
1/4
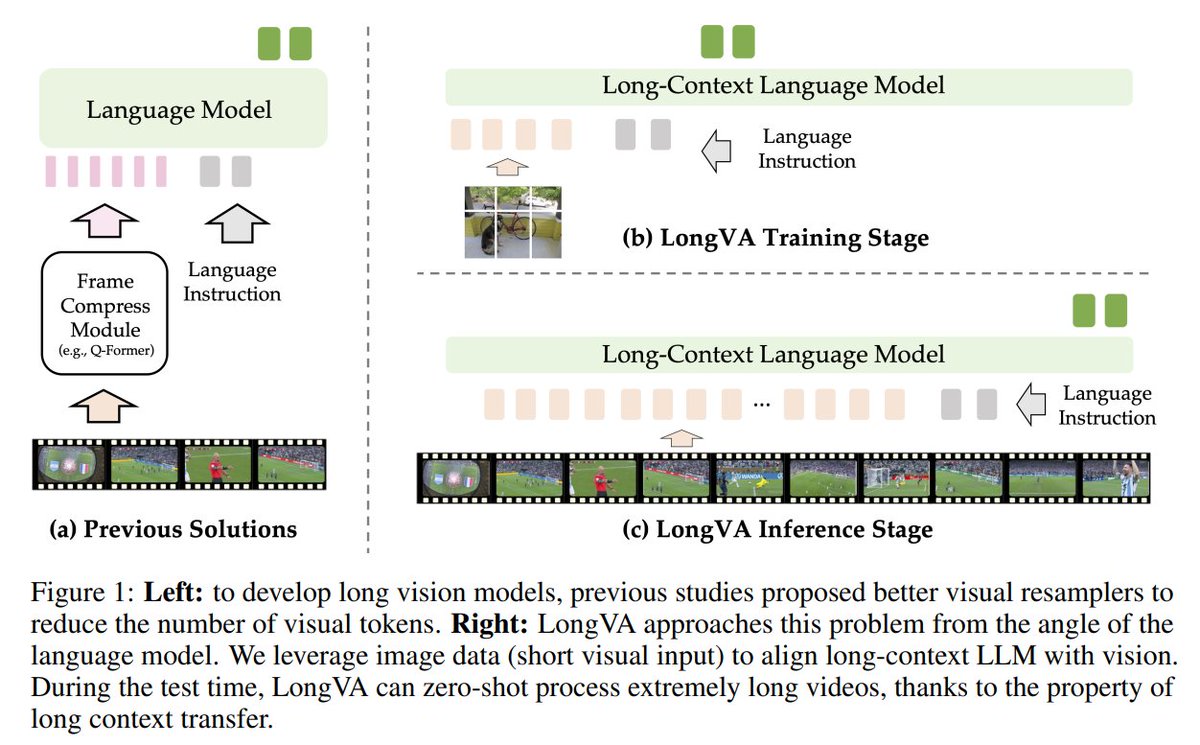
Long Context Transfer from Language to Vision
- Can process 2000 frames or over 200K visual tokens
- SotA perf on VideoMME among 7B-scale models
abs: [2406.16852] Long Context Transfer from Language to Vision
repo: GitHub - EvolvingLMMs-Lab/LongVA: Long Context Transfer from Language to Vision
2/4
Dark mode for this paper for night readers Long Context Transfer from Language to Vision
Long Context Transfer from Language to Vision
3/4
AI Summary: The paper introduces a method called long context transfer to enable Large Multimodal Models (LMMs) to understand extremely long videos by extrapolating the context length of the language backbon...
Long Context Transfer from Language to Vision
4/4
Didn't get it. don't they need more training time?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Long Context Transfer from Language to Vision
- Can process 2000 frames or over 200K visual tokens
- SotA perf on VideoMME among 7B-scale models
abs: [2406.16852] Long Context Transfer from Language to Vision
repo: GitHub - EvolvingLMMs-Lab/LongVA: Long Context Transfer from Language to Vision
2/4
Dark mode for this paper for night readers
Long Context Transfer from Language to Vision3/4
AI Summary: The paper introduces a method called long context transfer to enable Large Multimodal Models (LMMs) to understand extremely long videos by extrapolating the context length of the language backbon...
Long Context Transfer from Language to Vision
4/4
Didn't get it. don't they need more training time?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196




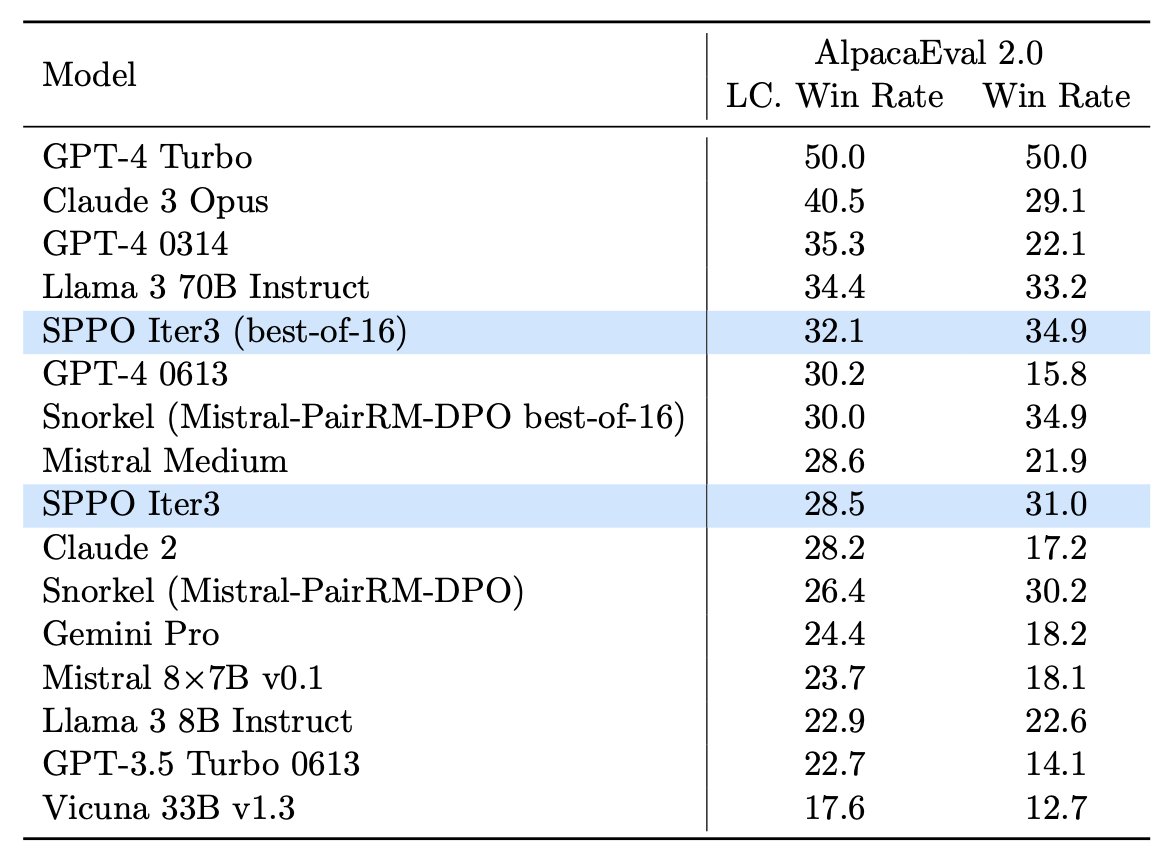
 code:
code:  models:
models: 









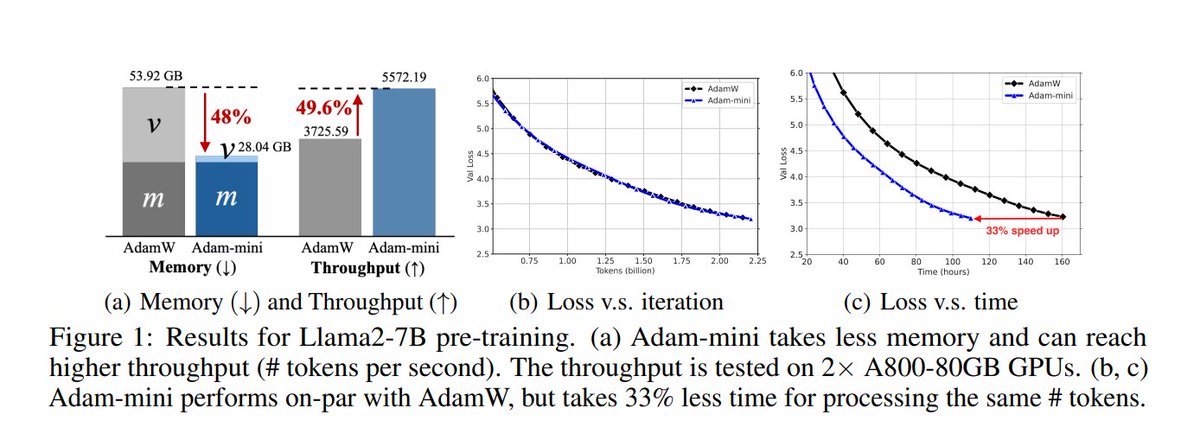






 :
: 












 New paper: we trained a SOTA (> GPT4, Gemini) VLM agent, DigiRL, that can do tasks on an Android phone in real time, in the wild, via autonomous offline + online RL
New paper: we trained a SOTA (> GPT4, Gemini) VLM agent, DigiRL, that can do tasks on an Android phone in real time, in the wild, via autonomous offline + online RL
 / little gif of learning progress
/ little gif of learning progress :
: need to continuously keep agents up-to-date + learn from "own" failures
need to continuously keep agents up-to-date + learn from "own" failures


















