
[Submitted on 10 Jul 2024]
[v1]
https://arxiv.org/pdf/2407.07472
A.I Generated explanation:
Title: Rectifier - Code Translation with Corrector via LLMs
This is a research paper about a new tool called Rectifier, which helps fix errors in code translation.
Author: Xin Yin
The author of this paper is Xin Yin, who can be found on the arXiv website.
Abstract:
The abstract is a summary of the paper. It says that:
* Software migration (moving software from one language to another) is becoming more important.
* Early methods of translation were manual and prone to errors.
* Recently, researchers have started using large language models (LLMs) to translate code, but these models can also make mistakes.
* The mistakes made by LLMs can be categorized into four types: compilation errors, runtime errors, functional errors, and non-terminating execution.
* The authors propose a new tool called Rectifier, which can fix these errors.
* Rectifier is a universal model that can be used to correct errors made by any LLM.
* The authors tested Rectifier on translation tasks between C++, Java, and Python, and found that it was effective in fixing errors.
Comments and Subjects:
* The paper has been submitted to the arXiv website, which is a repository of electronic preprints in physics, mathematics, computer science, and related disciplines.
* The subjects of the paper are Software Engineering and Artificial Intelligence.
Cite as and Submission history:
* The paper can be cited using the arXiv identifier 2407.07472.
* The submission history shows that the paper was submitted on July 10, 2024, and can be viewed in PDF format on the arXiv website.
Rectifier - Code Translation with Corrector via LLMs
Xin YinAbstract:Software migration is garnering increasing attention with the evolution of software and society. Early studies mainly relied on handcrafted translation rules to translate between two languages, the translation process is error-prone and time-consuming. In recent years, researchers have begun to explore the use of pre-trained large language models (LLMs) in code translation. However, code translation is a complex task that LLMs would generate mistakes during code translation, they all produce certain types of errors when performing code translation tasks, which include (1) compilation error, (2) runtime error, (3) functional error, and (4) non-terminating execution. We found that the root causes of these errors are very similar (e.g. failure to import packages, errors in loop boundaries, operator errors, and more). In this paper, we propose a general corrector, namely Rectifier, which is a micro and universal model for repairing translation errors. It learns from errors generated by existing LLMs and can be widely applied to correct errors generated by any LLM. The experimental results on translation tasks between C++, Java, and Python show that our model has effective repair ability, and cross experiments also demonstrate the robustness of our method.
| Comments: | arXiv:2308.03109 |
| Subjects: | Software Engineering (cs.SE); Artificial Intelligence (cs.AI) |
| Cite as: | arXiv:2407.07472 |
| arXiv:2407.07472v1 |
Submission history
From: [v1] [ view email][v1]
https://arxiv.org/pdf/2407.07472
A.I Generated explanation:
Title: Rectifier - Code Translation with Corrector via LLMs
This is a research paper about a new tool called Rectifier, which helps fix errors in code translation.
Author: Xin Yin
The author of this paper is Xin Yin, who can be found on the arXiv website.
Abstract:
The abstract is a summary of the paper. It says that:
* Software migration (moving software from one language to another) is becoming more important.
* Early methods of translation were manual and prone to errors.
* Recently, researchers have started using large language models (LLMs) to translate code, but these models can also make mistakes.
* The mistakes made by LLMs can be categorized into four types: compilation errors, runtime errors, functional errors, and non-terminating execution.
* The authors propose a new tool called Rectifier, which can fix these errors.
* Rectifier is a universal model that can be used to correct errors made by any LLM.
* The authors tested Rectifier on translation tasks between C++, Java, and Python, and found that it was effective in fixing errors.
Comments and Subjects:
* The paper has been submitted to the arXiv website, which is a repository of electronic preprints in physics, mathematics, computer science, and related disciplines.
* The subjects of the paper are Software Engineering and Artificial Intelligence.
Cite as and Submission history:
* The paper can be cited using the arXiv identifier 2407.07472.
* The submission history shows that the paper was submitted on July 10, 2024, and can be viewed in PDF format on the arXiv website.























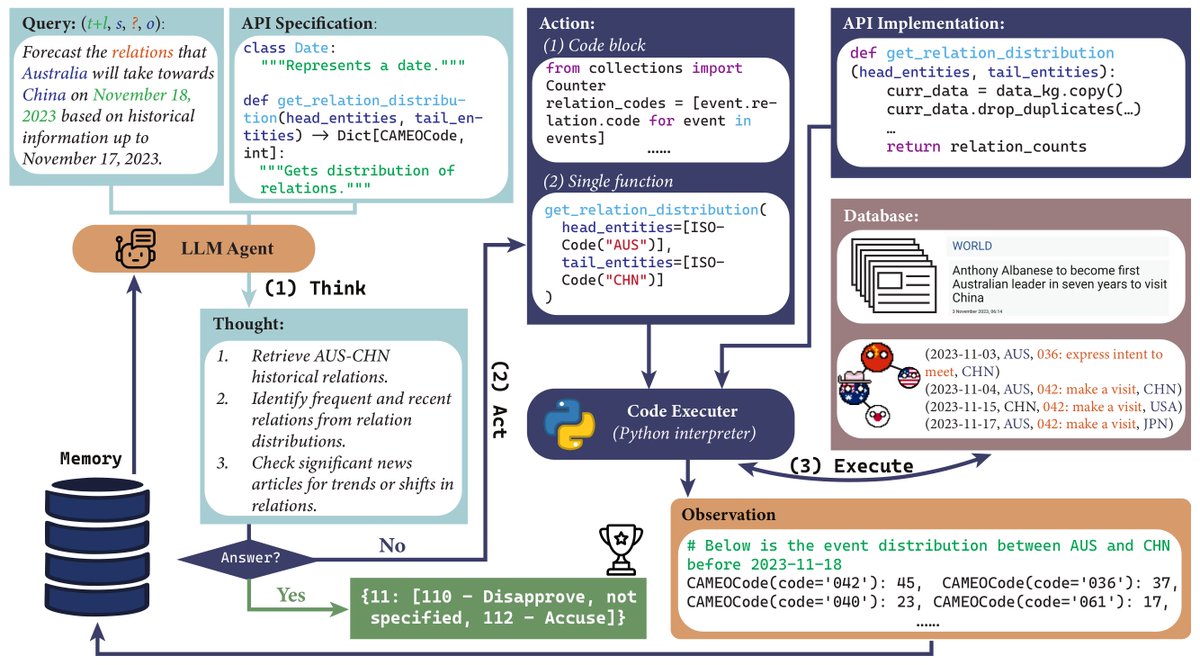



























 Excited to share our latest research on investigating the effect of coding data on LLMs' reasoning abilities!
Excited to share our latest research on investigating the effect of coding data on LLMs' reasoning abilities! 
 Discover how Instruction Fine-Tuning with code can boost zero-shot performance across various tasks and domains.
Discover how Instruction Fine-Tuning with code can boost zero-shot performance across various tasks and domains. 

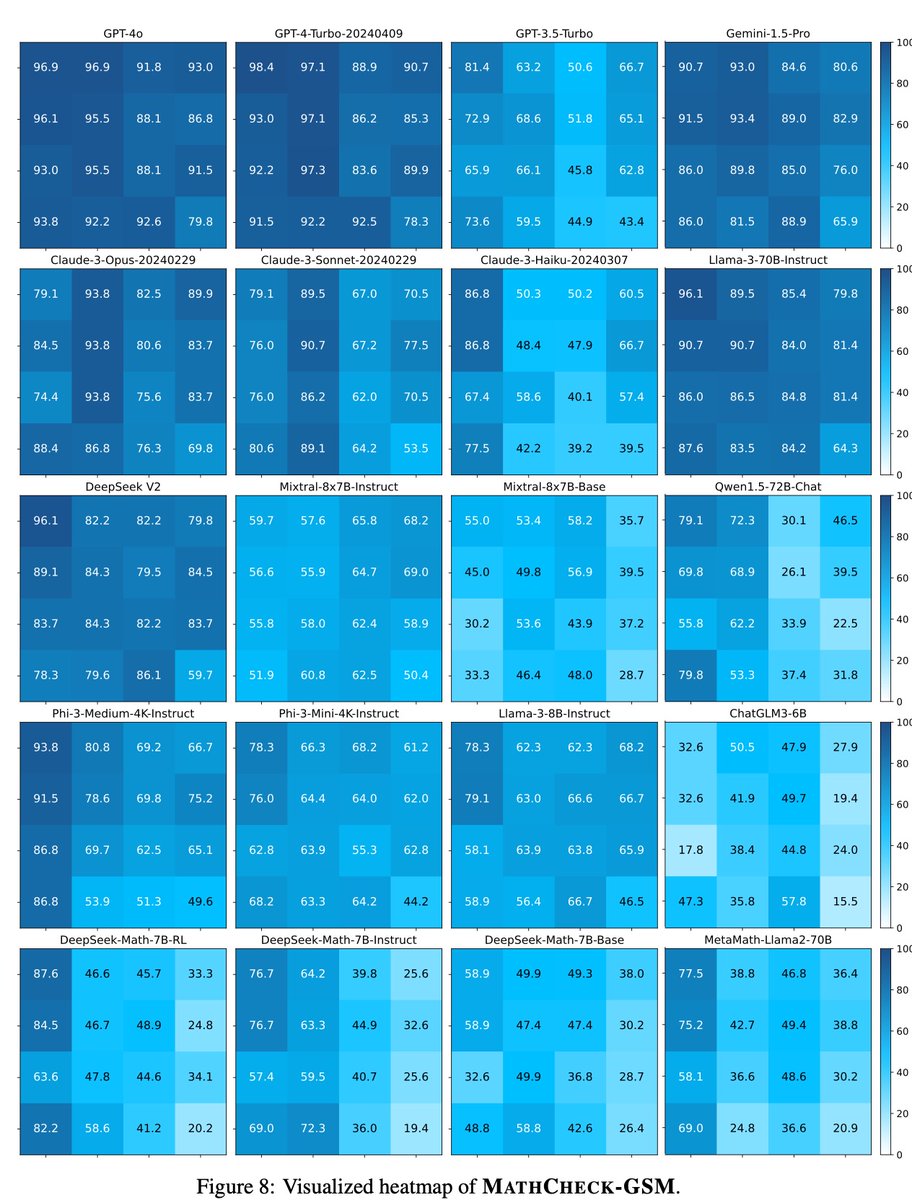
 Overall, we observed a consistent and gradual enhancement in the LLMs' reasoning performance as the proportion of coding data used for fine-tuning increased.
Overall, we observed a consistent and gradual enhancement in the LLMs' reasoning performance as the proportion of coding data used for fine-tuning increased. Further analysis revealed that coding data generally provides similar task-specific benefits across model families. While most optimal proportions of coding data are consistent across families, no single proportion enhances all task-specific reasoning abilities.
Further analysis revealed that coding data generally provides similar task-specific benefits across model families. While most optimal proportions of coding data are consistent across families, no single proportion enhances all task-specific reasoning abilities.



