
1/1
@MunchBaby1337
 **ByteDance Unveils Doubao-1.5-pro** /search?q=#db
**ByteDance Unveils Doubao-1.5-pro** /search?q=#db
- **Deep Thinking Mode**: Surpasses O1-preview and O1 on the AIME benchmark.
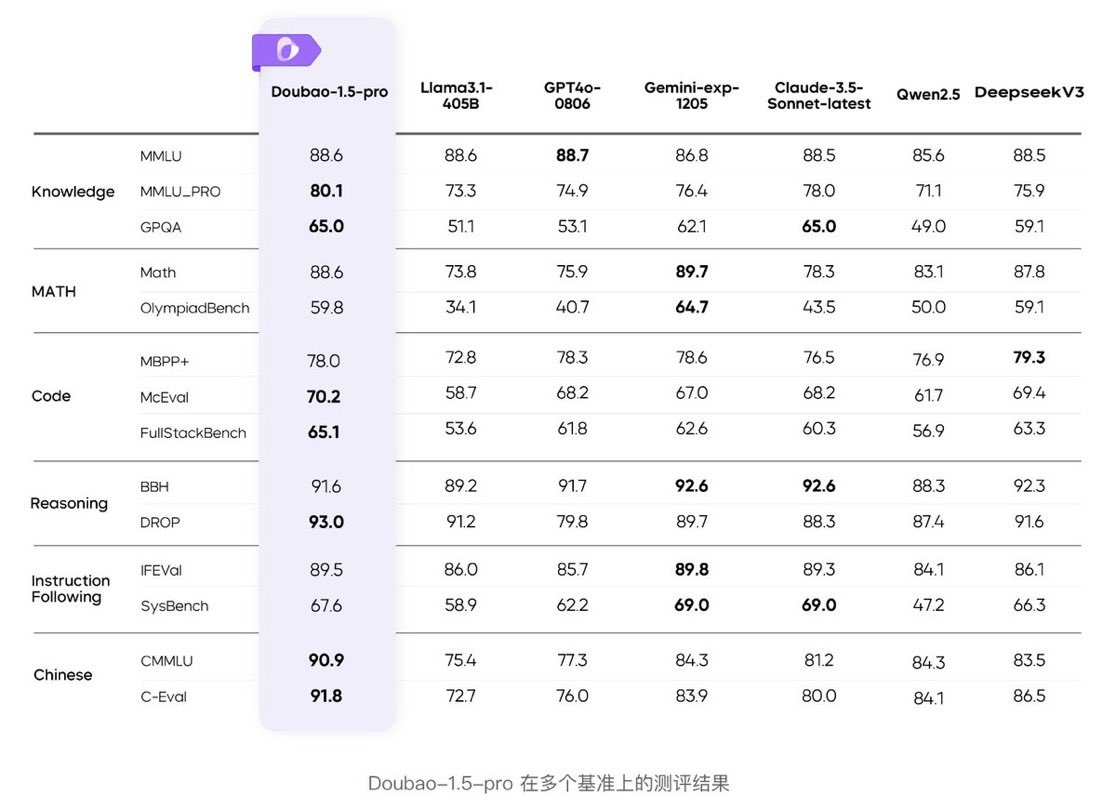
- **Benchmark Beast**: Outperforms deepseek-v3, gpt4o, and llama3.1-405B across multiple benchmarks.
- **MoE Magic**: Utilizes a Mixture of Experts architecture, with significantly fewer active parameters than competitors.
- **Performance Leverage**: Achieves dense model performance with just 1/7 of the parameters (20B active = 140B dense equivalent).
- **Tech Talk**: Employs a heterogeneous system design for prefill-decode and attention-FFN, optimizing throughput with low latency.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@MunchBaby1337
**ByteDance Unveils Doubao-1.5-pro** /search?q=#db- **Deep Thinking Mode**: Surpasses O1-preview and O1 on the AIME benchmark.
- **Benchmark Beast**: Outperforms deepseek-v3, gpt4o, and llama3.1-405B across multiple benchmarks.
- **MoE Magic**: Utilizes a Mixture of Experts architecture, with significantly fewer active parameters than competitors.
- **Performance Leverage**: Achieves dense model performance with just 1/7 of the parameters (20B active = 140B dense equivalent).
- **Tech Talk**: Employs a heterogeneous system design for prefill-decode and attention-FFN, optimizing throughput with low latency.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
ByteDance AI Introduces Doubao-1.5-Pro Language Model with a 'Deep Thinking' Mode and Matches GPT 4o and Claude 3.5 Sonnet Benchmarks at 50x Cheaper
The artificial intelligence (AI) landscape is evolving rapidly, but this growth is accompanied by significant challenges. High costs of developing and deploying large-scale AI models and the difficulty of achieving reliable reasoning capabilities are central issues. Models like OpenAI’s GPT-4...
 www.marktechpost.com
www.marktechpost.com
ByteDance AI Introduces Doubao-1.5-Pro Language Model with a ‘Deep Thinking’ Mode and Matches GPT 4o and Claude 3.5 Sonnet Benchmarks at 50x Cheaper
By
Asif Razzaq
-
January 25, 2025
The artificial intelligence (AI) landscape is evolving rapidly, but this growth is accompanied by significant challenges. High costs of developing and deploying large-scale AI models and the difficulty of achieving reliable reasoning capabilities are central issues. Models like OpenAI’s GPT-4 and Anthropic’s Claude have pushed the boundaries of AI, but their resource-intensive architectures often make them inaccessible to many organizations. Additionally, addressing long-context understanding and balancing computational efficiency with accuracy remain unresolved challenges. These barriers highlight the need for solutions that are both cost-effective and accessible without sacrificing performance.
To address these challenges, ByteDance has introduced Doubao-1.5-pro, an AI model equipped with a “Deep Thinking” mode. The model demonstrates performance on par with established competitors like GPT-4o and Claude 3.5 Sonnet while being significantly more cost-effective. Its pricing stands out, with $0.022 per million cached input tokens, $0.11 per million input tokens, and $0.275 per million output tokens. Beyond affordability, Doubao-1.5-pro outperforms models such as deepseek-v3 and llama3.1-405B on key benchmarks, including the AIME test. This development is part of ByteDance’s broader efforts to make advanced AI capabilities more accessible, reflecting a growing emphasis on cost-effective innovation in the AI industry.


Technical Highlights and Benefits
Doubao-1.5-pro’s strong performance is underpinned by its thoughtful design and architecture. The model employs a sparse Mixture-of-Experts (MoE) framework, which activates only a subset of its parameters during inference. This approach allows it to deliver the performance of a dense model with only a fraction of the computational load. For instance, 20 billion activated parameters in Doubao-1.5-pro equate to the performance of a 140-billion-parameter dense model. This efficiency reduces operational costs and enhances scalability.
The model also integrates a heterogeneous system design for prefill-decode and attention-FFN tasks, optimizing throughput and minimizing latency. Additionally, its extended context windows of 32,000 to 256,000 tokens enable it to process long-form text more effectively, making it a valuable tool for applications like legal document analysis, academic research, and customer service.

Results and Insights
Performance data highlights Doubao-1.5-pro’s competitiveness in the AI landscape. It matches GPT-4o in reasoning tasks and surpasses earlier models, including O1-preview and O1, on benchmarks like AIME. Its cost efficiency is another significant advantage, with operational expenses 5x lower than DeepSeek and over 200x lower than OpenAI’s O1 model. These factors underscore ByteDance’s ability to offer a model that combines strong performance with affordability.
Early users have noted the effectiveness of the “Deep Thinking” mode, which enhances reasoning capabilities and proves valuable for tasks requiring complex problem-solving. This combination of technical innovation and cost-conscious design positions Doubao-1.5-pro as a practical solution for a range of industries.

Conclusion
Doubao-1.5-pro exemplifies a balanced approach to addressing the challenges in AI development, offering a combination of performance, cost efficiency, and accessibility. Its sparse Mixture-of-Experts architecture and efficient system design provide a compelling alternative to more resource-intensive models like GPT-4 and Claude. By prioritizing affordability and usability, ByteDance’s latest model contributes to making advanced AI tools more widely available. This marks an important step forward in AI development, reflecting a broader shift towards creating solutions that meet the needs of diverse users and organizations.

 @DeepSeek
@DeepSeek


 Blog:
Blog:  Qwen Chat:
Qwen Chat:  API:
API:  HF Demo:
HF Demo: 
 Thank you for your support during the past year. See you next year!
Thank you for your support during the past year. See you next year!





















 (the development of those chips by Huawei being another direct effect of the export controls and sanctions)
(the development of those chips by Huawei being another direct effect of the export controls and sanctions)


 .
. from
from 

 is cookin'
is cookin'







 Extend reasoning: Insert “Wait” to block.
Extend reasoning: Insert “Wait” to block.
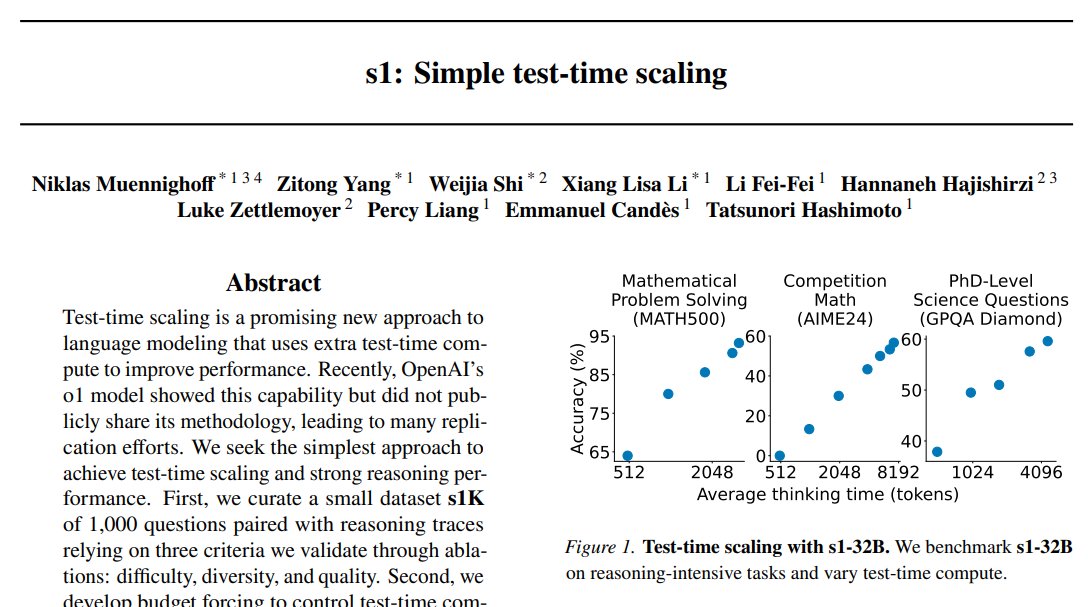









 Surprisingly, even when they tested with 59,000 examples, the model didn’t get much better— this shows that smart data selection (quality + difficulty + diversity) is key to efficient AI training.
Surprisingly, even when they tested with 59,000 examples, the model didn’t get much better— this shows that smart data selection (quality + difficulty + diversity) is key to efficient AI training.

 Extensive evaluation of latest models:
Extensive evaluation of latest models: Deep dive into temperature impact analysis & performance trends
Deep dive into temperature impact analysis & performance trends
 Evaluate your own models with our open-source scripts
Evaluate your own models with our open-source scripts 
 Math reasoning models are surprisingly temperature-sensitive!
Math reasoning models are surprisingly temperature-sensitive! Performance swings up to 15% across temperature settings
Performance swings up to 15% across temperature settings
 How many examples does an LLM need to learn competition-level math?
How many examples does an LLM need to learn competition-level math?

 arxiv.org/pdf/2502.03387
arxiv.org/pdf/2502.03387







