
1/9
mPLUG-DocOwl 1.5
Unified Structure Learning for OCR-free Document Understanding
Structure information is critical for understanding the semantics of text-rich images, such as documents, tables, and charts. Existing Multimodal Large Language Models (MLLMs) for
2/9
Visual Document Understanding are equipped with text recognition ability but lack general structure understanding abilities for text-rich document images. In this work, we emphasize the importance of structure information in Visual Document Understanding and propose the
3/9
Unified Structure Learning to boost the performance of MLLMs. Our Unified Structure Learning comprises structure-aware parsing tasks and multi-grained text localization tasks across 5 domains: document, webpage, table, chart, and natural image. To better encode
4/9
structure information, we design a simple and effective vision-to-text module H-Reducer, which can not only maintain the layout information but also reduce the length of visual features by merging horizontal adjacent patches through convolution, enabling the LLM to
5/9
understand high-resolution images more efficiently. Furthermore, by constructing structure-aware text sequences and multi-grained pairs of texts and bounding boxes for publicly available text-rich images, we build a comprehensive training set DocStruct4M to support
6/9
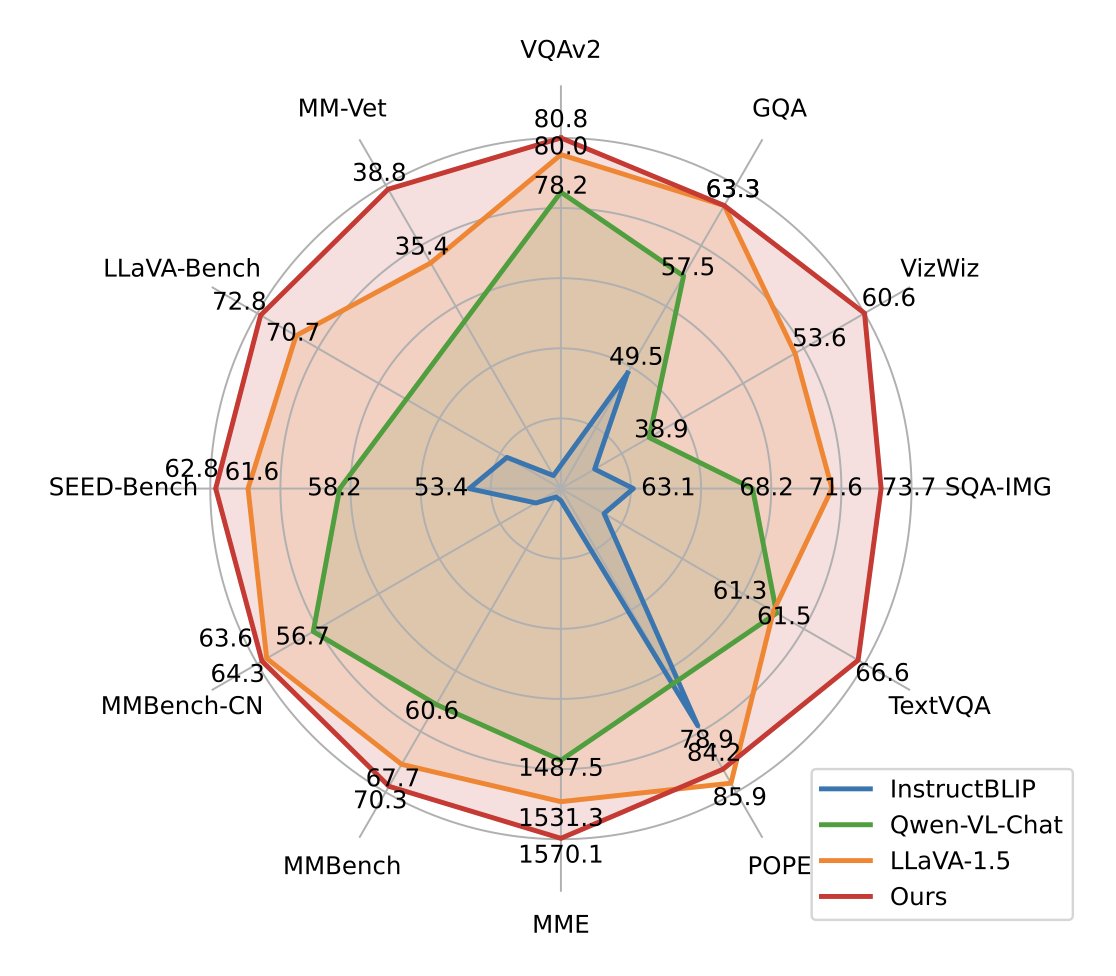
structure learning. Finally, we construct a small but high-quality reasoning tuning dataset DocReason25K to trigger the detailed explanation ability in the document domain. Our model DocOwl 1.5 achieves state-of-the-art performance on 10 visual document
7/9
understanding benchmarks, improving the SOTA performance of MLLMs with a 7B LLM by more than 10 points in 5/10 benchmarks.
8/9
paper page:
9/9
Google presents Chart-based Reasoning
Transferring Capabilities from LLMs to VLMs
Vision-language models (VLMs) are achieving increasingly strong performance on multimodal tasks. However, reasoning capabilities remain limited particularly for smaller VLMs, while those of
mPLUG-DocOwl 1.5
Unified Structure Learning for OCR-free Document Understanding
Structure information is critical for understanding the semantics of text-rich images, such as documents, tables, and charts. Existing Multimodal Large Language Models (MLLMs) for
2/9
Visual Document Understanding are equipped with text recognition ability but lack general structure understanding abilities for text-rich document images. In this work, we emphasize the importance of structure information in Visual Document Understanding and propose the
3/9
Unified Structure Learning to boost the performance of MLLMs. Our Unified Structure Learning comprises structure-aware parsing tasks and multi-grained text localization tasks across 5 domains: document, webpage, table, chart, and natural image. To better encode
4/9
structure information, we design a simple and effective vision-to-text module H-Reducer, which can not only maintain the layout information but also reduce the length of visual features by merging horizontal adjacent patches through convolution, enabling the LLM to
5/9
understand high-resolution images more efficiently. Furthermore, by constructing structure-aware text sequences and multi-grained pairs of texts and bounding boxes for publicly available text-rich images, we build a comprehensive training set DocStruct4M to support
6/9
structure learning. Finally, we construct a small but high-quality reasoning tuning dataset DocReason25K to trigger the detailed explanation ability in the document domain. Our model DocOwl 1.5 achieves state-of-the-art performance on 10 visual document
7/9
understanding benchmarks, improving the SOTA performance of MLLMs with a 7B LLM by more than 10 points in 5/10 benchmarks.
8/9
paper page:
9/9
Google presents Chart-based Reasoning
Transferring Capabilities from LLMs to VLMs
Vision-language models (VLMs) are achieving increasingly strong performance on multimodal tasks. However, reasoning capabilities remain limited particularly for smaller VLMs, while those of


 NeuralChat beats GPT4 and Claude on hallucination and factual consistency rate in a new leaderboard
NeuralChat beats GPT4 and Claude on hallucination and factual consistency rate in a new leaderboard initiated by
initiated by  RL/DPO is getting so important to improve the model quality, particularly for responsible AI.
RL/DPO is getting so important to improve the model quality, particularly for responsible AI. Code to fine-tune NeuralChat:
Code to fine-tune NeuralChat: Build your chatbot within minutes on your favorite device; offer SOTA compression techniques for LLMs; run LLMs efficiently on Intel Platforms
Build your chatbot within minutes on your favorite device; offer SOTA compression techniques for LLMs; run LLMs efficiently on Intel Platforms



















 AI lab, we wanted to apply our method to produce foundation models for Japan. We were able to quickly evolve 3 best-in-class models with language, vision and image generation capabilities, tailored for Japan and its culture.
AI lab, we wanted to apply our method to produce foundation models for Japan. We were able to quickly evolve 3 best-in-class models with language, vision and image generation capabilities, tailored for Japan and its culture.

 Model merging is a recent development in the open LLM community to merge multiple LLMs into a single new LLM (bigger or same size).
Model merging is a recent development in the open LLM community to merge multiple LLMs into a single new LLM (bigger or same size).  Merging doesn’t require additional training, but it is not fully clear why it works. A new paper from Sakana AI, “Evolutionary Optimization of Model Merging Recipes” applies evolutionary algorithms to automate model merging.
Merging doesn’t require additional training, but it is not fully clear why it works. A new paper from Sakana AI, “Evolutionary Optimization of Model Merging Recipes” applies evolutionary algorithms to automate model merging. Select a diverse set of open LLMs with distinct capabilities relevant to the desired combined functionality (e.g., language understanding and math reasoning).
Select a diverse set of open LLMs with distinct capabilities relevant to the desired combined functionality (e.g., language understanding and math reasoning). Define Configuration Spaces - parameter space (for weight mixing) and data flow space (layer stacking & layout).
Define Configuration Spaces - parameter space (for weight mixing) and data flow space (layer stacking & layout). Apply Evolutionary Algorithms (CMA-ES) to explore both configuration spaces individually, e.g. merge weights from different models with TIES-Merging or DARE and arrange layers with NSGA-II
Apply Evolutionary Algorithms (CMA-ES) to explore both configuration spaces individually, e.g. merge weights from different models with TIES-Merging or DARE and arrange layers with NSGA-II After optimizing in both spaces separately, merge models using the best strategies and evaluate them on relevant benchmarks
After optimizing in both spaces separately, merge models using the best strategies and evaluate them on relevant benchmarks Repeat until you find the best combination
Repeat until you find the best combination Evolved LLM (7B) achieved 52.0%, outperforming individual models (9.6%-30.0%).
Evolved LLM (7B) achieved 52.0%, outperforming individual models (9.6%-30.0%). Possible to cross-domain merge (e.g., language and math, language and vision)
Possible to cross-domain merge (e.g., language and math, language and vision) The evolved VLM outperforms source VLM by ~5%
The evolved VLM outperforms source VLM by ~5% Only the evaluation code released, not how CMA-ES was used
Only the evaluation code released, not how CMA-ES was used





