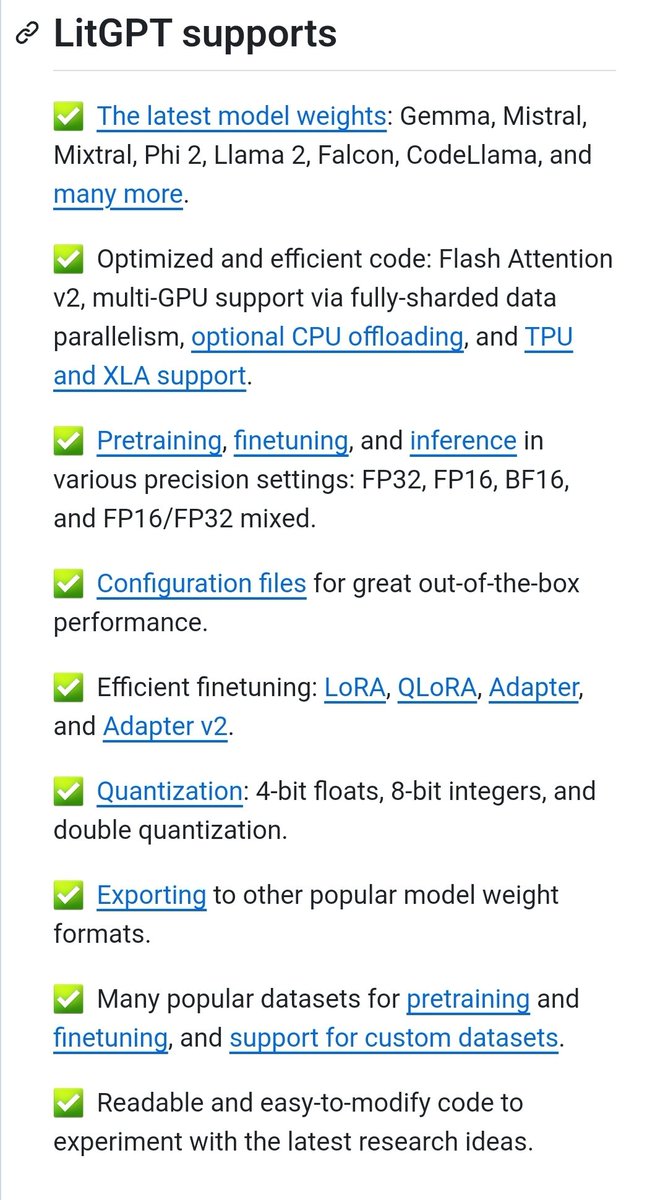
1/1
SambaNova already outpaces Databricks DBRX
@SambaNovaAI released Samba-CoE v0.2 LLM and it's already leaving the competition in the dust.
The model is doing more with less.
SambaNova already outpaces Databricks DBRX
@SambaNovaAI released Samba-CoE v0.2 LLM and it's already leaving the competition in the dust.
The model is doing more with less.
1/7
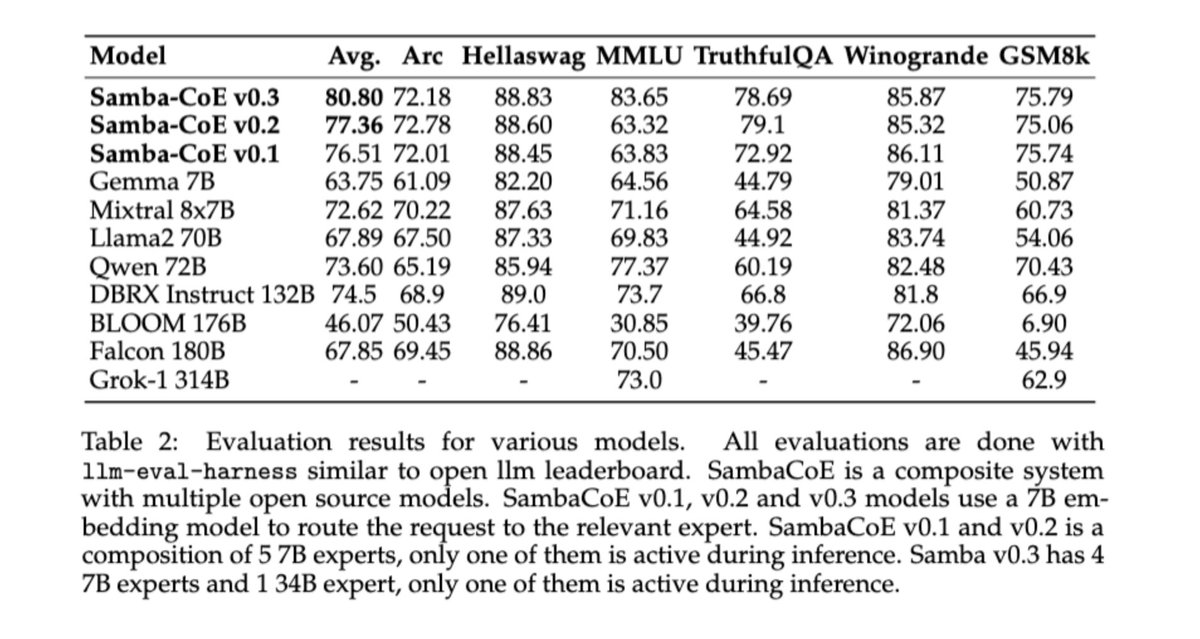
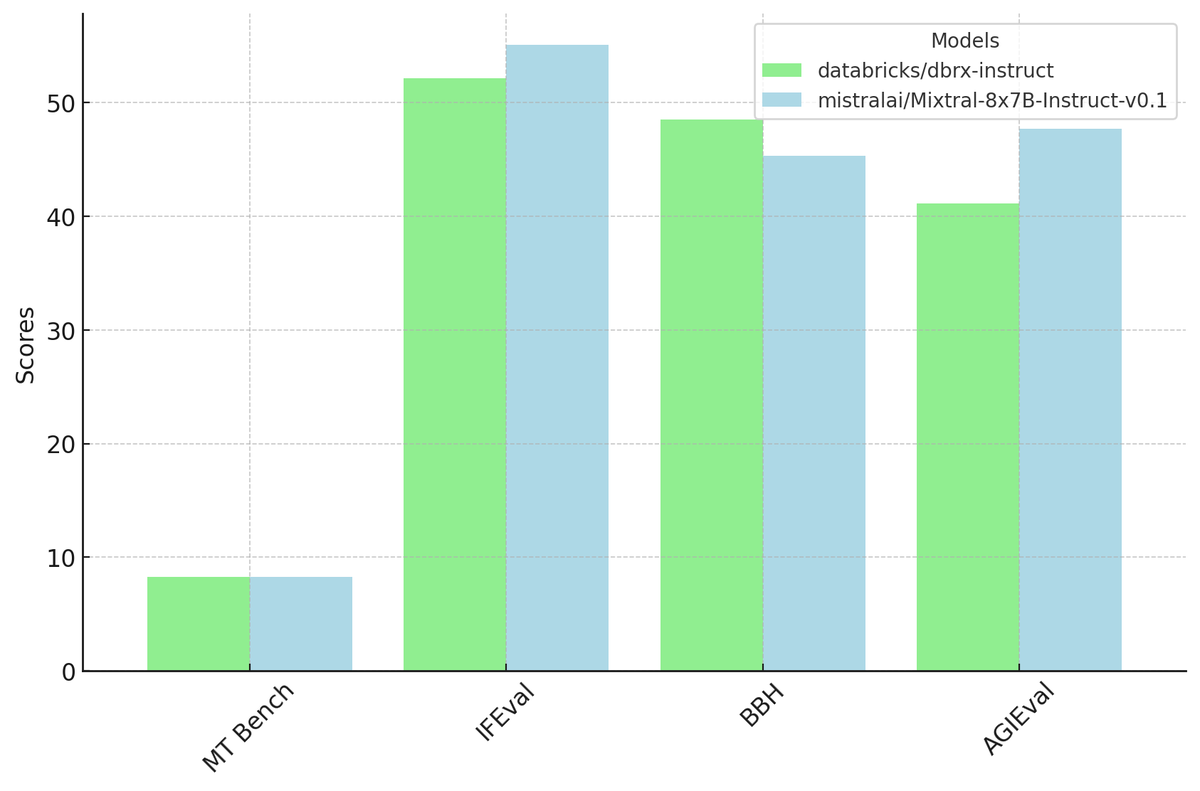
Excited to announce Samba-CoE v0.2, which outperforms DBRX by
@DbrxMosaicAI and
@databricks
, Mixtral-8x7B from
@MistralAI
, and Grok-1 by
@grok
at a breakneck speed of 330 tokens/s.
These breakthrough speeds were achieved without sacrificing precision and only on 8 sockets, showcasing the true capabilities of dataflow! Why would you buy 576 sockets and go to 8 bits when you can run using 16 bits and just 8 sockets. Try out the model and check out the speed here - Streamlit.
We are also providing a sneak peak of our next model, Samba-CoE v0.3, available soon with our partners at
@LeptonAI
. Read more about this announcement at SambaNova Delivers Accurate Models At Blazing Speed
2/7
Extending the methodology used to create Samba-CoE v0.1, these models are built on top of open-source models in Samba-1 and Sambaverse (Find the best open source model for your project with Sambaverse) using a unique approach towards ensembling and model merging.
3/7
This model outperforms Gemma-7B from
@GoogleAI and
@GoogleDeepMind
, Mixtral-8x7B from
@MistralAI
,
llama2-70B from
@AIatMeta
, Qwen-72B from
@AlibabaGroup
Qwen team, Falcon-180B from
@TIIuae
and BLOOM-176B from
@BigscienceW
.
4/7
The expert models are all open source, the routing strategy has not been open sourced yet. Much more information to follow in the coming weeks.
5/7
@mattshumer_
@EvanKirstel
@_akhaliq
@rasbt
@pmddomingos
@emollick
@GaryMarcus
6/7
@ylecun
@mattmayo13
@alliekmiller
@ValaAfshar
@Andrew
@rowancheung
7/7
The expert models are all open source, the routing strategy has not been open sourced yet. Much more information to follow in the coming weeks.
Excited to announce Samba-CoE v0.2, which outperforms DBRX by
@DbrxMosaicAI and
@databricks
, Mixtral-8x7B from
@MistralAI
, and Grok-1 by
@grok
at a breakneck speed of 330 tokens/s.
These breakthrough speeds were achieved without sacrificing precision and only on 8 sockets, showcasing the true capabilities of dataflow! Why would you buy 576 sockets and go to 8 bits when you can run using 16 bits and just 8 sockets. Try out the model and check out the speed here - Streamlit.
We are also providing a sneak peak of our next model, Samba-CoE v0.3, available soon with our partners at
@LeptonAI
. Read more about this announcement at SambaNova Delivers Accurate Models At Blazing Speed
2/7
Extending the methodology used to create Samba-CoE v0.1, these models are built on top of open-source models in Samba-1 and Sambaverse (Find the best open source model for your project with Sambaverse) using a unique approach towards ensembling and model merging.
3/7
This model outperforms Gemma-7B from
@GoogleAI and
@GoogleDeepMind
, Mixtral-8x7B from
@MistralAI
,
llama2-70B from
@AIatMeta
, Qwen-72B from
@AlibabaGroup
Qwen team, Falcon-180B from
@TIIuae
and BLOOM-176B from
@BigscienceW
.
4/7
The expert models are all open source, the routing strategy has not been open sourced yet. Much more information to follow in the coming weeks.
5/7
@mattshumer_
@EvanKirstel
@_akhaliq
@rasbt
@pmddomingos
@emollick
@GaryMarcus
6/7
@ylecun
@mattmayo13
@alliekmiller
@ValaAfshar
@Andrew
@rowancheung
7/7
The expert models are all open source, the routing strategy has not been open sourced yet. Much more information to follow in the coming weeks.