1/9
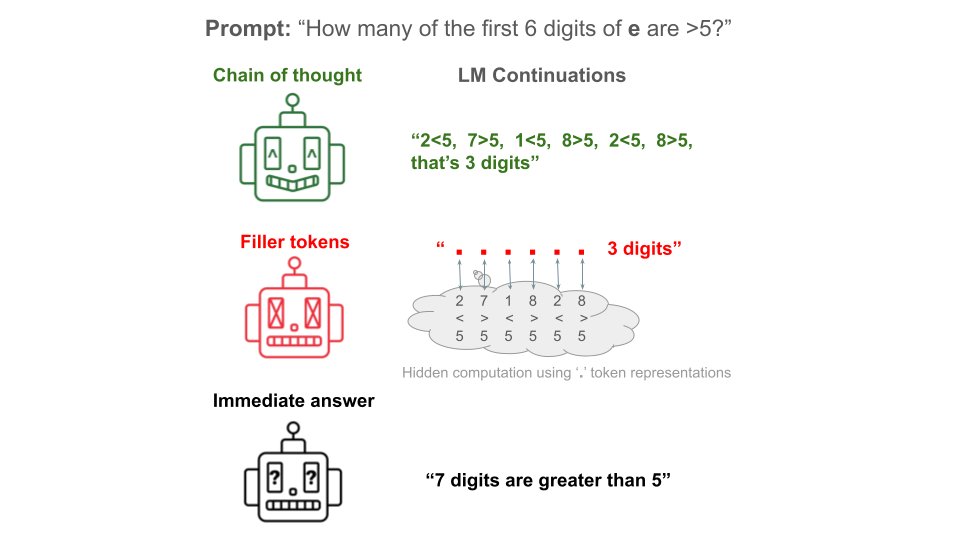
Do models need to reason in words to benefit from chain-of-thought tokens?
In our experiments, the answer is no! Models can perform on par with CoT using repeated '...' filler tokens.
This raises alignment concerns: Using filler, LMs can do hidden reasoning not visible in CoT
2/9
We experimentally demonstrate filler tokens’ utility by training small LLaMA LMs on 2 synthetic tasks:
Models trained on filler tokens match CoT performance. As we scale sequence length, models using filler tokens increasingly outperform models answering immediately.
3/9
But, are models really using filler tokens or are filler-token models just improving thanks to a difference in the training data presentation e.g. by regularizing loss gradients?
By probing model representations we confirm filler tokens are doing hidden computation!
4/9
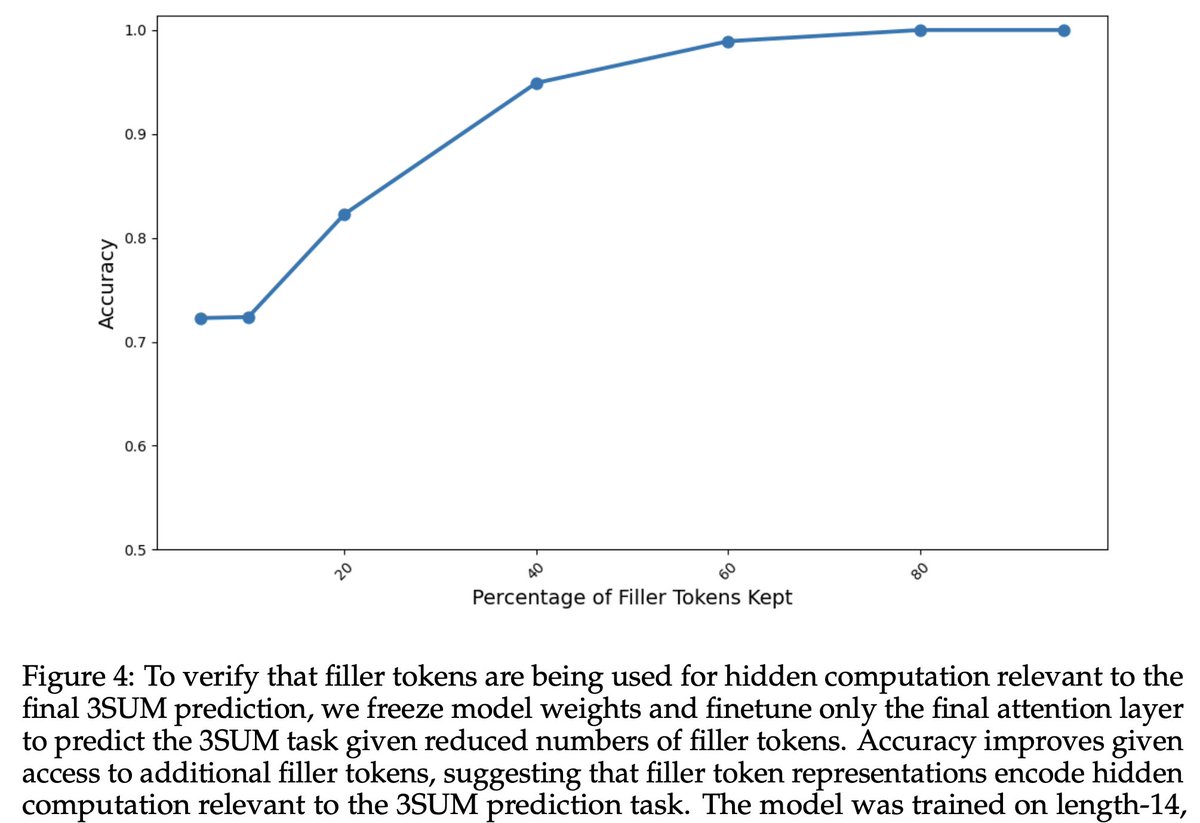
We train probes to predict the answer token using varied numbers of filler tokens.
Finding: filler tokens increase probe accuracy plateauing only at 100 '.' filler tokens.
5/9
Previous work suggested LLMs (eg GPT-3.5) do not benefit from filler tokens on common NL benchmarks. Should we expect future LLMs to use filler tokens?
We provide two conditions under which we expect filler tokens to improve LLM performance:
6/9
Data condition: On our task, LMs fail to converge when trained on only filler-token sequences (ie Question …… Answer).
Models converge only when the filler training set is augmented with additional, parallelizable CoTs, otherwise filler-token models remain at baseline accuracy
7/9
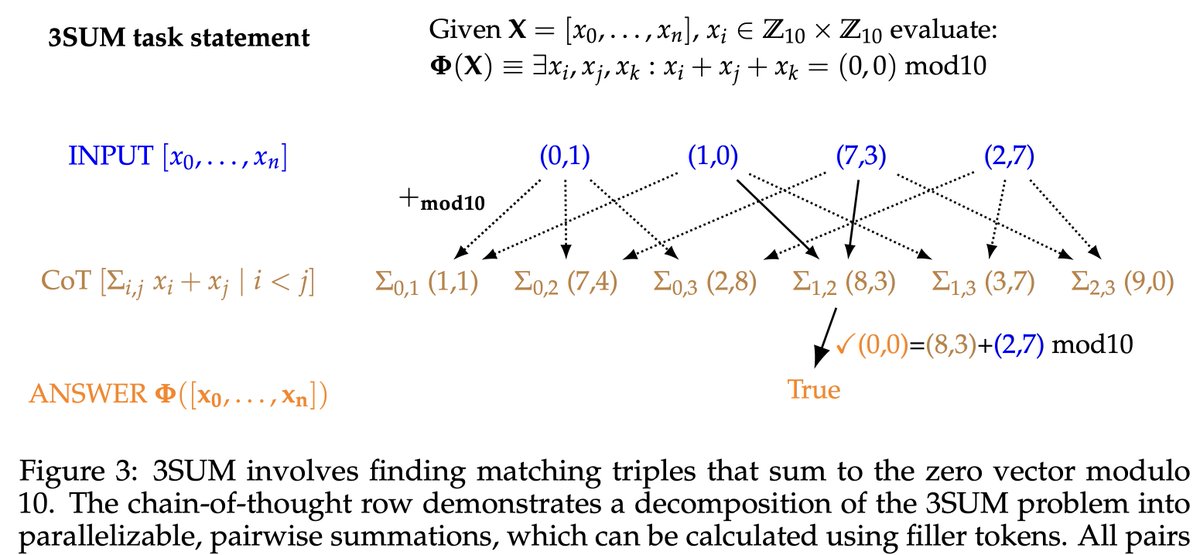
Parallelizable CoTs decompose a given task into independent subproblems solvable in parallel (eg by using individual filler tokens for each sub-problem).
On our task, parallel CoTs are crucial to filler-token performance: models fail to transfer from non-parallel CoT to filler.
8/9
Expressivity: We identify nested quantifier resolution as a general class of tasks where filler can improve transformer expressivity.
Intuitively for first-order logic formula using N>2 quantifiers a model uses N filler tokens to check each N-tuple combination for satisfiability
9/9
Shout-out to my coauthors who were indispensable throughout the project!
@lambdaviking and @sleepinyourhat
Check out our paper for more!
 arxiv.org
arxiv.org
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Do models need to reason in words to benefit from chain-of-thought tokens?
In our experiments, the answer is no! Models can perform on par with CoT using repeated '...' filler tokens.
This raises alignment concerns: Using filler, LMs can do hidden reasoning not visible in CoT
2/9
We experimentally demonstrate filler tokens’ utility by training small LLaMA LMs on 2 synthetic tasks:
Models trained on filler tokens match CoT performance. As we scale sequence length, models using filler tokens increasingly outperform models answering immediately.
3/9
But, are models really using filler tokens or are filler-token models just improving thanks to a difference in the training data presentation e.g. by regularizing loss gradients?
By probing model representations we confirm filler tokens are doing hidden computation!
4/9
We train probes to predict the answer token using varied numbers of filler tokens.
Finding: filler tokens increase probe accuracy plateauing only at 100 '.' filler tokens.
5/9
Previous work suggested LLMs (eg GPT-3.5) do not benefit from filler tokens on common NL benchmarks. Should we expect future LLMs to use filler tokens?
We provide two conditions under which we expect filler tokens to improve LLM performance:
6/9
Data condition: On our task, LMs fail to converge when trained on only filler-token sequences (ie Question …… Answer).
Models converge only when the filler training set is augmented with additional, parallelizable CoTs, otherwise filler-token models remain at baseline accuracy
7/9
Parallelizable CoTs decompose a given task into independent subproblems solvable in parallel (eg by using individual filler tokens for each sub-problem).
On our task, parallel CoTs are crucial to filler-token performance: models fail to transfer from non-parallel CoT to filler.
8/9
Expressivity: We identify nested quantifier resolution as a general class of tasks where filler can improve transformer expressivity.
Intuitively for first-order logic formula using N>2 quantifiers a model uses N filler tokens to check each N-tuple combination for satisfiability
9/9
Shout-out to my coauthors who were indispensable throughout the project!
@lambdaviking and @sleepinyourhat
Check out our paper for more!
Let's Think Dot by Dot: Hidden Computation in Transformer Language Models
Chain-of-thought responses from language models improve performance across most benchmarks. However, it remains unclear to what extent these performance gains can be attributed to human-like task decomposition or simply the greater computation that additional tokens allow. We show that...
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196








.jpg")



 Marketing Letters
Marketing Letters