
1/11
@GoogleAI
Today we introduce an AI co-scientist system, designed to go beyond deep research tools to aid scientists in generating novel hypotheses & research strategies. Learn more, including how to join the Trusted Tester Program, at Accelerating scientific breakthroughs with an AI co-scientist
https://video.twimg.com/ext_tw_video/1892214105580220417/pu/vid/avc1/830x470/iGQajDvaaMm8a0tN.mp4
2/11
@Chuck_Petras
@BrianRoemmele
3/11
@lmqlai
@LorraineTwohill
@sundarpichai
Googly balling is the heart of cricket! As a cricket fan & a decent googly bowler myself, I thought of creating an AI domain inspired by it.
As a cricket fan & a decent googly bowler myself, I thought of creating an AI domain inspired by it. 
I stumbled upon http://Gogle.ai being available & started developing it—until I realized it might cause confusion.
But hey, brands like BMW vs. BMW Group or Capital One vs. Capital Investment exist without issues! I registered http://Gogle.ai in good faith, rooted in my love for cricket.
Would you be interested in acquiring http://Gogle.ai?
 /search?q=#AI /search?q=#Cricket /search?q=#Googly
/search?q=#AI /search?q=#Cricket /search?q=#Googly
4/11
@pittstony1
@brometheus0x what do you think about this?
5/11
@manninglawrence
Yes, its not just science researcher who make critical discoveries. No different than deep research and everyone should have
6/11
@RRKhanapurkar
Wow
7/11
@geekyabhijit
People got stuck in string theory and quantum gravity for so long hopefully with AI we can move forward or take a different route towards theory of everything
8/11
@laur_science
@GoogleAI That's fascinating! The integration of AI in scientific research could revolutionize how we approach hypothesis generation and strategy development. It reminds me of the potential for cross-disciplinary collaborations, like those between AI systems and environmental science to tackle climate change. Speaking of innovative partnerships, I recently came across a project that combines technology with canine companionship to enhance human well-being—check it out at Bark Raffalo's trulyadog.com.
9/11
@tarrysingh
Amazing
10/11
@anthara_ai
Exciting new tool for research innovation!
11/11
@koltregaskes
Very interesting.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@GoogleAI
Today we introduce an AI co-scientist system, designed to go beyond deep research tools to aid scientists in generating novel hypotheses & research strategies. Learn more, including how to join the Trusted Tester Program, at Accelerating scientific breakthroughs with an AI co-scientist
https://video.twimg.com/ext_tw_video/1892214105580220417/pu/vid/avc1/830x470/iGQajDvaaMm8a0tN.mp4
2/11
@Chuck_Petras
@BrianRoemmele
3/11
@lmqlai
@LorraineTwohill
@sundarpichai
Googly balling is the heart of cricket!
As a cricket fan & a decent googly bowler myself, I thought of creating an AI domain inspired by it. I stumbled upon http://Gogle.ai being available & started developing it—until I realized it might cause confusion.
But hey, brands like BMW vs. BMW Group or Capital One vs. Capital Investment exist without issues! I registered http://Gogle.ai in good faith, rooted in my love for cricket.
Would you be interested in acquiring http://Gogle.ai?
/search?q=#AI /search?q=#Cricket /search?q=#Googly4/11
@pittstony1
@brometheus0x what do you think about this?
5/11
@manninglawrence
Yes, its not just science researcher who make critical discoveries. No different than deep research and everyone should have
6/11
@RRKhanapurkar
Wow
7/11
@geekyabhijit
People got stuck in string theory and quantum gravity for so long hopefully with AI we can move forward or take a different route towards theory of everything
8/11
@laur_science
@GoogleAI That's fascinating! The integration of AI in scientific research could revolutionize how we approach hypothesis generation and strategy development. It reminds me of the potential for cross-disciplinary collaborations, like those between AI systems and environmental science to tackle climate change. Speaking of innovative partnerships, I recently came across a project that combines technology with canine companionship to enhance human well-being—check it out at Bark Raffalo's trulyadog.com.
9/11
@tarrysingh
Amazing
10/11
@anthara_ai
Exciting new tool for research innovation!
11/11
@koltregaskes
Very interesting.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/11
@sundarpichai
Introducing our AI co-scientist, a multi-agent AI system built with Gemini 2.0.
We think of it as a virtual collaborator for scientists, using advanced reasoning to synthesize a huge amount of literature, generate novel hypotheses, and suggest detailed research plans. We’re seeing promising early results in important research areas like liver fibrosis treatments, antimicrobial resistance, and drug repurposing. As a next step, we’re opening up a trusted tester program for scientists around the world.
2/11
@sundarpichai
Accelerating science and discovery is one of the most profound applications of AI and I’m really excited to see where this research will go. More details here: Accelerating scientific breakthroughs with an AI co-scientist
3/11
@howdataworks
@demishassabis, the concept of an AI co-scientist is fascinating! Virtual collaboration can unlock new discoveries. How do you see this technology shaping research in the future? /search?q=#Innovation
/search?q=#Innovation
4/11
@MemeticaAI
These tools can not only be used for doing research, but to spread it aswell. AI Agents help to do that!
5/11
@unkjpeg
na google i use Grook3
6/11
@ArturSchaback
Can i design new clothes with it?
7/11
@photoOrg1
Love it
8/11
@anthara_ai
Exciting advancements in AI research! Looking forward to seeing the impact of this virtual collaborator.
9/11
@joinzo
Multi-agent AI systems will transform scientific research.
10/11
@Siddhar05086147
Out acceleration
11/11
@Arp_it1
The future of collaboration looks intelligent.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@sundarpichai
Introducing our AI co-scientist, a multi-agent AI system built with Gemini 2.0.
We think of it as a virtual collaborator for scientists, using advanced reasoning to synthesize a huge amount of literature, generate novel hypotheses, and suggest detailed research plans. We’re seeing promising early results in important research areas like liver fibrosis treatments, antimicrobial resistance, and drug repurposing. As a next step, we’re opening up a trusted tester program for scientists around the world.
2/11
@sundarpichai
Accelerating science and discovery is one of the most profound applications of AI and I’m really excited to see where this research will go. More details here: Accelerating scientific breakthroughs with an AI co-scientist
3/11
@howdataworks
@demishassabis, the concept of an AI co-scientist is fascinating! Virtual collaboration can unlock new discoveries. How do you see this technology shaping research in the future?
/search?q=#Innovation4/11
@MemeticaAI
These tools can not only be used for doing research, but to spread it aswell. AI Agents help to do that!
5/11
@unkjpeg
na google i use Grook3
6/11
@ArturSchaback
Can i design new clothes with it?
7/11
@photoOrg1
Love it
8/11
@anthara_ai
Exciting advancements in AI research! Looking forward to seeing the impact of this virtual collaborator.
9/11
@joinzo
Multi-agent AI systems will transform scientific research.
10/11
@Siddhar05086147
Out acceleration
11/11
@Arp_it1
The future of collaboration looks intelligent.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/20
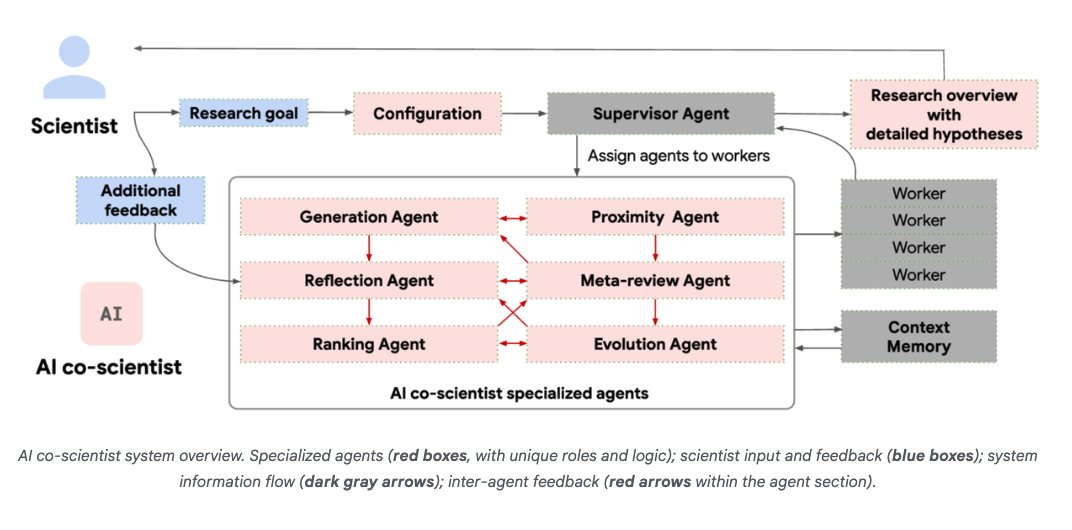
@omarsar0
NEW: Google introduces AI co-scientist.
It's a multi-agent AI system built with Gemini 2.0 to help accelerate scientific breakthroughs.
2025 is truly the year of multi-agents!
Let's break it down:
2/20
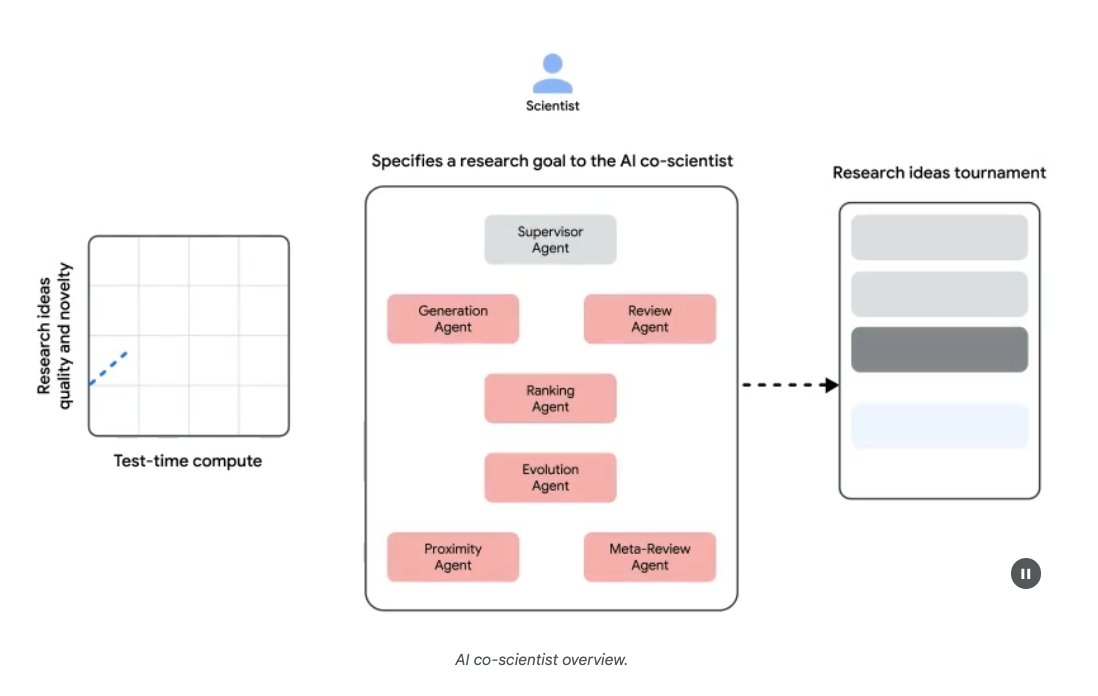
@omarsar0
What's the goal of this AI co-scientist?
It can serve as a "virtual scientific collaborator to help scientists generate novel hypotheses and research proposals, and to accelerate the clock speed of scientific and biomedical discoveries."
3/20
@omarsar0
How is it built?
It uses a coalition of specialized agents inspired by the scientific method.
It can generate, evaluate, and refine hypotheses.
It also has self-improving capabilities.
4/20
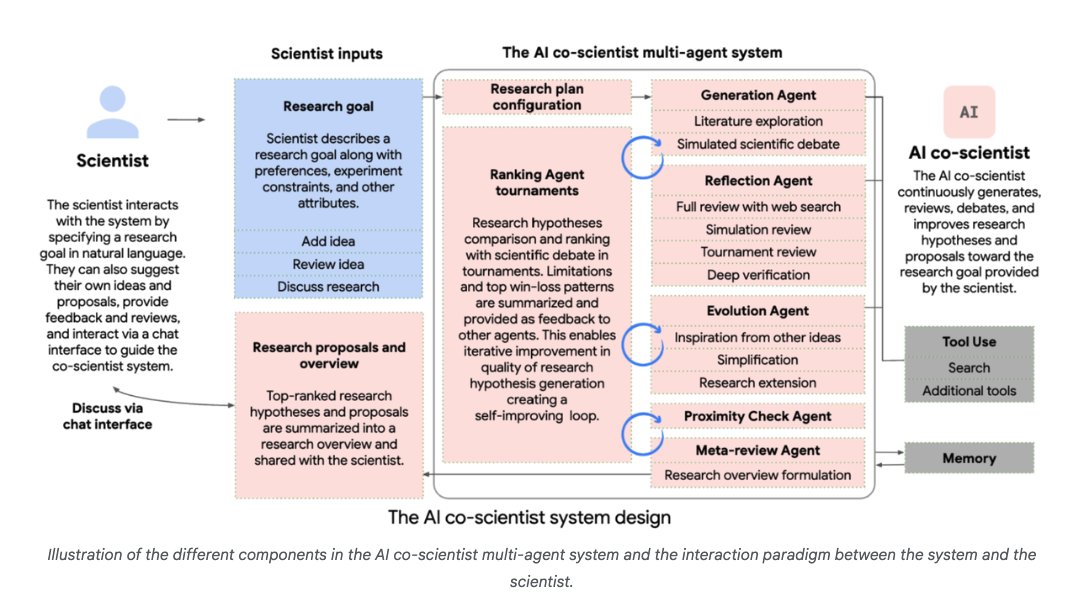
@omarsar0
Collaboration and tools are key!
Scientists can either propose ideas or provide feedback on outputs generated by the agentic system.
Tools like web search and specialized AI models improve the quality of responses.
5/20
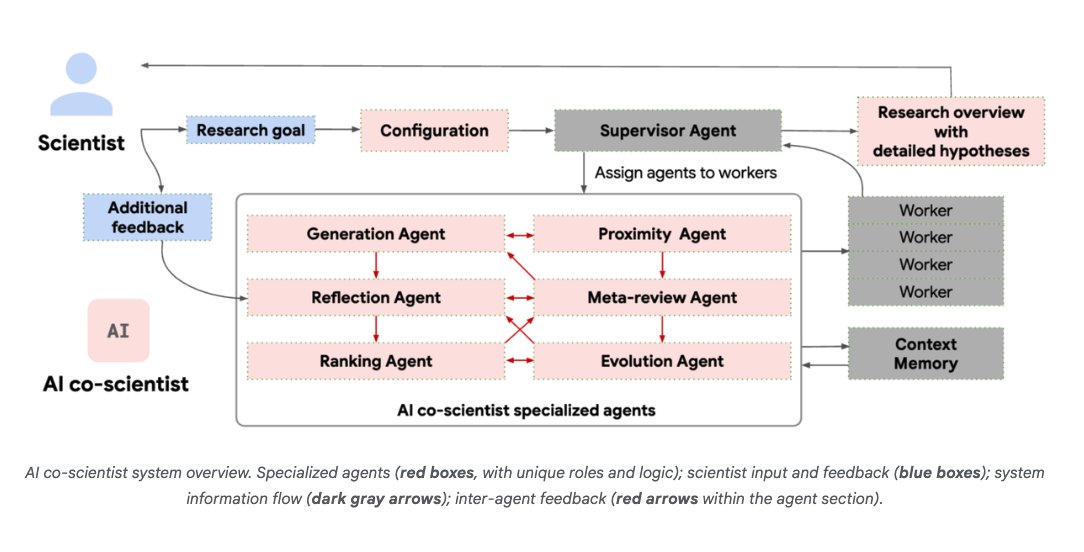
@omarsar0
Hierarchical Multi-Agent System
AI co-scientist is built with a Supervisor agent that assigns tasks to specialized agents.
Apparently, this architecture helps with scaling compute and iteratively improving scientific reasoning.
6/20
@omarsar0
Test-time Compute
AI co-scientist leverages test-time compute scaling to iteratively reason, evolve, and improve outputs.
Self-play, self-critique, and self-improvement are all important to generate and refine hypotheses and proposals.
7/20
@omarsar0
Performance?
Self-improvement relies on the Elo auto-evaluation metric.
On GPQA diamond questions, they found that "higher Elo ratings positively correlate with a higher probability of correct answers."

8/20
@omarsar0
More results:
AI co-scientist outperforms other SoTA agentic and reasoning models for complex problems generated by domain experts.
Just look at how performance increases with more time spent on reasoning, surpassing unassisted human experts.
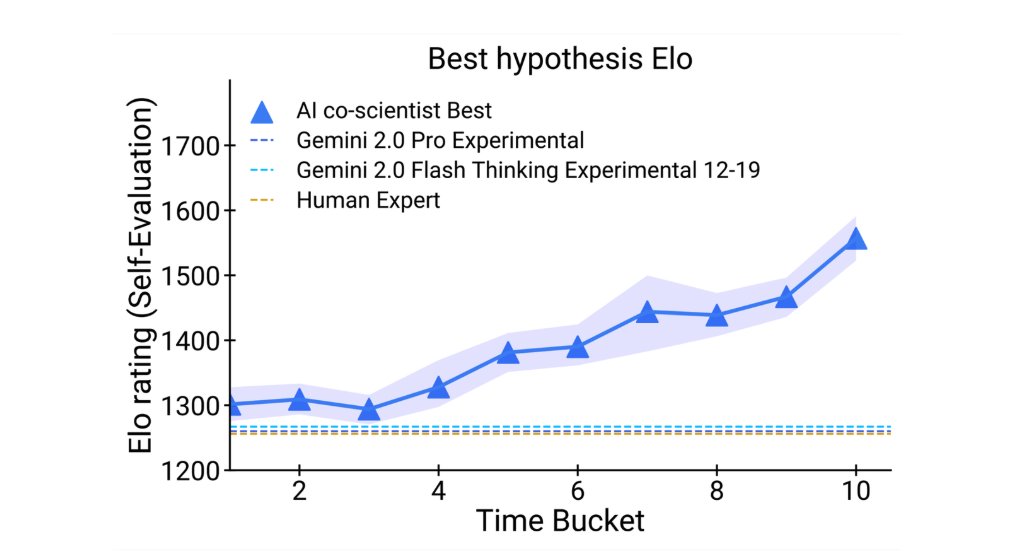
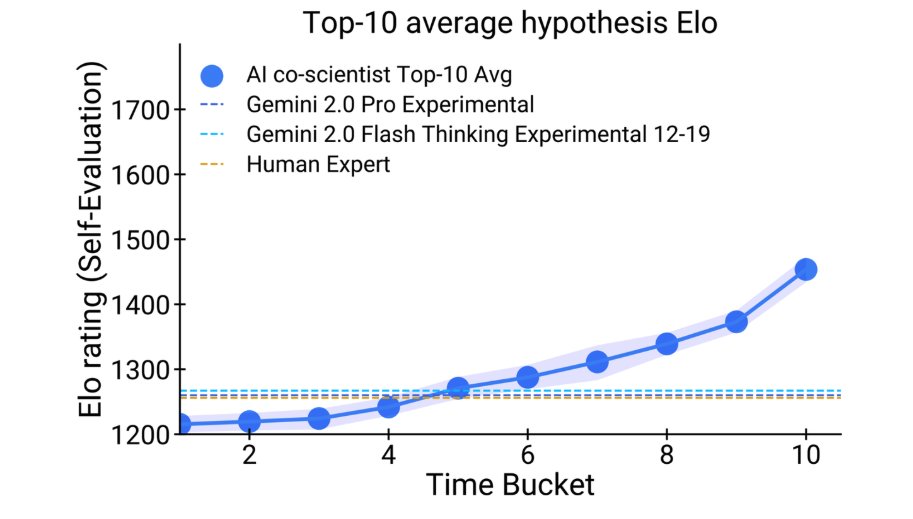
9/20
@omarsar0
How about novelty?
Experts assessed the AI co-scientist to have a higher potential for novelty and impact.
It was even preferred over other models like OpenAI o1.
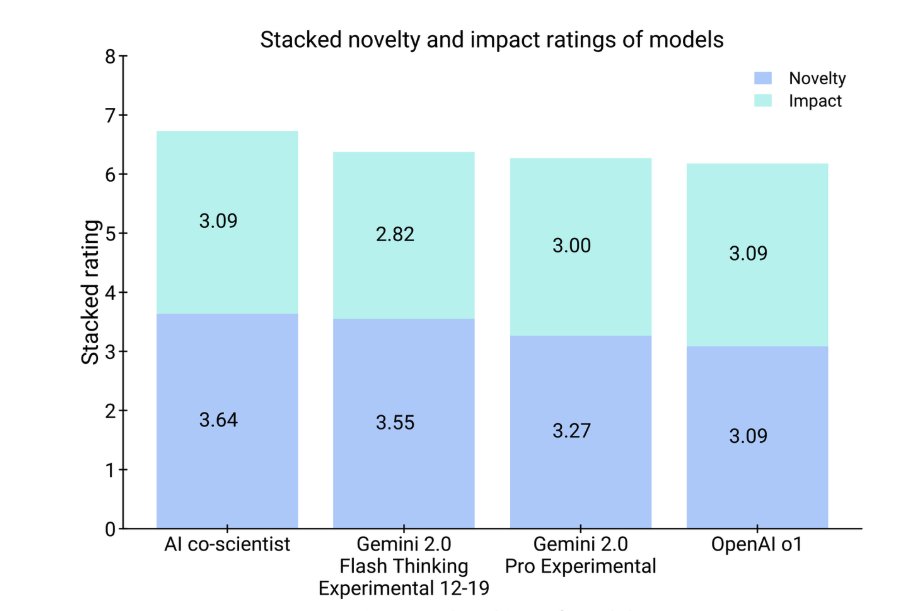
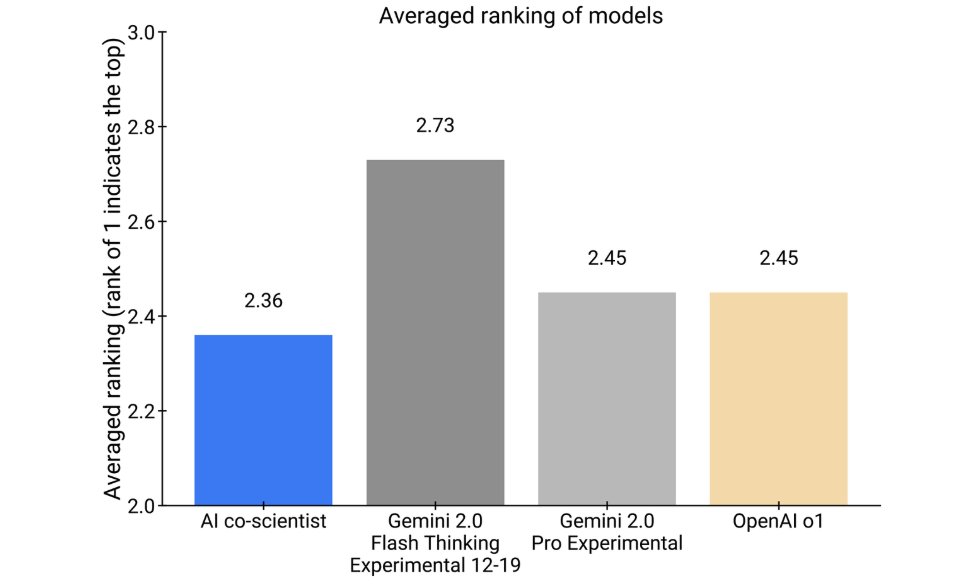
10/20
@omarsar0
Real-world experiments:
"AI co-scientist proposed novel repurposing candidates for acute myeloid leukemia (AML)."
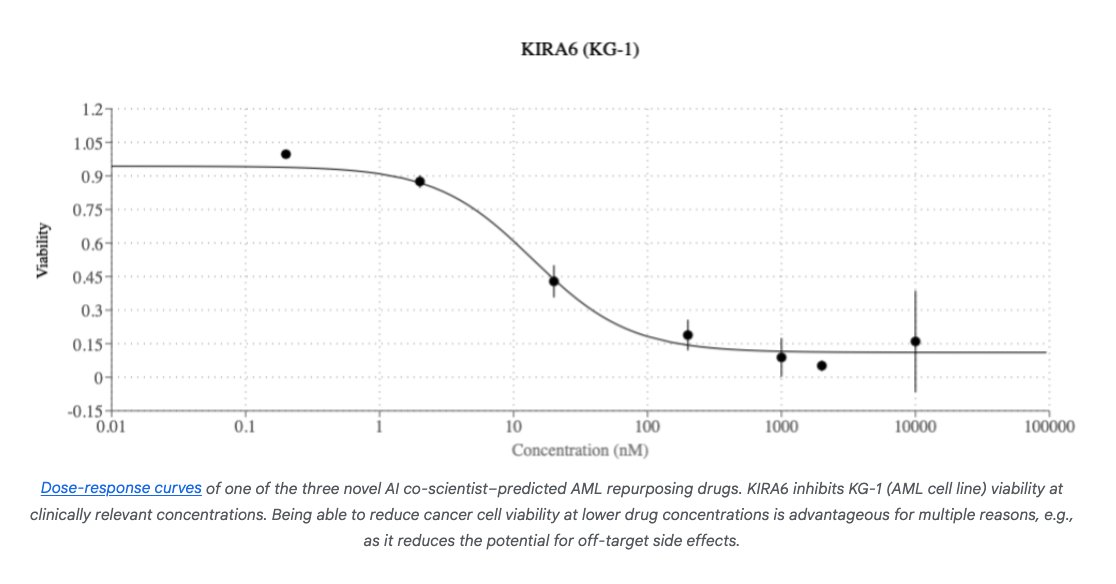
11/20
@omarsar0
There is more:
"AI co-scientist identified epigenetic targets grounded in preclinical evidence with significant anti-fibrotic activity in human hepatic organoids..."
Check out all the results here: Accelerating scientific breakthroughs with an AI co-scientist
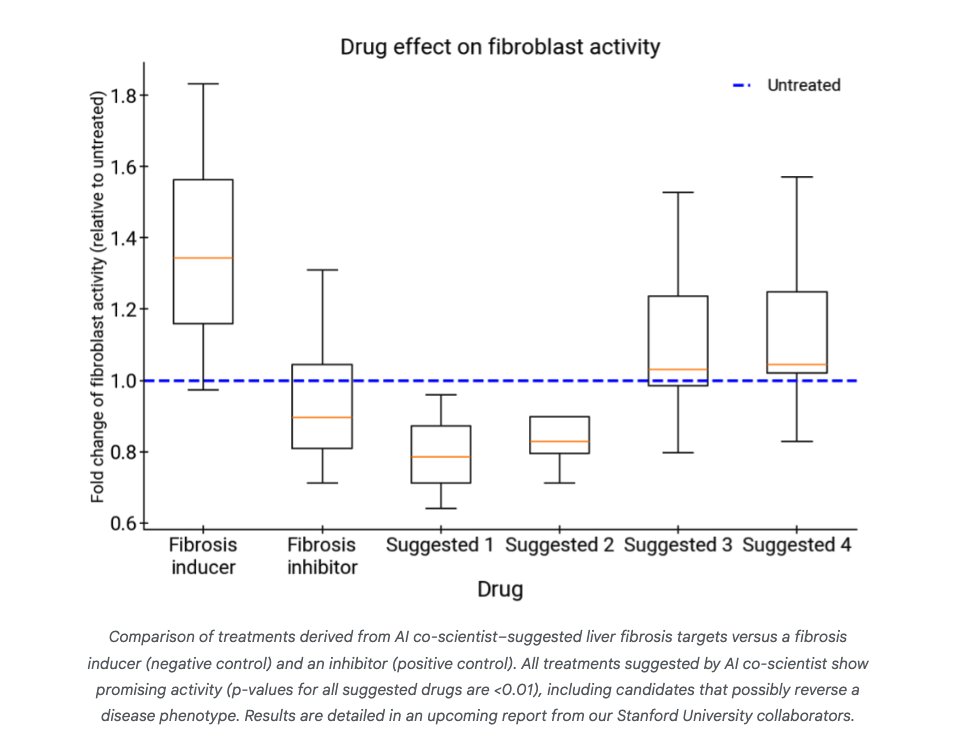
12/20
@leo_grundstrom
AI agents are going to be big!
13/20
@MemeticaAI
AI Agents are going to go big!
14/20
@serenaclou71112
Benefiting from the previous NotebookLM, learning about Gemini, I hope this product will truly assist in scientific research. Wait and see.
15/20
@NaveenP314
Awesome. Thanks for sharing
16/20
@scitechtalk
@threadreaderapp unroll
17/20
@OiiDev
rst @readwise save thread
18/20
@raijin_io
It’s not even March and we’ve seen insane progress in the AI world, 2025 is going to be quite entertaining!
19/20
@MaverickPramit
Nice!
20/20
@abhivendra
Multi-agent systems are reshaping our understanding of collaboration in AI. Google’s AI co-scientist is a significant leap forward, showing how technology can amplify human potential. 2025 is indeed a pivotal year for innovation.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@omarsar0
NEW: Google introduces AI co-scientist.
It's a multi-agent AI system built with Gemini 2.0 to help accelerate scientific breakthroughs.
2025 is truly the year of multi-agents!
Let's break it down:
2/20
@omarsar0
What's the goal of this AI co-scientist?
It can serve as a "virtual scientific collaborator to help scientists generate novel hypotheses and research proposals, and to accelerate the clock speed of scientific and biomedical discoveries."
3/20
@omarsar0
How is it built?
It uses a coalition of specialized agents inspired by the scientific method.
It can generate, evaluate, and refine hypotheses.
It also has self-improving capabilities.
4/20
@omarsar0
Collaboration and tools are key!
Scientists can either propose ideas or provide feedback on outputs generated by the agentic system.
Tools like web search and specialized AI models improve the quality of responses.
5/20
@omarsar0
Hierarchical Multi-Agent System
AI co-scientist is built with a Supervisor agent that assigns tasks to specialized agents.
Apparently, this architecture helps with scaling compute and iteratively improving scientific reasoning.
6/20
@omarsar0
Test-time Compute
AI co-scientist leverages test-time compute scaling to iteratively reason, evolve, and improve outputs.
Self-play, self-critique, and self-improvement are all important to generate and refine hypotheses and proposals.
7/20
@omarsar0
Performance?
Self-improvement relies on the Elo auto-evaluation metric.
On GPQA diamond questions, they found that "higher Elo ratings positively correlate with a higher probability of correct answers."
8/20
@omarsar0
More results:
AI co-scientist outperforms other SoTA agentic and reasoning models for complex problems generated by domain experts.
Just look at how performance increases with more time spent on reasoning, surpassing unassisted human experts.
9/20
@omarsar0
How about novelty?
Experts assessed the AI co-scientist to have a higher potential for novelty and impact.
It was even preferred over other models like OpenAI o1.
10/20
@omarsar0
Real-world experiments:
"AI co-scientist proposed novel repurposing candidates for acute myeloid leukemia (AML)."
11/20
@omarsar0
There is more:
"AI co-scientist identified epigenetic targets grounded in preclinical evidence with significant anti-fibrotic activity in human hepatic organoids..."
Check out all the results here: Accelerating scientific breakthroughs with an AI co-scientist
12/20
@leo_grundstrom
AI agents are going to be big!
13/20
@MemeticaAI
AI Agents are going to go big!
14/20
@serenaclou71112
Benefiting from the previous NotebookLM, learning about Gemini, I hope this product will truly assist in scientific research. Wait and see.
15/20
@NaveenP314
Awesome. Thanks for sharing
16/20
@scitechtalk
@threadreaderapp unroll
17/20
@OiiDev
rst @readwise save thread
18/20
@raijin_io
It’s not even March and we’ve seen insane progress in the AI world, 2025 is going to be quite entertaining!
19/20
@MaverickPramit
Nice!
20/20
@abhivendra
Multi-agent systems are reshaping our understanding of collaboration in AI. Google’s AI co-scientist is a significant leap forward, showing how technology can amplify human potential. 2025 is indeed a pivotal year for innovation.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196












 It’s topped @lmarena_ai's leaderboard by a huge margin
It’s topped @lmarena_ai's leaderboard by a huge margin
 Developers can try it out in Google AI Studio
Developers can try it out in Google AI Studio



 @sundarpichai
@sundarpichai



 All time high scores in MMLU-Pro and GPQA Diamond of 86% and 83% respectively
All time high scores in MMLU-Pro and GPQA Diamond of 86% and 83% respectively Speed: 195 output tokens/s, much faster than Gemini 1.5 Pro’s 92 tokens/s and nearly as fast as Gemini 2.0 Flash’s 253 tokens/s
Speed: 195 output tokens/s, much faster than Gemini 1.5 Pro’s 92 tokens/s and nearly as fast as Gemini 2.0 Flash’s 253 tokens/s
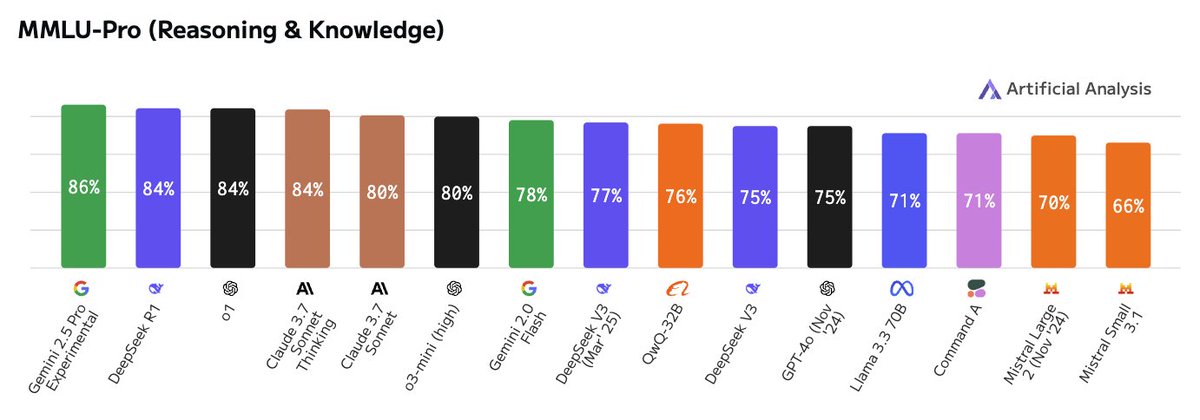






 Such a cool idea to make learning much more fun and interactive.
Such a cool idea to make learning much more fun and interactive.

 , Gemini 2.5 Pro ranked #1
, Gemini 2.5 Pro ranked #1




 leaderboard!
leaderboard!


 Curious to see how it holds up in real-world use
Curious to see how it holds up in real-world use




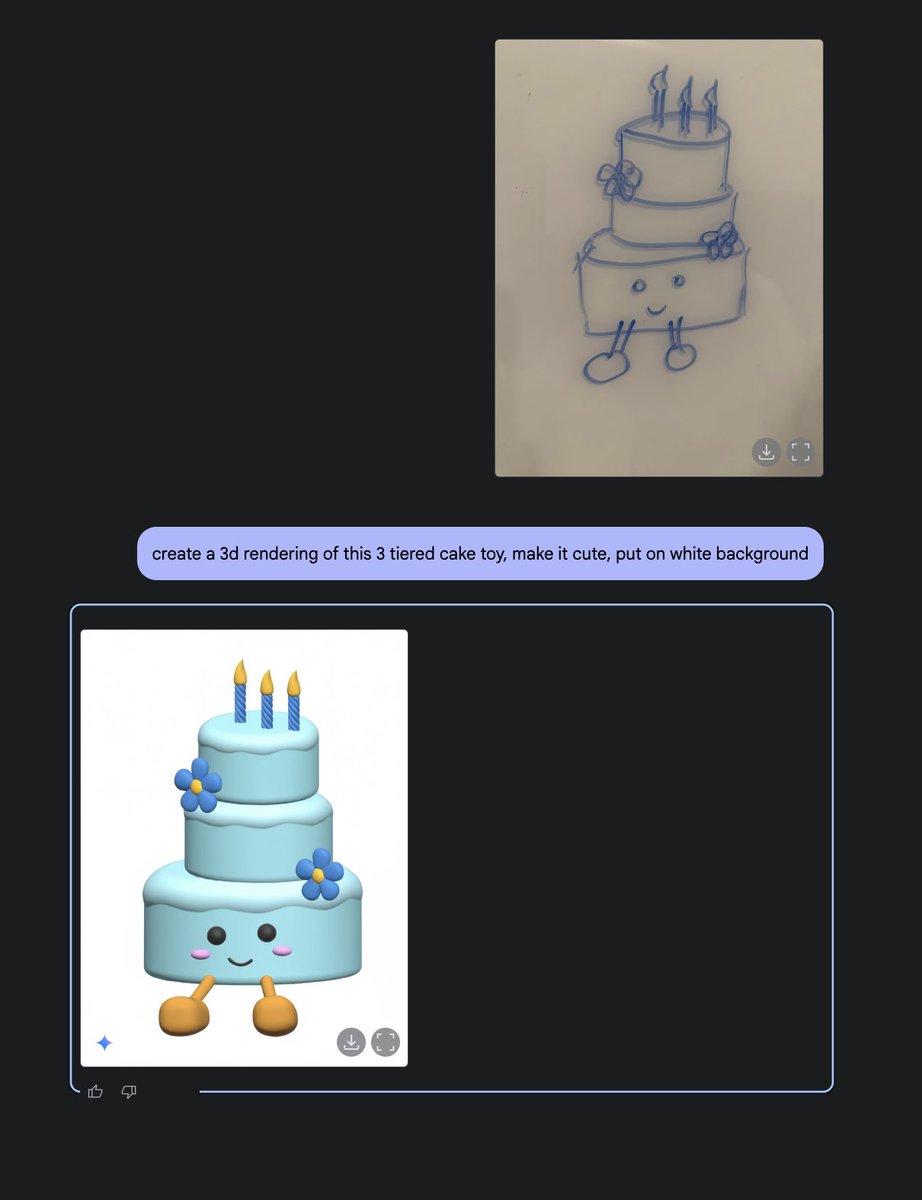







 Please share:
Please share:
 j/k
j/k
 Transformers has hit the scaling wall
Transformers has hit the scaling wall  GPT 4.5 cost billions, with no clear path to AGI for 10x$ more
GPT 4.5 cost billions, with no clear path to AGI for 10x$ more Facebook, Yann LeCun, is now saying we need new architectures
Facebook, Yann LeCun, is now saying we need new architectures Deepmind CEO, Demis Hassabis, is saying we need 10 years
Deepmind CEO, Demis Hassabis, is saying we need 10 years Our roadmap to Personalized AI and AGI
Our roadmap to Personalized AI and AGI
 ️Attention is NOT all you need
️Attention is NOT all you need 

 )
)



 Social, Email, and Wallet Login
Social, Email, and Wallet Login 




