
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?If this AI is all powerful as you seem to believe, why then should anybody bother enrolling in college for..why not pull kids out of high-school and let AI do all the work.
A lot of people should not have been going to college for decades now.
Fast Facts: Most common undergraduate fields of study (37)
The NCES Fast Facts Tool provides quick answers to many education questions (National Center for Education Statistics). Get answers on Early Childhood Education, Elementary and Secondary Education and Higher Education here.
nces.ed.gov
Liberal Arts and Business Majors make up the bulk of USELESS college degrees.
But if everyone studied Health and STEM, the wages would go do down.
A lot of people should not have been going to college for decades now.
Fast Facts: Most common undergraduate fields of study (37)
The NCES Fast Facts Tool provides quick answers to many education questions (National Center for Education Statistics). Get answers on Early Childhood Education, Elementary and Secondary Education and Higher Education here.nces.ed.gov
Liberal Arts and Business Majors make up the bulk of USELESS college degrees.
But if everyone studied Health and STEM, the wages would go do down.
I think liberal arts majors might benefit greatly from generative AI. I mean we're talking about pairing very power generative technology with some creative minded people, i'm excited to see what creative people like that can/will create with this stuff.
I think liberal arts majors might benefit greatly from generative AI. I mean we're talking about pairing very power generative technology with some creative minded people, i'm excited to see what creative people like that can/will create with this stuff.
I'd make this distinction.
Liberal Arts =! Artists.
Most folks with Liberal Arts degrees don't explicitly use those degrees for anything.
There's not a big market for people to analyze and critique Toni Morrison.
There might be one guy doing "Hardcore History" but there aren't 300,000.
IMO, Business degrees are is far far worse in terms of "hit the ground running" type skills. But that's a topic for a different post.
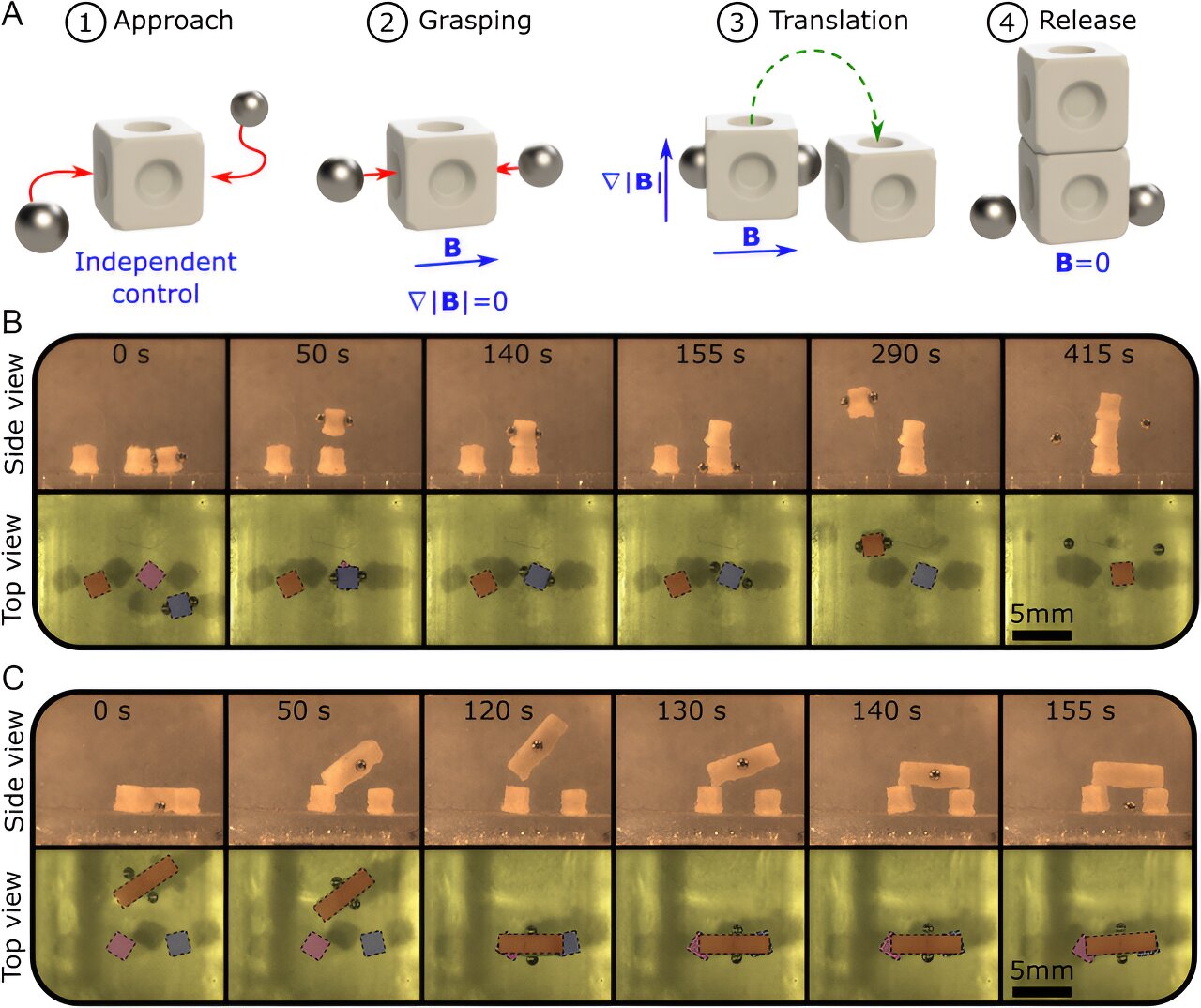
Researchers create magnetic microrobots that work together to assemble objects in 3D environments
For the first time ever, researchers at the Surgical Robotics Laboratory of the University of Twente successfully made two microrobots work together to pick up, move and assemble passive objects in 3D environments. This achievement opens new horizons for promising biomedical applications.
OCTOBER 24, 2023
Editors' notes
Researchers create magnetic microrobots that work together to assemble objects in 3D environments
by K. W. Wesselink-Schram, University of Twente
For the first time ever, researchers at the Surgical Robotics Laboratory of the University of Twente successfully made two microrobots work together to pick up, move and assemble passive objects in 3D environments. This achievement opens new horizons for promising biomedical applications.
Imagine you need surgery somewhere inside your body. However, the part that needs surgery is very difficult for a surgeon to reach. In the future, a couple of robots smaller than a grain of salt might go into your body and perform the surgery. These microrobots could work together to perform all kinds of complex tasks. "It's almost like magic," says Franco Piñan Basualdo, corresponding author of the publication.
Researchers from the University of Twente successfully exploited two of these 1-millimeter-sized magnetic microrobots to perform several operations. Like clockwork, the microrobots were able to pick up, move and assemble cubes. Unique to this achievement is the 3D environment in which the robots performed their tasks.
Achieving this was quite a challenge. Just like regular magnets stick together when they get too close, these tiny magnetic robots behave similarly. This means they have a limit to how close they can get before they start sticking together. But the researchers at the Surgical Robotics Laboratory found a way to use this natural attraction to their advantage. With a custom-made controller, the team could move the individual robots and make them interact with each other.
Credit: University of Twente
The microrobots are biocompatible and can be controlled in difficult-to-reach and even enclosed environments. This makes the technology promising for biomedical studies and applications. "We can remotely manipulate biomedical samples without contaminating them. This could improve existing procedures and open the door to new ones," says Piñan Basualdo.
Piñan Basualdo is a postdoctoral researcher at the Surgical Robotics Laboratory. His research interests include micro-robotics, non-contact control, swarm robotics, active matter, microfluidics, and interfacial phenomena.
This research was performed at the Surgical Robotics Laboratory. Prof. Sarthak Misra, head of the lab, focuses on developing innovative solutions for a broad range of clinically relevant challenges, including biomedical imaging, automation of medical procedures, and the development of microrobotic tools.
The research was performed in the framework of the European RĔGO project (Horizon Europe program), which aims to develop an innovative set of AI-powered, microsized, untethered, stimuli-responsive swarms of robots. The findings were published in a paper titled "Collaborative Magnetic Agents for 3D Microrobotic Grasping," in the journal Advanced Intelligent Systems.
More information: Franco N. Piñan Basualdo et al, Collaborative Magnetic Agents for 3D Microrobotic Grasping, Advanced Intelligent Systems (2023). DOI: 10.1002/aisy.202300365
I'd make this distinction.
Liberal Arts =! Artists.
Most folks with Liberal Arts degrees don't explicitly use those degrees for anything.
There's not a big market for people to analyze and critique Toni Morrison.
There might be one guy doing "Hardcore History" but there aren't 300,000.
IMO, Business degrees are is far far worse in terms of "hit the ground running" type skills. But that's a topic for a different post.
yeah, i know.
Modern usage[edit]
The modern use of the term liberal arts consists of four areas: the natural sciences, social sciences, arts, and humanities. Academic areas that are associated with the term liberal arts include:- Life sciences (biology, ecology, neuroscience)
- Physical science (physics, astronomy, chemistry, geology, physical geography)
- Logic, mathematics, statistics
- Philosophy
- History
- Social science (anthropology, economics, human geography, linguistics, political science, jurisprudence, psychology, and sociology)
- Creative arts (fine arts, music, literature)
Computer Science > Artificial Intelligence
[Submitted on 19 Oct 2023]GPT-4 Doesn't Know It's Wrong: An Analysis of Iterative Prompting for Reasoning Problems
Kaya Stechly, Matthew Marquez, Subbarao KambhampatiThere has been considerable divergence of opinion on the reasoning abilities of Large Language Models (LLMs). While the initial optimism that reasoning might emerge automatically with scale has been tempered thanks to a slew of counterexamples, a wide spread belief in their iterative self-critique capabilities persists. In this paper, we set out to systematically investigate the effectiveness of iterative prompting of LLMs in the context of Graph Coloring, a canonical NP-complete reasoning problem that is related to propositional satisfiability as well as practical problems like scheduling and allocation. We present a principled empirical study of the performance of GPT4 in solving graph coloring instances or verifying the correctness of candidate colorings. In iterative modes, we experiment with the model critiquing its own answers and an external correct reasoner verifying proposed solutions. In both cases, we analyze whether the content of the criticisms actually affects bottom line performance. The study seems to indicate that (i) LLMs are bad at solving graph coloring instances (ii) they are no better at verifying a solution--and thus are not effective in iterative modes with LLMs critiquing LLM-generated solutions (iii) the correctness and content of the criticisms--whether by LLMs or external solvers--seems largely irrelevant to the performance of iterative prompting. We show that the observed increase in effectiveness is largely due to the correct solution being fortuitously present in the top-k completions of the prompt (and being recognized as such by an external verifier). Our results thus call into question claims about the self-critiquing capabilities of state of the art LLMs.
| Comments: | 18 pages, 3 figures |
| Subjects: | Artificial Intelligence (cs.AI) |
| Cite as: | arXiv:2310.12397 [cs.AI] |
| (or arXiv:2310.12397v1 [cs.AI] for this version) | |
| https://doi.org/10.48550/arXiv.2310.12397 Focus to learn more |
Submission history
From: Kaya Stechly [view email][v1] Thu, 19 Oct 2023 00:56:37 UTC (335 KB)
EvalPlus Leaderboard
 evalplus.github.io
evalplus.github.io
 EvalPlus Leaderboard
EvalPlus Leaderboard
EvalPlus evaluates AI Coders with rigorous tests.
Ayumi's LLM Role Play & ERP Ranking
This ranking table contains a rating of different LLMs that tries to determine which model is most suitable for (erotic) role playing (ERP) by using an automated benchmark.3B-7B Models

Run LLMs on Any GPU: GPT4All Universal GPU Support
Nomic AI releases support for edge LLM inference on all AMD, Intel, Samsung, Qualcomm and Nvidia GPU's in GPT4All.


[Long read] Deep dive into AutoGPT: A comprehensive and in-depth step-by-step guide to how it works
Motivation I've recently started experimenting with AI agents and stumbled upon AutoGPT. My curiosity led me to wonder about the mechanisms behind it. To gain a better understanding of AutoGPT's inner workings, I embarked on a journey of practical ex...
 airt.hashnode.dev
airt.hashnode.dev