
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Large Language Models News & Discussions
- Thread starter Macallik86
- Start date
More options
Who Replied?
WizardLM/WizardCoder-33B-V1.1 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
WizardLM/WizardCoder at main · nlpxucan/WizardLM
LLMs build upon Evol Insturct: WizardLM, WizardCoder, WizardMath - nlpxucan/WizardLM
 github.com
github.com


ChatGPT bombs test on diagnosing kids’ medical cases with 83% error rate
It was bad at recognizing relationships and needs selective training, researchers say.
 arstechnica.com
arstechnica.com
ChatGPT bombs test on diagnosing kids’ medical cases with 83% error rate
It was bad at recognizing relationships and needs selective training, researchers say.
BETH MOLE - 1/3/2024, 6:46 PM
Enlarge / Dr. Greg House has a better rate of accurately diagnosing patients than ChatGPT.
Getty | Alan Zenuk/NBCU Photo Bank/NBCUniversa
ChatGPT is still no House, MD.
While the chatty AI bot has previously underwhelmed with its attempts to diagnose challenging medical cases—with an accuracy rate of 39 percent in an analysis last year— a study out this week in JAMA Pediatrics suggests the fourth version of the large language model is especially bad with kids. It had an accuracy rate of just 17 percent when diagnosing pediatric medical cases.
The low success rate suggests human pediatricians won't be out of jobs any time soon, in case that was a concern. As the authors put it: "[T]his study underscores the invaluable role that clinical experience holds." But it also identifies the critical weaknesses that led to ChatGPT's high error rate and ways to transform it into a useful tool in clinical care. With so much interest and experimentation with AI chatbots, many pediatricians and other doctors see their integration into clinical care as inevitable.
The medical field has generally been an early adopter of AI-powered technologies, resulting in some notable failures, such as creating algorithmic racial bias, as well as successes, such as automating administrative tasks and helping to interpret chest scans and retinal images. There's also lot in between. But AI's potential for problem-solving has raised considerable interest in developing it into a helpful tool for complex diagnostics—no eccentric, prickly, pill-popping medical genius required.
In the new study conducted by researchers at Cohen Children’s Medical Center in New York, ChatGPT-4 showed it isn't ready for pediatric diagnoses yet. Compared to general cases, pediatric ones require more consideration of the patient's age, the researchers note. And as any parent knows, diagnosing conditions in infants and small children is especially hard when they can't pinpoint or articulate all the symptoms they're experiencing.
For the study, the researchers put the chatbot up against 100 pediatric case challenges published in JAMA Pediatrics and NEJM between 2013 and 2023. These are medical cases published as challenges or quizzes. Physicians reading along are invited to try to come up with the correct diagnosis of a complex or unusual case based on the information that attending doctors had at the time. Sometimes, the publications also explain how attending doctors got to the correct diagnosis.
Missed connections
For ChatGPT's test, the researchers pasted the relevant text of the medical cases into the prompt, and then two qualified physician-researchers scored the AI-generated answers as correct, incorrect, or "did not fully capture the diagnosis." In the latter case, ChatGPT came up with a clinically related condition that was too broad or unspecific to be considered the correct diagnosis. For instance, ChatGPT diagnosed one child's case as caused by a branchial cleft cyst—a lump in the neck or below the collarbone—when the correct diagnosis was Branchio-oto-renal syndrome, a genetic condition that causes the abnormal development of tissue in the neck, and malformations in the ears and kidneys. One of the signs of the condition is the formation of branchial cleft cysts.Overall, ChatGPT got the right answer in just 17 of the 100 cases. It was plainly wrong in 72 cases, and did not fully capture the diagnosis of the remaining 11 cases. Among the 83 wrong diagnoses, 47 (57 percent) were in the same organ system.
Among the failures, researchers noted that ChatGPT appeared to struggle with spotting known relationships between conditions that an experienced physician would hopefully pick up on. For example, it didn't make the connection between autism and scurvy (Vitamin C deficiency) in one medical case. Neuropsychiatric conditions, such as autism, can lead to restricted diets, and that in turn can lead to vitamin deficiencies. As such, neuropsychiatric conditions are notable risk factors for the development of vitamin deficiencies in kids living in high-income countries, and clinicians should be on the lookout for them. ChatGPT, meanwhile, came up with the diagnosis of a rare autoimmune condition.
Though the chatbot struggled in this test, the researchers suggest it could improve by being specifically and selectively trained on accurate and trustworthy medical literature—not stuff on the Internet, which can include inaccurate information and misinformation. They also suggest chatbots could improve with more real-time access to medical data, allowing the models to refine their accuracy, described as "tuning."
"This presents an opportunity for researchers to investigate if specific medical data training and tuning can improve the diagnostic accuracy of LLM-based chatbots," the authors conclude.





Google outlines new methods for training robots with video and large language models | TechCrunch
In a blog post today, Google is highlighting on-going research designed to give robotics a better understanding.
 techcrunch.com
techcrunch.com
Google outlines new methods for training robots with video and large language models
Brian Heater @bheater / 2:45 PM EST•January 4, 2024

Image Credits: Google DeepMind Robotics
2024 is going to be a huge year for the cross-section of generative AI/large foundational models and robotics. There’s a lot of excitement swirling around the potential for various applications, ranging from learning to product design. Google’s DeepMind Robotics researchers are one of a number of teams exploring the space’s potential. In a blog post today, the team is highlighting ongoing research designed to give robotics a better understanding of precisely what it is we humans want out of them.
Traditionally, robots have focused on doing a singular task repeatedly for the course of their life. Single-purpose robots tend to be very good at that one thing, but even they run into difficulty when changes or errors are unintentionally introduced to the proceedings.
The newly announced AutoRT is designed to harness large foundational models, to a number of different ends. In a standard example given by the DeepMind team, the system begins by leveraging a Visual Language Model (VLM) for better situational awareness. AutoRT is capable of managing a fleet of robots working in tandem and equipped with cameras to get a layout of their environment and the object within it.
A large language model, meanwhile, suggests tasks that can be accomplished by the hardware, including its end effector. LLMs are understood by many to be the key to unlocking robotics that effectively understand more natural language commands, reducing the need for hard-coding skills.
The system has already been tested quite a bit over the past seven or so months. AutoRT is capable of orchestrating up to 20 robots at once and a total of 52 different devices. All told, DeepMind has collected some 77,000 trials, including more than 6,000 tasks.
Also new from the team is RT-Trajectory, which leverages video input for robotic learning. Plenty of teams are exploring the use of YouTube videos as a method to train robots at scale, but RT-Trajectory adds an interesting layer, overlaying a two-dimension sketch of the arm in action over the video.
The team notes, “these trajectories, in the form of RGB images, provide low-level, practical visual hints to the model as it learns its robot-control policies.”
DeepMind says the training had double the success rate of its RT-2 training, at 63% compared to 29%, while testing 41 tasks.
“RT-Trajectory makes use of the rich robotic-motion information that is present in all robot datasets, but currently under-utilized,” the team notes. “RT-Trajectory not only represents another step along the road to building robots able to move with efficient accuracy in novel situations, but also unlocking knowledge from existing datasets.”

A survey of 2,778 researchers shows how fragmented the AI science community is
The "2023 Expert Survey on Progress in AI" shows that the scientific community has no consensus on the risks and opportunities of AI, but everything is moving faster than once thought.
 the-decoder.com
the-decoder.com
Jan 5, 2024
A survey of 2,778 researchers shows how fragmented the AI science community is
DALL-E 3 prompted by THE DECODER
Matthias Bastian
Online journalist Matthias is the co-founder and publisher of THE DECODER. He believes that artificial intelligence will fundamentally change the relationship between humans and computers.
Profile
The "2023 Expert Survey on Progress in AI" shows that the scientific community has no consensus on the risks and opportunities of AI, but everything is moving faster than once thought.
On the much-discussed question of whether the development of AI needs a pause, the survey reveals an undecided picture: about 35% support either a slower or a faster development compared to the current pace.
However, at 15.6%, the "much faster" group is three times larger than the "much slower" group. 27% say the current pace is appropriate.
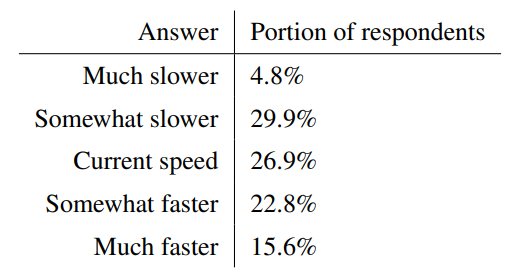
Image: Grace et al.
AI development will continue to accelerate
The survey found that the pace of AI development will continue to accelerate. The overall forecast revealed a probability of at least 50 percent that AI systems will reach several milestones by 2028, many significantly earlier than previously thought.These milestones include autonomously creating a payment processing website from scratch, creating a song indistinguishable from a new song by a well-known musician, and autonomously downloading and refining a comprehensive language model.
A fictional New York Times bestseller is expected to be written by AI around 2030. In the last survey, this estimate was around 2038.
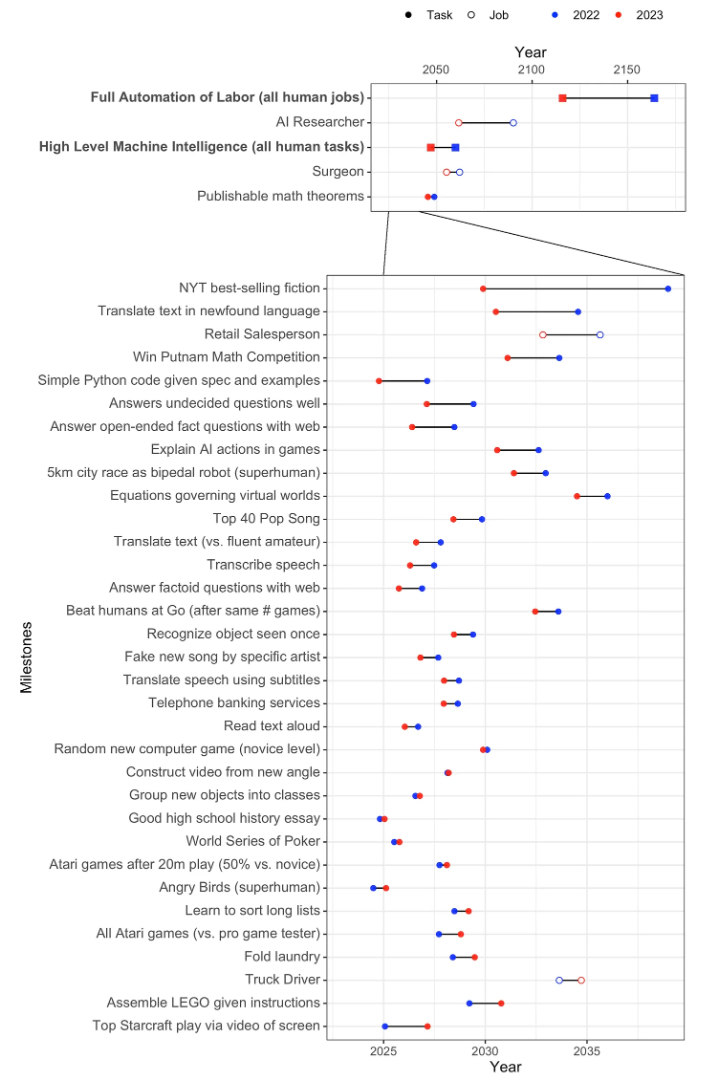
Image: Grace et al.
Answers to the questions about "high-level machine intelligence" (HLMI) and "full automation of work" (FAOL) also varied widely in some cases, but the overall forecast for both questions points to a much earlier occurrence than previously expected.
If scientific progress continues unabated, the probability that machines will outperform humans in all possible tasks without outside help is estimated at 10 percent by 2027 and 50 percent by 2047. This estimate is 13 years ahead of a similar survey conducted just one year earlier.
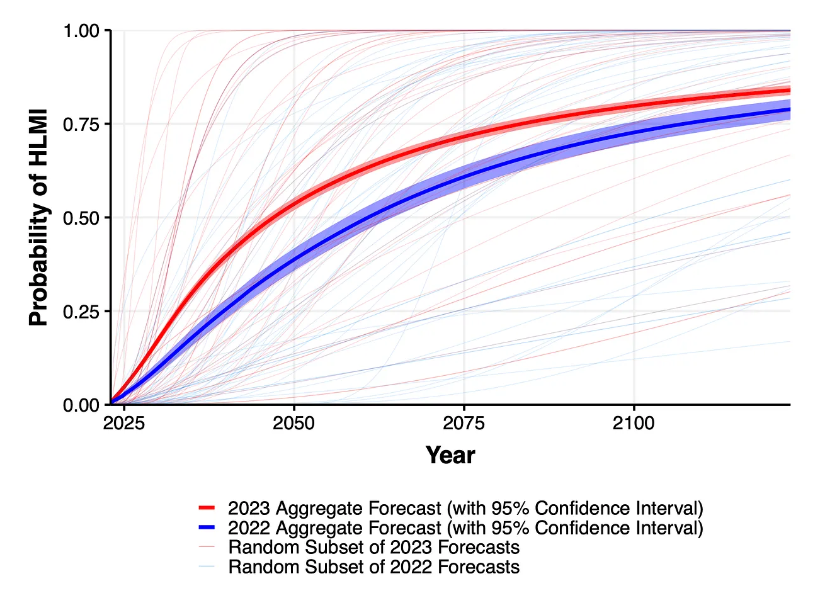
Image: Grace et al.
The likelihood of all human occupations being fully automated was estimated at 10 percent by 2037 and 50 percent by 2116 (compared to 2164 in the 2022 survey).
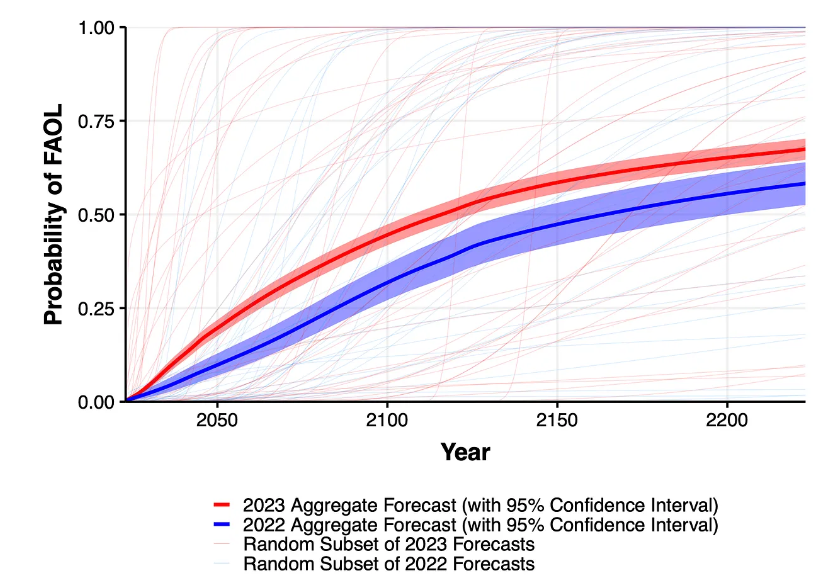
Image: Grace et al.
Existential fears also exist in AI science, but they are becoming more moderate
High hopes and gloomy fears often lie close together among the participants. More than half of the respondents (52%) expect positive or even very positive (23%) effects of AI on humanity.In contrast, 27 percent of respondents see more negative effects of human-like AI. Nine percent expect extremely negative effects, including the extinction of humanity. Compared to last year's survey, the extreme positions have lost some ground.
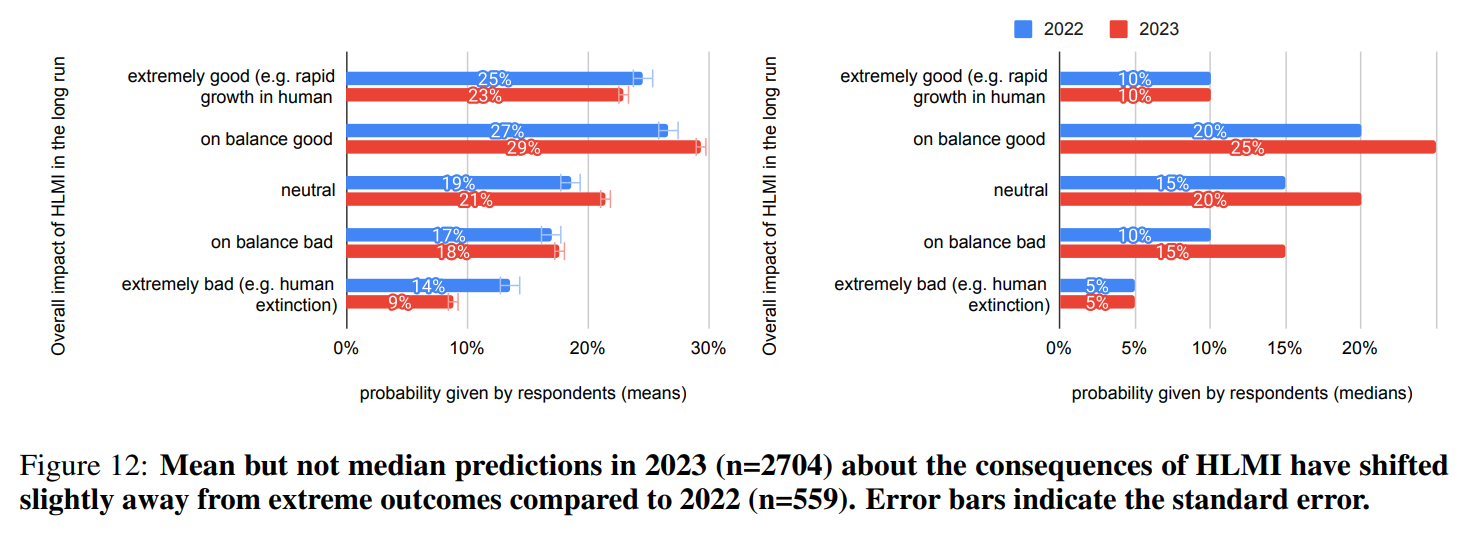
Image: Grace et al.
While 68.3 percent of respondents believe that good consequences of a possible superhuman AI are more likely than bad consequences, 48 percent of these net optimists give a probability of at least 5 percent for extremely bad consequences, such as the extinction of humanity. Conversely, 59 percent of net pessimists gave a probability of 5 percent or higher for extremely good outcomes.
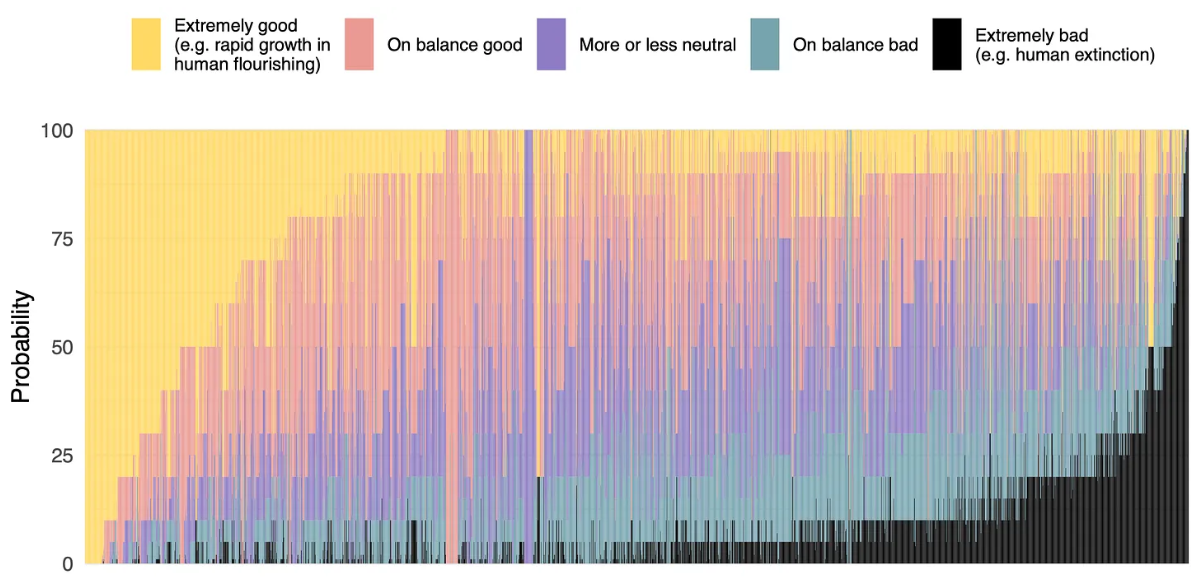
Image: Grace et al.
In terms of specific risks, disinformation and deepfakes are considered particularly threatening. This goes hand in hand with mass manipulation and AI-assisted population control by authoritarian rulers. By comparison, disruptions to the labor market are deemed less risky.
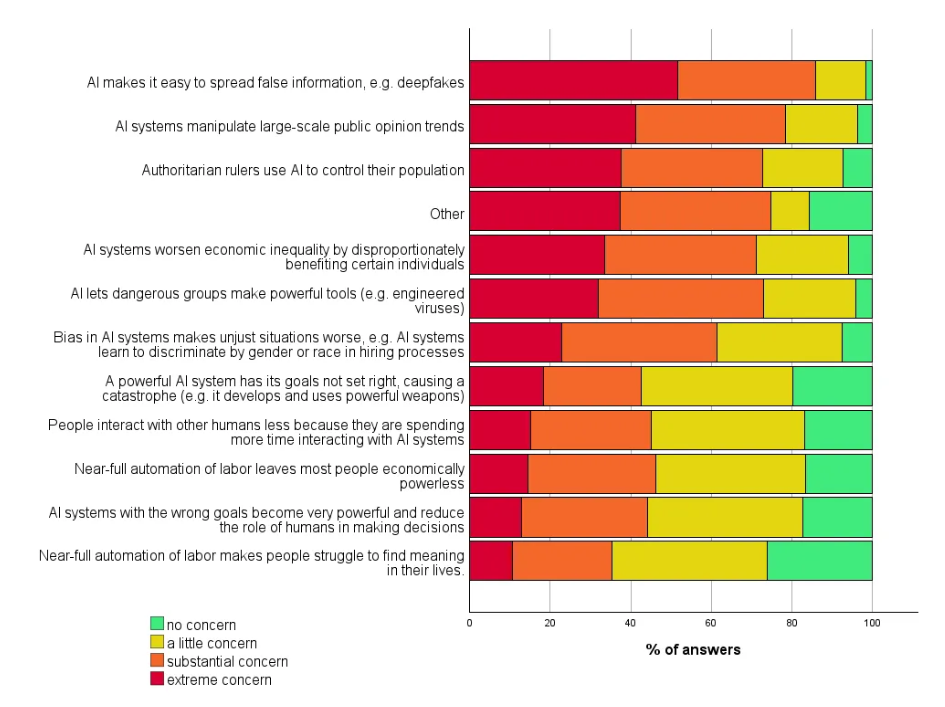
Image: Grace et al.
There was broad consensus (70 percent) that research into mitigating the potential risks of AI systems should be a higher priority.
The survey is based on responses from 2,778 attendees at six leading AI conferences. It was conducted in October 2023 and is the largest of its kind, according to the initiators. Compared to last year, more than three times as many attendees were surveyed across a broader range of AI research areas.
Support our independent, free-access reporting. Any contribution helps and secures our future. Support now:
Summary
- The "2023 Expert Survey on Progress in AI" shows that AI systems are expected to reach several milestones by 2028, many of them much sooner than previously thought, such as autonomously creating a website or generating a song in the style of a popular artist.
- The probability of machines outperforming humans in all possible tasks without outside help is estimated at 10% by 2027 and 50% by 2047, while the full automation of all human occupations is estimated at 10% by 2037 and 50% by 2116.
- Among the individual risks, disinformation and deepfakes are seen as particularly threatening. 70% of respondents agree that research into minimizing the potential risks of AI systems should be given higher priority.

DeepMind AI with built-in fact-checker makes mathematical discoveries
The AI company DeepMind claims it has developed a way to harness the creativity of chatbots to solve mathematical problems while filtering out mistakes
 www.newscientist.com
www.newscientist.com
DeepMind AI with built-in fact-checker makes mathematical discoveries
The AI company DeepMind claims it has developed a way to harness the creativity of chatbots to solve mathematical problems while filtering out mistakesBy Matthew Sparkes
14 December 2023

DeepMind’s FunSearch AI can tackle mathematical problems
alengo/Getty Images
Google DeepMind claims to have made the first ever scientific discovery with an AI chatbot by building a fact-checker to filter out useless outputs, leaving only reliable solutions to mathematical or computing problems.
Previous DeepMind achievements, such as using AI to predict the weather or protein shapes, have relied on models created specifically for the task at hand, trained on accurate and specific data. Large language models (LLMs), such as GPT-4 and Google’s Gemini, are instead trained on vast amounts of varied data to create a breadth of abilities. But that approach also makes them susceptible to “hallucination”, a term researchers use for producing false outputs.
Gemini – which was released earlier this month – has already demonstrated a propensity for hallucination, getting even simple facts such as the winners of this year’s Oscars wrong. Google’s previous AI-powered search engine even made errors in the advertising material for its own launch.
One common fix for this phenomenon is to add a layer above the AI that verifies the accuracy of its outputs before passing them to the user. But creating a comprehensive safety net is an enormously difficult task given the broad range of topics that chatbots can be asked about.
Alhussein Fawzi at Google DeepMind and his colleagues have created a generalised LLM called FunSearch based on Google’s PaLM2 model with a fact-checking layer, which they call an “evaluator”. The model is constrained to providing computer code that solves problems in mathematics and computer science, which DeepMind says is a much more manageable task because these new ideas and solutions are inherently and quickly verifiable.
The underlying AI can still hallucinate and provide inaccurate or misleading results, but the evaluator filters out erroneous outputs and leaves only reliable, potentially useful concepts.
“We think that perhaps 90 per cent of what the LLM outputs is not going to be useful,” says Fawzi. “Given a candidate solution, it’s very easy for me to tell you whether this is actually a correct solution and to evaluate the solution, but actually coming up with a solution is really hard. And so mathematics and computer science fit particularly well.”
DeepMind claims the model can generate new scientific knowledge and ideas – something LLMs haven’t done before.
To start with, FunSearch is given a problem and a very basic solution in source code as an input, then it generates a database of new solutions that are checked by the evaluator for accuracy. The best of the reliable solutions are given back to the LLM as inputs with a prompt asking it to improve on the ideas. DeepMind says the system produces millions of potential solutions, which eventually converge on an efficient result – sometimes surpassing the best known solution.
For mathematical problems, the model writes computer programs that can find solutions rather than trying to solve the problem directly.
Fawzi and his colleagues challenged FunSearch to find solutions to the cap set problem, which involves determining patterns of points where no three points make a straight line. The problem gets rapidly more computationally intensive as the number of points grows. The AI found a solution consisting of 512 points in eight dimensions, larger than any previously known.
When tasked with the bin-packing problem, where the aim is to efficiently place objects of various sizes into containers, FunSearch found solutions that outperform commonly used algorithms – a result that has immediate applications for transport and logistics companies. DeepMind says FunSearch could lead to improvements in many more mathematical and computing problems.
Read more
How maths can help you pack your shopping more efficiently
Mark Lee at the University of Birmingham, UK, says the next breakthroughs in AI won’t come from scaling-up LLMs to ever-larger sizes, but from adding layers that ensure accuracy, as DeepMind has done with FunSearch.
“The strength of a language model is its ability to imagine things, but the problem is hallucinations,” says Lee. “And this research is breaking that problem: it’s reining it in, or fact-checking. It’s a neat idea.”
Lee says AIs shouldn’t be criticised for producing large amounts of inaccurate or useless outputs, as this is not dissimilar to the way that human mathematicians and scientists operate: brainstorming ideas, testing them and following up on the best ones while discarding the worst.
Journal reference
Nature DOI: 10.1038/s41586-023-06924-6
Topics:

Humanoid robot acts out prompts like it's playing charades
A large language model can translate written instructions into code for a robot’s movement, enabling it to perform a wide range of human-like actions
www.newscientist.com
Humanoid robot acts out prompts like it's playing charades
A large language model can translate written instructions into code for a robot’s movement, enabling it to perform a wide range of human-like actions
By Alex Wilkins
4 January 2024
A humanoid robot that can perform actions based on text prompts could pave the way for machines that behave more like us and communicate using gestures.
Read more
Meet the robots that can reproduce, learn and evolve all by themselves
Large language models (LLMs) like GPT-4, the artificial intelligence behind ChatGPT, are proficient at writing many kinds of computer code, but they can struggle when it comes to doing this for robot movement. This is because almost every robot has very different physical forms and software to control its parts. Much of the code for this isn’t on the internet, and…
so isn’t in the training data that LLMs learn from.
Takashi Ikegami at the University of Tokyo in Japan and his colleagues suspected that humanoid robots might be easier for LLMs to control with code, because of their similarity to the human body. So they used GPT-4 to control a robot they had built, called Alter3, which has 43 different moving parts in its head, body and arms controlled by air pistons.

The Alter3 robot gestures in response to the prompt “I was enjoying a movie while eating popcorn at the theatre when I realised that I was actually eating the popcorn of the person next to me”
Takahide Yoshida et al
Ikegami and his team gave two prompts to GPT-4 to get the robot to carry out a particular movement. The first asks the LLM to translate the request into a list of concrete actions that the robot will have to perform to make the movement. A second prompt then asks the LLM to transform each item on the list into the Python programming language, with details of how the code maps to Alter3’s body parts.
They found that the system could come up with convincing actions for a wide range of requests, including simple ones like “pretend to be a snake” and “take a selfie with your phone”. It also got the robot to act out more complex scenes, such as “I was enjoying a movie while eating popcorn at the theatre when I realised that I was actually eating the popcorn of the person next to me”.
“This android can have more complicated and sophisticated facial and non-linguistic expressions so that the people can really understand, and be more empathic with, the android,” says Ikegami.
Though the requests currently take a minute or two to convert into code and move the robot, Ikegami hopes human-like motions might make our future interactions with robots more meaningful.
The study is an impressive technical display and can help open up robots to people who don’t know how to code, says Angelo Cangelosi at the University of Manchester, UK. But it doesn’t help robots gain more human-like intelligence because it relies on an LLM, which is a knowledge system very unlike the human brain, he says.
Reference:
arXiv DOI: 10.48550/arXiv.2312.06571
Topics:

OpenAI GPT Store launching next week
The key question will be: how much will OpenAI take for its cut of custom GPT sales/subscriptions? And will it be the App Store of the AI age?
 venturebeat.com
venturebeat.com
OpenAI GPT Store launching next week
Carl Franzen @carlfranzenJanuary 4, 2024 11:05 AM

Credit: VentureBeat made with Midjourney V6
OpenAI appears to be ready to kick off the year 2024 with a bang.
The company behind ChatGPT and arguably the one most responsible for bringing generative AI to the masses is gearing up to launch its GPT Store, where creators of third-party customized GPTs built with OpenAI’s new GPT Builder can sell and monetize their creations, next week — January 8-13, 2024.
OpenAI sent out an email today to those who have already created and launched custom GPTs through the GPT Builder, including this author. The email text reads as follows:
Dear GPT Builder,
We want to let you know that we will launch the GPT Store next week. If you’re interested in sharing your GPT in the store, you’ll need to:
- Review our updated usage policies and GPT brand guidelines to ensure that your GPT is compliant
- Verify your Builder Profile (settings > builder profile > enable your name or a verified website)
- Publish your GPT as ‘Public’ (GPT’s with ‘Anyone with a link’ selected will not be shown in the store)
Thank you for investing time to build a GPT.
– ChatGPT Team

An exact launch date, time, region and user availability were not given, and a spokesperson for OpenAI simply responded to our inquiry with: “Thanks for reaching out. We’ll have more to share here next week.”
What is the GPT Store and why is it so hyped?
First unveiled by OpenAI CEO and co-founder Sam Altman and his compatriots at OpenAI’s DevDay developer conference in November, the GPT Store was introduced as a place on the ChatGPT website for those who build with OpenAI’s tools to make cash while sharing their creations with a large audience.You need to use OpenAI’s GPT Builder to build customized GPTs atop OpenAI’s underlying, powerful large language model (LLM) GPT-4, but doing so is relatively simple and straightforward, especially compared to programming other software.
OpenAI’s GPT Builder lets you type the capabilities you want your GPT to offer in plain language, and it will try to make a simplified version of ChatGPT designed to perform those on behalf of you or any other users you share your GPT with. This can be done using a share link or the forthcoming store.
It immediately calls to mind Apple’s success with the App Store for the iPhone launched in the summer of 2008, and subsequently, iPad and Mac devices — which has resulted in trillions in annual revenue for third-party developers and of course, Apple itself, which takes a 30% cut on all sales. It has also been the target of antitrust lawsuits from the likes of Epic Games, though so far, it has largely withstood those.
Yet, like the Apple App Store, OpenAI’s GPT Store is not without controversy.
OpenAI initially promised to launch it in late 2023 but incurred massive drama after the former board of directors of its holding nonprofit fired Altman briefly before ultimately re-hiring him and stepping down themselves.
All that commotion — and the outsized attention toward the GPT Builder, as well as a reported distributed denial-of-service (DDoS) attack on OpenAI’s servers, likely slowed the launch of the GPT Store.
Critical questions remain
But when the OpenAI GPT Store finally does launch, the key question will be: how much will OpenAI take for its cut of custom GPT sales/subscriptions?Also important: what pricing options and mechanisms will they allow, how much will developers be able to charge and will it become the App Store of the AI age?
Already, the OpenAI GPT Store has one advantage to other third-party software stores: it doesn’t require a developer account or any software experience to participate. All it requires is an idea and a way to type it into the ChatGPT Builder, and of course, a subscription to OpenAI’s ChatGPT Plus or Enterprise, which starts at $20 per month USD.
How much detail is too much? Midjourney v6 attempts to find out
As Midjourney rolls out new features, it continues to make some artists furious.
BENJ EDWARDS - 1/5/2024, 1:41 PM
Enlarge / An AI-generated image of a "Beautiful queen of the universe looking at the camera in sci-fi armor, snow and particles flowing, fire in the background" created using alpha Midjourney v6.
Midjourney
124
In December, just before Christmas, Midjourney launched an alpha version of its latest image synthesis model, Midjourney v6. Over winter break, Midjourney fans put the new AI model through its paces, with the results shared on social media. So far, fans have noted much more detail than v5.2 (the current default) and a different approach to prompting. Version 6 can also handle generating text in a rudimentary way, but it's far from perfect.
FURTHER READING
“Stunning”—Midjourney update wows AI artists with camera-like feature"It's definitely a crazy update, both in good and less good ways," artist Julie Wieland, who frequently shares her Midjourney creations online, told Ars. "The details and scenery are INSANE, the downside (for now) are that the generations are very high contrast and overly saturated (imo). Plus you need to kind of re-adapt and rethink your prompts, working with new structures and now less is kind of more in terms of prompting."
At the same time, critics of the service still bristle about Midjourney training its models using human-made artwork scraped from the web and obtained without permission—a controversial practice common among AI model trainers we have covered in detail in the past. We've also covered the challenges artists might face in the future from these technologies elsewhere.
Too much detail?
With AI-generated detail ramping up dramatically between major Midjourney versions, one could wonder if there is ever such as thing as "too much detail" in an AI-generated image. Midjourney v6 seems to be testing that very question, creating many images that sometimes seem more detailed than reality in an unrealistic way, although that can be modified with careful prompting.Previous Slide Next Slide

- An AI-generated image of Mickey Mouse holding a machine gun created using alpha Midjourney v6.
Midjourney











In our testing of version 6 (which can currently be invoked with the "--v 6.0" argument at the end of a prompt), we noticed times when the new model appeared to produce worse results than v5.2, but Midjourney veterans like Wieland tell Ars that those differences are largely due to the different way that v6.0 interprets prompts. That is something Midjourney is continuously updating over time. "Old prompts sometimes work a bit better than the day they released it," Wieland told us.
 with the prompt a muscular barbarian with weapons beside a CRT television set, cinematic, 8K, studio lighting.")
Enlarge / A comparison between output from Midjourney versions (from left to right: v3, v4, v5, v5.2, v6) with the prompt "a muscular barbarian with weapons beside a CRT television set, cinematic, 8K, studio lighting."
Midjourney
We submitted Version 6 to our usual battery of image synthesis tests: barbarians with CRTs, cats holding cans of beer, plates of pickles, and Abraham Lincoln. Results felt a lot like Midjourney 5.2 but with more intricate detail. Compared to other AI image synthesis models available, Midjourney still seems to be the photorealism champion, although DALL-E 3 and fine-tuned versions of Stable Diffusion XL aren't far behind.
Compared with DALL-E 3, Midjourney v6 arguably bests its photorealism but falls behind in the prompt fidelity category. And yet v6 is notably more capable than v5.2 at handling descriptive prompts. "Version 6 is a bit more 'natural language,' less keywords and the usual prompt mechanics," says Wieland.
 and Midjourney v6 (right).")
Enlarge / An AI-generated comparison of Abraham Lincoln using a computer at his desk using DALL-E 3 (left) and Midjourney v6 (right).
OpenAI, Midjourney
In an announcement on the Midjourney Discord, Midjourney creator David Holz described changes to v6:
Much more accurate prompt following as well as longer prompts
Improved coherence, and model knowledge
Improved image prompting and remix
Minor text drawing ability (you must write your text in "quotations" and --style raw or lower --stylize values may help)
/imagine a photo of the text "Hello World!" written with a marker on a sticky note --ar 16:9 --v 6
Improved upscalers, with both 'subtle' and 'creative' modes (increases resolution by 2x)
(you'll see buttons for these under your images after clicking U1/U2/U3/U4)
Style and prompting for V6
Prompting with V6 is significantly different than V5. You will need to 'relearn' how to prompt.
V6 is MUCH more sensitive to your prompt. Avoid 'junk' like "award winning, photorealistic, 4k, 8k"
Be explicit about what you want. It may be less vibey but if you are explicit it's now MUCH better at understanding you.
If you want something more photographic / less opinionated / more literal you should probably default to using --style raw
Lower values of --stylize (default 100) may have better prompt understanding while higher values (up to 1000) may have better aesthetics
Midjourney v6 is still a work in progress, with Holz announcing that things will change rapidly over the coming months. "DO NOT rely on this exact model being available in the future," he wrote. "It will significantly change as we take V6 to full release." As far as the current limitations go, Wieland says, "I try to keep in mind that this is just v6 alpha and they will do updates without announcements and it kind of feels, like they already did a few updates."
Midjourney is also working on a web interface that will be an alternative to (and potentially a replacement of) the current Discord-only interface. The new interface is expected to widen Midjourney's audience by making it more accessible.
An unresolved controversy
FURTHER READING
From toy to tool: DALL-E 3 is a wake-up call for visual artists—and the rest of usDespite these technical advancements, Midjourney remains highly polarizing and controversial for some people. At the turn of this new year, viral threads emerged on social media from frequent AI art foes, criticizing the service anew. The posts shared screenshots of early conversations among Midjourney developers discussing how the technology could simulate many existing artists' styles. They included lists of artists and styles in the Midjourney training dataset that were revealed in November during discovery in a copyright lawsuit against Midjourney.
Some companies producing AI synthesis models, such as Adobe, seek to avoid these issues by training their models only on licensed images. But Midjourney's strength arguably comes from its ability to play fast and loose with intellectual property. It's undeniably cheaper to grab training data for free online than to license hundreds of millions of images. Until the legality of that kind of scraping is resolved in the US—or Midjourney adopts a different training approach—no matter how detailed or capable Midjourney gets, its ethics will continue to be debated.

Steering at the Frontier: Extending the Power of Prompting - Microsoft Research
We’re seeing exciting capabilities of frontier foundation models, including intriguing powers of abstraction, generalization, and composition across numerous areas of knowledge and expertise. Even seasoned AI researchers have been impressed with the ability to steer the models with...
www.microsoft.com
Microsoft Research Blog
Steering at the Frontier: Extending the Power of Prompting
Published December 12, 2023By Eric Horvitz, Chief Scientific Officer Harsha Nori, Director, Research Engineering Yin Tat Lee, Principal Researcher
Share this page

We’re seeing exciting capabilities of frontier foundation models, including intriguing powers of abstraction, generalization, and composition across numerous areas of knowledge and expertise. Even seasoned AI researchers have been impressed with the ability to steer the models with straightforward, zero-shot prompts. Beyond basic, out-of-the-box prompting, we’ve been exploring new prompting strategies, showcased in our Medprompt work, to evoke the powers of specialists.
Today, we’re sharing information on Medprompt and other approaches to steering frontier models in promptbase(opens in new tab), a collection of resources on GitHub. Our goal is to provide information and tools to engineers and customers to evoke the best performance from foundation models. We’ll start by including scripts that enable replication of our results using the prompting strategies that we present here. We’ll be adding more sophisticated general-purpose tools and information over the coming weeks.
As an illustration of the capabilities of the frontier models and on opportunities to harness and extend the recent efforts with reaching state-of-the-art (SoTA) results via steering GPT-4, we’ll review SoTA results on benchmarks that Google chose for evaluating Gemini Ultra. Our end-to-end exploration, prompt design, and computing of performance took just a couple of days.
MICROSOFT RESEARCH PODCAST

AI Frontiers: The future of causal reasoning with Emre Kiciman and Amit Sharma
Emre Kiciman and Amit Sharma discuss their paper “Causal Reasoning and Large Language Models: Opening a New Frontier for Causality” and how it examines the causal capabilities of large language models (LLMs) and their implications.Listen now
Opens in a new tab
Let’s focus on the well-known MMLU(opens in new tab) (Measuring Massive Multitask Language Understanding) challenge that was established as a test of general knowledge and reasoning powers of large language models. The complete MMLU benchmark contains tens of thousands of challenge problems of different forms across 57 areas from basic mathematics to United States history, law, computer science, engineering, medicine, and more.
In our Medprompt study, we focused on medical challenge problems, but found that the prompt strategy could have more general-purpose application and examined its performance on several out-of-domain benchmarks—despite the roots of the work on medical challenges. Today, we report that steering GPT-4 with a modified version of Medprompt achieves the highest score ever achieved on the complete MMLU.
 achieved 78.4% accuracy, Claude 2 (5-shot CoT) achieved 78.5% accuracy, Inflection-2 (5-shot) achieved 79.6% accuracy, Google Pro (CoT@8) achieved 79.13% accuracy, Gemini Ultra (CoT@32) achieved 90.04% accuracy, GPT-4-1106 (5-Shot) achieved 86.4% accuracy, GPT-4-1106 (Medprompt @ 5) achieved 89.1% accuracy, GPT-4-1106 (Medprompt @ 20) achieved 89.56% accuracy, and GPT-4-1106 (Medprompt @ 31) achieved 90.10% accuracy.")
Figure1. Reported performance of multiple models and methods on the MMLU benchmark.
In our explorations, we initially found that applying the original Medprompt to GPT-4 on the comprehensive MMLU achieved a score of 89.1%. By increasing the number of ensembled calls in Medprompt from five to 20, performance by GPT-4 on the MMLU further increased to 89.56%. To achieve a new SoTA on MMLU, we extended Medprompt to Medprompt+ by adding a simpler prompting method and formulating a policy for deriving a final answer by integrating outputs from both the base Medprompt strategy and the simple prompts. The synthesis of a final answer is guided by a control strategy governed by GPT-4 and inferred confidences of candidate answers. More details on Medprompt+ are provided in the promptbase repo. A related method for coupling complex and simple queries was harnessed by the Google Gemini team. GPT-4 steered with the modified Medprompt+ reaches a record score of 90.10%. We note that Medprompt+ relies on accessing confidence scores (logprobs) from GPT-4. These are not publicly available via the current API but will be enabled for all in the near future.
While systematic prompt engineering can yield maximal performance, we continue to explore the out-of-the-box performance of frontier models with simple prompts. It’s important to keep an eye on the native power of GPT-4 and how we can steer the model with zero- or few-shot prompting strategies. As demonstrated in Table 1, starting with simple prompting is useful to establish baseline performance before layering in more sophisticated and expensive methods.
| Benchmark | GPT-4 Prompt | GPT-4 Results | Gemini Ultra Results |
|---|---|---|---|
| MMLU | Medprompt+ | 90.10% | 90.04% |
| GSM8K | Zero-shot | 95.27% | 94.4% |
| MATH | Zero-shot | 68.42% | 53.2% |
| HumanEval | Zero-shot | 87.8% | 74.4% |
| BIG-Bench-Hard | Few-shot + CoT* | 89.0% | 83.6% |
| DROP | Zero-shot + CoT | 83.7% | 82.4% |
| HellaSwag | 10-shot** | 95.3%** | 87.8% |
* followed the norm of evaluations and used standard few-shot examples from dataset creators
** source: Google
Table 1: Model, strategies, and results
We encourage you to check out the promptbase repo(opens in new tab) on GitHub for more details about prompting techniques and tools. This area of work is evolving with much to learn and share. We’re excited about the directions and possibilities ahead.
GitHub - microsoft/promptbase: All things prompt engineering
All things prompt engineering. Contribute to microsoft/promptbase development by creating an account on GitHub.
github.com
About
All things prompt engineeringpromptbase
promptbase is an evolving collection of resources, best practices, and example scripts for eliciting the best performance from foundation models like GPT-4. We currently host scripts demonstrating the Medprompt methodology, including examples of how we further extended this collection of prompting techniques ("Medprompt+") into non-medical domains:| Benchmark | GPT-4 Prompt | GPT-4 Results | Gemini Ultra Results |
|---|---|---|---|
| MMLU | Medprompt+ | 90.10% | 90.04% |
| GSM8K | Zero-shot | 95.3% | 94.4% |
| MATH | Zero-shot | 68.4% | 53.2% |
| HumanEval | Zero-shot | 87.8% | 74.4% |
| BIG-Bench-Hard | Few-shot + CoT | 89.0% | 83.6% |
| DROP | Zero-shot + CoT | 83.7% | 82.4% |
| HellaSwag | 10-shot | 95.3% | 87.8% |
In the near future,
promptbase will also offer further case studies and structured interviews around the scientific process we take behind prompt engineering. We'll also offer specialized deep dives into specialized tooling that accentuates the prompt engineering process. Stay tuned!Medprompt and The Power of Prompting
"Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine" (H. Nori, Y. T. Lee, S. Zhang, D. Carignan, R. Edgar, N. Fusi, N. King, J. Larson, Y. Li, W. Liu, R. Luo, S. M. McKinney, R. O. Ness, H. Poon, T. Qin, N. Usuyama, C. White, E. Horvitz 2023)
In a recent study, we showed how the composition of several prompting strategies into a method that we refer to as
Medprompt can efficiently steer generalist models like GPT-4 to achieve top performance, even when compared to models specifically finetuned for medicine. Medprompt composes three distinct strategies together -- including dynamic few-shot selection, self-generated chain of thought, and choice-shuffle ensembling -- to elicit specialist level performance from GPT-4. We briefly describe these strategies here:

TinyLlama 1.1B powerful small AI model trained on 3 trillion tokens
If you are interested in using and installing TinyLlama 1.1B, a new language model that packs a punch despite its small size. This quick guide will take
 www.geeky-gadgets.com
www.geeky-gadgets.com
Computer Science > Computation and Language
[Submitted on 4 Jan 2024]TinyLlama: An Open-Source Small Language Model
Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, Wei LuWe present TinyLlama, a compact 1.1B language model pretrained on around 1 trillion tokens for approximately 3 epochs. Building on the architecture and tokenizer of Llama 2, TinyLlama leverages various advances contributed by the open-source community (e.g., FlashAttention), achieving better computational efficiency. Despite its relatively small size, TinyLlama demonstrates remarkable performance in a series of downstream tasks. It significantly outperforms existing open-source language models with comparable sizes. Our model checkpoints and code are publicly available on GitHub at this https URL.
| Comments: | Technical Report |
| Subjects: | Computation and Language (cs.CL); Artificial Intelligence (cs.AI) |
| Cite as: | arXiv:2401.02385 [cs.CL] |
| (or arXiv:2401.02385v1 [cs.CL] for this version) | |
| [2401.02385] TinyLlama: An Open-Source Small Language Model Focus to learn more |
Submission history
From: Guangtao Zeng [ view email][v1] Thu, 4 Jan 2024 17:54:59 UTC (1,783 KB)
Abstract
We present TinyLlama, a compact 1.1B language model pretrained on around 1 trillion tokens for approximately 3 epochs. Building on the architecture and tokenizer of Llama 2 ( Touvron et al., 2023b,), TinyLlama leverages various advances contributed by the open-source community (e.g., FlashAttention (Dao,, 2023)), achieving better computational efficiency. Despite its relatively small size, TinyLlama demonstrates remarkable performance in a series of downstream tasks. It significantly outperforms existing open-source language models with comparable sizes. Our model checkpoints and code are publicly available on GitHub at GitHub - jzhang38/TinyLlama: The TinyLlama project is an open endeavor to pretrain a 1.1B Llama model on 3 trillion tokens..
1The first two authors contributed equally.
1The first two authors contributed equally.
1Introduction
Recent progress in natural language processing (NLP) has been largely propelled by scaling up language model sizes (Brown et al.,, 2020; Chowdhery et al.,, 2022; Touvron et al., 2023a,; Touvron et al., 2023b,). Large Language Models (LLMs) pre-trained on extensive text corpora have demonstrated their effectiveness on a wide range of tasks (OpenAI,, 2023; Touvron et al., 2023b,). Some empirical studies demonstrated emergent abilities in LLMs, abilities that may only manifest in models with a sufficiently large number of parameters, such as few-shot prompting (Brown et al.,, 2020) and chain-of-thought reasoning (Wei et al.,, 2022). Other studies focus on modeling the scaling behavior of LLMs (Kaplan et al.,, 2020; Hoffmann et al.,, 2022). Hoffmann et al., ( 2022) suggest that, to train a compute-optimal model, the size of the model and the amount of training data should be increased at the same rate. This provides a guideline on how to optimally select the model size and allocate the amount of training data when the compute budget is fixed.
Although these works show a clear preference on large models, the potential of training smaller models with larger dataset remains under-explored. Instead of training compute-optimal language models, Touvron et al., 2023a highlight the importance of the inference budget, instead of focusing solely on training compute-optimal language models. Inference-optimal language models aim for optimal performance within specific inference constraints This is achieved by training models with more tokens than what is recommended by the scaling law (Hoffmann et al.,, 2022). Touvron et al., 2023a demonstrates that smaller models, when trained with more data, can match or even outperform their larger counterparts. Also, Thaddée, ( 2023) suggest that existing scaling laws (Hoffmann et al.,, 2022) may not predict accurately in situations where smaller models are trained for longer periods.
Motivated by these new findings, this work focuses on exploring the behavior of smaller models when trained with a significantly larger number of tokens than what is suggested by the scaling law (Hoffmann et al.,, 2022). Specifically, we train a Transformer decoder-only model (Vaswani et al.,, 2017) with 1.1B parameters using approximately 3 trillion tokens. To our knowledge, this is the first attempt to train a model with 1B parameters using such a large amount of data. Following the same architecture and tokenizer as Llama 2 ( Touvron et al., 2023b,), we name our model TinyLlama. TinyLlama shows competitive performance compared to existing open-source language models of similar sizes. Specifically, TinyLlama surpasses both OPT-1.3B (Zhang et al.,, 2022) and Pythia-1.4B (Biderman et al.,, 2023) in various downstream tasks.
Our TinyLlama is open-source, aimed at improving accessibility for researchers in language model research. We believe its excellent performance and compact size make it an attractive platform for researchers and practitioners in language model research.
Although these works show a clear preference on large models, the potential of training smaller models with larger dataset remains under-explored. Instead of training compute-optimal language models, Touvron et al., 2023a highlight the importance of the inference budget, instead of focusing solely on training compute-optimal language models. Inference-optimal language models aim for optimal performance within specific inference constraints This is achieved by training models with more tokens than what is recommended by the scaling law (Hoffmann et al.,, 2022). Touvron et al., 2023a demonstrates that smaller models, when trained with more data, can match or even outperform their larger counterparts. Also, Thaddée, ( 2023) suggest that existing scaling laws (Hoffmann et al.,, 2022) may not predict accurately in situations where smaller models are trained for longer periods.
Motivated by these new findings, this work focuses on exploring the behavior of smaller models when trained with a significantly larger number of tokens than what is suggested by the scaling law (Hoffmann et al.,, 2022). Specifically, we train a Transformer decoder-only model (Vaswani et al.,, 2017) with 1.1B parameters using approximately 3 trillion tokens. To our knowledge, this is the first attempt to train a model with 1B parameters using such a large amount of data. Following the same architecture and tokenizer as Llama 2 ( Touvron et al., 2023b,), we name our model TinyLlama. TinyLlama shows competitive performance compared to existing open-source language models of similar sizes. Specifically, TinyLlama surpasses both OPT-1.3B (Zhang et al.,, 2022) and Pythia-1.4B (Biderman et al.,, 2023) in various downstream tasks.
Our TinyLlama is open-source, aimed at improving accessibility for researchers in language model research. We believe its excellent performance and compact size make it an attractive platform for researchers and practitioners in language model research.
GitHub - jzhang38/TinyLlama: The TinyLlama project is an open endeavor to pretrain a 1.1B Llama model on 3 trillion tokens.
The TinyLlama project is an open endeavor to pretrain a 1.1B Llama model on 3 trillion tokens. - GitHub - jzhang38/TinyLlama: The TinyLlama project is an open endeavor to pretrain a 1.1B Llama mode...
github.com
About
The TinyLlama project is an open endeavor to pretrain a 1.1B Llama model on 3 trillion tokens.TinyLlama-1.1B
The TinyLlama project aims to pretrain a 1.1B Llama model on 3 trillion tokens. With some proper optimization, we can achieve this within a span of "just" 90 days using 16 A100-40G GPUs
 . The training has started on 2023-09-01.
. The training has started on 2023-09-01. We adopted exactly the same architecture and tokenizer as Llama 2. This means TinyLlama can be plugged and played in many open-source projects built upon Llama. Besides, TinyLlama is compact with only 1.1B parameters. This compactness allows it to cater to a multitude of applications demanding a restricted computation and memory footprint.