Updated the title to be more inclusive to other Large Language models out there
add chatgpt in the tags and other related keywords.

Updated the title to be more inclusive to other Large Language models out there
The Capacity for Moral Self-Correction in Large Language Models
snippet:
Abstract
We test the hypothesis that language models trained with reinforcement learning from human feedback (RLHF) have the capability to “morally self-correct”—to avoid producing harmful outputs—if instructed to do so. We find strong evidence in support of this hypothesis across three different experiments, each of which reveal different facets of moral self-correction. We find that the capability for moral self-correction emerges at 22B model parameters, and typically improves with increasing model size and RLHF training. We believe that at this level of scale, language models obtain two capabilities that they can use for moral self-correction: (1) they can follow instructions and (2) they can learn complex normative concepts of harm like stereotyping, bias, and discrimination. As such, they can follow instructions to avoid certain kinds of morally harmful outputs. We believe our results are cause for cautious optimism regarding the ability to train language models to abide by ethical principles.
https://web.archive.org/web/20230430005058/https://twitter.com/lupantech/status/1652022897563795456 65B LLaMA-Adapter-V2 code & checkpoint are NOW ready at GitHub - ZrrSkywalker/LLaMA-Adapter: Fine-tuning LLaMA to follow Instructions within 1 Hour and 1.2M Parameters!
65B LLaMA-Adapter-V2 code & checkpoint are NOW ready at GitHub - ZrrSkywalker/LLaMA-Adapter: Fine-tuning LLaMA to follow Instructions within 1 Hour and 1.2M Parameters! Big update enhancing multimodality & chatbot.
Big update enhancing multimodality & chatbot. LLaMA-Adapter-V2 surpasses #ChatGPT in response quality (102%:100%) & beats #Vicuna in win-tie-lost (50:14).
LLaMA-Adapter-V2 surpasses #ChatGPT in response quality (102%:100%) & beats #Vicuna in win-tie-lost (50:14). ️Thanks to Peng Gao &
️Thanks to Peng Gao & github.com
github.com
https://web.archive.org/save/https://twitter.com/gdb/status/1652369023609470976
 Image-to-Multilingual-OCR
Image-to-Multilingual-OCR  Gradio - a Hugging Face Space by awacke1
Gradio - a Hugging Face Space by awacke1
https://web.archive.org/web/20230430012709/https://twitter.com/DrEalmutairi/status/1652272468105543681https://web.archive.org/web/20230430022903/https://twitter.com/rasbt/status/1652288118924644352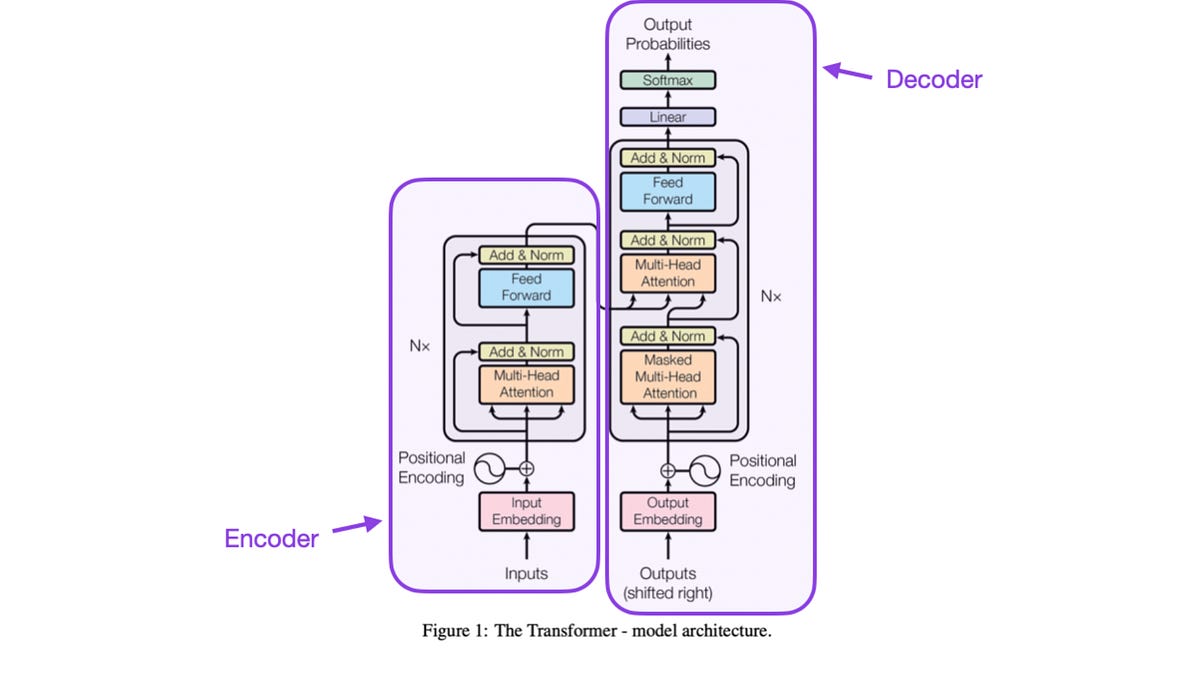
 magazine.sebastianraschka.com
magazine.sebastianraschka.com
https://web.archive.org/web/20230430024108/https://twitter.com/madiator/status/1652326887589556224Self-supervised learning, dubbed the dark matter of intelligence, is a promising path to advance machine learning. Yet, much like cooking, training SSL methods is a delicate art with a high barrier to entry. While many components are familiar, successfully training a SSL method involves a dizzying set of choices from the pretext tasks to training hyper-parameters. Our goal is to lower the barrier to entry into SSL research by laying the foundations and latest SSL recipes in the style of a cookbook. We hope to empower the curious researcher to navigate the terrain of methods, understand the role of the various knobs, and gain the know-how required to explore how delicious SSL can be.





https://web.archive.org/web/20230430105553/https://twitter.com/carperai/status/1652025709953716224