
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Large Language Models News & Discussions
- Thread starter Macallik86
- Start date
More options
Who Replied?PoorAndDangerous
Superstar
Has anyone used Grok yet? How is it? GPT 4 has had some great updates lately. It's accuracy in transcribing text in an image has been a bit hit or miss though
{MEDIA=twitter]1726734804450705756[/MEDIA]


DEMO:
deepseek-coder-7b-instruct
DeepSeek-6.7B-Chat
This space demonstrates model DeepSeek-Coder by DeepSeek, a code model with 6.7B parameters fine-tuned for chat instructions.
DEMO:
deepseek-coder-7b-instruct
DeepSeek-6.7B-Chat
This space demonstrates model DeepSeek-Coder by DeepSeek, a code model with 6.7B parameters fine-tuned for chat instructions.
Last edited:
System 2 Attention (is something you might need too)
Soft attention in Transformer-based Large Language Models (LLMs) is susceptible to incorporating irrelevant information from the context into its latent representations, which adversely affects next token generations. To help rectify these issues, we introduce System 2 Attention (S2A), which...
Computer Science > Computation and Language
[Submitted on 20 Nov 2023]System 2 Attention (is something you might need too)
Jason Weston, Sainbayar SukhbaatarSoft attention in Transformer-based Large Language Models (LLMs) is susceptible to incorporating irrelevant information from the context into its latent representations, which adversely affects next token generations. To help rectify these issues, we introduce System 2 Attention (S2A), which leverages the ability of LLMs to reason in natural language and follow instructions in order to decide what to attend to. S2A regenerates the input context to only include the relevant portions, before attending to the regenerated context to elicit the final response. In experiments, S2A outperforms standard attention-based LLMs on three tasks containing opinion or irrelevant information, QA, math word problems and longform generation, where S2A increases factuality and objectivity, and decreases sycophancy.
| Subjects: | Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG) |
| Cite as: | arXiv:2311.11829 [cs.CL] |
| (or arXiv:2311.11829v1 [cs.CL] for this version) | |
| [2311.11829] System 2 Attention (is something you might need too) Focus to learn more |
Submission history
From: Jason Weston [view email][v1] Mon, 20 Nov 2023 15:04:50 UTC (97 KB)
AI summary:
System 2 Attention is a way to help LLM's understand what parts of a sentence are important and what parts are not. It does this by looking at the sentence and deciding which words are relevant and which ones are not. This helps the LLM generate better responses to questions and problems. It’s like when you’re reading a book and you only focus on the important parts, instead of reading every single word. This is important because sometimes LLM's can get confused by too much information and give the wrong answer. System 2 Attention helps the LLM focus on the right information and give better answers. It has been shown to work better than other methods on tasks like answering questions and generating long-form text.
GitHub - camenduru/latent-consistency-model-colab
Contribute to camenduru/latent-consistency-model-colab development by creating an account on GitHub.
 github.com
github.com
Pretty Amazing Stuff - Starling-7B model, that dropped today, performs almost as well as GPT-4 in everything except math, reasoning and code!
Starling in an open-source reward model and uses synthetic data from multiple-models combined with online RLAIF to fine-tune Llama-7B!
Super cool to see a 7B model match GPT-4 performance on certain aspects. Once again, it's amazing how much supervised labelled data can improvel LLM performance.
Open-source still needs to catch up on reasoning, math and code-gen - all related to each other. The good news is that it is definitely very possible to move the needle on all 3 fronts.
A $10M prize was just announced for anyone who releases a public model that does well on math olympiad questions - so thre is a lot of impetus to get better.

berkeley-nest/Starling-LM-7B-alpha · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/Starling-LM-7B-alpha-GGUF · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

TheBloke/Starling-LM-7B-alpha-AWQ · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
| Model | Tuning Method | MT Bench | AlpacaEval | MMLU |
|---|---|---|---|---|
| GPT-4-Turbo | ? | 9.32 | 97.70 | |
| GPT-4 | SFT + PPO | 8.99 | 95.28 | 86.4 |
| Starling-7B | C-RLFT + APA | 8.09 | 91.99 | 63.9 |
| Claude-2 | ? | 8.06 | 91.36 | 78.5 |
| GPT-3.5-Turbo | ? | 7.94 | 89.37 | 70 |
| Claude-1 | ? | 7.9 | 88.39 | 77 |
| Tulu-2-dpo-70b | SFT + DPO | 7.89 | 95.1 | |
| Openchat-3.5 | C-RLFT | 7.81 | 88.51 | 64.3 |
| Zephyr-7B-beta | SFT + DPO | 7.34 | 90.60 | 61.4 |
| Llama-2-70b-chat-hf | SFT + PPO | 6.86 | 92.66 | 63 |
| Neural-chat-7b-v3-1 | SFT + DPO | 6.84 | 84.53 | 62.4 |
| Tulu-2-dpo-7b | SFT + DPO | 6.29 | 85.1 |
Starling-7B: Increasing LLM Helpfulness & Harmlessness with RLAIF
Author: Banghua Zhu * , Evan Frick * , Tianhao Wu * , Hanlin Zhu and Jiantao JiaoStarling-LM-7B (generated by DALL·E 3)
We introduce Starling-7B, an open large language model (LLM) trained by Reinforcement Learning from AI Feedback (RLAIF). The model harnesses the power of our new GPT-4 labeled ranking dataset, Nectar, and our new reward training and policy tuning pipeline. Starling-7B-alpha scores 8.09 in MT Bench with GPT-4 as a judge, outperforming every model to date on MT-Bench except for OpenAI’s GPT-4 and GPT-4 Turbo. We release the ranking dataset Nectar, the reward model Starling-RM-7B-alpha and the language model Starling-LM-7B-alpha on HuggingFace, and an online demo in LMSYS Chatbot Arena. Stay tuned for our forthcoming code and paper, which will provide more details on the whole process.
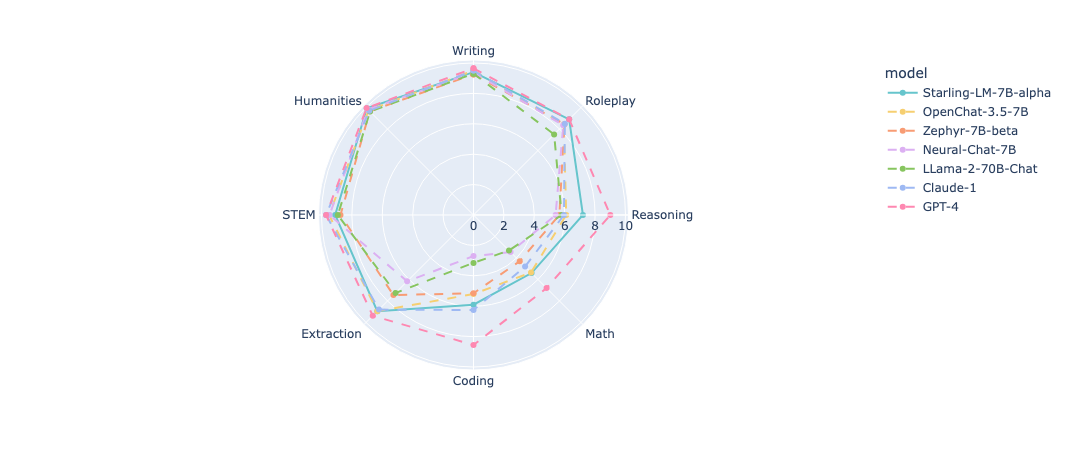
*Based on MT Bench evaluations, using GPT-4 scoring. Further human evaluation is needed.
Overview
Supervised fine-tuning (SFT) has demonstrated remarkable effectiveness in developing chatbot systems from language models, particularly when leveraging high-quality data distilled from ChatGPT/GPT-4 (examples include Alpaca, Vicuna, OpenHermes 2.5, and Openchat 3.5). However, the extent to which Reinforcement Learning from Human Feedback (RLHF) or AI feedback (RLAIF) can enhance models when scaling high-quality preference data remains an open question. Earlier endeavors in the open-source community, such as Zephyra-7B, Neural-Chat-7B, and Tulu-2-DPO-70B, employed Direct Preference Optimization (DPO), but their performance in MT Bench (and some in Chatbot Arena), when compared to leading SFT models like OpenHermes 2.5 and Openchat 3.5, has not fully showcased RLHF’s potential.To facilitate more thorough research into RLHF, a high-quality ranking dataset specifically for chat is essential. We release Nectar, a GPT-4 labeled ranking dataset composed of 183K chat prompts. Each prompt includes 7 responses distilled from various models like GPT-4, GPT-3.5-instruct, GPT-3.5-turbo, Mistral-7B-Instruct, Llama2-7B, resulting in a total of 3.8M pairwise comparisons. Considerable effort was invested in mitigating positional bias when prompting GPT-4 for rankings, the details of which are elaborated in the dataset section below.
Moreover, there is a notable scarcity of open-source reward models. We address this gap by releasing our reward model Starling-RM-7B-alpha, trained with our K-wise loss on the Nectar dataset.
Lastly, we fine-tuned the Openchat 3.5 language model using the learned reward model. This resulted in an increase in the MT-Bench score from 7.81 to 8.09, and an improvement in the AlpacaEval score from 88.51% to 91.99%. Both metrics assess the chatbot’s helpfulness.
We hope the open-sourced dataset, reward model and language model can help deepen the understanding of the RLHF mechanism and contribute to AI safety research. Our team is actively exploring various training methodologies for both the reward and language models, and will continue to update this blog with our findings and model releases.
Evaluation of the Model
Evaluating chatbots is never a simple task. We mainly evaluate the helpfulness of our models based on MT-Bench and AlpacaEval, which are GPT-4-based comparisons. We also test the basic capability of the model via MMLU. The results are listed below.In line with findings in GPT-4 Technical Report, our observations post-RLHF reveal similar trends. We’ve observed improvements in the model’s helpfulness and safety features; however, its basic capabilities in areas like knowledge-based QA, math, and coding have either remained static or experienced minor regression. We also detected a tendency for the model to respond with excessive caution to certain benign prompts after initial RLHF, while still showing vulnerabilities to jailbreaking attempts. This may require further fine-tuning with rule-based reward models with GPT-4 as classifiers, similar to what is done in the GPT-4 Technical Report. In the upcoming release of the paper, we will also benchmark the quality of the reward model, and the safety of the language model.
Can someone explain the significance and utility of all these open-source models? Is the goal to make them as powerful as GPT4 but with less compute? I've been following this space for a while but I still don't see the purpose of all these open source models. What's the advantage of using open-source models over using the free version of ChatGPT or Bing (which used GPT4)?

GPT-4's potential in shaping the future of radiology
As the benefits of AI in healthcare continue to emerge, we investigate GPT-4's potential in radiology. Learn about research exploring GPT-4’s potential in assisting report structuring, classifying diseases, and generating comprehensive findings summaries:
www.microsoft.com
GPT-4’s potential in shaping the future of radiology
Published November 27, 2023By Javier Alvarez-Valle , Senior Director of Biomedical Imaging Matthew Lungren , Chief Medical Information Officer, Nuance Communications
This research paper is being presented at the 2023 Conference on Empirical Methods in Natural Language Processing(opens in new tab) (EMNLP 2023), the premier conference on natural language processing and artificial intelligence.

- PROJECTProject MAIRA
In recent years, AI has been increasingly integrated into healthcare, bringing about new areas of focus and priority, such as diagnostics, treatment planning, patient engagement. While AI’s contribution in certain fields like image analysis and drug interaction is widely recognized, its potential in natural language tasks with these newer areas presents an intriguing research opportunity.
One notable advancement in this area involves GPT-4’s impressive performance(opens in new tab) on medical competency exams and benchmark datasets. GPT-4 has also demonstrated potential utility(opens in new tab) in medical consultations, providing a promising outlook for healthcare innovation.
Progressing radiology AI for real problems
Our paper, “Exploring the Boundaries of GPT-4 in Radiology(opens in new tab),” which we are presenting at EMNLP 2023(opens in new tab), further explores GPT-4’s potential in healthcare, focusing on its abilities and limitations in radiology—a field that is crucial in disease diagnosis and treatment through imaging technologies like x-rays, computed tomography (CT) and magnetic resonance imaging (MRI). We collaborated with our colleagues at Nuance(opens in new tab), a Microsoft company, whose solution, PowerScribe, is used by more than 80 percent of US radiologists. Together, we aimed to better understand technology’s impact on radiologists’ workflow.Our research included a comprehensive evaluation and error analysis framework to rigorously assess GPT-4’s ability to process radiology reports, including common language understanding and generation tasks in radiology, such as disease classification and findings summarization. This framework was developed in collaboration with a board-certified radiologist to tackle more intricate and challenging real-world scenarios in radiology and move beyond mere metric scores.
We also explored various effective zero-, few-shot, and chain-of-thought (CoT) prompting techniques for GPT-4 across different radiology tasks and experimented with approaches to improve the reliability of GPT-4 outputs. For each task, GPT-4 performance was benchmarked against prior GPT-3.5 models and respective state-of-the-art radiology models.
We found that GPT-4 demonstrates new state-of-the-art performance in some tasks, achieving about a 10-percent absolute improvement over existing models, as shown in Table 1. Surprisingly, we found radiology report summaries generated by GPT-4 to be comparable and, in some cases, even preferred over those written by experienced radiologists, with one example illustrated in Table 2.


Another encouraging prospect for GPT-4 is its ability to automatically structure radiology reports, as schematically illustrated in Figure 1. These reports, based on a radiologist’s interpretation of medical images like x-rays and include patients’ clinical history, are often complex and unstructured, making them difficult to interpret. Research shows that structuring these reports can improve standardization and consistency in disease descriptions, making them easier to interpret by other healthcare providers and more easily searchable for research and quality improvement initiatives. Additionally, using GPT-4 to structure and standardize radiology reports can further support efforts to augment real-world data (RWD) and its use for real-world evidence (RWE). This can complement more robust and comprehensive clinical trials and, in turn, accelerate the application of research findings into clinical practice.

Beyond radiology, GPT-4’s potential extends to translating medical reports into more empathetic(opens in new tab) and understandable formats for patients and other health professionals. This innovation could revolutionize patient engagement and education, making it easier for them and their carers to actively participate in their healthcare.
MICROSOFT RESEARCH PODCAST

Abstracts: October 23, 2023
On “Abstracts,” Partner Research Manager Andy Gordon & Senior Researcher Carina Negreanu explore new work introducing co-audit, a term for any tool-assisted experience that helps users of generative AI find and fix mistakes in AI output.Listen now
Opens in a new tab
A promising path toward advancing radiology and beyond
When used with human oversight, GPT-4 also has the potential to transform radiology by assisting professionals in their day-to-day tasks. As we continue to explore this cutting-edge technology, there is great promise in improving our evaluation results of GPT-4 by investigating how it can be verified more thoroughly and finding ways to improve its accuracy and reliability.Our research highlights GPT-4’s potential in advancing radiology and other medical specialties, and while our results are encouraging, they require further validation through extensive research and clinical trials. Nonetheless, the emergence of GPT-4 heralds an exciting future for radiology. It will take the entire medical community working alongside other stakeholders in technology and policy to determine the appropriate use of these tools and responsibly realize the opportunity to transform healthcare. We eagerly anticipate its transformative impact towards improving patient care and safety.
Learn more about this work by visiting the Project MAIRA(opens in new tab) (Multimodal AI for Radiology Applications) page.
Acknowledgements
We’d like to thank our coauthors: Qianchu Liu, Stephanie Hyland, Shruthi Bannur, Kenza Bouzid, Daniel C. Castro, Maria Teodora Wetscherek, Robert Tinn, Harshyta Sharma, Fernando Perez-Garcia, Anton Schwaighofer, Pranav Rajpurkar, Sameer Tajdin Khanna, Hoifung Poon, Naoto Usuyama, Anja Thieme, Aditya V. Nori, Ozan Oktay
Last edited:

Amazon Introduces Q, an A.I. Chatbot for Companies (Published 2023)
Amazon has been racing to shake off the perception that it is lagging in the push to take advantage of artificial intelligence.
Amazon Introduces Q, an A.I. Chatbot for Companies
Amazon has been racing to shake off the perception that it is lagging in the push to take advantage of artificial intelligence.
Amazon’s new A.I. chatbot, Q.CreditCredit...Video by Amazon Web Services
By Karen Weise
Reporting from Seattle
Nov. 28, 2023Updated 2:10 p.m. ET
OpenAI has ChatGPT. Google has the Bard chatbot. Microsoft has its Copilots. On Tuesday, Amazon joined the chatbot race and announced an artificial intelligence assistant of its own: Amazon Q.
The chatbot, developed by Amazon’s cloud computing division, is focused on workplaces and not intended for consumers. Amazon Q aims to help employees with daily tasks, such as summarizing strategy documents, filling out internal support tickets and answering questions about company policy. It will compete with other corporate chatbots, including Copilot, Google’s Duet AI and ChatGPT Enterprise.
“We think Q has the potential to become a work companion for millions and millions of people in their work life,” Adam Selipsky, the chief executive of Amazon Web Services, said in an interview.
Image

Adam Selipsky, the head of Amazon Web Services, last year. He said companies wanted to use chatbots but were concerned about data security and privacy.Credit...Noah Berger/Amazon Web Services, via Associated Press
Amazon has been racing to shake off the perception that it is lagging behind in the A.I. competition. In the year since OpenAI released ChatGPT, Google, Microsoft and others have jumped into the frenzy by unveiling their own chatbots and investing heavily in A.I. development.
Amazon was quieter about its A.I. plans until more recently. In September, it announced that it would invest up to $4 billion in Anthropic, an A.I. start-up that competes with OpenAI, and develop advanced computing chips together. Amazon also introduced a platform this year that allows customers to have access to different A.I. systems.
As the leading provider of cloud computing, Amazon already has business customers storing vast amounts of information on its cloud servers. Companies were interested in using chatbots in their workplaces, Mr. Selipsky said, but they wanted to make sure the assistants would safeguard those hoards of corporate data and keep their information private.
Many companies “told me that they had banned these A.I. assistants from the enterprise because of the security and privacy concerns,” he said.
In response, Amazon built Q to be more secure and private than a consumer chatbot, Mr. Selipsky said. Amazon Q, for example, can have the same security permissions that business customers have already set up for their users. At a company where an employee in marketing may not have access to sensitive financial forecasts, Q can emulate that by not providing that employee with such financial data when asked.
Image

Amazon Q is intended to help employees with daily tasks, including answering questions about corporate policy.Credit...Amazon Web Services

Credit...Amazon Web Services
Companies can also give Amazon Q permission to work with their corporate data that isn’t on Amazon’s servers, such as connecting with Slack and Gmail.
Unlike ChatGPT and Bard, Amazon Q is not built on a specific A.I. model. Instead, it uses an Amazon platform known as Bedrock, which connects several A.I. systems together, including Amazon’s own Titan as well as ones developed by Anthropic and Meta.
The name Q is a play on the word “question,” given the chatbot’s conversational nature, Mr. Selipsky said. It is also a play on the character Q in the James Bond novels, who makes stealthy, helpful tools, and on a powerful “Star Trek” figure, he added.
Pricing for Amazon Q starts at $20 per user each month. Microsoft and Google both charge $30 a month for each user of the enterprise chatbots that work with their email and other productivity applications.
Amazon Q was one of a slew of announcements that the company made at its annual cloud computing conference in Las Vegas. It also shared plans to beef up its computing infrastructure for A.I. And it expanded a longtime partnership with Nvidia, the dominant supplier of A.I. chips, including by building what the companies called the world’s fastest A.I. supercomputer.
Image

An image of Nvidia and Amazon’s forthcoming DGX Cloud Project Ceiba, which they describe as the world’s fastest A.I. supercomputer.Credit...via Nvidia
Most such systems use standard microprocessors along with specialized chips from Nvidia called GPUs, or graphics processing units. Instead, the system announced on Tuesday will be built with new Nvidia chips that include processor technology from Arm, the company whose technology powers most mobile phones.
Image

An image of Nvidia’s GH200 Grace Hopper A.I. Superchip, which the supercomputer will use.Credit...via Nvidia
The shift is a troubling sign for Intel and Advanced Micro Devices, the dominant microprocessor suppliers. But it is positive news for Arm in its long-running effort to break into data center computers.
Don Clark contributed reporting from San Francisco.
Putin: West dominating AI industry, Russia must step up
Putin says foreign LLMs are biased and ignore the Russian culture.%2Favatars%2FEwuSxftyWaVt.png&w=96&q=75 "Sejal Sharma")
Sejal Sharma
Published: Nov 27, 2023 11:06 AM EST
CULTURE
/2023/11/27/image/jpeg/7DGD9w05UB9DvtonUzPZemlhWUC1C0p6lfpNHePo.jpg "Russian President Vladimir Putin")
Russian President Vladimir Putin
Wikimedia Commons
Get a daily digest of the latest news in tech, science, and technology, delivered right to your mailbox. Subscribe now.
By subscribing, you agree to our Terms of Use and Policies You may unsubscribe at any time.In a call for domestic artificial intelligence models that reflect Russian culture and are trained on Russia-specific data, President Vladimir Putin said that “monopolistic dominance” of foreign AI models is unacceptable and dangerous.
Putin was speaking at the Artificial Intelligence Journey 2023 international AI and machine learning conference, which took place in Moscow on Friday.
Listen to his full speech here:
Staking claim in the AI arms race
AI has become the central point of contention in the arms race between the United States and China, the most dominant countries in the development of the technology.Last month, The Biden administration imposed more bans on importing US-produced AI chips to China. These bans are meant to inhibit China’s advancements from gaining technological advantage.
In the global dance of technological aspirations, Putin doubled on Moscow’s dreams of waltzing into the realm of AI supremacy.
However, the war in Ukraine has thrown a wrench into those plans. The conflict has caused an exodus of talent from the country and further pressure mounting after sanctions by the West, putting the brakes on its high-tech imports.
Putin acknowledged the turbulence at the conference. Despite the occasionally disconcerting ethical and social repercussions of emerging technologies, Putin declared that banning AI wasn’t an option.
Since it exploded on the scene last year, OpenAI’s ChatGPT has been banned in Russia.
New strategy for AI development
Putin announced that he’s about to nod to a fresh version of Russia's game plan for AI development. He's throwing down the gauntlet and announced that a new AI advancement bill will be signed. He has also called for a major boost in the number of supercomputers."This is critically necessary for the further development of generative artificial intelligence… In the very near future, as one of the first steps, a presidential decree will be signed and a new version of the national strategy for the development of artificial intelligence will be approved," Putin said at the conference.
Coming down on large language models that are “biased” as they have been trained in English, Putin said that these models sometimes ignore or cancel Russian culture, equivalent to “a kind of abolition in the digital space.”
According to Stanford’s Artificial Intelligence Index Report 2023, American institutions produce most of the world’s large language and multimodal models (54 percent in 2022).
In a call to end their dependency on the West for technology, Putin said, “How can we make our country more efficient and ensure the happiness of all people? This is a question for artificial intelligence.”
Can someone explain the significance and utility of all these open-source models? Is the goal to make them as powerful as GPT4 but with less compute? I've been following this space for a while but I still don't see the purpose of all these open source models. What's the advantage of using open-source models over using the free version of ChatGPT or Bing (which used GPT4)?
I was starting to reply to you twice but then decided to use a vehicles as an analogy but got lazy and i decided to just prompt an explanation instead.
zephyr beta output:
##"model": "HuggingFaceH4/zephyr-7b-beta",
"parameters": {
"temperature": 0.7,
"truncate": 1000,
"max_new_tokens": 1024,
"stop": [
"</s>",
"<|>"
],
"top_p": 0.95,
"top_k": 50,
"repetition_penalty": 1.2,
##
As an analogy, let me explain the benefits, downsides, and differences of LLMs (Large Language Models) as if they were vehicles:
Benefits:
1. Customization - Just like how you can customize your car with different features based on your needs, LLMs provide flexibility in terms of functionality and performance that can be tailored to specific use cases through fine-tuning. This allows organizations to improve their LLM’s accuracy, contextual awareness, and overall effectiveness depending on the nature of the tasks required.
2. Open-Source Collaboration - Similar to how communities collaborate to share ideas and resources related to vehicle development, open-source LLMs enable researchers and developers to freely access, modify, and distribute pre-trained language models without any restrictions. As a result, it fosters innovation, accelerates learning and improves the quality of the model by leveraging collective knowledge from various experts across the world.
3. Cost Efficiency - Using open-source LLMs is more cost-effective than relying solely on proprietary offerings since there are no licensing fees involved. Moreover, users do not have to bear the costs associated with training a new model from scratch which could potentially save time and money.
Downsides:
1. Training Data Requirements - Just as cars require fuel to run efficiently, LLMs need vast amounts of high-quality data during training to achieve optimal performance. The availability and quality of such data vary greatly between industries, making it challenging to ensure consistency and reliability when working with open-source LLMs.
2. Model Drift & Updates - Vehicles need regular maintenance and updates to maintain peak efficiency; similarly, LLMs undergo frequent iterations and improvements due to advancements in research techniques, hardware capabilities, and software tools. Keeping up with these changes requires continuous monitoring, testing, and retraining to avoid model drift issues, particularly when dealing with evolving domains or languages.
Differences:
1. Pre-Trained vs Fine-Tuned - Just like how some people prefer to drive new cars straight out of the factory, others choose to buy secondhand vehicles that already come with certain modifications made by previous owners. Similarly, there are two types of LLMs available – pre-trained models that are optimized for general-purpose text understanding tasks and finetuned ones where the weights of the former are adjusted according to a specific task at hand. Both approaches have their tradeoffs regarding speed, versatility, and performance.
2. Architecture & Capacity - Cars differ significantly based on factors such as size, engine power, driving style preferences etc., whereas LLMs also exhibit variation concerning architecture and capacity levels. Some architectures excel at answering factual questions or generating human-like responses, while others specialize in summarizing lengthy documents or performing complex reasoning tasks. Furthermore, larger models tend to have better performance yet come at a higher computational expense compared to smaller ones.
In summary, just like vehicles serve diverse purposes based on individual requirements, LLMs have unique advantages and drawbacks dependent on the particular application context. Choosing the right one ultimately depends on balancing the desired level of accuracy, computing resource constraints, and practicality considerations while keeping in mind the inherent limitations of the technology itself.
LLAMA 70B output
## default settings/parametersMax New Tokens=2048
Temperature=0.9
Top P=0.7
Top K=0
##
Sure, I can help you understand the advantages and disadvantages of using open-source language models (LLMs) compared to the free versions of ChatGPT or Bing, which use proprietary models like GPT-4. Let's consider LLMs as cars for easier explanation:
Open-Source Language Models (LLMs):
Advantages:
- Customizability: Imagine an open-source car that allows you to modify its engine, add custom features, or change the interior design to suit your preferences. Similarly, LLMs provide flexibility in adapting the model architecture, training data, and fine-tuning parameters to cater to specific use cases or domains. This versatility enables developers to create tailored solutions for various applications such as chatbots, voice assistants, or sentiment analysis tools.
- Community Support: Open-source projects often have large communities of contributors who actively maintain, improve, and debug the software. In the case of LLMs, researchers and developers can collaborate on advancing the state-of-the-art in natural language processing, sharing knowledge and resources that benefit everyone. This communal effort can lead to faster improvements and innovations compared to proprietary models.
- Cost-Effective: Just as purchasing a Toyota Corolla might be more cost-effective than buying a Tesla, utilizing open-source LLMs can save significant resources compared to developing or licensing proprietary models like GPT-4. This is particularly beneficial for startups, academic institutions, and non-profit organizations with limited budgets.
- Technical Expertise: Working with open-source LLMs requires a deeper understanding of the underlying technology and programming skills, much like modifying a car's engine requires mechanical know-how. Developers need to invest time in learning about the model architecture, optimization techniques, and relevant programming languages like Python or TensorFlow. This technical barrier may discourage some users from adopting LLMs.
- Performance Limitations: While open-source LLMs have made impressive strides in recent years, their performance sometimes lags behind that of advanced proprietary models like GPT-4. This difference stems from factors like access to vast computational resources, exclusive datasets, and top talent that only well-funded organizations can afford. As a result, certain tasks or applications might not achieve the same level of accuracy or effectiveness with open-source LLMs.
- Security Risks: With more people involved in the development process, there is a higher likelihood of security vulnerabilities or malicious intentions being introduced into open-source code. Users must exercise caution when selecting pre-trained models or incorporating community-contributed components into their projects. Proprietary models, on the other hand, are typically developed and maintained by dedicated teams with strict quality control measures in place.
Advantages:
- Ease of Use: Using a pre-trained, off-the-shelf AI model like GPT-4 is analogous to driving a luxury car that comes with advanced features and intuitive controls. These models require minimal setup, and users can quickly integrate them into their products or services without delving deep into the underlying technology. This user-friendliness makes it simpler for businesses and individuals to leverage AI capabilities without substantial technical expertise.
- State-of-the-Art Performance: Well-resourced companies like Microsoft and Google invest heavily in R&D to push the boundaries of AI research. Their proprietary models, like GPT-4, often achieve superior results in various NLP benchmarks due to their scale and resources. This performance edge can be critical for applications where accuracy and efficiency are paramount, such as in legal document analysis, medical diagnosis, or high-stakes decision-making.
- Streamlined Integration: Proprietary models usually come with well-documented APIs, SDKs, and sample code, making integration relatively smooth and hassle-free. This streamlined process reduces the overhead associated with implementing complex AI functionality, enabling developers to focus on their core product rather than wrestling with technical integrations.
- Limited Flexibility: Unlike open-source models, proprietary models have restricted customization options. Although they offer excellent performance, they cannot be easily adapted to niche domains or specific use cases that deviate from their primary design objectives. This inflexibility might limit their applicability in certain scenarios where tailored approaches are necessary.
- Dependence on Vendors: Businesses relying on proprietary models may face vendor lock-in, which means they depend on the provider for support, updates, and bug fixes. If a company experiences issues with the model or needs specialized modifications, they might encounter difficulties negotiating with the vendor or navigating their internal processes. Additionally, vendors could potentially discontinue model support or raise prices for their services.
- Ethical Concerns: The closed nature of proprietary models raises ethical questions regarding transparency, accountability, and potential biases. Since the general public cannot inspect or analyze the inner workings of these models, concerns around fairness, privacy, and compliance may arise, especially in sectors subject to regulations or ethical guidelines.
easiest way to see the benefits is to use the same exact prompt on multiple LLM's , I like testing the open source ones because you can change the parameters which could give wildly different results in many instances and i say this as someone who has used bing chat everyday for months now.
go to and enter a prompt to see the responses you get from different LLM's.

Millions of new materials discovered with deep learning
We share the discovery of 2.2 million new crystals – equivalent to nearly 800 years’ worth of knowledge. We introduce Graph Networks for Materials Exploration (GNoME), our new deep learning tool that dramatically increases the speed and efficiency of discovery by predicting the stability of...
Millions of new materials discovered with deep learning
Published29 NOVEMBER 2023AuthorsAmil Merchant and Ekin Dogus Cubuk

AI tool GNoME finds 2.2 million new crystals, including 380,000 stable materials that could power future technologies
Modern technologies from computer chips and batteries to solar panels rely on inorganic crystals. To enable new technologies, crystals must be stable otherwise they can decompose, and behind each new, stable crystal can be months of painstaking experimentation.
Today, in a paper published in Nature, we share the discovery of 2.2 million new crystals – equivalent to nearly 800 years’ worth of knowledge. We introduce Graph Networks for Materials Exploration (GNoME), our new deep learning tool that dramatically increases the speed and efficiency of discovery by predicting the stability of new materials.
With GNoME, we’ve multiplied the number of technologically viable materials known to humanity. Of its 2.2 million predictions, 380,000 are the most stable, making them promising candidates for experimental synthesis. Among these candidates are materials that have the potential to develop future transformative technologies ranging from superconductors, powering supercomputers, and next-generation batteries to boost the efficiency of electric vehicles.
GNoME shows the potential of using AI to discover and develop new materials at scale. External researchers in labs around the world have independently created 736 of these new structures experimentally in concurrent work. In partnership with Google DeepMind, a team of researchers at the Lawrence Berkeley National Laboratory has also published a second paper in Nature that shows how our AI predictions can be leveraged for autonomous material synthesis.
We’ve made GNoME’s predictions available to the research community. We will be contributing 380,000 materials that we predict to be stable to the Materials Project, which is now processing the compounds and adding them into its online database. We hope these resources will drive forward research into inorganic crystals, and unlock the promise of machine learning tools as guides for experimentation
Accelerating materials discovery with AI

About 20,000 of the crystals experimentally identified in the ICSD database are computationally stable. Computational approaches drawing from the Materials Project, Open Quantum Materials Database and WBM database boosted this number to 48,000 stable crystals. GNoME expands the number of stable materials known to humanity to 421,000.
In the past, scientists searched for novel crystal structures by tweaking known crystals or experimenting with new combinations of elements - an expensive, trial-and-error process that could take months to deliver even limited results. Over the last decade, computational approaches led by the Materials Project and other groups have helped discover 28,000 new materials. But up until now, new AI-guided approaches hit a fundamental limit in their ability to accurately predict materials that could be experimentally viable. GNoME’s discovery of 2.2 million materials would be equivalent to about 800 years’ worth of knowledge and demonstrates an unprecedented scale and level of accuracy in predictions.
For example, 52,000 new layered compounds similar to graphene that have the potential to revolutionize electronics with the development of superconductors. Previously, about 1,000 such materials had been identified. We also found 528 potential lithium ion conductors, 25 times more than a previous study, which could be used to improve the performance of rechargeable batteries.
We are releasing the predicted structures for 380,000 materials that have the highest chance of successfully being made in the lab and being used in viable applications. For a material to be considered stable, it must not decompose into similar compositions with lower energy. For example, carbon in a graphene-like structure is stable compared to carbon in diamonds. Mathematically, these materials lie on the convex hull. This project discovered 2.2 million new crystals that are stable by current scientific standards and lie below the convex hull of previous discoveries. Of these, 380,000 are considered the most stable, and lie on the “final” convex hull – the new standard we have set for materials stability.
GNoME: Harnessing graph networks for materials exploration

GNoME uses two pipelines to discover low-energy (stable) materials. The structural pipeline creates candidates with structures similar to known crystals, while the compositional pipeline follows a more randomized approach based on chemical formulas. The outputs of both pipelines are evaluated using established Density Functional Theory calculations and those results are added to the GNoME database, informing the next round of active learning.
GNoME is a state-of-the-art graph neural network (GNN) model. The input data for GNNs take the form of a graph that can be likened to connections between atoms, which makes GNNs particularly suited to discovering new crystalline materials.
GNoME was originally trained with data on crystal structures and their stability, openly available through the Materials Project. We used GNoME to generate novel candidate crystals, and also to predict their stability. To assess our model’s predictive power during progressive training cycles, we repeatedly checked its performance using established computational techniques known as Density Functional Theory (DFT), used in physics, chemistry and materials science to understand structures of atoms, which is important to assess the stability of crystals.
We used a training process called ‘active learning’ that dramatically boosted GNoME’s performance. GNoME would generate predictions for the structures of novel, stable crystals, which were then tested using DFT. The resulting high-quality training data was then fed back into our model training.
Our research boosted the discovery rate of materials stability prediction from around 50%, to 80% - based on an external benchmark set by previous state-of-the-art models. We also managed to scale up the efficiency of our model by improving the discovery rate from under 10% to over 80% - such efficiency increases could have significant impact on how much compute is required per discovery.
AI ‘recipes’ for new materials
The GNoME project aims to drive down the cost of discovering new materials. External researchers have independently created 736 of GNoME’s new materials in the lab, demonstrating that our model’s predictions of stable crystals accurately reflect reality. We’ve released our database of newly discovered crystals to the research community. By giving scientists the full catalog of the promising ‘recipes’ for new candidate materials, we hope this helps them to test and potentially make the best ones.
Upon completion of our latest discovery efforts, we searched the scientific literature and found 736 of our computational discoveries were independently realized by external teams across the globe. Above are six examples ranging from a first-of-its-kind Alkaline-Earth Diamond-Like optical material (Li4MgGe2S7) to a potential superconductor (Mo5GeB2).
Rapidly developing new technologies based on these crystals will depend on the ability to manufacture them. In a paper led by our collaborators at Berkeley Lab, researchers showed a robotic lab could rapidly make new materials with automated synthesis techniques. Using materials from the Materials Project and insights on stability from GNoME, the autonomous lab created new recipes for crystal structures and successfully synthesized more than 41 new materials, opening up new possibilities for AI-driven materials synthesis.

A-Lab, a facility at Berkeley Lab where artificial intelligence guides robots in making new materials. Photo credit: Marilyn Sargent/Berkeley Lab
New materials for new technologies
To build a more sustainable future, we need new materials. GNoME has discovered 380,000 stable crystals that hold the potential to develop greener technologies – from better batteries for electric cars, to superconductors for more efficient computing.Our research – and that of collaborators at the Berkeley Lab, Google Research, and teams around the world — shows the potential to use AI to guide materials discovery, experimentation, and synthesis. We hope that GNoME together with other AI tools can help revolutionize materials discovery today and shape the future of the field.
I’ll preface by saying I’m not a tech nerd
During work I asked ChatGPT today to simply cross reference two FDA databases asking of the new approved drugs in 2023 how many are biologics vs small molecules… would take me <20mins but extra lazy….
shyt spat out multiple incorrect answers, one of them being “every drug approved is a small molecule”
Not saying AI won’t continue to advance… maybe my prompts suck? But since the whole “they found AGI” shyt popped up I’m calling cap on that… way too soon
During work I asked ChatGPT today to simply cross reference two FDA databases asking of the new approved drugs in 2023 how many are biologics vs small molecules… would take me <20mins but extra lazy….
shyt spat out multiple incorrect answers, one of them being “every drug approved is a small molecule”
Not saying AI won’t continue to advance… maybe my prompts suck? But since the whole “they found AGI” shyt popped up I’m calling cap on that… way too soon