Reasoning skills of large language models are often overestimated
MIT CSAIL researchers developed an evaluation framework for large language models about counterfactual tasks. They found that LLMs can recite answers, but struggle to reason as it relates to abstract task-solving.
 news.mit.edu
news.mit.edu
Reasoning skills of large language models are often overestimated
New CSAIL research highlights how LLMs excel in familiar scenarios but struggle in novel ones, questioning their true reasoning abilities versus reliance on memorization.Rachel Gordon | MIT CSAIL
Publication Date:
July 11, 2024
PRESS INQUIRIES

Caption:
MIT researchers examined how LLMs fare with variations of different tasks, putting their memorization and reasoning skills to the test. The result: Their reasoning abilities are often overestimated.
Credits:
Image: Alex Shipps/MIT CSAIL
When it comes to artificial intelligence, appearances can be deceiving. The mystery surrounding the inner workings of large language models (LLMs) stems from their vast size, complex training methods, hard-to-predict behaviors, and elusive interpretability.
MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL) researchers recently peered into the proverbial magnifying glass to examine how LLMs fare with variations of different tasks, revealing intriguing insights into the interplay between memorization and reasoning skills. It turns out that their reasoning abilities are often overestimated.
The study compared “default tasks,” the common tasks a model is trained and tested on, with “counterfactual scenarios,” hypothetical situations deviating from default conditions — which models like GPT-4 and Claude can usually be expected to cope with. The researchers developed some tests outside the models’ comfort zones by tweaking existing tasks instead of creating entirely new ones. They used a variety of datasets and benchmarks specifically tailored to different aspects of the models' capabilities for things like arithmetic, chess, evaluating code, answering logical questions, etc.
When users interact with language models, any arithmetic is usually in base-10, the familiar number base to the models. But observing that they do well on base-10 could give us a false impression of them having strong competency in addition. Logically, if they truly possess good addition skills, you’d expect reliably high performance across all number bases, similar to calculators or computers. Indeed, the research showed that these models are not as robust as many initially think. Their high performance is limited to common task variants and suffer from consistent and severe performance drop in the unfamiliar counterfactual scenarios, indicating a lack of generalizable addition ability.
The pattern held true for many other tasks like musical chord fingering, spatial reasoning, and even chess problems where the starting positions of pieces were slightly altered. While human players are expected to still be able to determine the legality of moves in altered scenarios (given enough time), the models struggled and couldn’t perform better than random guessing, meaning they have limited ability to generalize to unfamiliar situations. And much of their performance on the standard tasks is likely not due to general task abilities, but overfitting to, or directly memorizing from, what they have seen in their training data.
“We’ve uncovered a fascinating aspect of large language models: they excel in familiar scenarios, almost like a well-worn path, but struggle when the terrain gets unfamiliar. This insight is crucial as we strive to enhance these models’ adaptability and broaden their application horizons,” says Zhaofeng Wu, an MIT PhD student in electrical engineering and computer science, CSAIL affiliate, and the lead author on a new paper about the research. “As AI is becoming increasingly ubiquitous in our society, it must reliably handle diverse scenarios, whether familiar or not. We hope these insights will one day inform the design of future LLMs with improved robustness.”
Despite the insights gained, there are, of course, limitations. The study’s focus on specific tasks and settings didn’t capture the full range of challenges the models could potentially encounter in real-world applications, signaling the need for more diverse testing environments. Future work could involve expanding the range of tasks and counterfactual conditions to uncover more potential weaknesses. This could mean looking at more complex and less common scenarios. The team also wants to improve interpretability by creating methods to better comprehend the rationale behind the models’ decision-making processes.
“As language models scale up, understanding their training data becomes increasingly challenging even for open models, let alone proprietary ones,” says Hao Peng, assistant professor at the University of Illinois at Urbana-Champaign. “The community remains puzzled about whether these models genuinely generalize to unseen tasks, or seemingly succeed by memorizing the training data. This paper makes important strides in addressing this question. It constructs a suite of carefully designed counterfactual evaluations, providing fresh insights into the capabilities of state-of-the-art LLMs. It reveals that their ability to solve unseen tasks is perhaps far more limited than anticipated by many. It has the potential to inspire future research towards identifying the failure modes of today’s models and developing better ones.”
Additional authors include Najoung Kim, who is a Boston University assistant professor and Google visiting researcher, and seven CSAIL affiliates: MIT electrical engineering and computer science (EECS) PhD students Linlu Qiu, Alexis Ross, Ekin Akyürek SM ’21, and Boyuan Chen; former postdoc and Apple AI/ML researcher Bailin Wang; and EECS assistant professors Jacob Andreas and Yoon Kim.
The team’s study was supported, in part, by the MIT–IBM Watson AI Lab, the MIT Quest for Intelligence, and the National Science Foundation. The team presented the work at the North American Chapter of the Association for Computational Linguistics (NAACL) last month.

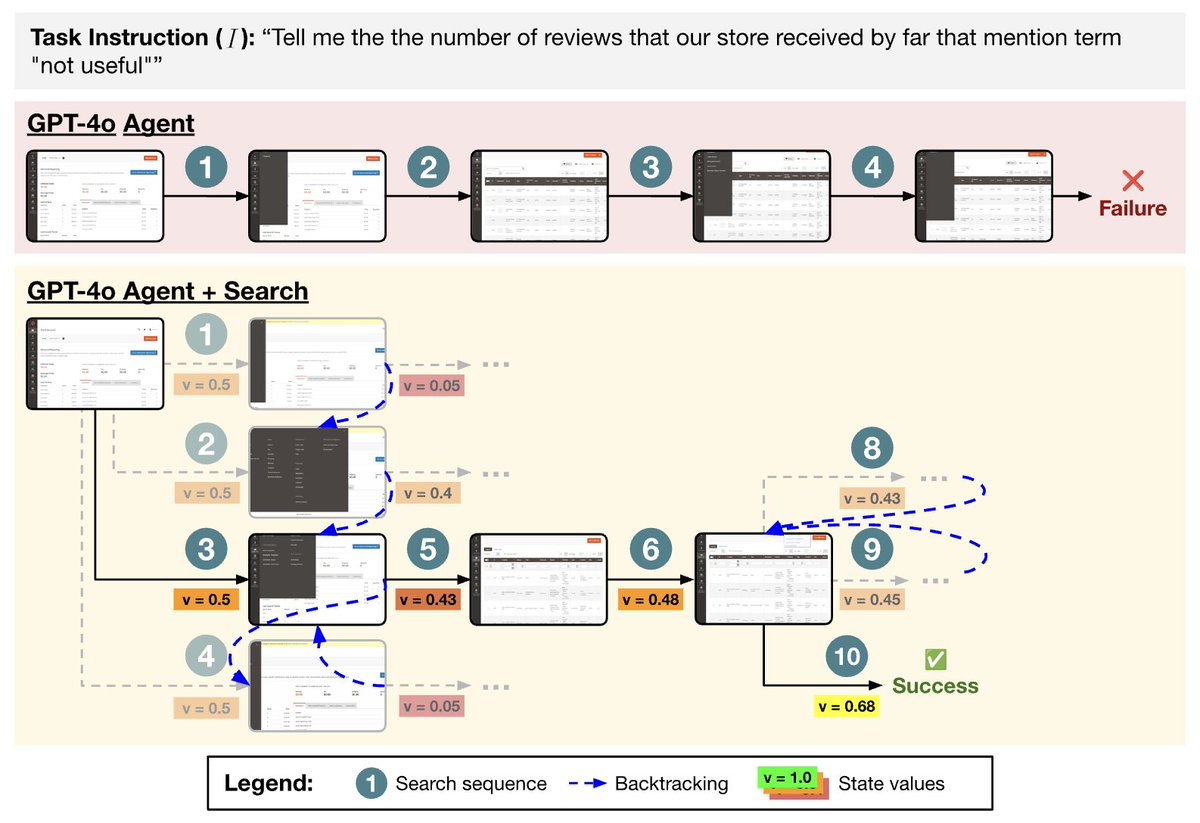
 Tree Search for Language Model Agents
Tree Search for Language Model Agents