Stumbled across H2O.ai's website and of course you already posted it bnew lol. Was looking to leverage an open-source LLM and was using huggingface's website, but the UX/UI was meh. H2O.ai is the best of both worlds. Created a shortcut in my Chrome and pinned it to my taskbar

You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Large Language Models News & Discussions
- Thread starter Macallik86
- Start date
More options
Who Replied?i like that you can save the chats and upload them too. i need to find a proper viewer though so I don't have to see the json output.Stumbled across H2O.ai's website and of course you already posted it bnew lol. Was looking to leverage an open-source LLM and was using huggingface's website, but the UX/UI was meh. H2O.ai is the best of both worlds. Created a shortcut in my Chrome and pinned it to my taskbar
/cdn.vox-cdn.com/uploads/chorus_asset/file/24778390/668894138.jpg)
Sarah Silverman is suing OpenAI and Meta for copyright infringement
She says the companies’ chatbots were trained on her book.
Sarah Silverman is suing OpenAI and Meta for copyright infringement
The lawsuits allege the companies trained their AI models on their works without their consent.
By Wes Davis, a weekend editor who covers the latest in tech and entertainment. He has written news, reviews, and more as a tech journalist since 2020.Jul 9, 2023, 2:14 PM EDT
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/24778390/668894138.jpg "Tax Day Activists Hold Marches In Major U.S. Cities")
Comedian and author Sarah Silverman, seen here participating in a Tax Day protest in 2017. Photo by Stephanie Keith/Getty Images
Comedian and author Sarah Silverman, as well as authors Christopher Golden and Richard Kadrey — are suing OpenAI and Meta each in a US District Court over dual claims of copyright infringement.
The suits alleges, among other things, that OpenAI’s ChatGPT and Meta’s LLaMA were trained on illegally-acquired datasets containing their works, which they say were acquired from “shadow library” websites like Bibliotik, Library Genesis, Z-Library, and others, noting the books are “available in bulk via torrent systems.”
Golden and Kadrey each declined to comment on the lawsuit, while Silverman’s team did not respond by press time.
In the OpenAI suit, the trio offers exhibits showing that when prompted, ChatGPT will summarize their books, infringing on their copyrights. Silverman’s Bedwetter is the first book shown being summarized by ChatGPT in the exhibits, while Golden’s book Ararat is also used as an example, as is Kadrey’s book Sandman Slim. The claim says the chatbot never bothered to “reproduce any of the copyright management information Plaintiffs included with their published works.”
As for the separate lawsuit against Meta, it alleges the authors’ books were accessible in datasets Meta used to train its LLaMA models, a quartet of open-source AI Models the company introduced in February.
The complaint lays out in steps why the plaintiffs believe the datasets have illicit origins — in a Meta paper detailing LLaMA, the company points to sources for its training datasets, one of which is called ThePile, which was assembled by a company called EleutherAI. ThePile, the complaint points out, was described in an EleutherAI paper as being put together from “a copy of the contents of the Bibliotik private tracker.” Bibliotik and the other “shadow libraries” listed, says the lawsuit, are “flagrantly illegal.”
In both claims, the authors say that they “did not consent to the use of their copyrighted books as training material” for the companies’ AI models. Their lawsuits each contain six counts of various types of copyright violations, negligence, unjust enrichment, and unfair competition. The authors are looking for statutory damages, restitution of profits, and more.
Lawyers Joseph Saveri and Matthew Butterick, who are representing the three authors, write on their LLMlitigation website that they’ve heard from “writers, authors, and publishers who are concerned about [ChatGPT’s] uncanny ability to generate text similar to that found in copyrighted textual materials, including thousands of books.”
Saveri has also started litigation against AI companies on behalf of programmers and artists. Getty Images also filed an AI lawsuit, alleging that Stability AI, who created the AI image generation tool Stable Diffusion, trained its model on “millions of images protected by copyright.” Saveri and Butterick are also representing authors Mona Awad and Paul Tremblay in a similar case over the company’s chatbot.
Lawsuits like this aren’t just a headache for OpenAI and other AI companies; they are challenging the very limits of copyright. As we’ve said on The Vergecast every time someone gets Nilay going on copyright law, we’re going to see lawsuits centered around this stuff for years to come.
We’ve reached out to Meta, OpenAI, and the Joseph Saveri Law Firm for comment, but they did not respond by press time.
Here are the suits:
/cdn.vox-cdn.com/uploads/chorus_asset/file/24016885/STK093_Google_04.jpg)
Google’s medical AI chatbot is already being tested in hospitals
Google says doctors prefer its answers, even if they’re less accurate.
Google’s medical AI chatbot is already being tested in hospitals
The Mayo Clinic has reportedly been testing the system since April.
By Wes Davis, a weekend editor who covers the latest in tech and entertainment. He has written news, reviews, and more as a tech journalist since 2020.Jul 8, 2023, 6:01 PM EDT
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/24016885/STK093_Google_04.jpg "Google logo with colorful shapes")
Illustration: The Verge
Google’s Med-PaLM 2, an AI tool designed to answer questions about medical information, has been in testing at the Mayo Clinic research hospital, among others, since April, The Wall Street Journal reported this morning. Med-PaLM 2 is a variant of PaLM 2, which was announced at Google I/O in May this year. PaLM 2 is the language model underpinning Google’s Bard.
WSJ reports that an internal email it saw said Google believes its updated model can be particularly helpful in countries with “more limited access to doctors.” Med-PaLM 2 was trained on a curated set of medical expert demonstrations, which Google believes will make it better at healthcare conversations than generalized chatbots like Bard, Bing, and ChatGPT.
The paper also mentions research Google made public in May (pdf) showing that Med-PaLM 2 still suffers from some of the accuracy issues we’re already used to seeing in large language models. In the study, physicians found more inaccuracies and irrelevant information in answers provided by Google’s Med-PaLM and Med-PalM 2 than those of other doctors.
Still, in almost every other metric, such as showing evidence of reasoning, consensus-supported answers, or showing no sign of incorrect comprehension, Med-PaLM 2 performed more or less as well as the actual doctors.
WSJ reports customers testing Med-PaLM 2 will control their data, which will be encrypted, and Google won’t have access to it.
According to Google senior research director Greg Corrado, WSJ says, Med-PaLM 2 is still in its early stages. Corrado said that while he wouldn’t want it to be a part of his own family’s “healthcare journey,” he believes Med-PaLM 2 “takes the places in healthcare where AI can be beneficial and expands them by 10-fold.”
We’ve reached out to Google and Mayo Clinic for more information.


Vivaldi 6.1 | Vivaldi Browser
 vivaldi.com
vivaldi.com
Vivaldi bypasses restrictions to access Bing Chat. 
Like to try Bing Chat without using Microsoft Edge for that?
You can. We’ve taken additional steps for you to use it in Vivaldi.
Back in 2019, we were forced to change our User-Agent strings for better site compatibility. Now, some websites continue to block us based on their Client Hints.
We’d love to announce ourselves as Vivaldi, but the current state of the web makes this difficult. Therefore, we are masquerading as competitors to benefit our users.
Having to find workarounds for such issues have opened new possibilities which includes access to Bing Chat in Vivaldi.
Download Vivaldi | Vivaldi Browser
Download the latest version of the Vivaldi browser for Windows, Mac or Linux. Browse your way with a fully customisable browser packed with advanced features.
vivaldi.com

Vivaldi is spoofing Edge Browser to bypass Bing Chat restrictions
The Vivaldi Browser announced today that they are now spoofing Microsoft Edge to bypass browser restrictions Microsoft placed in Bing Chat.
Introducing Llama 2
The next generation of our
open source large language model
Llama 2 is available for free for research and commercial use.

Industry Leading, Open-Source AI | Llama
Discover Llama 4's class-leading AI models, Scout and Maverick. Experience top performance, multimodality, low costs, and unparalleled efficiency.
 ai.meta.com
ai.meta.com
Inside the model
This release includes model weights and starting code for pretrained and fine-tuned Llama language models — ranging from 7B to 70B parameters.

Llama 2 pretrained models are trained on 2 trillion tokens, and have double the context length than Llama 1. Its fine-tuned models have been trained on over 1 million human annotations.
Benchmarks
Llama 2 outperforms other open source language models on many external benchmarks, including reasoning, coding, proficiency, and knowledge tests.

More model details
Llama 2 was pretrained on publicly available online data sources. The fine-tuned model, Llama-2-chat, leverages publicly available instruction datasets and over 1 million human annotations.
Technical details
Partnerships
Our global partners and supporters
We have a broad range of supporters around the world who believe in our open approach to today’s AI — companies that have given early feedback and are excited to build with Llama 2, cloud providers that will include the model as part of their offering to customers, researchers committed to doing research with the model, and people across tech, academia, and policy who see the benefits of Llama and an open platform as we do.







Statement of support for Meta’s open approach to today’s AI
“We support an open innovation approach to AI. Responsible and open innovation gives us all a stake in the AI development process, bringing visibility, scrutiny and trust to these technologies. Opening today’s Llama models will let everyone benefit from this technology.”
See the complete list of signatories
Responsibility
We’re committed to building responsibly.
To promote a responsible, collaborative AI innovation ecosystem, we’ve established a range of resources for all who use Llama 2: individuals, creators, developers, researchers, academics, and businesses of any size.Responsible Use Guide
The Responsible Use Guide is a resource for developers that provides best practices and considerations for building products powered by large language models (LLMs) in a responsible manner, covering various stages of development from inception to deployment.
Responsible Use Guide

meta-llama (Meta Llama)
Org profile for Meta Llama on Hugging Face, the AI community building the future.
huggingface.co
https://huggingface.co/llamaste/Llama-2-13b
meta-llama/Llama-2-13b-chat · Hugging Face
meta-llama/Llama-2-13b-hf · Hugging Face
meta-llama/Llama-2-70b · Hugging Face
meta-llama/Llama-2-70b-chat · Hugging Face
meta-llama/Llama-2-70b-hf · Hugging Face
meta-llama/Llama-2-7b · Hugging Face
meta-llama/Llama-2-7b-chat · Hugging Face
meta-llama/Llama-2-7b-chat-hf · Hugging Face
meta-llama/Llama-2-7b-hf · Hugging Face
meta-llama/Llama-2-13b · Hugging Face
meta-llama/Llama-2-13b-chat · Hugging Face
meta-llama/Llama-2-70b · Hugging Face
meta-llama/Llama-2-70b-chat · Hugging Face
meta-llama/Llama-2-70b-chat-hf · Hugging Face
meta-llama/Llama-2-70b-hf · Hugging Face
meta-llama/Llama-2-7b · Hugging Face
meta-llama/Llama-2-7b-chat · Hugging Face
meta-llama/Llama-2-7b-chat-hf · Hugging Face
https://huggingface.co/meta-llama/Llama-2-7b-hf
Llama 2 | Hacker News
 news.ycombinator.com
news.ycombinator.com

Chat with Meta Llama 3.1 on Replicate
Llama 3.1 is the latest language model from Meta.
www.llama2.ai
Last edited:
Gotta spread rep but couldn't find this link in news articles for the life of me. D'ya know if Meta collects session data? I'm assuming so but not sure. I'll definitely avoid it if they are pulling a Threads w/ it re: data collection.Chat with Meta Llama 3.1 on Replicate
Llama 3.1 is the latest language model from Meta.www.llama2.ai
Come to think of it, I'll likely stick to Falcon 40B for the time being unless I hear that this is drastically better. Gonna wait for some of the
Gotta spread rep but couldn't find this link in news articles for the life of me. D'ya know if Meta collects session data? I'm assuming so but not sure. I'll definitely avoid it if they are pulling a Threads w/ it re: data collection.
Come to think of it, I'll likely stick to Falcon 40B for the time being unless I hear that this is drastically better. Gonna wait for some of theYTInvidious AI channels I follow to do a deep dive
I assume online AI chat service free or paid is collecting session data. everyone seen how much open source models improved when trained with the shareGPT data. theres a lot of value in getting tens or hundreds of thousands of users to ask questions in multiple languages about thousands of topics in millions of ways. i'm taking advantage of these free services while they last.

Last edited:
My thought was that they're here to stay? The smaller models are getting better while becoming more compact, so it seems that if/when free models attempt to charge, most ppl could just use their phones or host their LLMs w/ yesteryear's GPUsI assume online AI chat service free or paid is collecting session data. everyone seen how much open source models improved when trained with the shareGPT data. theres a lot of value in getting tens or hundreds of thousands of users to ask questions in multiple lanaguages about thousands of topics in millions of ways. i'm taking advantage of these free services while they last.

With that said, I just watched a few videos on Code Interpreter and I can see why OpenAI requires a subscription to utilize that type of advanced responses. Free models have a ways to catch up to ChatGPT4 (but they're quickly gaining on 3.5 fwiw)
a llama v2 chat instance

Explore Llamav2 With TGI - a Hugging Face Space by ysharma
Discover amazing ML apps made by the community
huggingface.co
How is ChatGPT's behavior changing over time?
GPT-3.5 and GPT-4 are the two most widely used large language model (LLM) services. However, when and how these models are updated over time is opaque. Here, we evaluate the March 2023 and June 2023 versions of GPT-3.5 and GPT-4 on several diverse tasks: 1) math problems, 2) sensitive/dangerous...
How is ChatGPT's behavior changing over time?
Lingjiao Chen, Matei Zaharia, James ZouGPT-3.5 and GPT-4 are the two most widely used large language model (LLM) services. However, when and how these models are updated over time is opaque. Here, we evaluate the March 2023 and June 2023 versions of GPT-3.5 and GPT-4 on four diverse tasks: 1) solving math problems, 2) answering sensitive/dangerous questions, 3) generating code and 4) visual reasoning. We find that the performance and behavior of both GPT-3.5 and GPT-4 can vary greatly over time. For example, GPT-4 (March 2023) was very good at identifying prime numbers (accuracy 97.6%) but GPT-4 (June 2023) was very poor on these same questions (accuracy 2.4%). Interestingly GPT-3.5 (June 2023) was much better than GPT-3.5 (March 2023) in this task. GPT-4 was less willing to answer sensitive questions in June than in March, and both GPT-4 and GPT-3.5 had more formatting mistakes in code generation in June than in March. Overall, our findings shows that the behavior of the same LLM service can change substantially in a relatively short amount of time, highlighting the need for continuous monitoring of LLM quality.
How is ChatGPT's behavior changing over time? | Hacker News
 news.ycombinator.com
news.ycombinator.com

A jargon-free explanation of how AI large language models work
Want to really understand large language models? Here’s a gentle primer.
 arstechnica.com
arstechnica.com

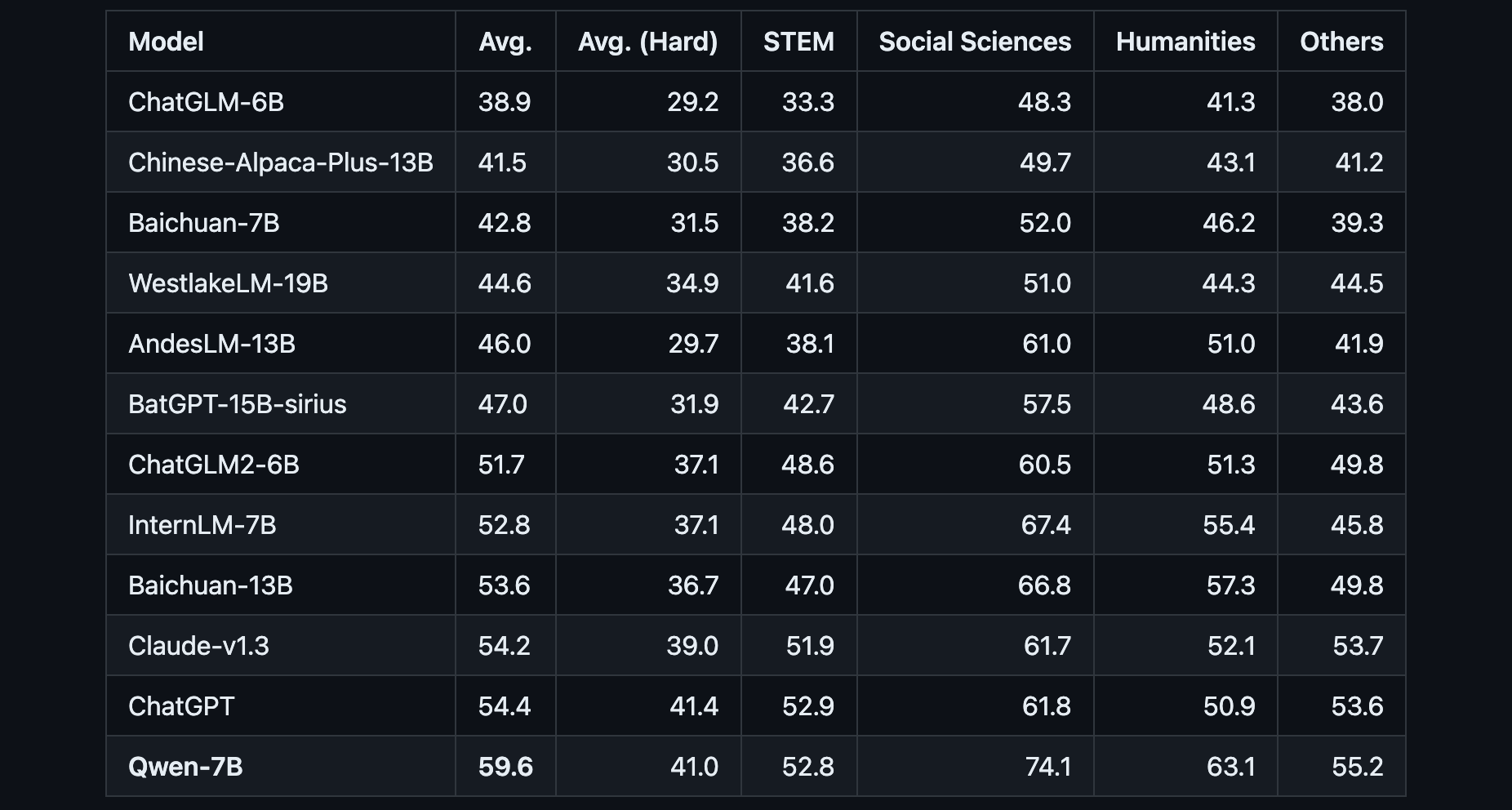
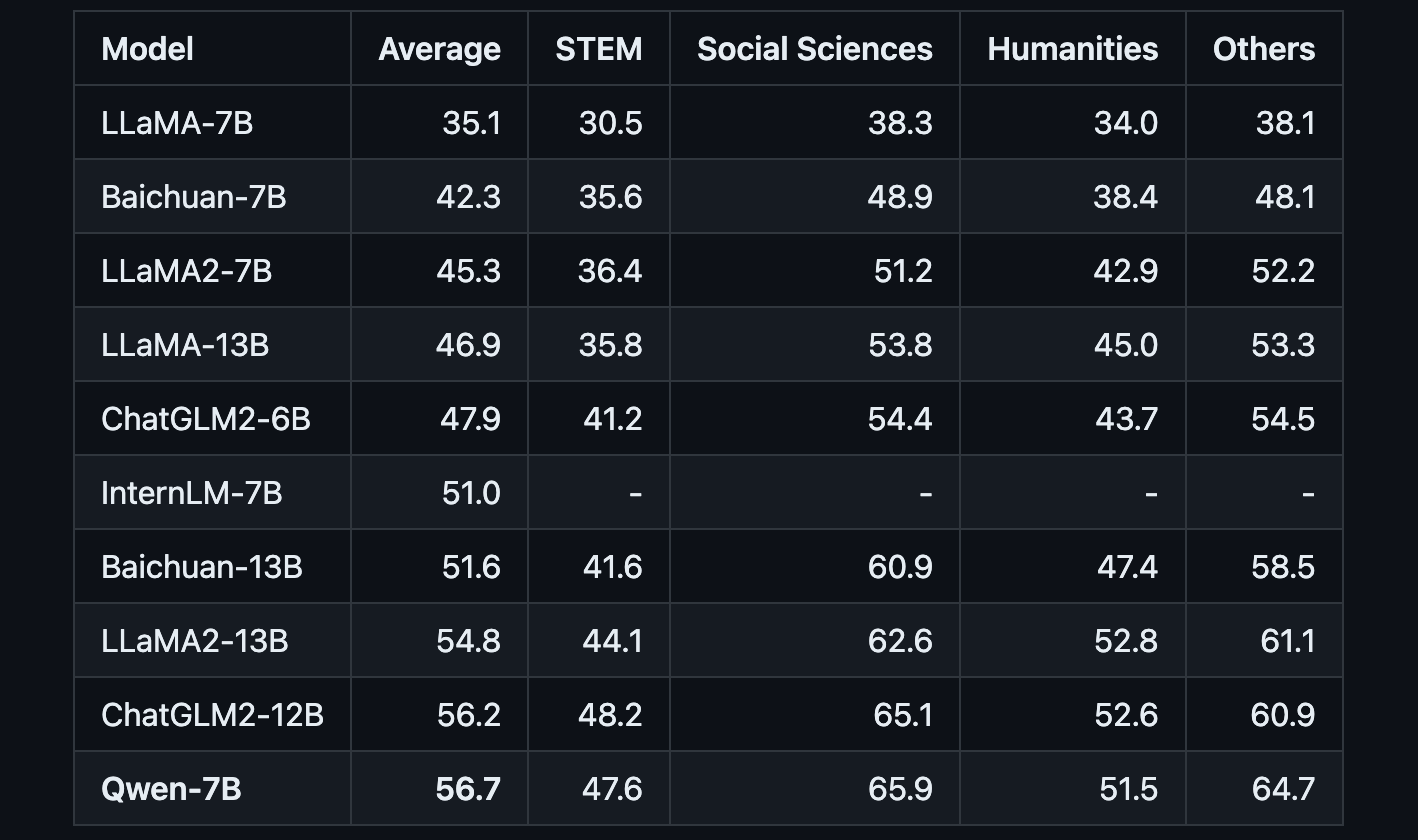
Alibaba Open Sources Qwen, a 7B Parameter AI Model
Qwen achieves state-of-the-art results compared to LLaMA and other leading models on tests of knowledge, coding, mathematical reasoning and translation capabilities.
Alibaba Open Sources Qwen, a 7B Parameter AI Model
Qwen achieves state-of-the-art results compared to LLaMA and other leading models on tests of knowledge, coding, mathematical reasoning and translation capabilities.CHRIS MCKAY
AUGUST 3, 2023 • 2 MIN READImage Credit: Alibaba
Chinese tech giant Alibaba has open-sourced its 7 billion parameter generative AI model Tongyi Qianwen (Qwen). The release positions Qwen as a direct competitor to Meta's similarly sized LLaMA model, setting up a showdown between the two tech titans.
Qwen is a transformer-based language model that has been pre-trained on over 2.2 trillion text tokens covering a diverse range of domains and languages. Benchmark testing shows that Qwen achieves state-of-the-art results compared to LLaMA and other leading models on tests of knowledge, coding, mathematical reasoning and translation capabilities.
The release includes model weights and codes for pre-trained and human-aligned language models of 7B parameters:
- Qwen-7B is the pretrained language model, and Qwen-7B-Chat is fine-tuned to align with human intent.
- Qwen-7B is pretrained on over 2.2 trillion tokens with a context length of 2048. On the series of benchmarks we tested, Qwen-7B generally performs better than existing open models of similar scales and appears to be on par with some of the larger models.
- Qwen-7B-Chat is fine-tuned on curated data, including not only task-oriented data but also specific security- and service-oriented data, which seems insufficient in existing open models.
- Example codes for fine-tuning, evaluation, and inference are included. There are also guides on long-context and tool use in inference.
Beyond the base Qwen model, Alibaba has also released Qwen-7B-Chat, a version fine-tuned specifically for dialog applications aligned with human intent and instructions. This chat-capable version of Qwen also supports calling plugins/tools/APIs through ReAct Prompting. This gives Qwen an edge in tasks like conversational agents and AI assistants where integration with external functions is invaluable.
The launch of Qwen highlights the intensifying competition between tech giants like Alibaba, Meta, Google and Microsoft as they race to develop more capable generative AI models.
By open-sourcing Qwen, Alibaba not only matches Meta's LLaMA but also leapfrogs the capabilities of its own previous model releases. Its formidable performance across a range of NLP tasks positions Qwen as a true general purpose model that developers can potentially adopt instead of LLaMA for building next-generation AI applications.
Helpful Links
Qwen-7B/examples/transformers_agent.md at main · QwenLM/Qwen-7B
The official repo of Qwen-7B (通义千问-7B) chat & pretrained large language model proposed by Alibaba Cloud. - QwenLM/Qwen-7B
 github.com
github.com
{snippet:}



更多玩法参考HuggingFace官方文档Transformers Agents
Tools
Tools支持
HuggingFace Agent官方14个tool:- Document question answering: given a document (such as a PDF) in image format, answer a question on this document (Donut)
- Text question answering: given a long text and a question, answer the question in the text (Flan-T5)
- Unconditional image captioning: Caption the image! (BLIP)
- Image question answering: given an image, answer a question on this image (VILT)
- Image segmentation: given an image and a prompt, output the segmentation mask of that prompt (CLIPSeg)
- Speech to text: given an audio recording of a person talking, transcribe the speech into text (Whisper)
- Text to speech: convert text to speech (SpeechT5)
- Zero-shot text classification: given a text and a list of labels, identify to which label the text corresponds the most (BART)
- Text summarization: summarize a long text in one or a few sentences (BART)
- Translation: translate the text into a given language (NLLB)
- Text downloader: to download a text from a web URL
- Text to image: generate an image according to a prompt, leveraging stable diffusion
- Image transformation: transforms an image
GitHub - QwenLM/Qwen-7B: The official repo of Qwen-7B (通义千问-7B) chat & pretrained large language model proposed by Alibaba Cloud.
The official repo of Qwen-7B (通义千问-7B) chat & pretrained large language model proposed by Alibaba Cloud. - GitHub - QwenLM/Qwen-7B: The official repo of Qwen-7B (通义千问-7B) chat & pretrained ...
github.com
We opensource Qwen-7B and Qwen-7B-Chat on both
 ModelScope and
ModelScope and  Hugging Face (Click the logos on top to the repos with codes and checkpoints). This repo includes the brief introduction to Qwen-7B, the usage guidance, and also a technical memo link that provides more information.
Hugging Face (Click the logos on top to the repos with codes and checkpoints). This repo includes the brief introduction to Qwen-7B, the usage guidance, and also a technical memo link that provides more information.Qwen-7B is the 7B-parameter version of the large language model series, Qwen (abbr. Tongyi Qianwen), proposed by Alibaba Cloud. Qwen-7B is a Transformer-based large language model, which is pretrained on a large volume of data, including web texts, books, codes, etc. Additionally, based on the pretrained Qwen-7B, we release Qwen-7B-Chat, a large-model-based AI assistant, which is trained with alignment techniques. The features of the Qwen-7B series include:
- Trained with high-quality pretraining data. We have pretrained Qwen-7B on a self-constructed large-scale high-quality dataset of over 2.2 trillion tokens. The dataset includes plain texts and codes, and it covers a wide range of domains, including general domain data and professional domain data.
- Strong performance. In comparison with the models of the similar model size, we outperform the competitors on a series of benchmark datasets, which evaluates natural language understanding, mathematics, coding, etc.
- Better support of languages. Our tokenizer, based on a large vocabulary of over 150K tokens, is a more efficient one compared with other tokenizers. It is friendly to many languages, and it is helpful for users to further finetune Qwen-7B for the extension of understanding a certain language.
- Support of 8K Context Length. Both Qwen-7B and Qwen-7B-Chat support the context length of 8K, which allows inputs with long contexts.
- Support of Plugins. Qwen-7B-Chat is trained with plugin-related alignment data, and thus it is capable of using tools, including APIs, models, databases, etc., and it is capable of playing as an agent.

Hear Elvis sing Baby Got Back using AI—and learn how it was made
Despite help from neural networks, it requires more human work than you might think.
arstechnica.com
Thanks to AI, “Elvis” likes big butts and he cannot lie—here’s how it’s possible
Despite help from neural networks, it requires more human work than you might think.
BENJ EDWARDS - 8/4/2023, 11:32 AM
Recently, a number of viral music videos from a YouTube channel called There I Ruined It have included AI-generated voices of famous musical artists singing lyrics from surprising songs. One recent example imagines Elvis singing lyrics to Sir Mix-a-Lot's Baby Got Back. Another features a faux Johnny Cash singing the lyrics to Aqua's Barbie Girl.
(The original Elvis video has since been taken down from YouTube due to a copyright claim from Universal Music Group, but thanks to the magic of the Internet, you can hear it anyway.)
An excerpt copy of the "Elvis Sings Baby Got Back" video.
Obviously, since Elvis has been dead for 46 years (and Cash for 20), neither man could have actually sung the songs themselves. That's where AI comes in. But as we'll see, although generative AI can be amazing, there's still a lot of human talent and effort involved in crafting these musical mash-ups.
To figure out how There I Ruined It does its magic, we first reached out to the channel's creator, musician Dustin Ballard. Ballard's response was low in detail, but he laid out the basic workflow. He uses an AI model called so-vits-svc to transform his own vocals he records into those of other artists. "It's currently not a very user-friendly process (and the training itself is even more difficult)," he told Ars Technica in an email, "but basically once you have the trained model (based on a large sample of clean audio references), then you can upload your own vocal track, and it replaces it with the voice that you've modeled. You then put that into your mix and build the song around it."
But let's back up a second: What does "so-vits-svc" mean? The name originates from a series of open source technologies being chained together. The "so" part comes from "SoftVC" (VC for "voice conversion"), which breaks source audio (a singer's voice) into key parts that can be encoded and learned by a neural network. The "VITS" part is an acronym for "Variational Inference with adversarial learning for end-to-end Text-to-Speech," coined in this 2021 paper. VITS takes knowledge of the trained vocal model and generates the converted voice output. And "SVC" means "singing voice conversion"—converting one singing voice to another—as opposed to converting someone's speaking voice.
The recent There I Ruined It songs primarily use AI in one regard: The AI model relies on Ballard's vocal performance, but it changes the timbre of his voice to that of someone else, similar to how Respeecher's voice-to-voice technology can transform one actor's performance of Darth Vader into James Earl Jones' voice. The rest of the song comes from Ballard's arrangement in a conventional music app.
A complicated process—at the moment
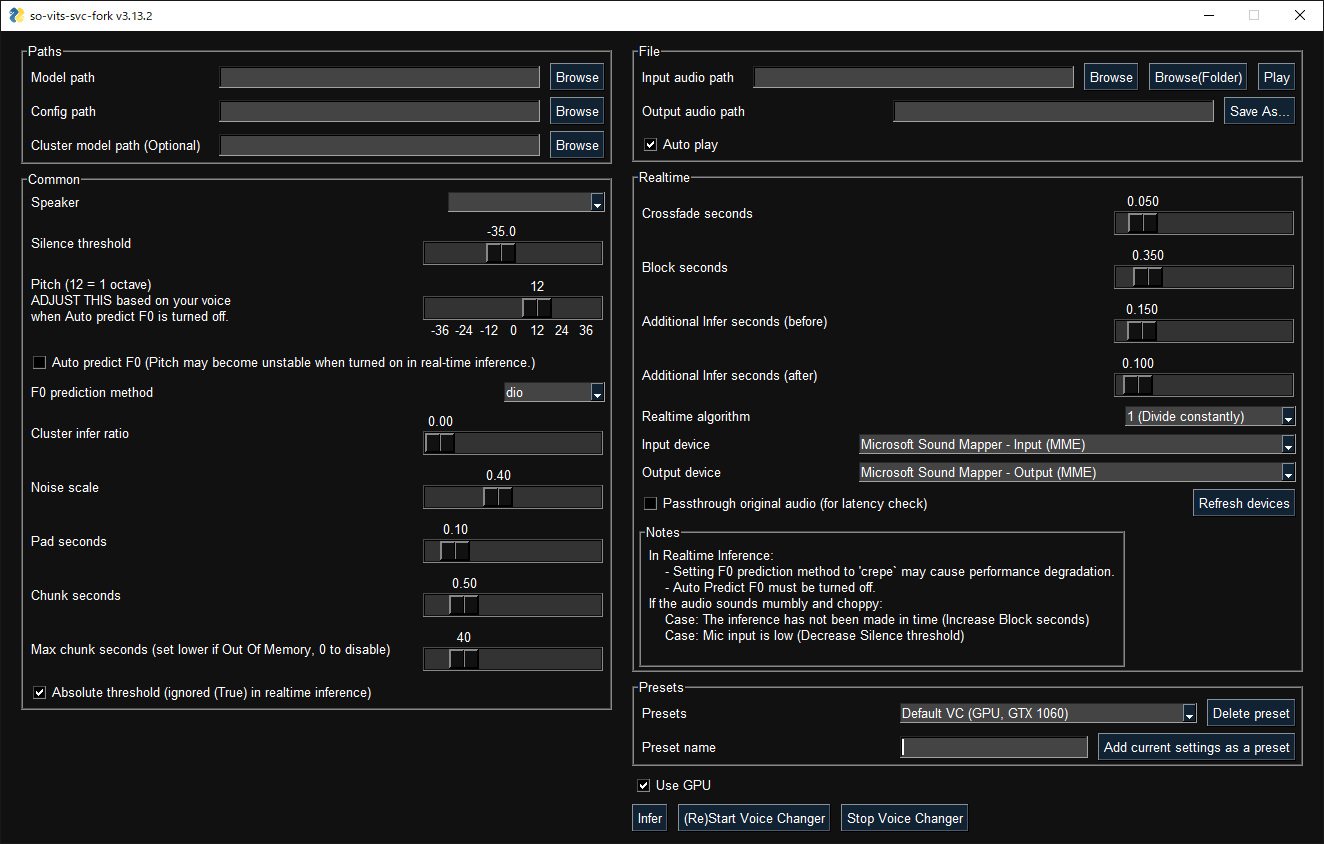
The GUI interface for a fork of so-vits-svc.
To get more insight into the musical voice-cloning process with so-vits-svc-fork (an altered version of the original so-vits-svc), we tracked down Michael van Voorst, the creator of the Elvis voice AI model that Ballard used in his Baby Got Back video. He walked us through the steps necessary to create an AI mash-up.
"In order to create an accurate replica of a voice, you start off with creating a data set of clean vocal audio samples from the person you are building a voice model of," said van Voorst. "The audio samples need to be of studio quality for the best results. If they are of lower quality, it will reflect back into the vocal model."
In the case of Elvis, van Voorst used vocal tracks from the singer's famous Aloha From Hawaii concert in 1973 as the foundational material to train the voice model. After careful manual screening, van Voorst extracted 36 minutes of high-quality audio, which he then divided into 10-second chunks for correct processing. "I listened carefully for any interference, like band or audience noise, and removed it from my data set," he said. Also, he tried to capture a wide variety of vocal expressions: "The quality of the model improves with more and varied samples."
Next, van Voorst shared the series of somewhat convoluted and technical steps necessary to perform the so-vits-svc-fork training process, repeated here in case it's useful for anyone who might want to attempt it:
After van Voorst ran 211,000 steps of training, the Elvis AI voice model was ready for action. Next, van Voorst shared the model with others online. There I Ruined It creator Dustin Ballard downloaded the Elvis vocal model—people frequently share them through Discord communities of like-minded voice-cloning hobbyists—and his part of the work began.Once you've prepared your audio, you'll put it inside the program's directory structure. In my case, it was /dataset_raw/elvis/ Then you'll have to run a few commands in this order to start training the model. "svc pre-resample" converts your audio to mono 44.1khz files. Following that, "svc pre-config" downloads a few configuration files and puts it in the correct directory. "svc pre-hubert" downloads and runs a speech model pre-training. It contains guidelines so that you get a predictable output when creating your own model in the last step.
This last step is "svc train -t". It starts the training and opens up a browser window with the TensorBoard. With the TensorBoard, you can keep track of the progress of your model. Once you are satisfied with the results, you can stop the training. The progress is measured in steps. In the configuration files, you can change how often you want to write the model to disk. For Elvis, i wanted to have a copy after every 100 steps and was ultimately satisfied at 211k steps.
To craft the song, Ballard opened a conventional music workstation app, such as Pro Tools, and imported an instrumental backing track for the Elvis hit Don't Be Cruel, played by human musicians. Next, Ballard sang the lyrics of Baby Got Back to the tune of Don't Be Cruel, recording his performance. He repeated the same with any backing vocals in the song. Next, he ran his recorded vocals through van Voorst's Elvis AI model using so-vits-svc, making them sound like Elvis singing them instead.
To make the song sound authentic and as close to the original record as possible, van Voorst said, it's best to not make any use of modern techniques like pitch correction or time stretching. "Phrasing and timing the vocal during recording is the best way to make sure it sounds natural," he said, pointing out some telltale signs in the Baby Got Back AI song. "I hear some remnants of a time stretching feature being used on the word 'sprung' and a little bit of pitch correction, but otherwise it sounds very natural."
Ballard then imported the Elvis-style vocals into Pro Tools, replacing his original guide vocals and lining them up with the instrumental backing track. After mixing, the new AI-augmented song was complete, and he documented it in YouTube and TikTok videos.
"At this moment, tools like these still require a lot of preparation and often come with a not so user-friendly installation process," said van Voorst, acknowledging the hoops necessary to jump through to make this kind of mash-up possible. But as technology progresses, we'll likely see easier-to-use solutions in the months and years ahead. For now, technically inclined musicians like Ballard who are willing to tinker with open source software have an edge when it comes to generating novel material using AI.
There I Ruined It makes Johnny Cash sing Barbie Girl lyrics.
In another recent showcase of this technology, a YouTube artist known as Dae Lims used a similar technique to recreate a young Paul McCartney's voice, although the result arguably still sounds very artificial. He replaced the vocals of a 2018 song by McCartney, I Don't Know, with his own, then converted them using a voice model of the young Beatle. The relatively high-quality results Ballard has achieved by comparison may partially come from his ability to imitate the vocal phrasing and mannerisms of Elvis, making so-vits-svc's job of transforming the vocals easier.
It seems that we're on the precipice of a new era in music, where AI can effectively mimic the voices of legendary artists. The implications of this tech are broad and uncertain and touch copyright, trademark, and deep ethical issues. But for now, we can marvel at the horribly weird reality that, through the power of AI, we can hear Elvis sing about his anaconda—and it has nothing to do with the Jungle Room.