

Behind the Compute: Benchmarking Compute Solutions — Stability AI
Our commitment to developing cutting-edge open models in multiple modalities necessitates a compute solution capable of handling diverse tasks with efficiency. To this end, we conducted a performance analysis, training two of our models, including the highly anticipated Stable Diffusion 3.
 stability.ai
stability.ai
Behind the Compute: Benchmarking Compute Solutions
11 MarBehind the Compute is a series of blog posts that chronicle elements of our business, offering insights for others to harness the power of generative AI.

In our last installment, we spoke about how we plan to utilize our state-of-the-art AI Supercomputer.
In this installment, we delve deeper into performance benchmarks and benefits of various compute solutions.
Our commitment to developing cutting-edge open models in multiple modalities necessitates a compute solution capable of handling diverse tasks with efficiency. To this end, we conducted a performance analysis, training two of our models, including the highly anticipated Stable Diffusion 3.
In our analysis, we compared the training speed of Intel Gaudi 2 accelerators versus Nvidia's A100 and H100, two of the most common choices for startups and developers training LLMs.
Model 1:
Stable Diffusion 3 is our most capable text-to-image model, soon to be in early preview.
Upon public release of Stable Diffusion 3, it will be available in sizes ranging from 800M to 8B parameters. Our analysis utilized the 2B parameter version and showed pleasantly surprising results.
We measured the training throughput for the 2B Multimodal Diffusion Transformer (MMDiT) architecture model with d=24, BFloat16mixed precision, optimized attention (xFormers for A100 and the FusedSDPA for Intel Gaudi). We call this model version MMDiT-ps2-d24.
First, let’s examine our training benchmark results across 2 nodes, a total of 16 accelerators (Gaudi/GPU). Here’s an excerpt of the raw data:

Keeping the batch size constant at 16 per accelerator, this Gaudi 2 system processed 927 training images per second - 1.5 times faster than the H100-80GB. Even better, we were able to fit a batch size of 32 per accelerator in the Gaudi 2 96GB of High Bandwidth Memory (HBM2E) to further increase the training rate to 1,254 images/sec.
As we scaled up the distributed training to 32 Gaudi 2 nodes (a total of 256 accelerators), we continued to measure very competitive performance:

In this configuration, the Gaudi 2 cluster processed over 3x more images per second, compared to A100-80GB GPUs. This is particularly impressive considering that the A100s have a very optimized software stack.
On inference tests with the Stable Diffusion 3 8B parameter model the Gaudi 2 chips offer inference speed similar to Nvidia A100 chips using base PyTorch. However, with TensorRT optimization, the A100 chips produce images 40% faster than Gaudi 2. We anticipate that with further optimization, Gaudi 2 will soon outperform A100s on this model. In earlier tests on our SDXL model with base PyTorch, Gaudi 2 generates a 1024x1024 image in 30 steps in 3.2 seconds, versus 3.6 seconds for PyTorch on A100s and 2.7 seconds for a generation with TensorRT on an A100.
The higher memory and fast interconnect of Gaudi 2, plus other design considerations, make it competitive to run the Diffusion Transformer architecture that underpins this next generation of media models.
Model 2:
Stable Beluga 2.5 70B is our fine-tuned version of LLaMA 2 70B, building on the Stable Beluga 2 model which was the first open model to best ChatGPT 3.5 in select benchmarks. We ran this training benchmark on 256 Gaudi 2 accelerators. Running our PyTorch code out of the box, with no extra optimizations, we measured an impressive total average throughput of 116,777 tokens/second. More specifically, this involves using a FP16 datatype, a global batch size of 1024, gradient accumulation steps of 2, and micro batch size of 2.
On inference tests with our 70B language model on Gaudi 2, it generates 673 tokens/second per accelerator, using an input token size of 128 and output token size of 2048. In comparison to TensorRT-LLM, Gaudi 2 appears to be 28% faster than the 525 tokens/second for the A100. We also anticipate further speed improvements with FP8.
Companies like ours face an increasing demand for more powerful and efficient computing solutions. Our findings underscore the need for alternatives like the Gaudi 2, which not only offers superior performance to other 7nm chips, but also addresses critical market needs such as affordability, reduced lead times, and superior price-to-performance ratios. Ultimately, the opportunity for choice in computing options broadens participation and innovation, thereby making advanced AI technologies more accessible to all.
Stay tuned for more insights in our next installment of "Behind the Compute."


.png)


/cdn.vox-cdn.com/uploads/chorus_asset/file/23262657/VRG_Illo_STK001_B_Sala_Hacker.jpg)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/23262657/VRG_Illo_STK001_B_Sala_Hacker.jpg "A cartoon illustration shows a shadowy figure carrying off a red directory folder, which has a surprised-looking face on its side.")
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/23262657/VRG_Illo_STK001_B_Sala_Hacker.jpg)
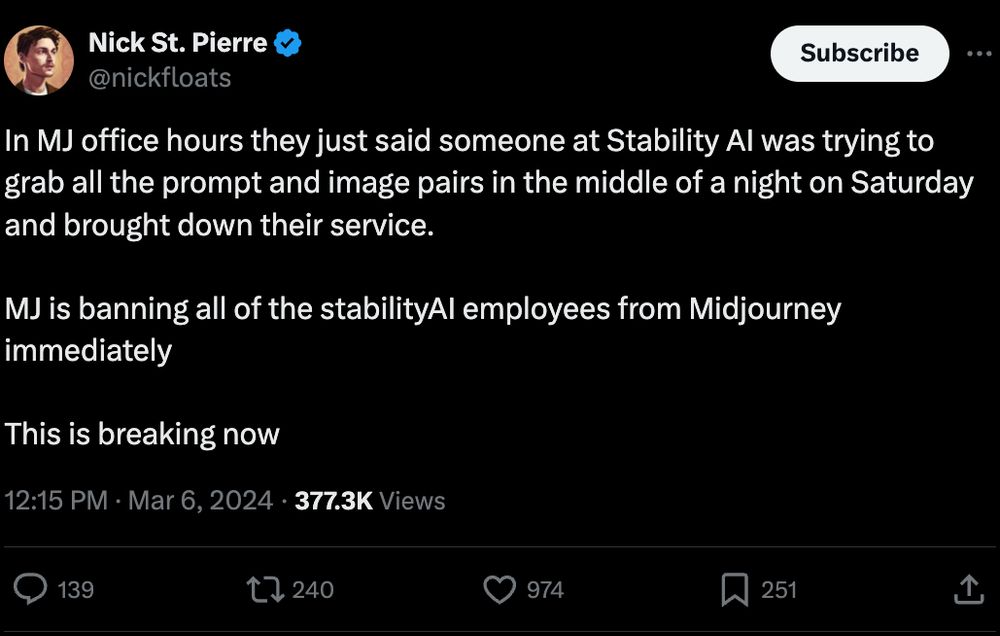
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25330175/Midjourney_office_hours.jpg "A screenshot taken from MidJourney’s Discord channel discussing action against Stability.AI employees.")
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25330175/Midjourney_office_hours.jpg)




















/cdn.vox-cdn.com/uploads/chorus_asset/file/24016885/STK093_Google_04.jpg)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/24016885/STK093_Google_04.jpg "Google logo with colorful shapes")
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/24016885/STK093_Google_04.jpg)
/cdn.vox-cdn.com/uploads/chorus_asset/file/25333634/openai_sora_screen.png)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25333634/openai_sora_screen.png "A screenshot of an AI-generated video produced by Sora")
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25333634/openai_sora_screen.png)
/cdn.vox-cdn.com/uploads/chorus_asset/file/25319789/STK450_EU_E.jpg)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25319789/STK450_EU_E.jpg)