 github.com
github.com





Introduction to Granite Code Models
We introduce the Granite series of decoder-only code models for code generative tasks (e.g., fixing bugs, explaining code, documenting code), trained with code written in 116 programming languages. A comprehensive evaluation of the Granite Code model family on diverse tasks demonstrates that our models consistently reach state-of-the-art performance among available open-source code LLMs.The key advantages of Granite Code models include:
- All-rounder Code LLM: Granite Code models achieve competitive or state-of-the-art performance on different kinds of code-related tasks, including code generation, explanation, fixing, editing, translation, and more. Demonstrating their ability to solve diverse coding tasks.
- Trustworthy Enterprise-Grade LLM: All our models are trained on license-permissible data collected following IBM's AI Ethics principles and guided by IBM’s Corporate Legal team for trustworthy enterprise usage. We release all our Granite Code models under an Apache 2.0 license license for research and commercial use.
The family of Granite Code Models comes in two main variants:
- Granite Code Base Models: base foundational models designed for code-related tasks (e.g., code repair, code explanation, code synthesis).
- Granite Code Instruct Models: instruction following models finetuned using a combination of Git commits paired with human instructions and open-source synthetically generated code instruction datasets.
Both base and instruct models are available in sizes of 3B, 8B, 20B, and 34B parameters.
Data Collection
Our process to prepare code pretraining data involves several stages. First, we collect a combination of publicly available datasets (e.g., GitHub Code Clean, Starcoder data), public code repositories, and issues from GitHub. Second, we filter the code data collected based on the programming language in which data is written (which we determined based on file extension). Then, we also filter out data with low code quality. Third, we adopt an aggressive deduplication strategy that includes both exact and fuzzy deduplication to remove documents having (near) identical code content. Finally, we apply a HAP content filter that reduces models' likelihood of generating hateful, abusive, or profane language. We also make sure to redact Personally Identifiable Information (PII) by replacing PII content (e.g., names, email addresses, keys, passwords) with corresponding tokens (e.g., ⟨NAME⟩, ⟨EMAIL⟩, ⟨KEY⟩, ⟨PASSWORD⟩). We also scan all datasets using ClamAV to identify and remove instances of malware in the source code. In addition to collecting code data for model training, we curate several publicly available high-quality natural language datasets for improving the model’s proficiency in language understanding and mathematical reasoning.Pretraining
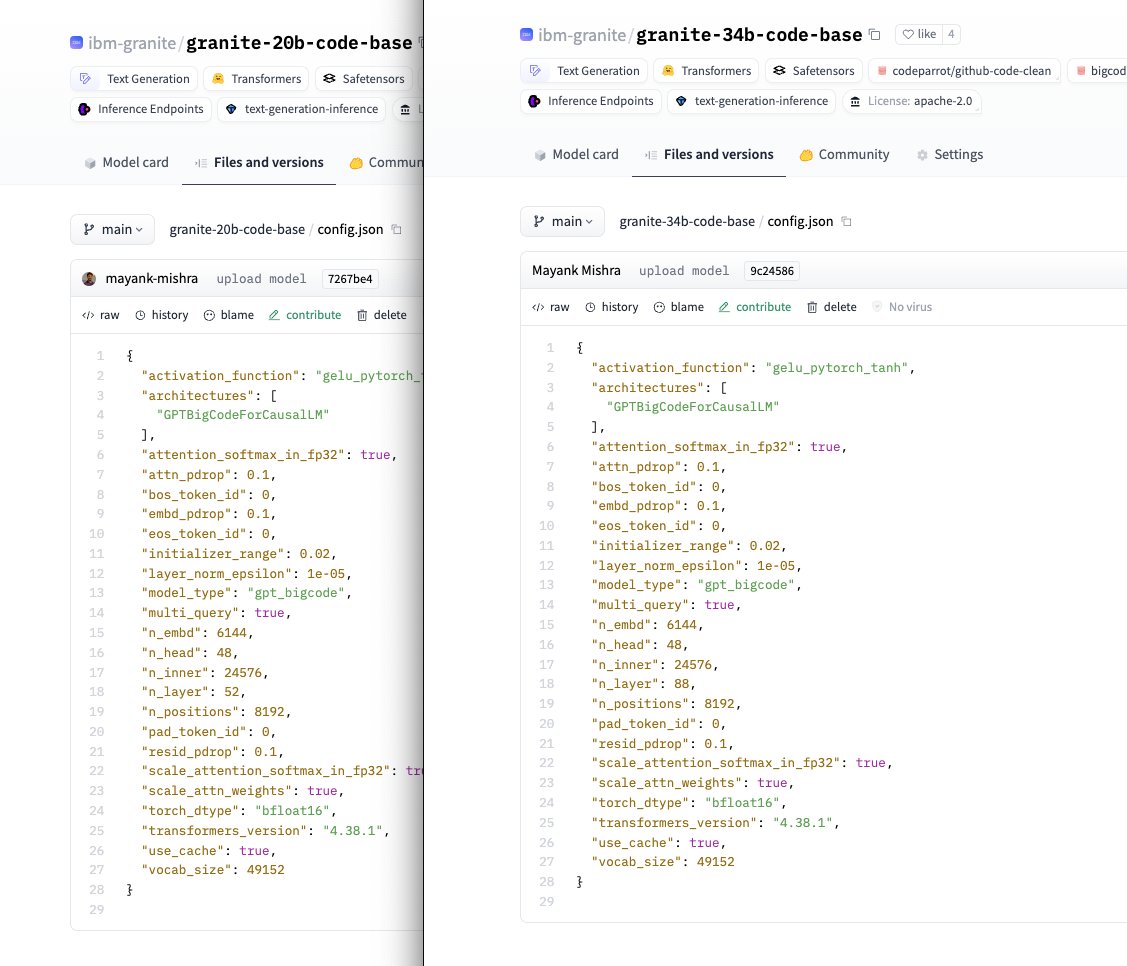
The Granite Code Base models are trained on 3-4T tokens of code data and natural language datasets related to code. Data is tokenized via byte pair encoding (BPE), employing the same tokenizer as StarCoder. We utilize high-quality data with two phases of training as follows:- Phase 1 (code only training): During phase 1, 3B and 8B models are trained for 4 trillion tokens of code data comprising 116 languages. The 20B parameter model is trained on 3 trillion tokens of code. The 34B model is trained on 1.4T tokens after the depth upscaling which is done on the 1.6T checkpoint of 20B model.
- Phase 2 (code + language training): In phase 2, we include additional high-quality publicly available data from various domains, including technical, mathematics, and web documents, to further improve the model’s performance. We train all our models for 500B tokens (80% code-20% language mixture) in phase 2 training.
Instruction Tuning
Granite Code Instruct models are finetuned on the following types of instruction data: 1) code commits sourced from CommitPackFT, 2) high-quality math datasets, specifically we used MathInstruct and MetaMathQA, 3) Code instruction datasets such as Glaive-Code-Assistant-v3, Self-OSS-Instruct-SC2, Glaive-Function-Calling-v2, NL2SQL11 and a small collection of synthetic API calling datasets, and 4) high-quality language instruction datasets such as HelpSteer and an open license-filtered version of Platypus.Evaluation Results
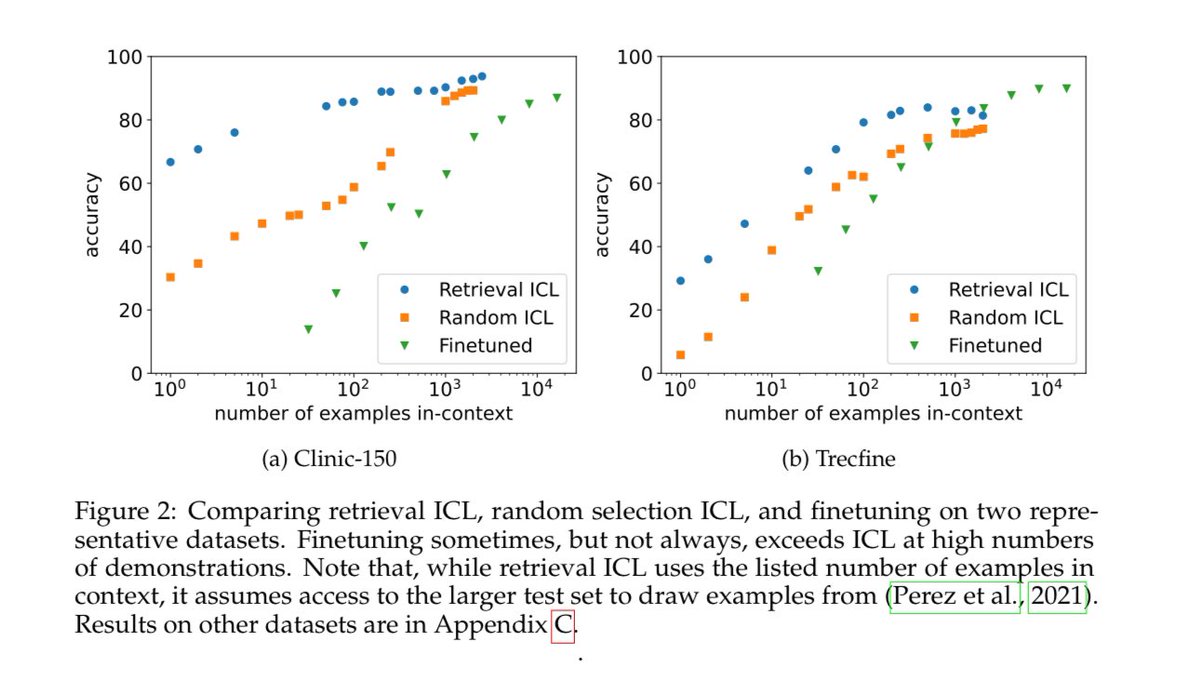
We conduct an extensive evaluation of our code models on a comprehensive list of benchmarks that includes but is not limited to HumanEvalPack, MBPP, and MBPP+. This set of benchmarks encompasses different coding tasks across commonly used programming languages (e.g., Python, JavaScript, Java, Go, C++, Rust).Our findings reveal that Granite Code models outperform strong open-source models across model sizes. The figure below illustrates how Granite-8B-Code-Base outperforms Mistral-7B, LLama-3-8B, and other open-source models in three coding tasks. We provide further evaluation results in our paper.

How to Use our Models?
To use any of our models, pick an appropriate model_path from:- ibm-granite/granite-3b-code-base
- ibm-granite/granite-3b-code-instruct
- ibm-granite/granite-8b-code-base
- ibm-granite/granite-8b-code-instruct
- ibm-granite/granite-20b-code-base
- ibm-granite/granite-20b-code-instruct
- ibm-granite/granite-34b-code-base
- ibm-granite/granite-34b-code-instruct
Last edited: