/cdn.vox-cdn.com/uploads/chorus_asset/file/25203771/Screen_Shot_2024_01_04_at_10.55.35_AM.png)
Google wrote a “Robot Constitution” to make sure its new AI droids won’t kill us
The robot AI system with built-in safety prompts.
Google wrote a ‘Robot Constitution’ to make sure its new AI droids won’t kill us
The data gathering system AutoRT applies safety guardrails inspired by Isaac Asimov’s Three Laws of Robotics.
By Amrita Khalid, one of the authors of audio industry newsletter Hot Pod. Khalid has covered tech, surveillance policy, consumer gadgets, and online communities for more than a decade.
Jan 4, 2024, 4:21 PM EST|11 Comments / 11 New
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25203771/Screen_Shot_2024_01_04_at_10.55.35_AM.png)
Image: Google
The DeepMind robotics team has revealed three new advances that it says will help robots make faster, better, and safer decisions in the wild. One includes a system for gathering training data with a “Robot Constitution” to make sure your robot office assistant can fetch you more printer paper — but without mowing down a human co-worker who happens to be in the way.
Google’s data gathering system, AutoRT, can use a visual language model (VLM) and large language model (LLM) working hand in hand to understand its environment, adapt to unfamiliar settings, and decide on appropriate tasks. The Robot Constitution, which is inspired by Isaac Asimov’s “Three Laws of Robotics,” is described as a set of “safety-focused prompts” instructing the LLM to avoid choosing tasks that involve humans, animals, sharp objects, and even electrical appliances.
For additional safety, DeepMind programmed the robots to stop automatically if the force on its joints goes past a certain threshold and included a physical kill switch human operators can use to deactivate them. Over a period of seven months, Google deployed a fleet of 53 AutoRT robots into four different office buildings and conducted over 77,000 trials. Some robots were controlled remotely by human operators, while others operated either based on a script or completely autonomously using Google’s Robotic Transformer (RT-2) AI learning model.
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25203936/Screen_Shot_2024_01_04_at_11.52.15_AM.png)
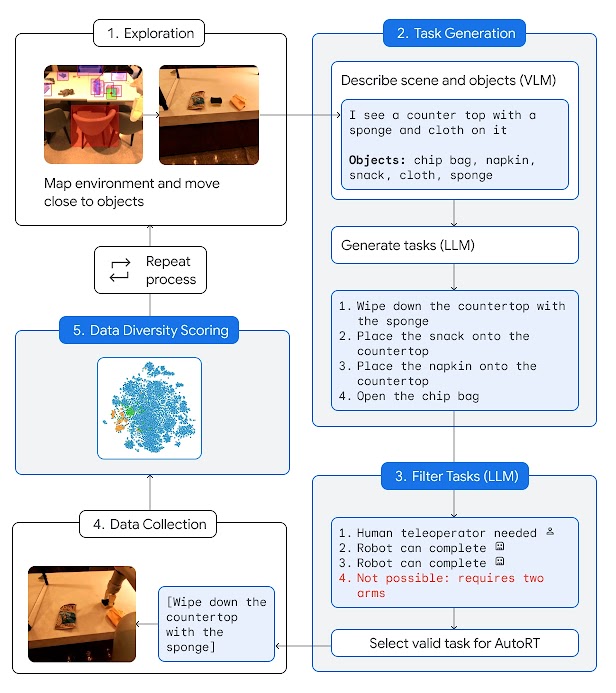
AutoRT follows these four steps for each task.
The robots used in the trial look more utilitarian than flashy — equipped with only a camera, robot arm, and mobile base. “For each robot, the system uses a VLM to understand its environment and the objects within sight. Next, an LLM suggests a list of creative tasks that the robot could carry out, such as ‘Place the snack onto the countertop’ and plays the role of decision-maker to select an appropriate task for the robot to carry out,” noted Google in its blog post.
:no_upscale():format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25204049/ezgif.com_optimize.gif)
Image: Google
DeepMind’s other new tech includes SARA-RT, a neural network architecture designed to make the existing Robotic Transformer RT-2 more accurate and faster. It also announced RT-Trajectory, which adds 2D outlines to help robots better perform specific physical tasks, such as wiping down a table.
We still seem to be a very long way from robots that serve drinks and fluff pillows autonomously, but when they’re available, they may have learned from a system like AutoRT.