1/11
We’re presenting the first AI to solve International Mathematical Olympiad problems at a silver medalist level.
It combines AlphaProof, a new breakthrough model for formal reasoning, and AlphaGeometry 2, an improved version of our previous system. AI achieves silver-medal standard solving International Mathematical Olympiad problems
AI achieves silver-medal standard solving International Mathematical Olympiad problems
2/11
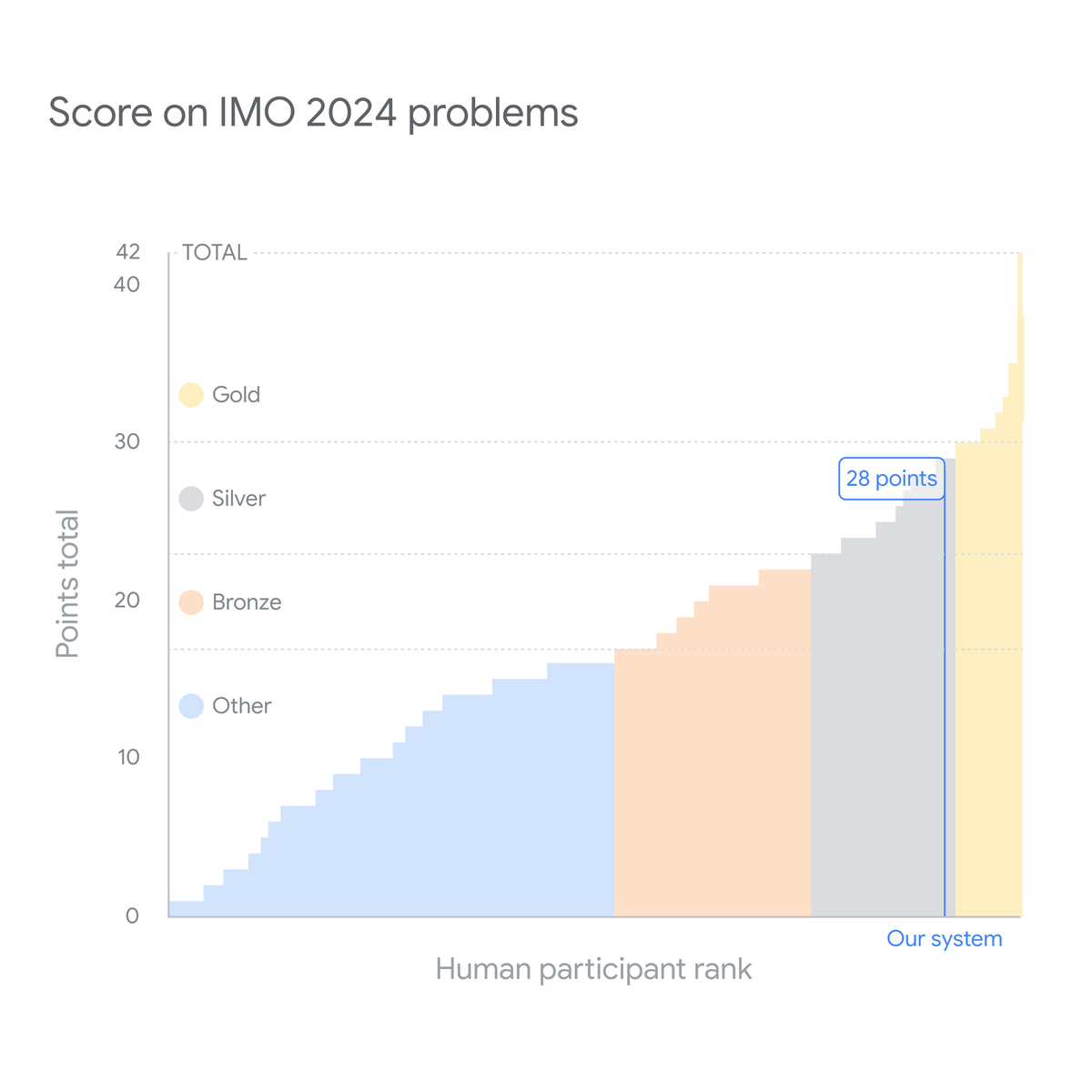
Our system had to solve this year's six IMO problems, involving algebra, combinatorics, geometry & number theory. We then invited mathematicians @wtgowers and Dr Joseph K Myers to oversee scoring.
It solved problems to gain 28 points - equivalent to earning a silver medal. ↓
problems to gain 28 points - equivalent to earning a silver medal. ↓
3/11
For non-geometry, it uses AlphaProof, which can create proofs in Lean.
It couples a pre-trained language model with the AlphaZero reinforcement learning algorithm, which previously taught itself to master games like chess, shogi and Go. AI achieves silver-medal standard solving International Mathematical Olympiad problems
4/11
Math programming languages like Lean allow answers to be formally verified. But their use has been limited by a lack of human-written data available.
So we fine-tuned a Gemini model to translate natural language problems into a set of formal ones for training AlphaProof.
5/11
When presented with a problem, AlphaProof attempts to prove or disprove it by searching over possible steps in Lean.
Each success is then used to reinforce its neural network, making it better at tackling subsequent, harder problems. → AI achieves silver-medal standard solving International Mathematical Olympiad problems
6/11
With geometry, it deploys AlphaGeometry 2: a neuro-symbolic hybrid system.
Its Gemini-based language model was trained on increased synthetic data, enabling it to tackle more types of problems - such as looking at movements of objects.
7/11
Powered with a novel search algorithm, AlphaGeometry 2 can now solve 83% of all historical problems from the past 25 years - compared to the 53% rate by its predecessor.
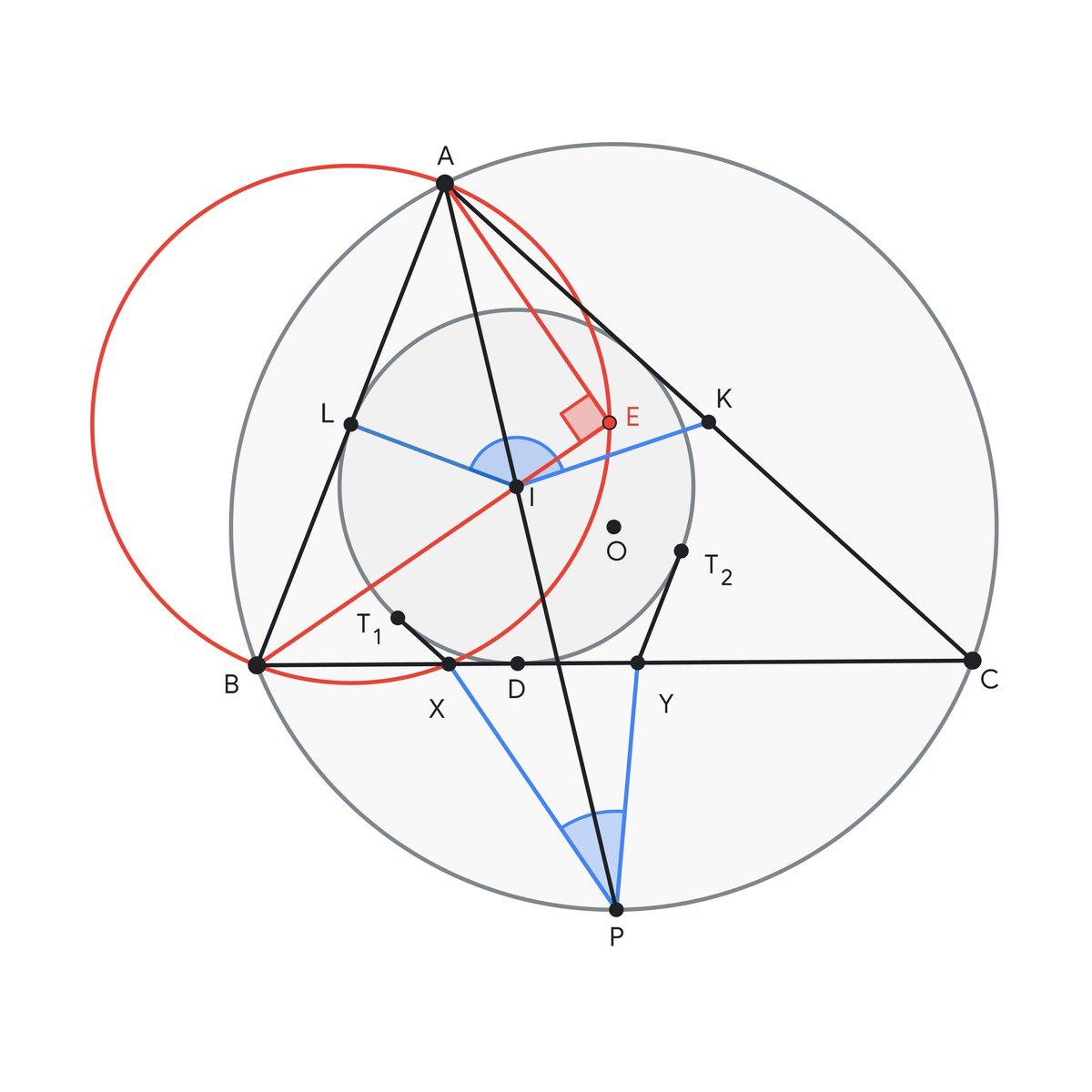
It solved this year’s IMO Problem 4 within 19 seconds.
Here’s an illustration showing its solution ↓
8/11
We’re excited to see how our new system could help accelerate AI-powered mathematics, from quickly completing elements of proofs to eventually discovering new knowledge for us - and unlocking further progress towards AGI.
Find out more → AI achieves silver-medal standard solving International Mathematical Olympiad problems
9/11
thank you for this hard work and thank you for sharing it with the world <3
10/11
That is astonishing
11/11
Amazing. Congrats!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
We’re presenting the first AI to solve International Mathematical Olympiad problems at a silver medalist level.
It combines AlphaProof, a new breakthrough model for formal reasoning, and AlphaGeometry 2, an improved version of our previous system.
AI achieves silver-medal standard solving International Mathematical Olympiad problems2/11
Our system had to solve this year's six IMO problems, involving algebra, combinatorics, geometry & number theory. We then invited mathematicians @wtgowers and Dr Joseph K Myers to oversee scoring.
It solved
problems to gain 28 points - equivalent to earning a silver medal. ↓3/11
For non-geometry, it uses AlphaProof, which can create proofs in Lean.
It couples a pre-trained language model with the AlphaZero reinforcement learning algorithm, which previously taught itself to master games like chess, shogi and Go. AI achieves silver-medal standard solving International Mathematical Olympiad problems
4/11
Math programming languages like Lean allow answers to be formally verified. But their use has been limited by a lack of human-written data available.
So we fine-tuned a Gemini model to translate natural language problems into a set of formal ones for training AlphaProof.
5/11
When presented with a problem, AlphaProof attempts to prove or disprove it by searching over possible steps in Lean.
Each success is then used to reinforce its neural network, making it better at tackling subsequent, harder problems. → AI achieves silver-medal standard solving International Mathematical Olympiad problems
6/11
With geometry, it deploys AlphaGeometry 2: a neuro-symbolic hybrid system.
Its Gemini-based language model was trained on increased synthetic data, enabling it to tackle more types of problems - such as looking at movements of objects.
7/11
Powered with a novel search algorithm, AlphaGeometry 2 can now solve 83% of all historical problems from the past 25 years - compared to the 53% rate by its predecessor.
It solved this year’s IMO Problem 4 within 19 seconds.
Here’s an illustration showing its solution ↓
8/11
We’re excited to see how our new system could help accelerate AI-powered mathematics, from quickly completing elements of proofs to eventually discovering new knowledge for us - and unlocking further progress towards AGI.
Find out more → AI achieves silver-medal standard solving International Mathematical Olympiad problems
9/11
thank you for this hard work and thank you for sharing it with the world <3
10/11
That is astonishing
11/11
Amazing. Congrats!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

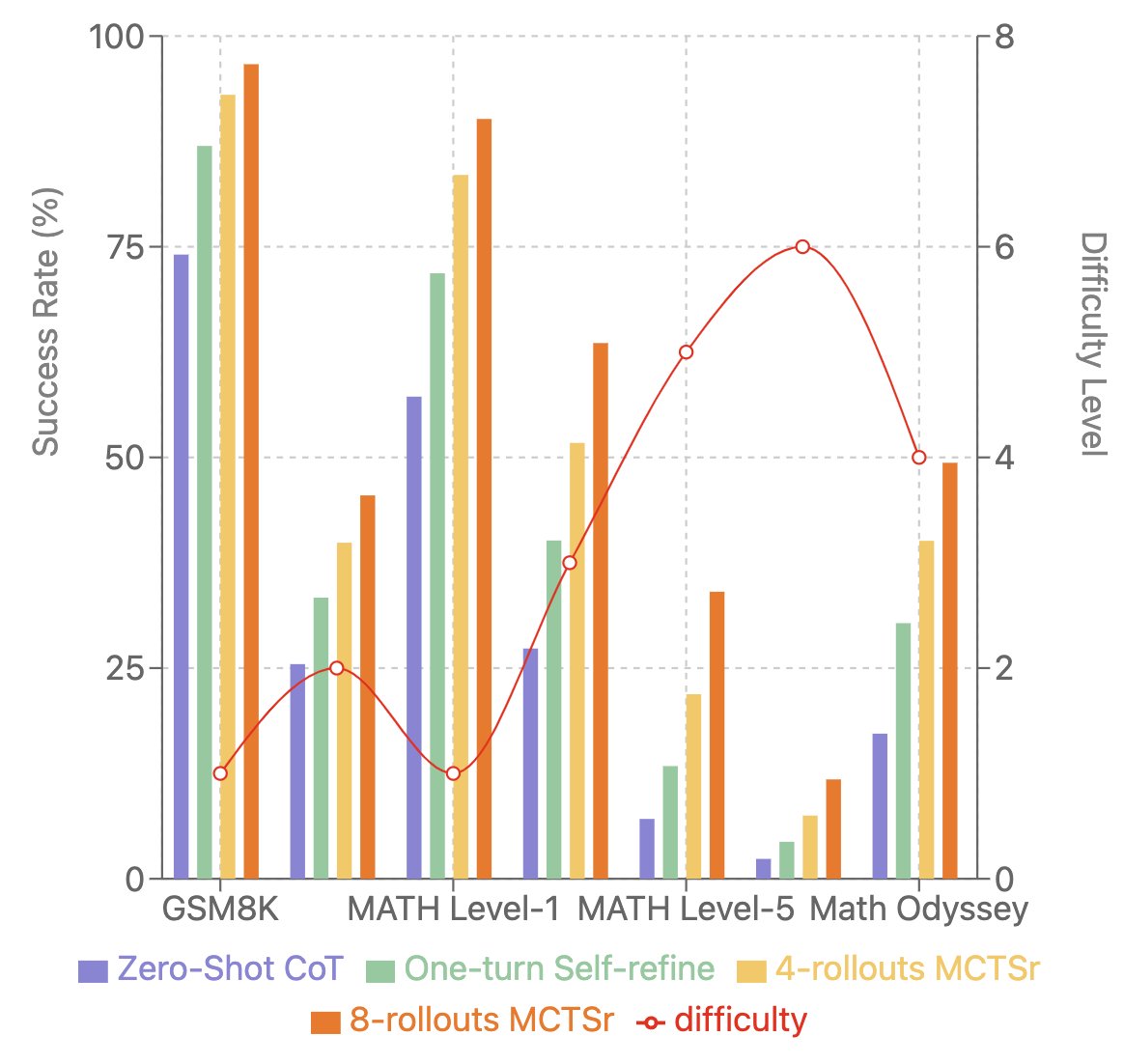
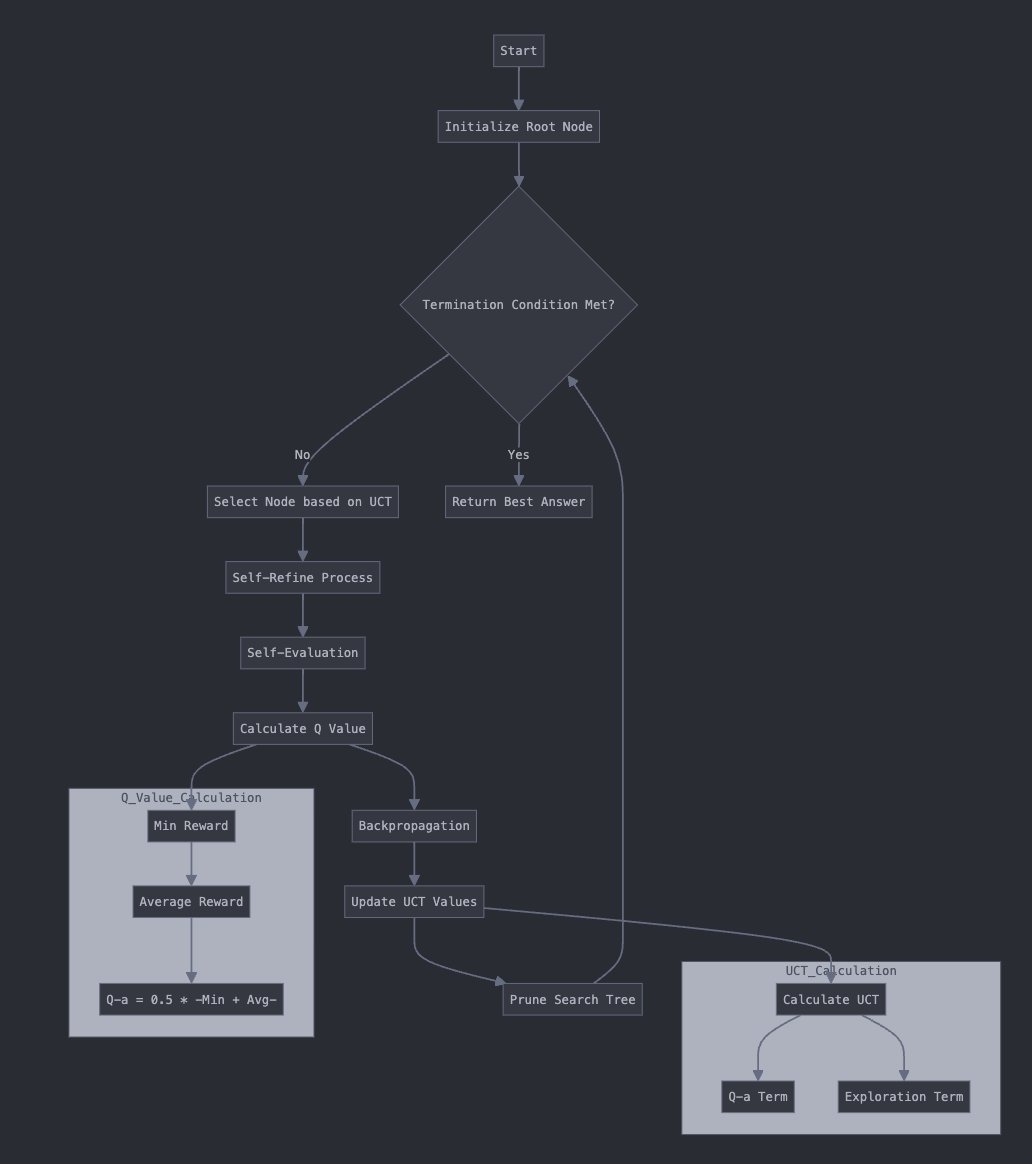

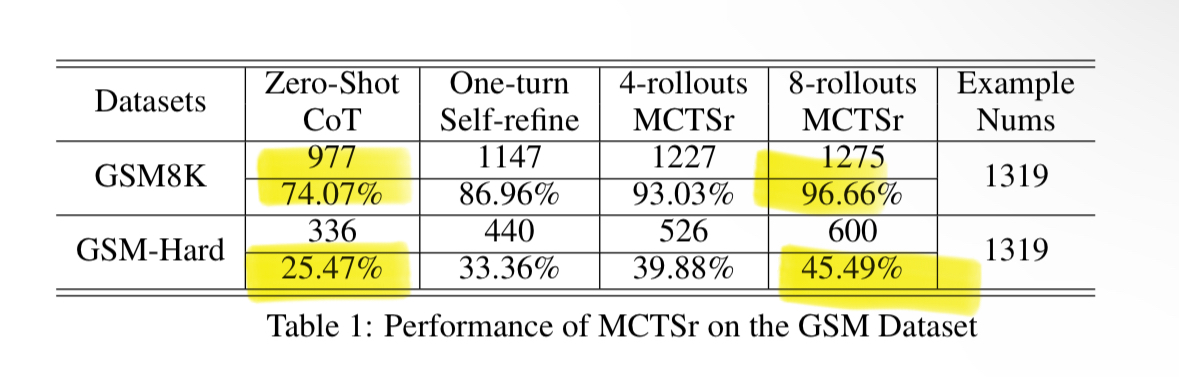

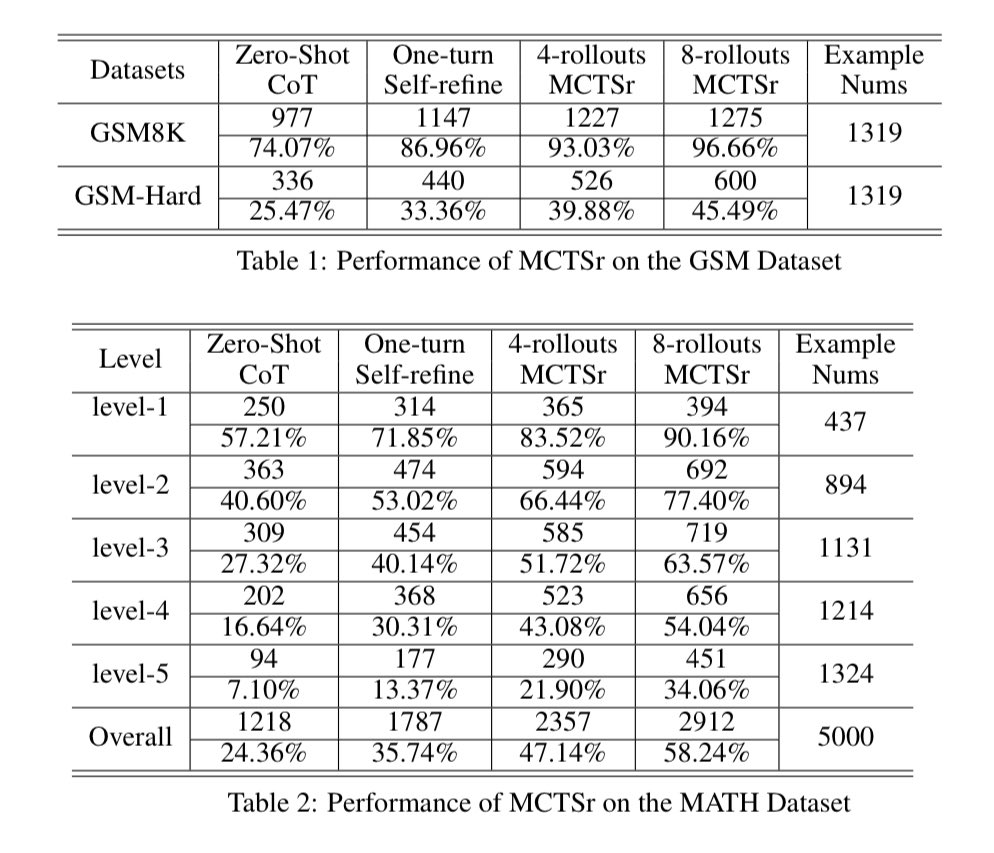
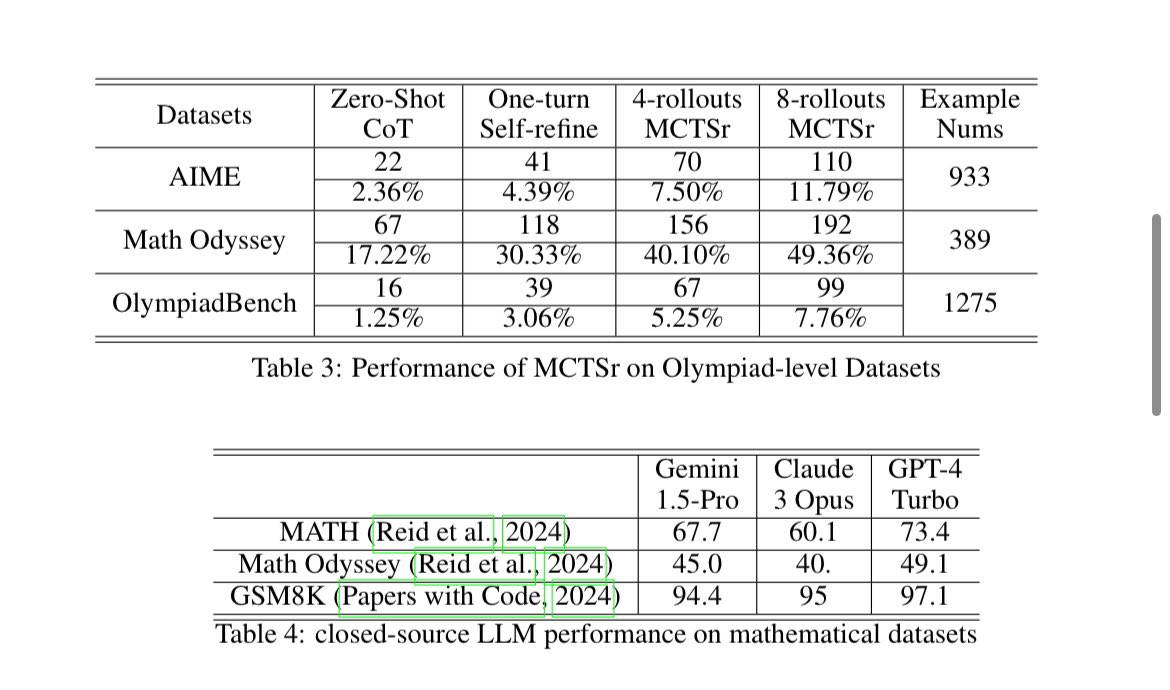
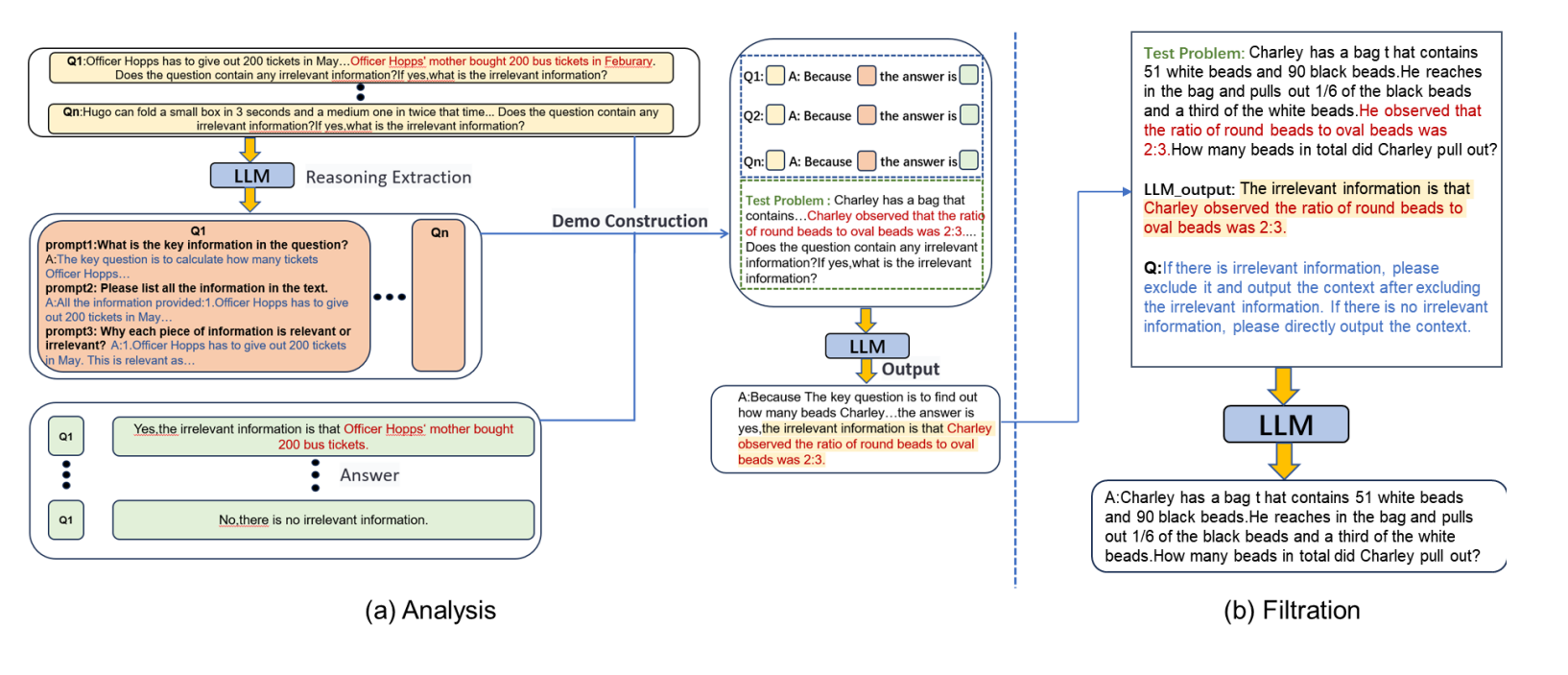
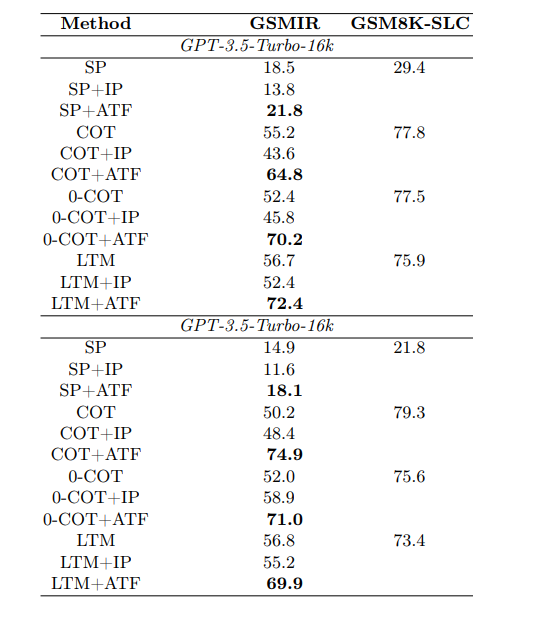
 Read of the day, day 85: Accessing GPT-4 level Mathematical Olympiad Solutions Via Monte Carlo Tree Self-refine with Llama-3 8B: A technical report, by Zhang et al from Shanghai Artificial Intelligence Laboratory
Read of the day, day 85: Accessing GPT-4 level Mathematical Olympiad Solutions Via Monte Carlo Tree Self-refine with Llama-3 8B: A technical report, by Zhang et al from Shanghai Artificial Intelligence Laboratory