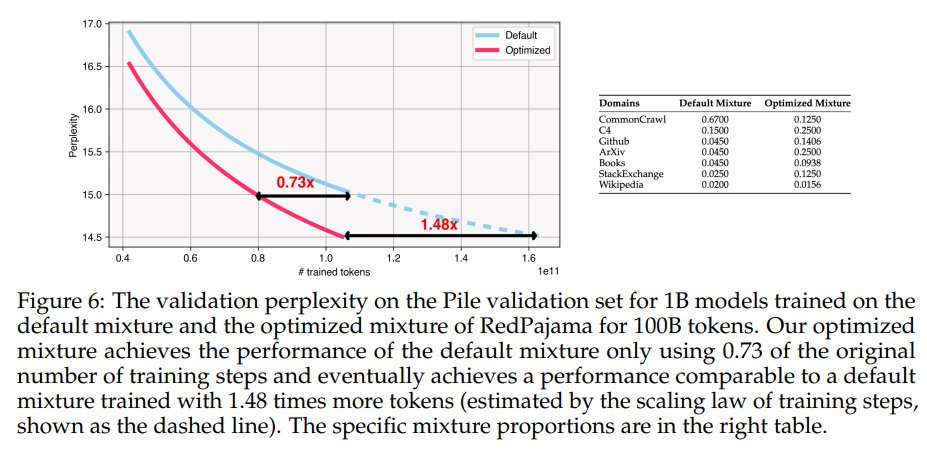
1/8
LLMs can use complex instructions - why can’t retrieval models?
We build FollowIR, a training/test set of real-world human retrieval instructions. Our FollowIR-7B is the best IR model for instruct-following, even beating
@cohere
@openai
retrievers
[2403.15246] FollowIR: Evaluating and Teaching Information Retrieval Models to Follow Instructions
2/8
We build FollowIR from three TREC datasets which have instructions for humans to judge doc relevance. If humans can do it, why not models?
We alter these instructions (and the rel. doc set) and see how models change their outputs. We measure w/ p-MRR, a new pairwise eval metric
3/8
We find that IR models generally fail to follow instructions, even those that have been trained with them. Only 3B+ models and LLMs without retrieval training are successful.
We show this is cuz existing IR models use their instructions as keywords instead of as instructions
4/8
Our new model FollowIR-7B has the highest score for following instructions, as well as gains in standard metrics
If you’re interested, check out our eval code: we extend MTEB
@muennighoff
@nils_reimers
making it easy to evaluate your MTEB model by only changing a few lines
5/8
This is a collaboration that started with my great internship mentors from
@allen_ai
@SemanticScholar
, including
@soldni
@kylelostat
@armancohan
as well as
@macavaney
at
@GlasgowCS
and my advisors at
@jhuclsp
@ben_vandurme
and
@lawrie_dawn
6/8
**Links**
Github:
https://github.com/orionw/FollowIR
Model: https://huggingface.co/jhu-clsp/FollowIR-7B
Paper: https://arxiv.org/abs/2403.15246
Data:
7/8
Separately,
@hanseok_oh had a similar idea to evaluate instructions in IR, but with a different approach to data creation. Definitely check it out also!
8/8
Can retrievers follow instructions, including your intentions and preferences?
Introducing INSTRUCTIR, a benchmark for evaluating instruction following in information retrieval. [1/N]