1/1
It's been exactly one week since we released Meta Llama 3, in that time the models have been downloaded over 1.2M times, we've seen 600+ derivative models on
@HuggingFace and much more.
More on the exciting impact we're already seeing with Llama 3 A look at the early impact of Meta Llama 3
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
It's been exactly one week since we released Meta Llama 3, in that time the models have been downloaded over 1.2M times, we've seen 600+ derivative models on
@HuggingFace and much more.
More on the exciting impact we're already seeing with Llama 3 A look at the early impact of Meta Llama 3
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

1/13
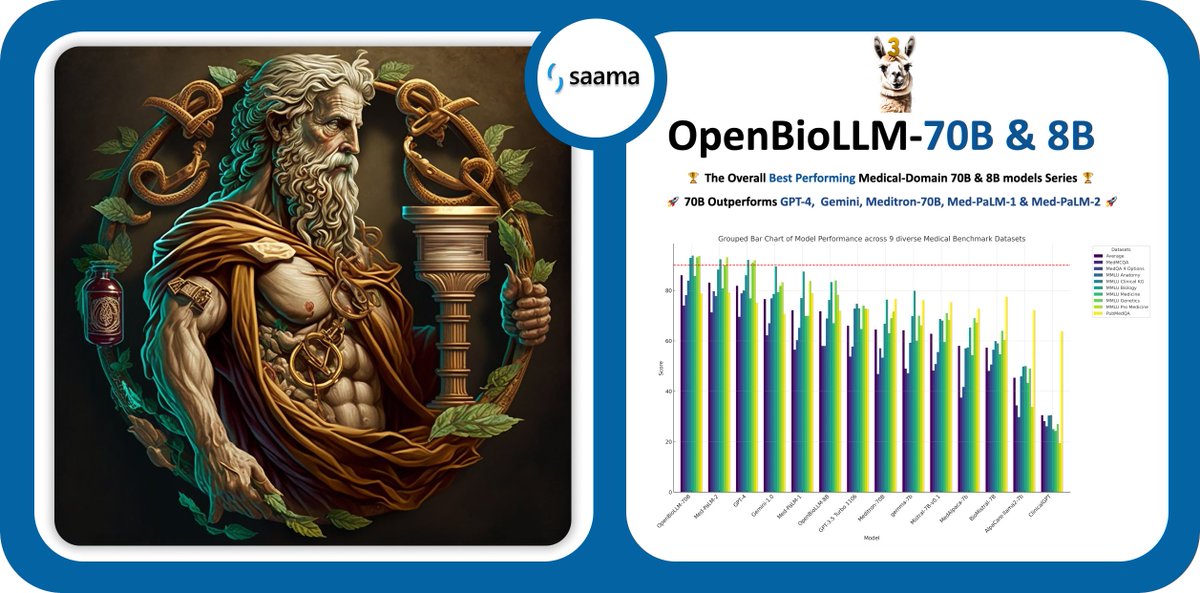
Introducing OpenBioLLM-Llama3-70B & 8B: The most capable openly available Medical-domain LLMs to date!
Outperforms industry giants like GPT-4, Gemini, Meditron-70B, Med-PaLM-1, and Med-PaLM-2 in the biomedical domain.
OpenBioLLM-70B delivers SOTA performance, setting a new state-of-the-art for models of its size.
OpenBioLLM-8B model and even surpasses GPT-3.5, Gemini, and Meditron-70B!
Today's release is just the beginning! In the coming months, we'll be introducing:
- Expanded medical domain coverage
- Longer context windows
- Better benchmarks
- Multimodal capabilities
Medical-LLM Leaderboard: Open Medical-LLM Leaderboard - a Hugging Face Space by openlifescienceai
#gpt #gpt4 #gemini #medical #llm #chatgpt #opensource #llama3 #meta
2/13
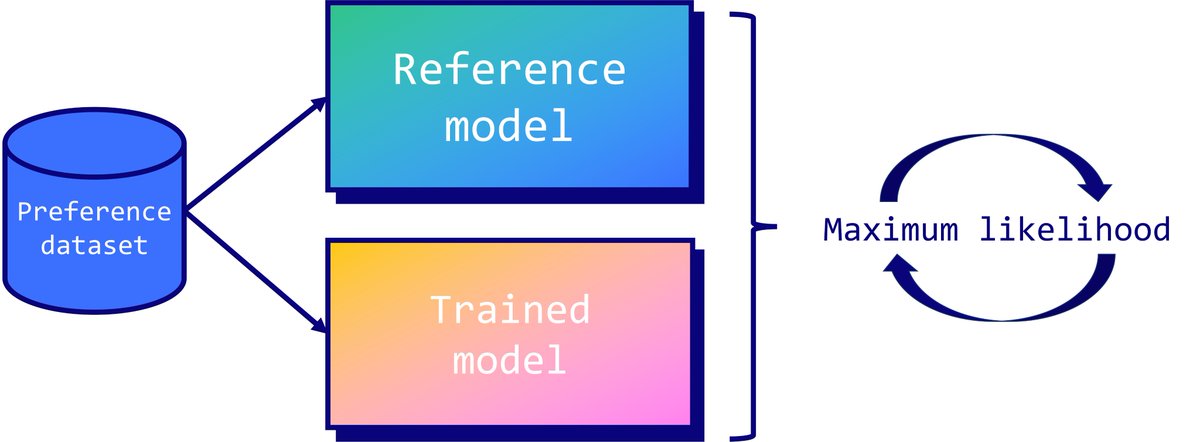
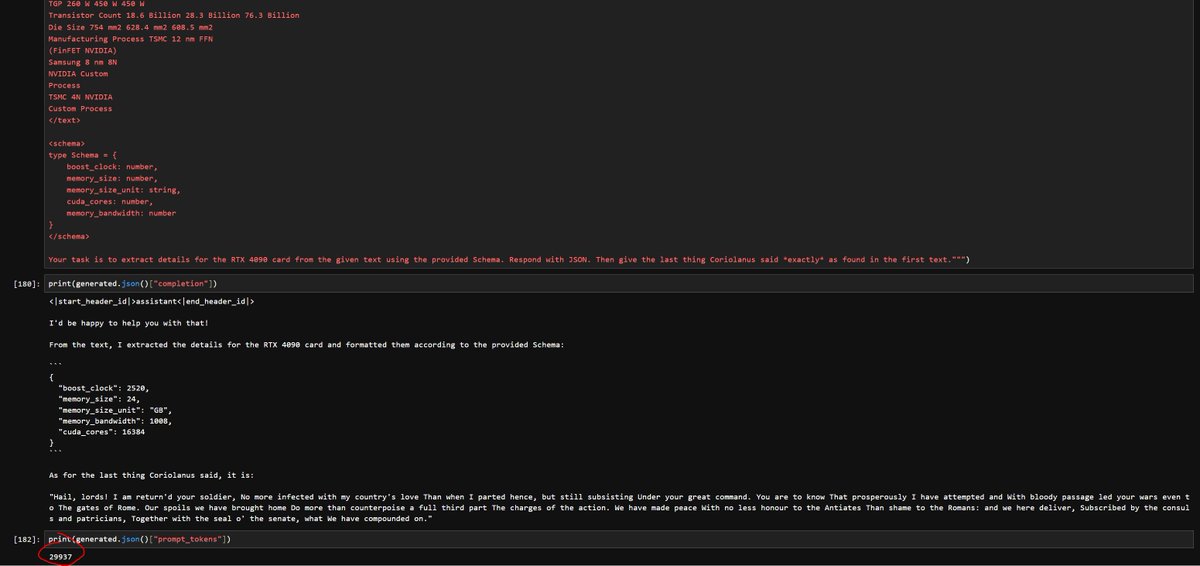
Fine-tuning details
The fine-tuning process was conducted in two phases to optimize the model's performance:
- Fine-tuned using the LLama-3 70B & 8B models as the base
- Utilized the Direct Preference Optimization: Your Language Model is Secretly a Reward Model (DPO) …
3/13
Dataset
Curating the custom dataset was a time-consuming process that spanned over ~4 months. We diligently collected data, collaborated with medical experts to review its quality, and filtered out subpar examples.
To enhance the dataset's diversity, we incorporated…
4/13
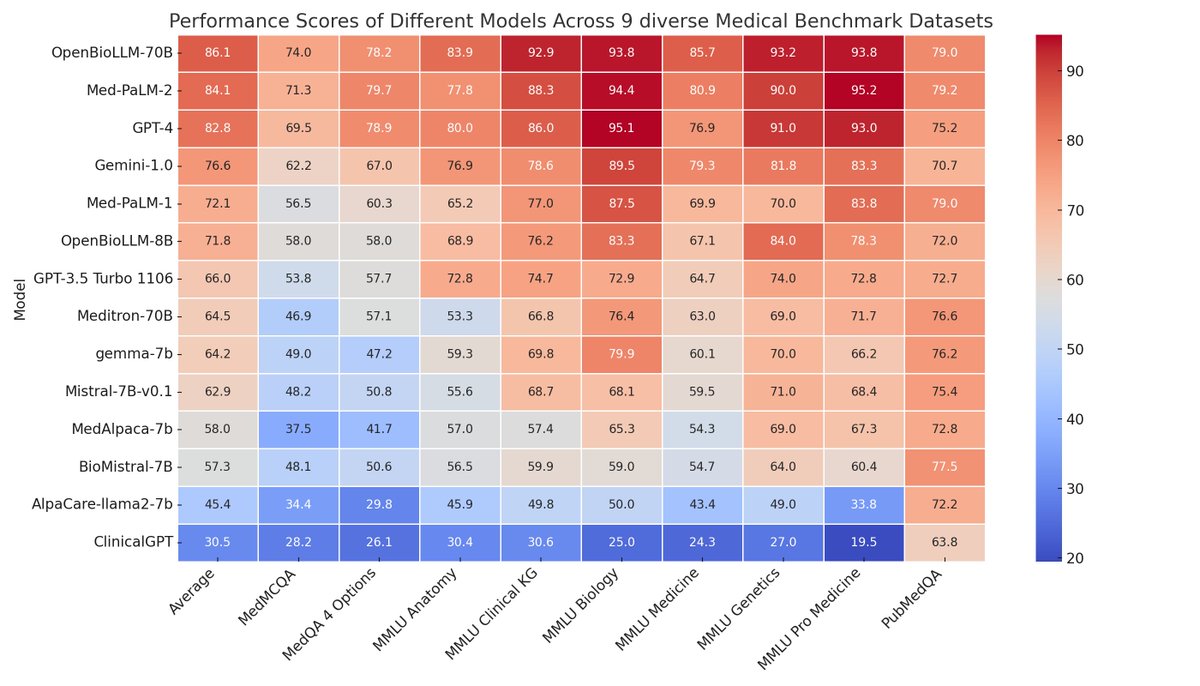
Results
OpenBioLLM-70B showcases remarkable performance, surpassing larger models such as GPT-4, Gemini, Meditron-70B, Med-PaLM-1, and Med-PaLM-2 across 9 diverse biomedical datasets.
Despite its smaller parameter count compared to GPT-4 & Med-PaLM, it achieves…
5/13
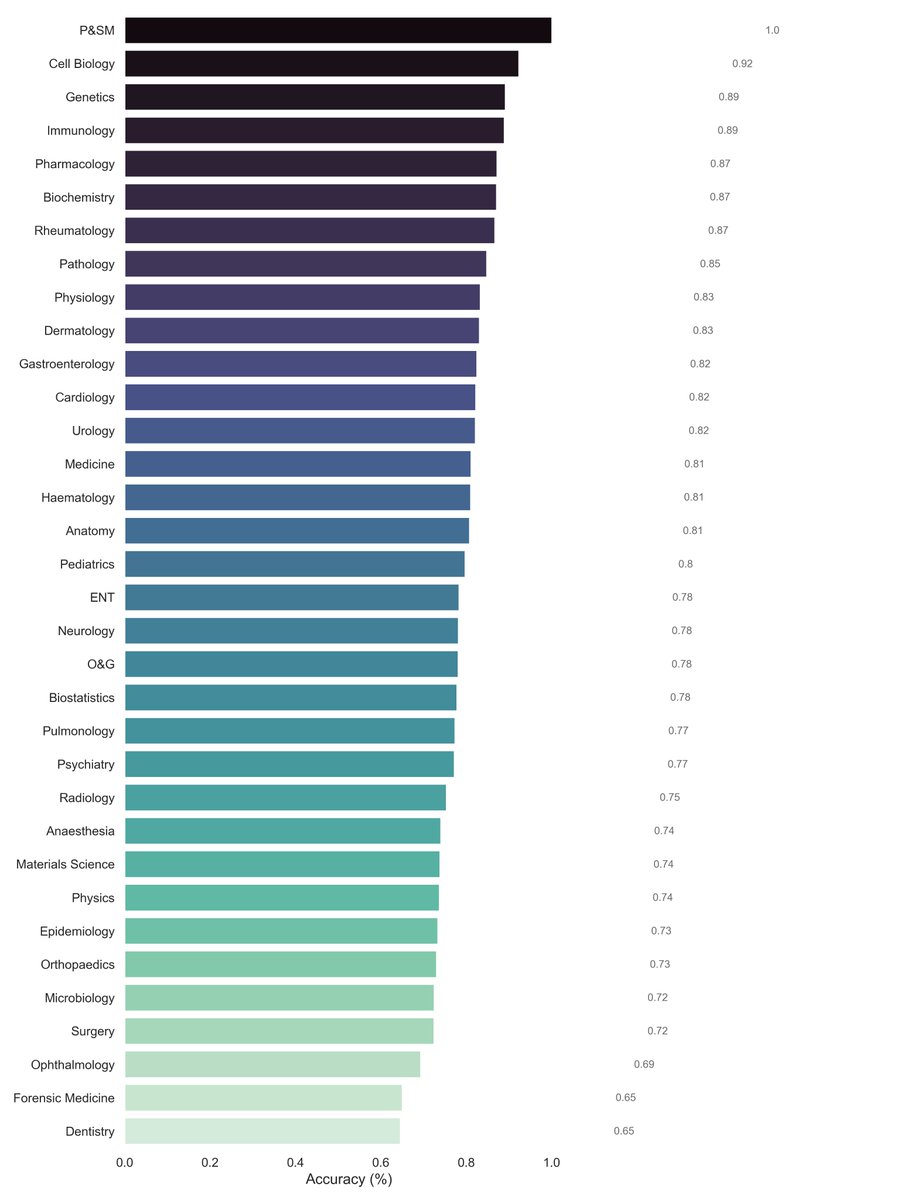
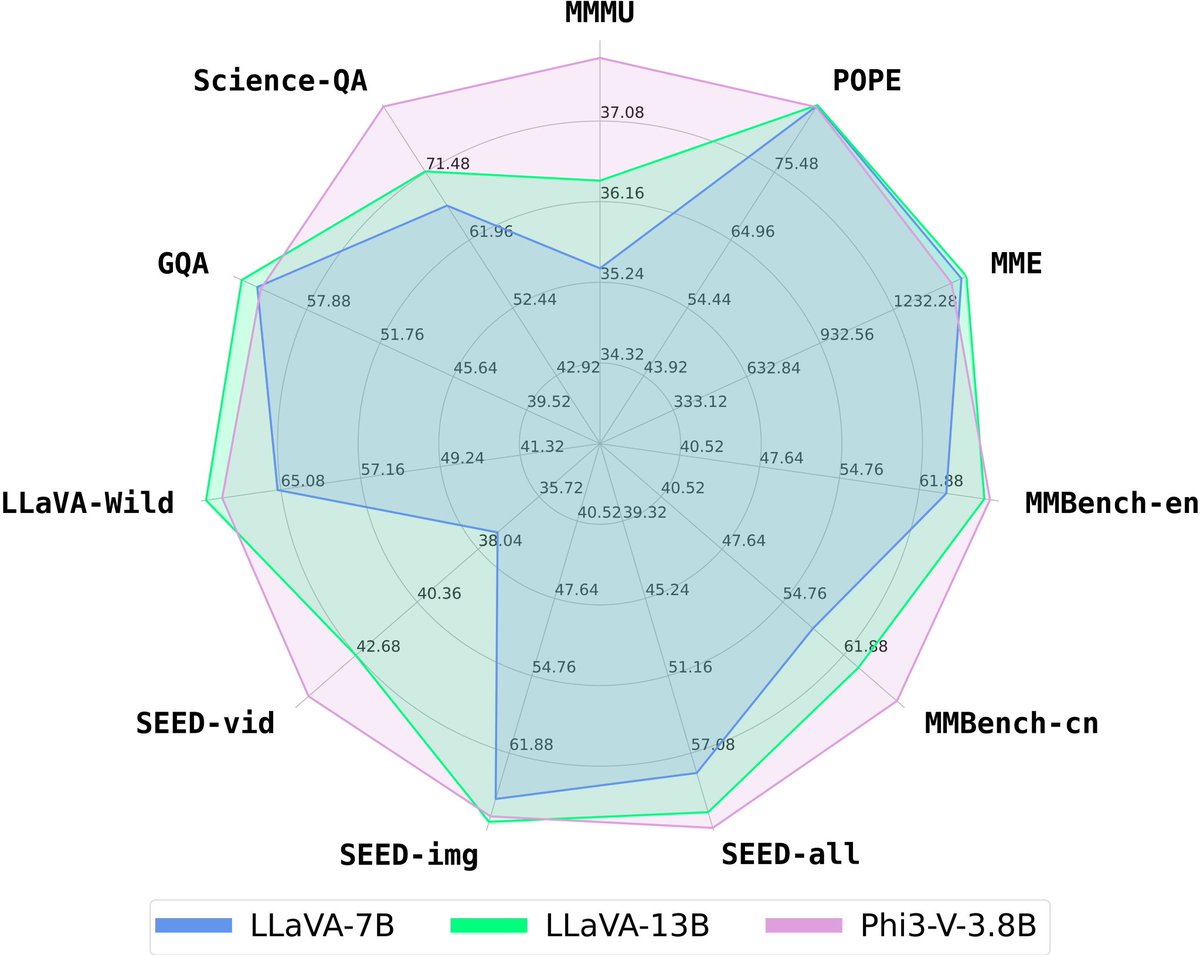
To gain a deeper understanding of the results, we also evaluated the top subject-wise accuracy of 70B.
6/13
Models
You can download the models directly from Huggingface today.
- 70B : aaditya/OpenBioLLM-Llama3-70B · Hugging Face
- 8B : aaditya/OpenBioLLM-Llama3-8B · Hugging Face
7/13
Here are the top medical use cases for OpenBioLLM-70B & 8B:
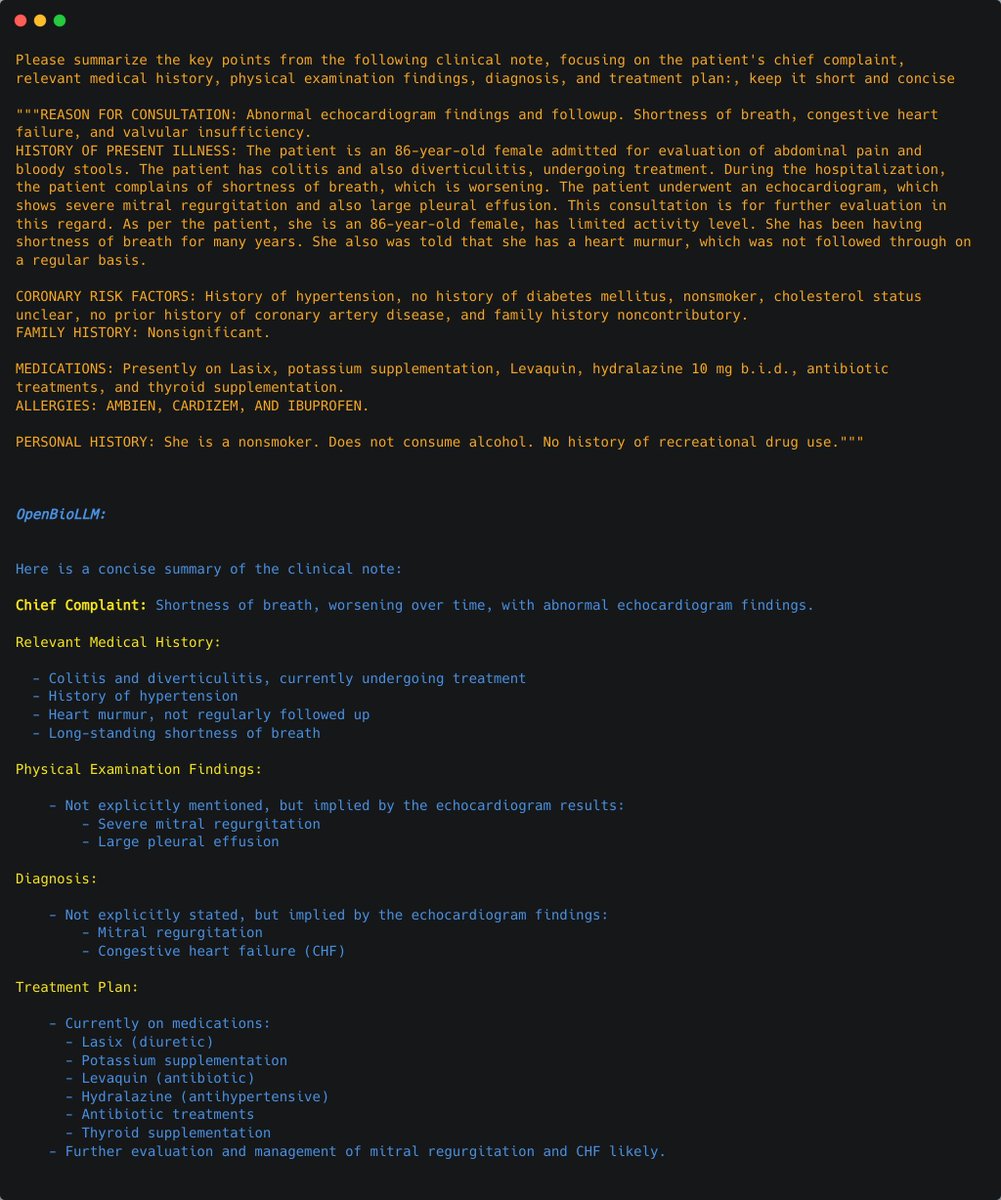
Summarize Clinical Notes
OpenBioLLM can efficiently analyze and summarize complex clinical notes, EHR data, and discharge summaries, extracting key information and generating concise, structured summaries
8/13
Answer Medical Questions
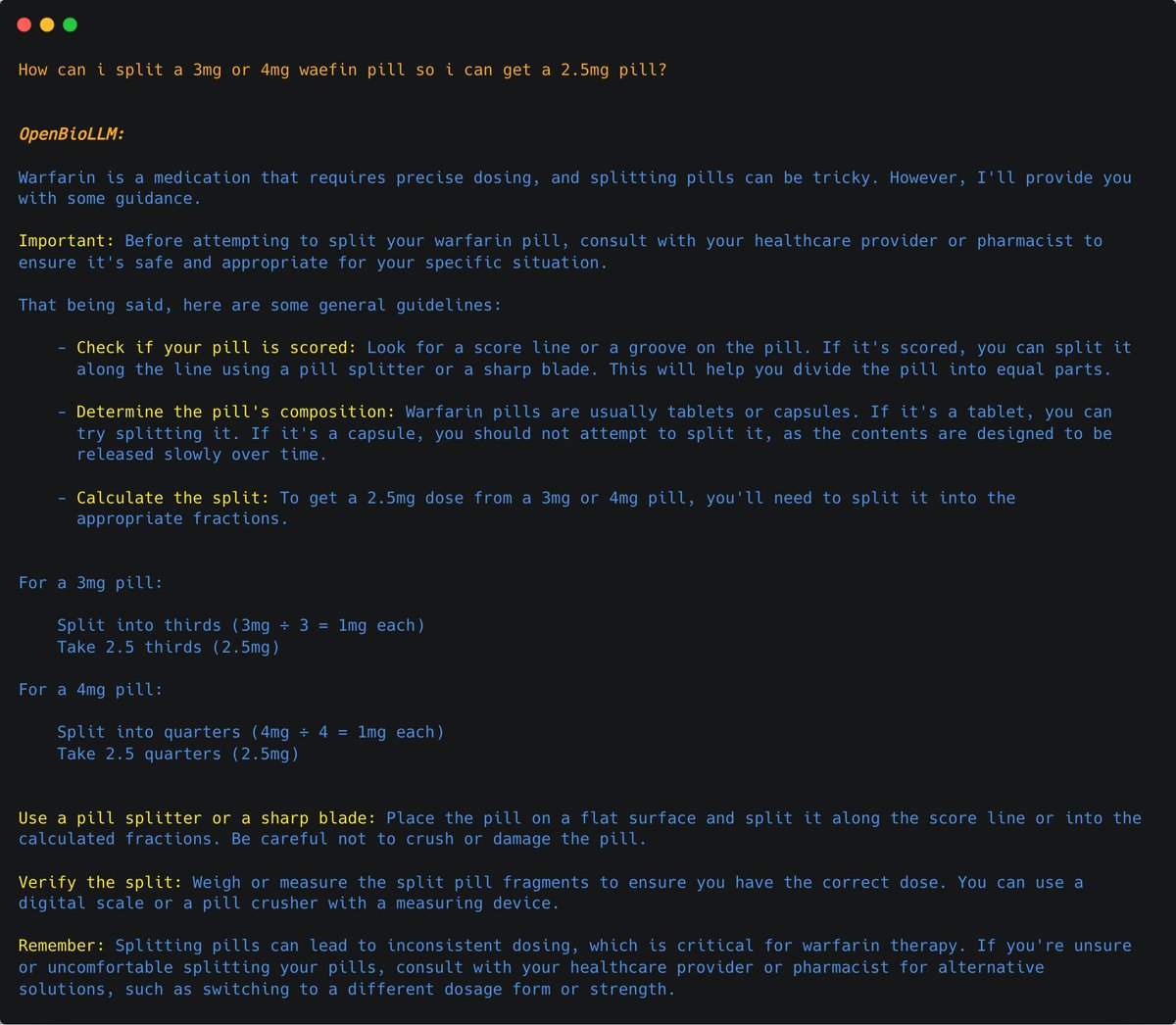
OpenBioLLM can provide answers to a wide range of medical questions.
9/13
Classification
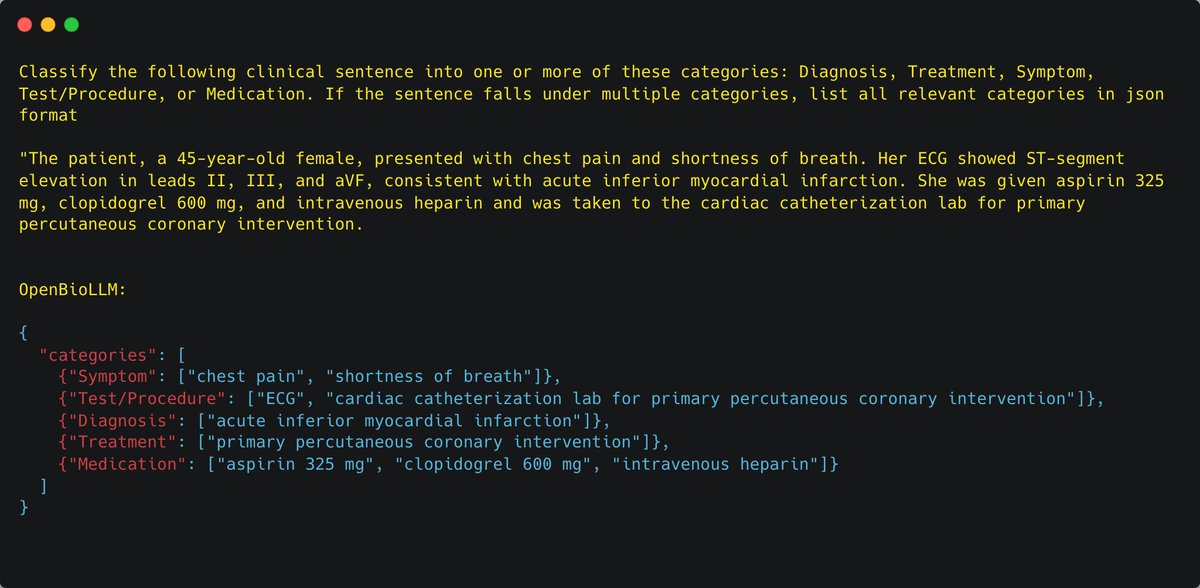
OpenBioLLM can perform various biomedical classification tasks, such as disease prediction, sentiment analysis, medical document categorization
10/13
De-Identification
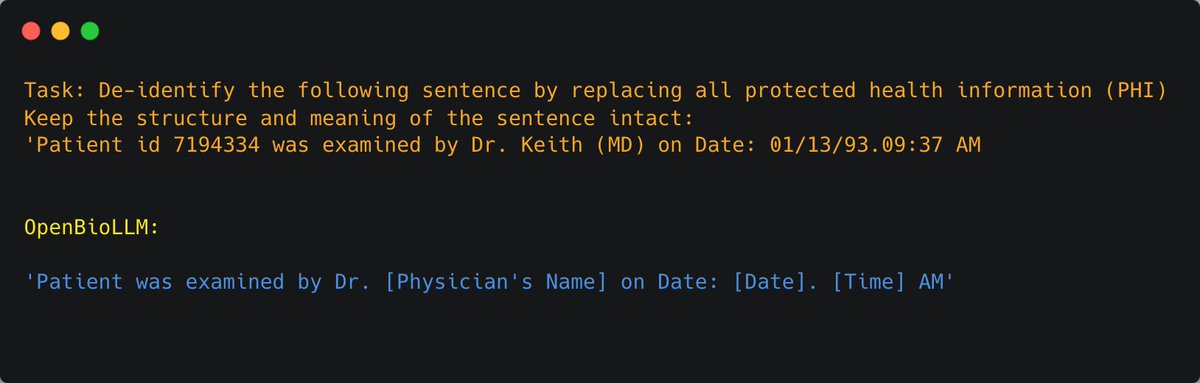
OpenBioLLM can detect and remove personally identifiable information (PII) from medical records, ensuring patient privacy and compliance with data protection regulations like HIPAA.
11/13
Advisory Notice!
While OpenBioLLM-70B & 8B leverages high-quality data sources, its outputs may still contain inaccuracies, biases, or misalignments that could pose risks if relied upon for medical decision-making without further testing and refinement.
The model's…
12/13
Thanks to
@malai_san for their guidance and the incredible team at @saamatechinc for their invaluable resources and support.
13/13
Thanks to
@winglian for the amazing Axolotl support and to @huggingface and @weights_biases for providing such awesome open-source tools
Thanks to
@Teknium1 for having a long discussion over Discord on fine-tuning and other topics. He is a really humble and awesome guy.…
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Introducing OpenBioLLM-Llama3-70B & 8B: The most capable openly available Medical-domain LLMs to date!
Outperforms industry giants like GPT-4, Gemini, Meditron-70B, Med-PaLM-1, and Med-PaLM-2 in the biomedical domain.
OpenBioLLM-70B delivers SOTA performance, setting a new state-of-the-art for models of its size.
OpenBioLLM-8B model and even surpasses GPT-3.5, Gemini, and Meditron-70B!
Today's release is just the beginning! In the coming months, we'll be introducing:
- Expanded medical domain coverage
- Longer context windows
- Better benchmarks
- Multimodal capabilities
Medical-LLM Leaderboard: Open Medical-LLM Leaderboard - a Hugging Face Space by openlifescienceai
#gpt #gpt4 #gemini #medical #llm #chatgpt #opensource #llama3 #meta
2/13
Fine-tuning details
The fine-tuning process was conducted in two phases to optimize the model's performance:
- Fine-tuned using the LLama-3 70B & 8B models as the base
- Utilized the Direct Preference Optimization: Your Language Model is Secretly a Reward Model (DPO) …
3/13
Dataset
Curating the custom dataset was a time-consuming process that spanned over ~4 months. We diligently collected data, collaborated with medical experts to review its quality, and filtered out subpar examples.
To enhance the dataset's diversity, we incorporated…
4/13
Results
OpenBioLLM-70B showcases remarkable performance, surpassing larger models such as GPT-4, Gemini, Meditron-70B, Med-PaLM-1, and Med-PaLM-2 across 9 diverse biomedical datasets.
Despite its smaller parameter count compared to GPT-4 & Med-PaLM, it achieves…
5/13
To gain a deeper understanding of the results, we also evaluated the top subject-wise accuracy of 70B.
6/13
Models
You can download the models directly from Huggingface today.
- 70B : aaditya/OpenBioLLM-Llama3-70B · Hugging Face
- 8B : aaditya/OpenBioLLM-Llama3-8B · Hugging Face
7/13
Here are the top medical use cases for OpenBioLLM-70B & 8B:
Summarize Clinical Notes
OpenBioLLM can efficiently analyze and summarize complex clinical notes, EHR data, and discharge summaries, extracting key information and generating concise, structured summaries
8/13
Answer Medical Questions
OpenBioLLM can provide answers to a wide range of medical questions.
9/13
Classification
OpenBioLLM can perform various biomedical classification tasks, such as disease prediction, sentiment analysis, medical document categorization
10/13
De-Identification
OpenBioLLM can detect and remove personally identifiable information (PII) from medical records, ensuring patient privacy and compliance with data protection regulations like HIPAA.
11/13
Advisory Notice!
While OpenBioLLM-70B & 8B leverages high-quality data sources, its outputs may still contain inaccuracies, biases, or misalignments that could pose risks if relied upon for medical decision-making without further testing and refinement.
The model's…
12/13
Thanks to
@malai_san for their guidance and the incredible team at @saamatechinc for their invaluable resources and support.
13/13
Thanks to
@winglian for the amazing Axolotl support and to @huggingface and @weights_biases for providing such awesome open-source tools
Thanks to
@Teknium1 for having a long discussion over Discord on fine-tuning and other topics. He is a really humble and awesome guy.…
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Last edited:









 WebLlama
WebLlama