
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?

How much detail is too much? Midjourney v6 attempts to find out
As Midjourney rolls out new features, it continues to make some artists furious.
BENJ EDWARDS - 1/5/2024, 1:41 PM
Enlarge / An AI-generated image of a "Beautiful queen of the universe looking at the camera in sci-fi armor, snow and particles flowing, fire in the background" created using alpha Midjourney v6.
Midjourney
124
In December, just before Christmas, Midjourney launched an alpha version of its latest image synthesis model, Midjourney v6. Over winter break, Midjourney fans put the new AI model through its paces, with the results shared on social media. So far, fans have noted much more detail than v5.2 (the current default) and a different approach to prompting. Version 6 can also handle generating text in a rudimentary way, but it's far from perfect.
FURTHER READING
“Stunning”—Midjourney update wows AI artists with camera-like feature"It's definitely a crazy update, both in good and less good ways," artist Julie Wieland, who frequently shares her Midjourney creations online, told Ars. "The details and scenery are INSANE, the downside (for now) are that the generations are very high contrast and overly saturated (imo). Plus you need to kind of re-adapt and rethink your prompts, working with new structures and now less is kind of more in terms of prompting."
At the same time, critics of the service still bristle about Midjourney training its models using human-made artwork scraped from the web and obtained without permission—a controversial practice common among AI model trainers we have covered in detail in the past. We've also covered the challenges artists might face in the future from these technologies elsewhere.
Too much detail?
With AI-generated detail ramping up dramatically between major Midjourney versions, one could wonder if there is ever such as thing as "too much detail" in an AI-generated image. Midjourney v6 seems to be testing that very question, creating many images that sometimes seem more detailed than reality in an unrealistic way, although that can be modified with careful prompting.Previous Slide Next Slide

- An AI-generated image of Mickey Mouse holding a machine gun created using alpha Midjourney v6.
Midjourney











In our testing of version 6 (which can currently be invoked with the "--v 6.0" argument at the end of a prompt), we noticed times when the new model appeared to produce worse results than v5.2, but Midjourney veterans like Wieland tell Ars that those differences are largely due to the different way that v6.0 interprets prompts. That is something Midjourney is continuously updating over time. "Old prompts sometimes work a bit better than the day they released it," Wieland told us.
 with the prompt a muscular barbarian with weapons beside a CRT television set, cinematic, 8K, studio lighting.")
Enlarge / A comparison between output from Midjourney versions (from left to right: v3, v4, v5, v5.2, v6) with the prompt "a muscular barbarian with weapons beside a CRT television set, cinematic, 8K, studio lighting."
Midjourney
We submitted Version 6 to our usual battery of image synthesis tests: barbarians with CRTs, cats holding cans of beer, plates of pickles, and Abraham Lincoln. Results felt a lot like Midjourney 5.2 but with more intricate detail. Compared to other AI image synthesis models available, Midjourney still seems to be the photorealism champion, although DALL-E 3 and fine-tuned versions of Stable Diffusion XL aren't far behind.
Compared with DALL-E 3, Midjourney v6 arguably bests its photorealism but falls behind in the prompt fidelity category. And yet v6 is notably more capable than v5.2 at handling descriptive prompts. "Version 6 is a bit more 'natural language,' less keywords and the usual prompt mechanics," says Wieland.
 and Midjourney v6 (right).")
Enlarge / An AI-generated comparison of Abraham Lincoln using a computer at his desk using DALL-E 3 (left) and Midjourney v6 (right).
OpenAI, Midjourney
In an announcement on the Midjourney Discord, Midjourney creator David Holz described changes to v6:
Much more accurate prompt following as well as longer prompts
Improved coherence, and model knowledge
Improved image prompting and remix
Minor text drawing ability (you must write your text in "quotations" and --style raw or lower --stylize values may help)
/imagine a photo of the text "Hello World!" written with a marker on a sticky note --ar 16:9 --v 6
Improved upscalers, with both 'subtle' and 'creative' modes (increases resolution by 2x)
(you'll see buttons for these under your images after clicking U1/U2/U3/U4)
Style and prompting for V6
Prompting with V6 is significantly different than V5. You will need to 'relearn' how to prompt.
V6 is MUCH more sensitive to your prompt. Avoid 'junk' like "award winning, photorealistic, 4k, 8k"
Be explicit about what you want. It may be less vibey but if you are explicit it's now MUCH better at understanding you.
If you want something more photographic / less opinionated / more literal you should probably default to using --style raw
Lower values of --stylize (default 100) may have better prompt understanding while higher values (up to 1000) may have better aesthetics
Midjourney v6 is still a work in progress, with Holz announcing that things will change rapidly over the coming months. "DO NOT rely on this exact model being available in the future," he wrote. "It will significantly change as we take V6 to full release." As far as the current limitations go, Wieland says, "I try to keep in mind that this is just v6 alpha and they will do updates without announcements and it kind of feels, like they already did a few updates."
Midjourney is also working on a web interface that will be an alternative to (and potentially a replacement of) the current Discord-only interface. The new interface is expected to widen Midjourney's audience by making it more accessible.
An unresolved controversy
FURTHER READING
From toy to tool: DALL-E 3 is a wake-up call for visual artists—and the rest of usDespite these technical advancements, Midjourney remains highly polarizing and controversial for some people. At the turn of this new year, viral threads emerged on social media from frequent AI art foes, criticizing the service anew. The posts shared screenshots of early conversations among Midjourney developers discussing how the technology could simulate many existing artists' styles. They included lists of artists and styles in the Midjourney training dataset that were revealed in November during discovery in a copyright lawsuit against Midjourney.
Some companies producing AI synthesis models, such as Adobe, seek to avoid these issues by training their models only on licensed images. But Midjourney's strength arguably comes from its ability to play fast and loose with intellectual property. It's undeniably cheaper to grab training data for free online than to license hundreds of millions of images. Until the legality of that kind of scraping is resolved in the US—or Midjourney adopts a different training approach—no matter how detailed or capable Midjourney gets, its ethics will continue to be debated.
Hoshi_Toshi
Superstar
Those midjourney images are scary. Man a lot of layoffs on the horizon

Paper page - LLM Augmented LLMs: Expanding Capabilities through Composition
Join the discussion on this paper page
huggingface.co
LLM Augmented LLMs: Expanding Capabilities through Composition
Published on Jan 4·Featured in Daily Papers on Jan 4
Authors:
Rachit Bansal,
Bidisha Samanta,
Siddharth Dalmia,
Nitish Gupta,
Shikhar Vashishth,
Sriram Ganapathy,
Abhishek Bapna,
Prateek Jain,
Partha Talukdar
Abstract
Foundational models with billions of parameters which have been trained on large corpora of data have demonstrated non-trivial skills in a variety of domains. However, due to their monolithic structure, it is challenging and expensive to augment them or impart new skills. On the other hand, due to their adaptation abilities, several new instances of these models are being trained towards new domains and tasks. In this work, we study the problem of efficient and practical composition of existing foundation models with more specific models to enable newer capabilities. To this end, we propose CALM -- Composition to Augment Language Models -- which introduces cross-attention between models to compose their representations and enable new capabilities. Salient features of CALM are: (i) Scales up LLMs on new tasks by 're-using' existing LLMs along with a few additional parameters and data, (ii) Existing model weights are kept intact, and hence preserves existing capabilities, and (iii) Applies to diverse domains and settings. We illustrate that augmenting PaLM2-S with a smaller model trained on low-resource languages results in an absolute improvement of up to 13\% on tasks like translation into English and arithmetic reasoning for low-resource languages. Similarly, when PaLM2-S is augmented with a code-specific model, we see a relative improvement of 40\% over the base model for code generation and explanation tasks -- on-par with fully fine-tuned counterparts.
Steering at the Frontier: Extending the Power of Prompting - Microsoft Research
We’re seeing exciting capabilities of frontier foundation models, including intriguing powers of abstraction, generalization, and composition across numerous areas of knowledge and expertise. Even seasoned AI researchers have been impressed with the ability to steer the models with...
www.microsoft.com
Microsoft Research Blog
Steering at the Frontier: Extending the Power of Prompting
Published December 12, 2023By Eric Horvitz, Chief Scientific Officer Harsha Nori, Director, Research Engineering Yin Tat Lee, Principal Researcher
Share this page

We’re seeing exciting capabilities of frontier foundation models, including intriguing powers of abstraction, generalization, and composition across numerous areas of knowledge and expertise. Even seasoned AI researchers have been impressed with the ability to steer the models with straightforward, zero-shot prompts. Beyond basic, out-of-the-box prompting, we’ve been exploring new prompting strategies, showcased in our Medprompt work, to evoke the powers of specialists.
Today, we’re sharing information on Medprompt and other approaches to steering frontier models in promptbase(opens in new tab), a collection of resources on GitHub. Our goal is to provide information and tools to engineers and customers to evoke the best performance from foundation models. We’ll start by including scripts that enable replication of our results using the prompting strategies that we present here. We’ll be adding more sophisticated general-purpose tools and information over the coming weeks.
As an illustration of the capabilities of the frontier models and on opportunities to harness and extend the recent efforts with reaching state-of-the-art (SoTA) results via steering GPT-4, we’ll review SoTA results on benchmarks that Google chose for evaluating Gemini Ultra. Our end-to-end exploration, prompt design, and computing of performance took just a couple of days.
MICROSOFT RESEARCH PODCAST

AI Frontiers: The future of causal reasoning with Emre Kiciman and Amit Sharma
Emre Kiciman and Amit Sharma discuss their paper “Causal Reasoning and Large Language Models: Opening a New Frontier for Causality” and how it examines the causal capabilities of large language models (LLMs) and their implications.Listen now
Opens in a new tab
Let’s focus on the well-known MMLU(opens in new tab) (Measuring Massive Multitask Language Understanding) challenge that was established as a test of general knowledge and reasoning powers of large language models. The complete MMLU benchmark contains tens of thousands of challenge problems of different forms across 57 areas from basic mathematics to United States history, law, computer science, engineering, medicine, and more.
In our Medprompt study, we focused on medical challenge problems, but found that the prompt strategy could have more general-purpose application and examined its performance on several out-of-domain benchmarks—despite the roots of the work on medical challenges. Today, we report that steering GPT-4 with a modified version of Medprompt achieves the highest score ever achieved on the complete MMLU.
 achieved 78.4% accuracy, Claude 2 (5-shot CoT) achieved 78.5% accuracy, Inflection-2 (5-shot) achieved 79.6% accuracy, Google Pro (CoT@8) achieved 79.13% accuracy, Gemini Ultra (CoT@32) achieved 90.04% accuracy, GPT-4-1106 (5-Shot) achieved 86.4% accuracy, GPT-4-1106 (Medprompt @ 5) achieved 89.1% accuracy, GPT-4-1106 (Medprompt @ 20) achieved 89.56% accuracy, and GPT-4-1106 (Medprompt @ 31) achieved 90.10% accuracy.")
Figure1. Reported performance of multiple models and methods on the MMLU benchmark.
In our explorations, we initially found that applying the original Medprompt to GPT-4 on the comprehensive MMLU achieved a score of 89.1%. By increasing the number of ensembled calls in Medprompt from five to 20, performance by GPT-4 on the MMLU further increased to 89.56%. To achieve a new SoTA on MMLU, we extended Medprompt to Medprompt+ by adding a simpler prompting method and formulating a policy for deriving a final answer by integrating outputs from both the base Medprompt strategy and the simple prompts. The synthesis of a final answer is guided by a control strategy governed by GPT-4 and inferred confidences of candidate answers. More details on Medprompt+ are provided in the promptbase repo. A related method for coupling complex and simple queries was harnessed by the Google Gemini team. GPT-4 steered with the modified Medprompt+ reaches a record score of 90.10%. We note that Medprompt+ relies on accessing confidence scores (logprobs) from GPT-4. These are not publicly available via the current API but will be enabled for all in the near future.
While systematic prompt engineering can yield maximal performance, we continue to explore the out-of-the-box performance of frontier models with simple prompts. It’s important to keep an eye on the native power of GPT-4 and how we can steer the model with zero- or few-shot prompting strategies. As demonstrated in Table 1, starting with simple prompting is useful to establish baseline performance before layering in more sophisticated and expensive methods.
| Benchmark | GPT-4 Prompt | GPT-4 Results | Gemini Ultra Results |
|---|---|---|---|
| MMLU | Medprompt+ | 90.10% | 90.04% |
| GSM8K | Zero-shot | 95.27% | 94.4% |
| MATH | Zero-shot | 68.42% | 53.2% |
| HumanEval | Zero-shot | 87.8% | 74.4% |
| BIG-Bench-Hard | Few-shot + CoT* | 89.0% | 83.6% |
| DROP | Zero-shot + CoT | 83.7% | 82.4% |
| HellaSwag | 10-shot** | 95.3%** | 87.8% |
* followed the norm of evaluations and used standard few-shot examples from dataset creators
** source: Google
Table 1: Model, strategies, and results
We encourage you to check out the promptbase repo(opens in new tab) on GitHub for more details about prompting techniques and tools. This area of work is evolving with much to learn and share. We’re excited about the directions and possibilities ahead.
GitHub - microsoft/promptbase: All things prompt engineering
All things prompt engineering. Contribute to microsoft/promptbase development by creating an account on GitHub.
 github.com
github.com
About
All things prompt engineeringpromptbase
promptbase is an evolving collection of resources, best practices, and example scripts for eliciting the best performance from foundation models like GPT-4. We currently host scripts demonstrating the Medprompt methodology, including examples of how we further extended this collection of prompting techniques ("Medprompt+") into non-medical domains:| Benchmark | GPT-4 Prompt | GPT-4 Results | Gemini Ultra Results |
|---|---|---|---|
| MMLU | Medprompt+ | 90.10% | 90.04% |
| GSM8K | Zero-shot | 95.3% | 94.4% |
| MATH | Zero-shot | 68.4% | 53.2% |
| HumanEval | Zero-shot | 87.8% | 74.4% |
| BIG-Bench-Hard | Few-shot + CoT | 89.0% | 83.6% |
| DROP | Zero-shot + CoT | 83.7% | 82.4% |
| HellaSwag | 10-shot | 95.3% | 87.8% |
In the near future,
promptbase will also offer further case studies and structured interviews around the scientific process we take behind prompt engineering. We'll also offer specialized deep dives into specialized tooling that accentuates the prompt engineering process. Stay tuned!Medprompt and The Power of Prompting
"Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine" (H. Nori, Y. T. Lee, S. Zhang, D. Carignan, R. Edgar, N. Fusi, N. King, J. Larson, Y. Li, W. Liu, R. Luo, S. M. McKinney, R. O. Ness, H. Poon, T. Qin, N. Usuyama, C. White, E. Horvitz 2023)
In a recent study, we showed how the composition of several prompting strategies into a method that we refer to as
Medprompt can efficiently steer generalist models like GPT-4 to achieve top performance, even when compared to models specifically finetuned for medicine. Medprompt composes three distinct strategies together -- including dynamic few-shot selection, self-generated chain of thought, and choice-shuffle ensembling -- to elicit specialist level performance from GPT-4. We briefly describe these strategies here:

TinyLlama 1.1B powerful small AI model trained on 3 trillion tokens
If you are interested in using and installing TinyLlama 1.1B, a new language model that packs a punch despite its small size. This quick guide will take
 www.geeky-gadgets.com
www.geeky-gadgets.com
Computer Science > Computation and Language
[Submitted on 4 Jan 2024]TinyLlama: An Open-Source Small Language Model
Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, Wei LuWe present TinyLlama, a compact 1.1B language model pretrained on around 1 trillion tokens for approximately 3 epochs. Building on the architecture and tokenizer of Llama 2, TinyLlama leverages various advances contributed by the open-source community (e.g., FlashAttention), achieving better computational efficiency. Despite its relatively small size, TinyLlama demonstrates remarkable performance in a series of downstream tasks. It significantly outperforms existing open-source language models with comparable sizes. Our model checkpoints and code are publicly available on GitHub at this https URL.
| Comments: | Technical Report |
| Subjects: | Computation and Language (cs.CL); Artificial Intelligence (cs.AI) |
| Cite as: | arXiv:2401.02385 [cs.CL] |
| (or arXiv:2401.02385v1 [cs.CL] for this version) | |
| [2401.02385] TinyLlama: An Open-Source Small Language Model Focus to learn more |
Submission history
From: Guangtao Zeng [ view email][v1] Thu, 4 Jan 2024 17:54:59 UTC (1,783 KB)
Abstract
We present TinyLlama, a compact 1.1B language model pretrained on around 1 trillion tokens for approximately 3 epochs. Building on the architecture and tokenizer of Llama 2 ( Touvron et al., 2023b,), TinyLlama leverages various advances contributed by the open-source community (e.g., FlashAttention (Dao,, 2023)), achieving better computational efficiency. Despite its relatively small size, TinyLlama demonstrates remarkable performance in a series of downstream tasks. It significantly outperforms existing open-source language models with comparable sizes. Our model checkpoints and code are publicly available on GitHub at GitHub - jzhang38/TinyLlama: The TinyLlama project is an open endeavor to pretrain a 1.1B Llama model on 3 trillion tokens..
1The first two authors contributed equally.
1The first two authors contributed equally.
1Introduction
Recent progress in natural language processing (NLP) has been largely propelled by scaling up language model sizes (Brown et al.,, 2020; Chowdhery et al.,, 2022; Touvron et al., 2023a,; Touvron et al., 2023b,). Large Language Models (LLMs) pre-trained on extensive text corpora have demonstrated their effectiveness on a wide range of tasks (OpenAI,, 2023; Touvron et al., 2023b,). Some empirical studies demonstrated emergent abilities in LLMs, abilities that may only manifest in models with a sufficiently large number of parameters, such as few-shot prompting (Brown et al.,, 2020) and chain-of-thought reasoning (Wei et al.,, 2022). Other studies focus on modeling the scaling behavior of LLMs (Kaplan et al.,, 2020; Hoffmann et al.,, 2022). Hoffmann et al., ( 2022) suggest that, to train a compute-optimal model, the size of the model and the amount of training data should be increased at the same rate. This provides a guideline on how to optimally select the model size and allocate the amount of training data when the compute budget is fixed.
Although these works show a clear preference on large models, the potential of training smaller models with larger dataset remains under-explored. Instead of training compute-optimal language models, Touvron et al., 2023a highlight the importance of the inference budget, instead of focusing solely on training compute-optimal language models. Inference-optimal language models aim for optimal performance within specific inference constraints This is achieved by training models with more tokens than what is recommended by the scaling law (Hoffmann et al.,, 2022). Touvron et al., 2023a demonstrates that smaller models, when trained with more data, can match or even outperform their larger counterparts. Also, Thaddée, ( 2023) suggest that existing scaling laws (Hoffmann et al.,, 2022) may not predict accurately in situations where smaller models are trained for longer periods.
Motivated by these new findings, this work focuses on exploring the behavior of smaller models when trained with a significantly larger number of tokens than what is suggested by the scaling law (Hoffmann et al.,, 2022). Specifically, we train a Transformer decoder-only model (Vaswani et al.,, 2017) with 1.1B parameters using approximately 3 trillion tokens. To our knowledge, this is the first attempt to train a model with 1B parameters using such a large amount of data. Following the same architecture and tokenizer as Llama 2 ( Touvron et al., 2023b,), we name our model TinyLlama. TinyLlama shows competitive performance compared to existing open-source language models of similar sizes. Specifically, TinyLlama surpasses both OPT-1.3B (Zhang et al.,, 2022) and Pythia-1.4B (Biderman et al.,, 2023) in various downstream tasks.
Our TinyLlama is open-source, aimed at improving accessibility for researchers in language model research. We believe its excellent performance and compact size make it an attractive platform for researchers and practitioners in language model research.
Although these works show a clear preference on large models, the potential of training smaller models with larger dataset remains under-explored. Instead of training compute-optimal language models, Touvron et al., 2023a highlight the importance of the inference budget, instead of focusing solely on training compute-optimal language models. Inference-optimal language models aim for optimal performance within specific inference constraints This is achieved by training models with more tokens than what is recommended by the scaling law (Hoffmann et al.,, 2022). Touvron et al., 2023a demonstrates that smaller models, when trained with more data, can match or even outperform their larger counterparts. Also, Thaddée, ( 2023) suggest that existing scaling laws (Hoffmann et al.,, 2022) may not predict accurately in situations where smaller models are trained for longer periods.
Motivated by these new findings, this work focuses on exploring the behavior of smaller models when trained with a significantly larger number of tokens than what is suggested by the scaling law (Hoffmann et al.,, 2022). Specifically, we train a Transformer decoder-only model (Vaswani et al.,, 2017) with 1.1B parameters using approximately 3 trillion tokens. To our knowledge, this is the first attempt to train a model with 1B parameters using such a large amount of data. Following the same architecture and tokenizer as Llama 2 ( Touvron et al., 2023b,), we name our model TinyLlama. TinyLlama shows competitive performance compared to existing open-source language models of similar sizes. Specifically, TinyLlama surpasses both OPT-1.3B (Zhang et al.,, 2022) and Pythia-1.4B (Biderman et al.,, 2023) in various downstream tasks.
Our TinyLlama is open-source, aimed at improving accessibility for researchers in language model research. We believe its excellent performance and compact size make it an attractive platform for researchers and practitioners in language model research.
GitHub - jzhang38/TinyLlama: The TinyLlama project is an open endeavor to pretrain a 1.1B Llama model on 3 trillion tokens.
The TinyLlama project is an open endeavor to pretrain a 1.1B Llama model on 3 trillion tokens. - GitHub - jzhang38/TinyLlama: The TinyLlama project is an open endeavor to pretrain a 1.1B Llama mode...
github.com
About
The TinyLlama project is an open endeavor to pretrain a 1.1B Llama model on 3 trillion tokens.TinyLlama-1.1B
The TinyLlama project aims to pretrain a 1.1B Llama model on 3 trillion tokens. With some proper optimization, we can achieve this within a span of "just" 90 days using 16 A100-40G GPUs
 . The training has started on 2023-09-01.
. The training has started on 2023-09-01. We adopted exactly the same architecture and tokenizer as Llama 2. This means TinyLlama can be plugged and played in many open-source projects built upon Llama. Besides, TinyLlama is compact with only 1.1B parameters. This compactness allows it to cater to a multitude of applications demanding a restricted computation and memory footprint.
Transformer-Based Large Language Models Are Not General Learners: A...
Large Language Models (LLMs) have demonstrated remarkable proficiency across diverse tasks, evoking perceptions of ``sparks of Artificial General Intelligence (AGI)". A key question naturally...
Transformer-Based Large Language Models Are Not General Learners: A Universal Circuit Perspective
NeurIPS 2023 Workshop ICBINB Submission15 Authors
Published: 27 Oct 2023, Last Modified: 01 Dec 2023ICBINB 2023EveryoneRevisionsBibTeXKeywords: Large Language Model, Transformer, Universal Circuit
TL;DR: We show Transformer-based large language models are not general learners from a perspective of universal circuits.
Abstract:
Large Language Models (LLMs) have demonstrated remarkable proficiency across diverse tasks, evoking perceptions of ``sparks of Artificial General Intelligence (AGI)". A key question naturally arises: Can foundation models lead to AGI? In this work, we try to answer this question partially by formally considering the capabilities of Transformer-based LLMs (T-LLMs) from the perspective of universal circuits. By investigating the expressive power of realistic T-LLMs as universal circuits, we show that a T-LLM of size poly(n) cannot perform all the basic operators of input length O(poly(logn)). We also demonstrate that a constant-depth-poly(n)-size log-precision T-LLM cannot faithfully execute prompts of complexity n. Our analysis provides a concrete theoretical foundation that T-LLMs can only be universal circuits for limited function classes. In other words, T-LLMs are not general learners. Furthermore, we exhibit that a constant-depth-poly(n)-size log-precision T-LLM can memorize O(poly(n)) instances, which could partially explain the seeming inconsistency between LLMs' empirical successes and our negative results. To the best of our knowledge, our work takes the first step towards analyzing the limitations of T-LLMs as general learners within a rigorous theoretical framework. Our results promote the understanding of LLMs' capabilities and highlight the need for innovative architecture designs beyond Transformers to break current limitations.

TencentARC/LLaMA-Pro-8B-Instruct · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
/cdn.vox-cdn.com/uploads/chorus_asset/file/25203771/Screen_Shot_2024_01_04_at_10.55.35_AM.png)
Google wrote a “Robot Constitution” to make sure its new AI droids won’t kill us
The robot AI system with built-in safety prompts.
Google wrote a ‘Robot Constitution’ to make sure its new AI droids won’t kill us
The data gathering system AutoRT applies safety guardrails inspired by Isaac Asimov’s Three Laws of Robotics.
By Amrita Khalid, one of the authors of audio industry newsletter Hot Pod. Khalid has covered tech, surveillance policy, consumer gadgets, and online communities for more than a decade.
Jan 4, 2024, 4:21 PM EST|11 Comments / 11 New
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25203771/Screen_Shot_2024_01_04_at_10.55.35_AM.png)
Image: Google
The DeepMind robotics team has revealed three new advances that it says will help robots make faster, better, and safer decisions in the wild. One includes a system for gathering training data with a “Robot Constitution” to make sure your robot office assistant can fetch you more printer paper — but without mowing down a human co-worker who happens to be in the way.
Google’s data gathering system, AutoRT, can use a visual language model (VLM) and large language model (LLM) working hand in hand to understand its environment, adapt to unfamiliar settings, and decide on appropriate tasks. The Robot Constitution, which is inspired by Isaac Asimov’s “Three Laws of Robotics,” is described as a set of “safety-focused prompts” instructing the LLM to avoid choosing tasks that involve humans, animals, sharp objects, and even electrical appliances.
For additional safety, DeepMind programmed the robots to stop automatically if the force on its joints goes past a certain threshold and included a physical kill switch human operators can use to deactivate them. Over a period of seven months, Google deployed a fleet of 53 AutoRT robots into four different office buildings and conducted over 77,000 trials. Some robots were controlled remotely by human operators, while others operated either based on a script or completely autonomously using Google’s Robotic Transformer (RT-2) AI learning model.
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25203936/Screen_Shot_2024_01_04_at_11.52.15_AM.png)
AutoRT follows these four steps for each task.
The robots used in the trial look more utilitarian than flashy — equipped with only a camera, robot arm, and mobile base. “For each robot, the system uses a VLM to understand its environment and the objects within sight. Next, an LLM suggests a list of creative tasks that the robot could carry out, such as ‘Place the snack onto the countertop’ and plays the role of decision-maker to select an appropriate task for the robot to carry out,” noted Google in its blog post.
:no_upscale():format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25204049/ezgif.com_optimize.gif)
Image: Google
DeepMind’s other new tech includes SARA-RT, a neural network architecture designed to make the existing Robotic Transformer RT-2 more accurate and faster. It also announced RT-Trajectory, which adds 2D outlines to help robots better perform specific physical tasks, such as wiping down a table.
We still seem to be a very long way from robots that serve drinks and fluff pillows autonomously, but when they’re available, they may have learned from a system like AutoRT.
Shaping the future of advanced robotics
Published
4 JANUARY 2024
Authors
The Google DeepMind Robotics Team

4 JANUARY 2024
Authors
The Google DeepMind Robotics Team
Introducing AutoRT, SARA-RT and RT-Trajectory to improve real-world robot data collection, speed, and generalization
Picture a future in which a simple request to your personal helper robot - “tidy the house” or “cook us a delicious, healthy meal” - is all it takes to get those jobs done. These tasks, straightforward for humans, require a high-level understanding of the world for robots.
Today we’re announcing a suite of advances in robotics research that bring us a step closer to this future. AutoRT, SARA-RT, and RT-Trajectory build on our historic Robotics Transformers work to help robots make decisions faster, and better understand and navigate their environments.
AutoRT: Harnessing large models to better train robots
We introduce AutoRT, a system that harnesses the potential of large foundation models which is critical to creating robots that can understand practical human goals. By collecting more experiential training data – and more diverse data – AutoRT can help scale robotic learning to better train robots for the real world.AutoRT combines large foundation models such as a Large Language Model (LLM) or Visual Language Model (VLM), and a robot control model (RT-1 or RT-2) to create a system that can deploy robots to gather training data in novel environments. AutoRT can simultaneously direct multiple robots, each equipped with a video camera and an end effector, to carry out diverse tasks in a range of settings. For each robot, the system uses a VLM to understand its environment and the objects within sight. Next, an LLM suggests a list of creative tasks that the robot could carry out, such as “Place the snack onto the countertop” and plays the role of decision-maker to select an appropriate task for the robot to carry out.
In extensive real-world evaluations over seven months, the system safely orchestrated as many as 20 robots simultaneously, and up to 52 unique robots in total, in a variety of office buildings, gathering a diverse dataset comprising 77,000 robotic trials across 6,650 unique tasks.
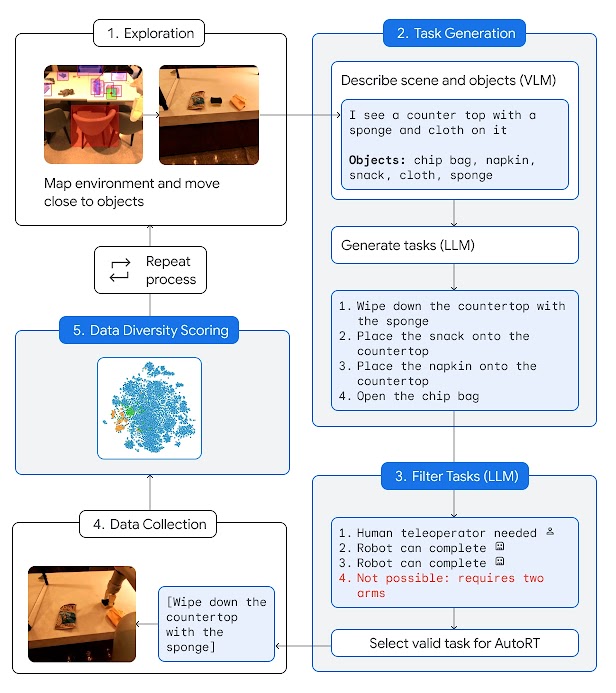
(1) An autonomous wheeled robot finds a location with multiple objects. (2) A VLM describes the scene and objects to an LLM. (3) An LLM suggests diverse manipulation tasks for the robot and decides which tasks the robot could do unassisted, which would require remote control by a human, and which are impossible, before making a choice. (4) The chosen task is attempted, the experiential data collected, and the data scored for its diversity/novelty. Repeat.
Layered safety protocols are critical
Before robots can be integrated into our everyday lives, they need to be developed responsibly with robust research demonstrating their real-world safety.While AutoRT is a data-gathering system, it is also an early demonstration of autonomous robots for real-world use. It features safety guardrails, one of which is providing its LLM-based decision-maker with a Robot Constitution - a set of safety-focused prompts to abide by when selecting tasks for the robots. These rules are in part inspired by Isaac Asimov’s Three Laws of Robotics – first and foremost that a robot “may not injure a human being”. Further safety rules require that no robot attempts tasks involving humans, animals, sharp objects or electrical appliances.
But even if large models are prompted correctly with self-critiquing, this alone cannot guarantee safety. So the AutoRT system comprises layers of practical safety measures from classical robotics. For example, the collaborative robots are programmed to stop automatically if the force on its joints exceed a given threshold, and all active robots were kept in line-of-sight of a human supervisor with a physical deactivation switch.
SARA-RT: Making Robotics Transformers leaner and faster
Our new system, Self-Adaptive Robust Attention for Robotics Transformers (SARA-RT), converts Robotics Transformer (RT) models into more efficient versions.The RT neural network architecture developed by our team is used in the latest robotic control systems, including our state-of-the-art RT-2 model. The best SARA-RT-2 models were 10.6% more accurate and 14% faster than RT-2 models after being provided with a short history of images. We believe this is the first scalable attention mechanism to provide computational improvements with no quality loss.
While transformers are powerful, they can be limited by computational demands that slow their decision-making. Transformers critically rely on attention modules of quadratic complexity. That means if an RT model’s input doubles – by giving a robot additional or higher-resolution sensors, for example – the computational resources required to process that input rise by a factor of four, which can slow decision-making.
SARA-RT makes models more efficient using a novel method of model fine-tuning that we call “up-training”. Up-training converts the quadratic complexity to mere linear complexity, sharply reducing the computational requirements. This conversion not only increases the original model’s speed, but also preserves its quality.
We designed our system for usability and hope many researchers and practitioners will apply it, in robotics and beyond. Because SARA provides a universal recipe for speeding up Transformers, without need for computationally expensive pre-training, this approach has the potential to massively scale up use of Transformers technology. SARA-RT does not require any additional code as various open-sourced linear variants can be used.
When we applied SARA-RT to a state-of-the-art RT-2 model with billions of parameters, it resulted in faster decision-making and better performance on a wide range of robotic tasks.
Play
SARA-RT-2 model for manipulation tasks. Robot’s actions are conditioned on images and text commands.
And with its robust theoretical grounding, SARA-RT can be applied to a wide variety of Transformer models. For example, applying SARA-RT to Point Cloud Transformers - used to process spatial data from robot depth cameras - more than doubled their speed.
RT-Trajectory: Helping robots generalize
It may be intuitive for humans to understand how to wipe a table, but there are many possible ways a robot could translate an instruction into actual physical motions.We developed a model called RT-Trajectory, which automatically adds visual outlines that describe robot motions in training videos. RT-Trajectory takes each video in a training dataset and overlays it with a 2D trajectory sketch of the robot arm’s gripper as it performs the task. These trajectories, in the form of RGB images, provide low-level, practical visual hints to the model as it learns its robot-control policies.
When tested on 41 tasks unseen in the training data, an arm controlled by RT-Trajectory more than doubled the performance of existing state-of-the-art RT models: it achieved a task success rate of 63%, compared with 29% for RT-2.
Traditionally, training a robotic arm relies on mapping abstract natural language (“wipe the table”) to specific movements (close gripper, move left, move right), making it hard for models to generalize to novel tasks. In contrast, an RT-Trajectory model enables RT models to understand "how to do" tasks by interpreting specific robot motions like those contained in videos or sketches.
The system is versatile: RT-Trajectory can also create trajectories by watching human demonstrations of desired tasks, and even accept hand-drawn sketches. And it can be readily adapted to different robot platforms.
Play
Left: A robot, controlled by an RT model trained with a natural-language-only dataset, is stymied when given the novel task: “clean the table”. A robot controlled by RT-Trajectory, trained on the same dataset augmented by 2D trajectories, successfully plans and executes a wiping trajectory
Right: A trained RT-Trajectory model given a novel task (“clean the table”) can create 2D trajectories in a variety of ways, assisted by humans or on its own using a vision-language model.
RT-Trajectory makes use of the rich robotic-motion information that is present in all robot datasets, but currently under-utilized. RT-Trajectory not only represents another step along the road to building robots able to move with efficient accuracy in novel situations, but also unlocking knowledge from existing datasets.
Building the foundations for next-generation robots
By building on the foundation of our state-of-the-art RT-1 and RT-2 models, each of these pieces help create ever more capable and helpful robots. We envision a future in which these models and systems can be integrated to create robots – with the motion generalization of RT-Trajectory, the efficiency of SARA-RT, and the large-scale data collection from models like AutoRT. We will continue to tackle challenges in robotics today and to adapt to the new capabilities and technologies of more advanced robotics.Learn more
AutoRT paper
AutoRT GitHub
SARA-RT paper
SARA-RT website
RT-Trajectory paper
RT-Trajectory GitHub
Access the Open X-Embodiment dataset
AutoRT GitHub
SARA-RT paper
SARA-RT website
RT-Trajectory paper
RT-Trajectory GitHub
Access the Open X-Embodiment dataset
ChatGPT could soon replace Google Assistant on your Android phone
Soon you won't need to open the ChatGPT app to talk to the chatbot on Android, as you'll be able to set it as the default assistant.
ChatGPT could soon replace Google Assistant on your Android phone
Asking ChatGPT a question won’t feel as clunky on Android anymoreBy Mishaal Rahman
•
January 4, 2024
Mishaal Rahman / Android Authority
TL;DR
- If you want to ask ChatGPT a question from your Android phone, you either need to navigate to OpenAI’s website or open their app.
- In contrast, you can easily access Google Assistant from any screen through a gesture or by voice command.
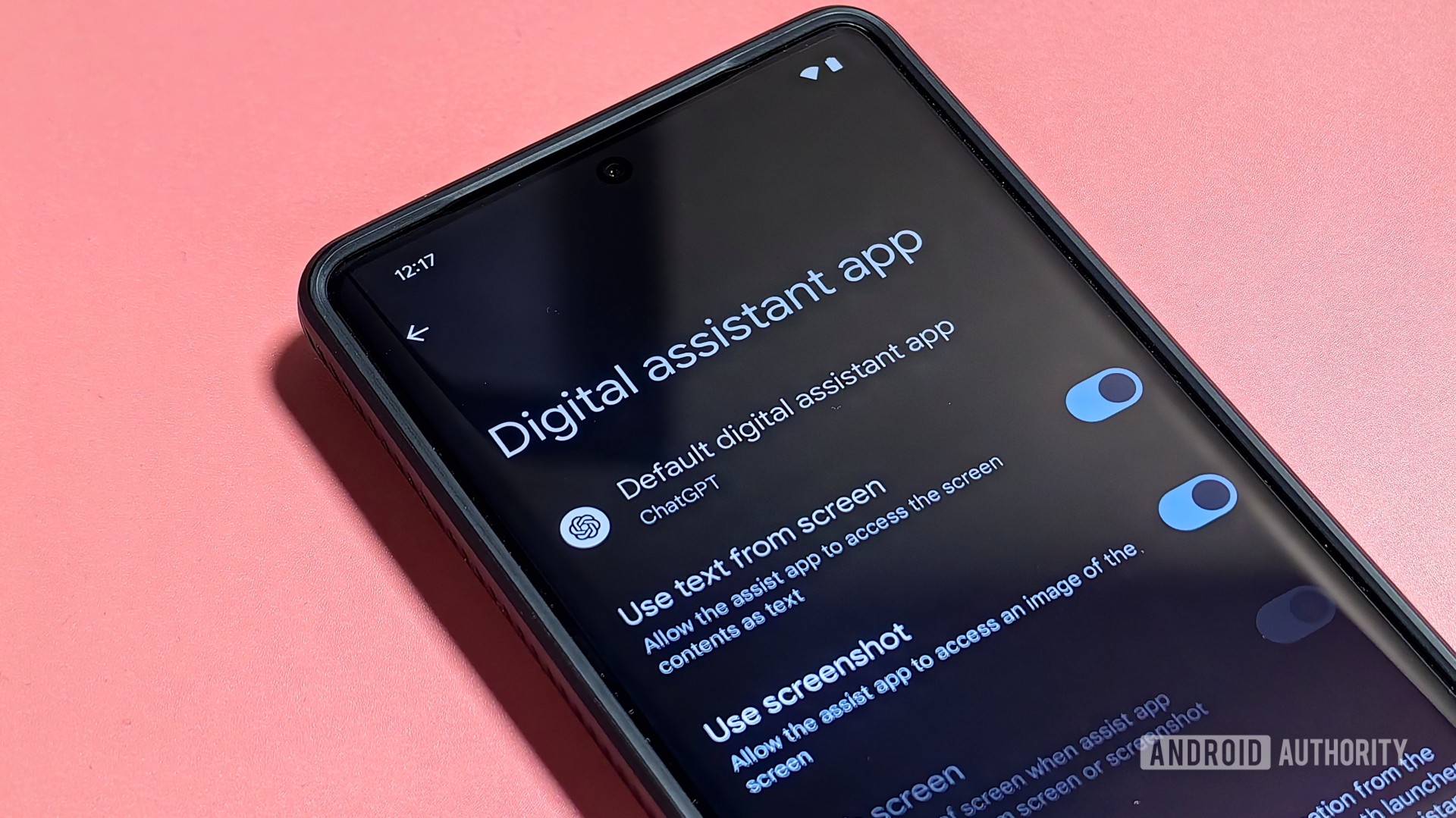
- Code within the ChatGPT app suggests that it’ll be able to become the default digital assistant app, making it easier to talk to the chatbot.
The hottest tech trend of 2023 was generative AI, led by chatbots like OpenAI’s ChatGPT. There are many ways to use ChatGPT on your Android phone, with the easiest being through OpenAI’s official ChatGPT app for Android. Once you open the app, you just need to type or dictate a query and then wait a few seconds for the chatbot to process and come up with a response. After years of bringing up the Google Assistant by using a gesture or by saying a hotword, having to manually launch the ChatGPT app to ask the chatbot a question feels antiquated. Fortunately, it looks like OpenAI is aware of this problem, as code within the latest version of the ChatGPT Android app suggests that you’ll be able to set it as the default assistant app.
An APK teardown helps predict features that may arrive on a service in the future based on work-in-progress code. However, it is possible that such predicted features may not make it to a public release.
ChatGPT version 1.2023.352, released last month, added a new activity named
com.openai.voice.assistant.AssistantActivity. The activity is disabled by default, but after manually enabling and launching it, an overlay appears on the screen with the same swirling animation as the one shown when using the in-app voice chat mode. This overlay appears over other apps and doesn’t take up the entire screen like the in-app voice chat mode. So, presumably, you could talk to ChatGPT from any screen by invoking this assistant.However, in my testing, the animation never finished and the activity promptly closed itself before I could speak with the chatbot. This could either be because the feature isn’t finished yet or is being controlled by some internal flag.
There’s some evidence the feature isn’t fully ready yet, since the code necessary for the app to appear as a “default digital assistant app” is only partially there. The latest version of the app added a XML file named
assistant_interaction_service that contains a voice-interaction-service tag defining the sessionService and recognitionService. The tag also declares that the service supportsAssist. These declarations are part of what’s required for an app to handle being the “default digital assistant app,” but the ChatGPT app is still missing the requisite declarations in its Manifest that let the system know which “service” to bind to. Until that service is defined with the appropriate attributes and metadata tag pointing to the aforementioned XML, then the ChatGPT app can’t be set as a “default digital assistant app”.CODE
Copy Text
<?xml version="1.0" encoding="utf-8"?> <voice-interaction-service android:sessionService="com.openai.voice.assistant.AssistantVoiceInteractionSessionService" android:recognitionService="com.openai.voice.assistant.AssistantVoiceInteractionService" android:supportsAssist="true" xmlns:android="http://schemas.android.com/apk/res/android" />However, the fact that the aforementioned XML file even exists hints that this is what OpenAI intends to do with the app. Making the ChatGPT app Android’s default digital assistant app would enable users to launch it by long-pressing the home button (if using three-button navigation) or swiping up from a bottom corner (if using gesture navigation). Unfortunately, the ChatGPT app still wouldn’t be able to create custom hotwords or respond to existing ones, since that functionality requires access to privileged APIs only available to trusted, preinstalled apps. Still, given that Google will launch Assistant with Bard any day now, it makes sense that OpenAI wants to make it easier for Android users to access ChatGPT so that users don’t flock to Bard just because it’s easier to use.
Speaking of which, OpenAI seems to have another trick up its sleeve to make ChatGPT easier to use on Android. The latest version of the Android app also added a Quick Settings tile, though it’s disabled by default right now. The Quick Settings tile, shown below, seems to be intended as a shortcut to launch ChatGPT’s new assistant mode, based on code within the app. Code also suggests that this feature will require a ChatGPT Plus subscription, though even with an active subscription, we were unable to get either the assistant activity or the Quick Setting tile working.

Mishaal Rahman / Android Authority
If OpenAI ends up announcing these features, we’ll let you know. Would you use ChatGPT more on Android if you could access it as easily as Google Assistant?