On Thursday, OpenAI researchers unveiled CriticGPT, a new AI model designed to identify mistakes in code generated by ChatGPT. It aims to enhance the process of making AI systems behave in ways humans want (called "alignment") through Reinforcement Learning from Human Feedback (RLHF), which helps human reviewers make large language model (LLM) outputs more accurate.
As outlined in a new research paper called " LLM Critics Help Catch LLM Bugs," OpenAI created CriticGPT to act as an AI assistant to human trainers who review programming code generated by the ChatGPT AI assistant. CriticGPT—based on the GPT-4 family of LLMS—analyzes the code and points out potential errors, making it easier for humans to spot mistakes that might otherwise go unnoticed. The researchers trained CriticGPT on a dataset of code samples with intentionally inserted bugs, teaching it to recognize and flag various coding errors.
The researchers found that CriticGPT's critiques were preferred by annotators over human critiques in 63 percent of cases involving naturally occurring LLM errors and that human-machine teams using CriticGPT wrote more comprehensive critiques than humans alone while reducing confabulation (hallucination) rates compared to AI-only critiques.
Developing an automated critic
The development of CriticGPT involved training the model on a large number of inputs containing deliberately inserted mistakes. Human trainers were asked to modify code written by ChatGPT, introducing errors and then providing example feedback as if they had discovered these bugs. This process allowed the model to learn how to identify and critique various types of coding errors.
In experiments, CriticGPT demonstrated its ability to catch both inserted bugs and naturally occurring errors in ChatGPT's output. The new model's critiques were preferred by trainers over those generated by ChatGPT itself in 63 percent of cases involving natural bugs (the aforementioned statistic). This preference was partly due to CriticGPT producing fewer unhelpful "nitpicks" and generating fewer false positives, or hallucinated problems.
The researchers also created a new technique they call Force Sampling Beam Search (FSBS). This method helps CriticGPT write more detailed reviews of code. It lets the researchers adjust how thorough CriticGPT is in looking for problems while also controlling how often it might make up issues that don't really exist. They can tweak this balance depending on what they need for different AI training tasks.
Interestingly, the researchers found that CriticGPT's capabilities extend beyond just code review. In their experiments, they applied the model to a subset of ChatGPT training data that had previously been rated as flawless by human annotators. Surprisingly, CriticGPT identified errors in 24 percent of these cases—errors that were subsequently confirmed by human reviewers. OpenAI thinks this demonstrates the model's potential to generalize to non-code tasks and highlights its ability to catch subtle mistakes that even careful human evaluation might miss.
Despite its promising results, like all AI models, CriticGPT has limitations. The model was trained on relatively short ChatGPT answers, which may not fully prepare it for evaluating longer, more complex tasks that future AI systems might tackle. Additionally, while CriticGPT reduces confabulations, it doesn't eliminate them entirely, and human trainers can still make labeling mistakes based on these false outputs.
The research team acknowledges that CriticGPT is most effective at identifying errors that can be pinpointed in one specific location within the code. However, real-world mistakes in AI outputs can often be spread across multiple parts of an answer, presenting a challenge for future model iterations.
OpenAI plans to integrate CriticGPT-like models into its RLHF labeling pipeline, providing its trainers with AI assistance. For OpenAI, it's a step toward developing better tools for evaluating outputs from LLM systems that may be difficult for humans to rate without additional support. However, the researchers caution that even with tools like CriticGPT, extremely complex tasks or responses may still prove challenging for human evaluators—even those assisted by AI.
OpenAI recently published a paper about CriticGPT, a version of GPT-4 fine-tuned to critique code generated by ChatGPT. When compared with human evaluators, CriticGPT catches more bugs and produces better critiques. OpenAI plans to use CriticGPT to improve future versions of their models.
www.infoq.com
OpenAI's CriticGPT Catches Errors in Code Generated by ChatGPT
Senior Director, Development at Genesys Cloud Services
OpenAI recently published a paper about CriticGPT, a version of GPT-4 fine-tuned to critique code generated by ChatGPT. When compared with human evaluators, CriticGPT catches more bugs and produces better critiques. OpenAI plans to use CriticGPT to improve future versions of their models.
When originally developing ChatGPT, OpenAI used human "AI trainers" to rate the outputs of the model, creating a dataset that was used to fine-tune it using reinforcement learning from human feedback (RLHF). However, as AI models improve, and can now perform some tasks at the same level as human experts, it can be difficult for human judges to evaluate their output. CriticGPT is part of OpenAI's effort on scalable oversight, which is intended to help solve this problem. OpenAI decided first to focus on helping ChatGPT improve its code-generating abilities. The researchers used CriticGPT to generate critiques of code; they also paid qualified human coders to do the same. In evaluations, AI trainers preferred CriticGPT's critiques 80% of the time, showing that CriticGPT could be a good source for RLHF training data. According to OpenAI:
The need for scalable oversight, broadly construed as methods that can help humans to correctly evaluate model output, is stronger than ever. Whether or not RLHF maintains its dominant status as the primary means by which LLMs are post-trained into useful assistants, we will still need to answer the question of whether particular model outputs are trustworthy. Here we take a very direct approach: training models that help humans to evaluate models....It is...essential to find scalable methods that ensure that we reward the right behaviors in our AI systems even as they become much smarter than us. We find LLM critics to be a promising start.
Interestly, CriticGPT is also a version of GPT-4 that is fine-tuned with RLHF. In this case, the RLHF training data consisted of buggy code as the input, and a human-generated critique or explanation of the bug as the desired output. The buggy code was produced by having ChatGPT write code, then having a human contractor insert a bug and write the critique.
To evaluate CriticGPT, OpenAI used human judges to rank several critiques side-by-side; judges were shown outputs from CriticGPT and from baseline ChatGPT, as well as critiques generated by humans alone or by humans with CriticGPT assistance ("Human+CriticGPT"). The judges preferred CriticGPT's output over that of ChatGPT and human critics. OpenAI also found that the Human+CriticGPT teams' output was "substantially more comprehensive" than that of humans alone. However, it tended to have more "nitpicks."
For those new to the field of AGI safety: this is an implementation of Paul Christiano's alignment procedure proposal called Iterated Amplification from 6 years ago...It's wonderful to see his idea coming to fruition! I'm honestly a bit skeptical of the idea myself (it's like proposing to stabilize the stack of "turtles all the way down" by adding more turtles)...but every innovative idea is worth a try, in a field as time-critical and urgent as AGI safety.
Christiano formerly ran OpenAI's language model alignment team. Other companies besides OpenAI are also working on scalable oversight. In particular, Anthropic has published research papers on the problem, such as their work on using a debate between LLMs to improve model truthfulness.
The 7B & 34B safety tuned models we’ve released can take any combination of text and images as input and produce text outputs using a new early fusion approach. While some LLMs have separate image and text encoders or decoders, Chameleon is one of the first publicly released approaches using a single unified architecture.
We’re releasing Chameleon models under a research license to help democratize access to foundational mixed-modal models & further research on early fusion.
The Fundamental AI Research (FAIR) team at Meta recently released Chameleon, a mixed-modal AI model that can understand and generate mixed text and image content. In experiments rated by human judges, Chameleon's generated output was preferred over GPT-4 in 51.6% of trials, and over Gemini Pro...
www.infoq.com
Meta's Chameleon AI Model Outperforms GPT-4 on Mixed Image-Text Tasks
Senior Director, Development at Genesys Cloud ServicesFOLLOW
The Fundamental AI Research (FAIR) team at Meta recently released Chameleon, a mixed-modal AI model that can understand and generate mixed text and image content. In experiments rated by human judges, Chameleon's generated output was preferred over GPT-4 in 51.6% of trials, and over Gemini Pro in 60.4%.
Chameleon differs from many mixed image-text AI models, which use separate encoders and decoders for the two modalities. Instead, Chameleon uses a single token-based representation of both text and image, and is trained end-to-end on mixed sequences of both image and text. Meta trained two sizes of the model: Chameleon-7B, with seven billion parameters, and Chameleon-34B with 34 billion. Both models were pre-trained on over four trillion tokens of mixed text and image data, and then fine-tuned for alignment and safety on smaller datasets. In addition to human judges comparing the model's output to that of baseline models, Meta evaluated Chameleon-34B on several benchmarks, noting that Chameleon achieved state-of-the-art performance on visual question answering and image captioning tasks. According to Meta,
By quantizing images into discrete tokens and training on mixed-modal data from scratch, Chameleon learns to jointly reason over image and text in a way that is impossible with...models that maintain separate encoders for each modality. At the same time, Chameleon introduces novel techniques for stable and scalable training of early-fusion models, addressing key optimization and architectural design challenges that have previously limited the scale of such approaches...Chameleon also unlocks entirely new possibilities for multimodal interaction, as demonstrated by its strong performance on our new benchmark for mixed-modal open-ended QA.
The Meta team noted that it was "challenging" to train Chameleon when scaling above 8B model parameters or more than 1T dataset tokens, due to instabilities. The researchers had to make changes to the standard Transformer architecture to resolve these challenges; in particular, they found that because the model weights were shared across both input modalities, "each modality will try to compete with the other" by increasing its vector norms, eventually moving the norms outside the range of the 16-bit floating point representation used in the model. The solution was to apply additional normalization operations into the model architecture.
Autoregressive output generation with Chameleon also presented "unique" performance challenges. First, generating mixed-mode output requires a different decoding strategy for each mode, so output tokens must be copied from GPU to CPU for program control flow. Also, since the model can be asked to generate single-mode output (for example, text-only), this requires the model to have the ability to mask or ignore tokens of other modalities. To solve these problems, Meta implemented a custom inference pipeline for the model.
One core learning we had with Chameleon is that the intended form of the modality is a modality in itself. Visual Perception and Visual Generation are two separate modalities and must be treated as such; hence, using discretized tokens for perception is wrong.
In another thread, AI researcher Nando de Freitas noted that Chameleon's architecture is similar to that of DeepMind's Gato model and wondered, "Is this going to be the ultimate approach for MIMO (multimodal input multimodal output models) or is there something else we should be trying?"
While Meta did not publicly release Chameleon, citing safety concerns, they released a modified version of the models that support mixed-mode inputs but cannot generate image output. These models are available on request for use under a "research-only license."
[Submitted on 16 May 2024]
Chameleon - Mixed-Modal Early-Fusion Foundation Models
Abstract:We present Chameleon, a family of early-fusion token-based mixed-modal models capable of understanding and generating images and text in any arbitrary sequence. We outline a stable training approach from inception, an alignment recipe, and an architectural parameterization tailored for the early-fusion, token-based, mixed-modal setting. The models are evaluated on a comprehensive range of tasks, including visual question answering, image captioning, text generation, image generation, and long-form mixed modal generation. Chameleon demonstrates broad and general capabilities, including state-of-the-art performance in image captioning tasks, outperforms Llama-2 in text-only tasks while being competitive with models such as Mixtral 8x7B and Gemini-Pro, and performs non-trivial image generation, all in a single model. It also matches or exceeds the performance of much larger models, including Gemini Pro and GPT-4V, according to human judgments on a new long-form mixed-modal generation evaluation, where either the prompt or outputs contain mixed sequences of both images and text. Chameleon marks a significant step forward in a unified modeling of full multimodal documents.
Researchers from Meta, University of Southern California, Carnegie Mellon University, and University of California San Diego recently open-sourced MEGALODON, a large language model (LLM) with an unlimited context length. MEGALODON has linear computational complexity and outperforms a...
www.infoq.com
Meta Open-Sources MEGALODON LLM for Efficient Long Sequence Modeling
MEGALODON is designed to address several shortcomings of the Transformer neural architecture underlying most LLMs. Instead of the standard multihead attention, MEGALODON uses a chunk-wise attention. The research team also introduced sequence-based parallelism during training, improving scalability for long-context training. When evaluated on standard LLM benchmarks, such as WinoGrande and MMLU, MEGALODON outperformed a Llama 2 model with the same amount of parameters, training data, and training compute budget. According to the researchers:
MEGALODON achieves impressive improvements on both training perplexity and across downstream benchmarks. Importantly, experimental results on long-context modeling demonstrate MEGALODON’s ability to model sequences of unlimited length. Additional experiments on small/medium-scale benchmarks across different data modalities illustrate the robust improvements of MEGALODON, which lead to a potential direction of future work to apply MEGALODON for large-scale multi-modality pretraining.
Although the Transformer architecture has become the standard for most Generative AI models, Transformers do have some drawbacks. In particular, their self-attention mechanism has quadratic complexity in both compute and storage, which limits the models' input context length. Several alternatives to the standard self-attention model have been developed recently, including structured state space models (SSMs) like Mamba, which scales linearly with context length. Another scheme that InfoQ recently covered is the RWKV Project's attention-free Transformer model, which has no maximum input context length.
MEGALODON builds on the research team's previous model, MEGA (exponential moving average with gated attention), with several new features. First, while MEGA uses a "classical" exponential moving average (EMA) within its attention mechanism, MEGALODON computes a complex EMA (CEMA). Mathematically, the CEMA component makes MEGALODON equivalent to a "simplified state space model with diagonal state matrix."
The research team trained a seven-billion parameter model, MEGALODON-7B, using the same 2-trillion token dataset that Llama2-7B used; they also used the same training hyperparameters. The team observed that MEGALODON-7B was more computationally efficient. When the Llama model was scaled up to a 32k context length, MEGALODON-7B was "significantly" faster.
Besides evaluating MEGALODON-7B on standard LLM benchmarks, the researchers also tested its performance on the SCROLLS long-context question-answering benchmark, and compared its results with several baseline models, including the modified Llama 2 model with a 32k context length. MEGALODON outperformed all baseline models on the NarrativeQA subtask, and on all tasks achieved results "competitive" with Llama 2.
For what it's worth, RWKV's website on that matter mentions that yes it's bad on recall, but for the vast majority of tasks you can just ask the question *before* the content, and it'll handle the task just fine.
Slack's engineering team recently published how it used a large language model (LLM) to automatically convert 15,000 unit and integration tests from Enzyme to React Testing Library (RTL). By combining Abstract Syntax Tree (AST) transformations and AI-powered automation, Slack's innovative...
www.infoq.com
Slack Combines ASTs with Large Language Models to Automatically Convert 80% of 15,000 Unit Tests
This transition was prompted by Enzyme's lack of support for React 18, necessitating a significant shift to maintain compatibility with the latest React version. The conversion tool's adoption rate at Slack reached approximately 64%, saving considerable developer time of at least 22% of 10,000 hours. While this figure represents a significant saving, Sergii Gorbachov, senior software engineer at Slack, speculates that, in reality, the figure is probably much higher:
It's important to note that this 22% time saving represents only the documented cases where the test case passed. However, it's conceivable that some test cases were converted properly, yet issues such as setup or importing syntax may have caused the test file not to run at all, and time savings were not accounted for in those instances.
The team initially attempted to automate the conversion using Abstract Syntax Tree (AST) transformations, aiming for 100% accuracy. However, the complexity and variety of Enzyme methods led to a modest success rate of 45% in automatically converting code. One factor contributing to the low success rate is that correct conversion depends on contextual information regarding the rendered Document Object Model (DOM) under test, to which the AST conversion has no access.
The AST representation of `wrapper.find('selector');` ( Source)
Next, the team attempted to perform the conversion using Anthropic's LLM, Claude 2.1. Despite efforts to refine prompts, the conversion success rates varied significantly between 40% and 60%. Gorbachov notes that "the outcomes ranged from remarkably effective conversions to disappointingly inadequate ones, depending largely on the complexity of the task."
Following the unsatisfactory results, the team decided to observe how human developers approached converting the unit tests. They noticed that human developers had access to a broad knowledge base on React, Enzyme and RTL, and they combined that knowledge with access to context on the rendered React element and the AST conversions provided by the initial version of the conversion tool.
Slack's engineers then adopted a hybrid approach, combining the AST transformations with LLM capabilities and mimicking human behaviour. By feeding the rendered React component under test and the conversions performed by the AST tool into the LLM as part of the prompt and creating a robust control mechanism for the AI, they achieved an 80% conversion success rate, demonstrating the complementary nature of these technologies.
An Abstract Syntax Tree (AST) is a tree representation of the abstract syntactic structure of source code written in a programming language. Each node in the tree denotes a construct occurring in the source code. A syntax tree focuses on the structure and content necessary for understanding the code's functionality. ASTs are commonly used in compilers and interpreters to parse and analyze code, enabling various transformations, optimizations, and translations during compilation.
1/11
Yesterday we introduced Moshi, the lowest latency conversational AI ever released. Moshi can perform small talk, explain various concepts, engage in roleplay in many emotions and speaking styles. Talk to Moshi here moshi.chat and learn more about the method below .
2/11
Moshi is an audio language model that can listen and speak continuously, with no need for explicitly modelling speaker turns or interruptions. When talking to Moshi, you will notice that the UI displays a transcript of its speech. This does *not* come from an ASR nor is an input to a TTS, but is rather part of the integrated multimodal modelling of Moshi. Here, listen to it whispering about quantum physics.
3/11
Moshi is not an assistant, but rather a prototype for advancing real-time interaction with machines. It can chit-chat, discuss facts and make recommendations, but a more groundbreaking ability is its expressivity and spontaneity that allow for engaging into fun roleplay.
4/11
The underlying model of Moshi is incredibly easy to adapt and tweak by finetuning on specific data. For example, make it listen to phone calls from the late 90’s early 00's and you get a magic phone to the past.
5/11
Developing Moshi required significant contributions to audio codecs, multimodal LLMs, multimodal instruction-tuning and much more. We believe the main impact of the project will be sharing all Moshi’s secrets with the upcoming paper and open-source of the model.
6/11
For now, you can experiment with Moshi with our online demo. The development of Moshi is more active than ever, and we will rollout frequent updates to address your feedback. This is just the beginning, let's improve it together.
7/11
This is incredible, we'll be discussing Moshi in our weekly AI space in 10 minutes, welcome to hop on and tell us about it!
9/11
My 8yo daughter and I were talking with it tonight. She couldn’t stop laughing,. She said it’s her favourite robot, more fun than ChatGPT and PI.. because of the quirkyness.. it’s amazing.
10/11
Incredible work.
Technical paper coming soon?
11/11
Le laboratoire Kyutai, un institut français de recherche en IA, a publié "moshi.chat".
Ni Kyutai ni moshi ne sont au moins français.
Les deux sonnent comme du japonais.
Kyutai est-il une "sphère" ?
Moshi, ChatGPT's newest competitor, asserts it comprehends humans better than any other AI bot Moshi: The New AI Voice Assistant Ready to Rival Alexa and Google Assistant Moshi is an AI voice assistant crafted for lifelike conversations, akin to Amazon’s Alexa or Google Assistant. What...
thetechrobot.com
Moshi, ChatGPT’s newest competitor, asserts it comprehends humans better than any other AI bot
Moshi, ChatGPT’s newest competitor, asserts it comprehends humans better than any other AI bot
Moshi: The New AI Voice Assistant Ready to Rival Alexa and Google Assistant
Moshi is an AI voice assistant crafted for lifelike conversations, akin to Amazon’s Alexa or Google Assistant. What distinguishes Moshi is its capability to speak in diverse accents and utilise 70 different emotional and speaking styles. Additionally, it can comprehend the tone of your voice.
In a recent turn of events, OpenAI delayed the launch of ChatGPT’s much-anticipated voice mode due to technical difficulties, leaving many enthusiasts disappointed. But there’s a new player in the AI chatbot field that might just fill that gap. Introducing Moshi, an advanced AI voice assistant created by the French AI company Kyutai.
Meet Moshi
Moshi stands out among AI voice assistants with its lifelike conversation abilities, rivalling well-known counterparts like Amazon’s Alexa and Google Assistant. What makes Moshi unique is its proficiency in various accents and an impressive range of 70 emotional and speaking styles. Remarkably, it can also comprehend the tone of your voice as you speak.
One of Moshi’s standout features is its ability to handle two audio streams simultaneously, allowing it to listen and respond in real time. Launched with a live stream, this innovative voice assistant has been making significant waves in the tech community.
Tech Radar reports that Moshi’s development involved an extensive fine-tuning process, incorporating over 100,000 synthetic dialogues generated through Text-to-Speech (TTS) technology. Kyutai also collaborated with a professional voice artist to ensure that Moshi’s responses sound natural and engaging.
Using Moshi
To use Moshi, open the application and enter your email in the provided box. Select ‘Join Queue,’ and a new screen will open. On the left, a speaker icon will light up when you speak, and on the right, a box will display Moshi’s responses.
Currently, you can converse with Moshi for up to 5 minutes. After your chat, you have the option to download the video or audio by clicking the option at the bottom left of the screen. To initiate a new conversation on another topic, just click on ‘Start Over’ located at the top of the screen.
Moshi promises to revolutionise the way we interact with AI voice assistants, bringing a new level of human-like understanding and engagement.
Moshi Chat is a new native speech AI model from French startup Kyutai, promising a similar experience to GPT-4o where it understands your tone of voice and can be interrupted.
Unlike GPT-4o, Moshi is a smaller model and can be installed locally and run offline. This could be perfect for the future of smart home appliances — if they can improve the responsiveness.
I had several conversations with Moshi. Each lasts up to five minutes in the current online demo and in every case it ended with it repeating the same word over and over, losing cohesion.
In one of the conversations it started to argue with me, flat out refusing to tell me a story, demanding instead to state a fact and wouldn’t let up until I said “tell me a fact.”
This is all likely an issue of context window size and compute resources that can be easily solved over time. While OpenAI doesn’t need to worry about the competition from Moshi yet, it does show that as with Sora, where Luma Labs, Runway and others are pressing against its quality — others are catching up.
What is Moshi Chat?
Testing Moshi Chat — AI speech-to-speech - YouTube
Moshi Chat is the brainchild of the Kyutai research lab and was built from scratch six months ago by a team of eight researchers. The goal is to make it open and build on the new model over time, but this is the first openly accessible native generative voice AI.
“This new type of technology makes it possible for the first time to communicate in a smooth, natural and expressive way with an AI,” the company said in a statement.
Its core functionality is similar to OpenAI’s GPT-4o but from a much smaller model. It is also available to use today, whereas GPT-4o advanced voice won’t be widely available until Fall.
The team suggests Moshi could be used in roleplay scenarios or even as a coach to spur you on while you train. The plan is to work with the community and make it open so others can build on top of and further fine-tune the AI.
It is a 7B parameter multimodal model called Helium trained on text and audio codecs, but Moshi is speech in speech out natively. It can run on an Nvidia GPU, Apple's Metal or a CPU.
Kyutai hopes that the community support will be used to enhance Moshi's knowledge base and factuality. These have been limited because it is a lightweight base model, but it is hoped that expanding these aspects in combination with native speech will create a powerful assistant.
The next stage is to further refine the model and scale it up to allow for more complex and longer form conversations with Moshi.
In using it and from watching the demos I’ve found it incredibly fast and responsive for the first minute or so, but the longer the conversation goes on the more incoherent it becomes. Its lack of knowledge is also obvious and if you cal it out for making a mistake it gets flustered and goes into a loop of "I’m sorry, I’m sorry, I’m sorry."
This isn’t a direct competitor for OpenAI’s GPT-4o advanced voice yet, even though advanced voice isn’t currently available. But, offering an open, locally running model that has the potential to work in much the same way is a significant step forward for open source AI development.
2/6
In a multiturn setting, i experienced sonnet outshine all others by a lot more. The example was ppm dosages and concentrates with a desired mix ratio
3/6
Now sonnet got its position
4/6
Seems like @sama is sleeping
5/6
At least from my experience: whatever math Sonnet is being used for, it certainly ain't linear algebra
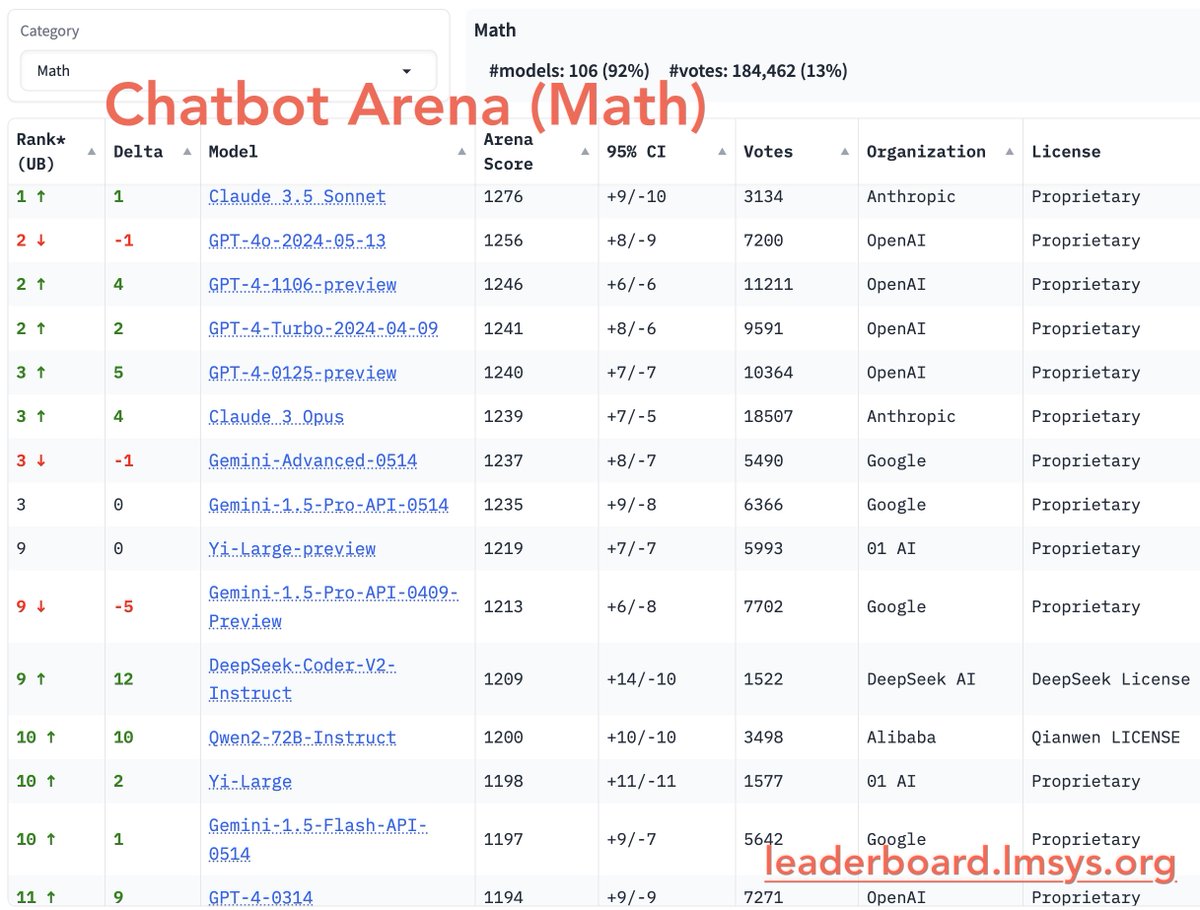
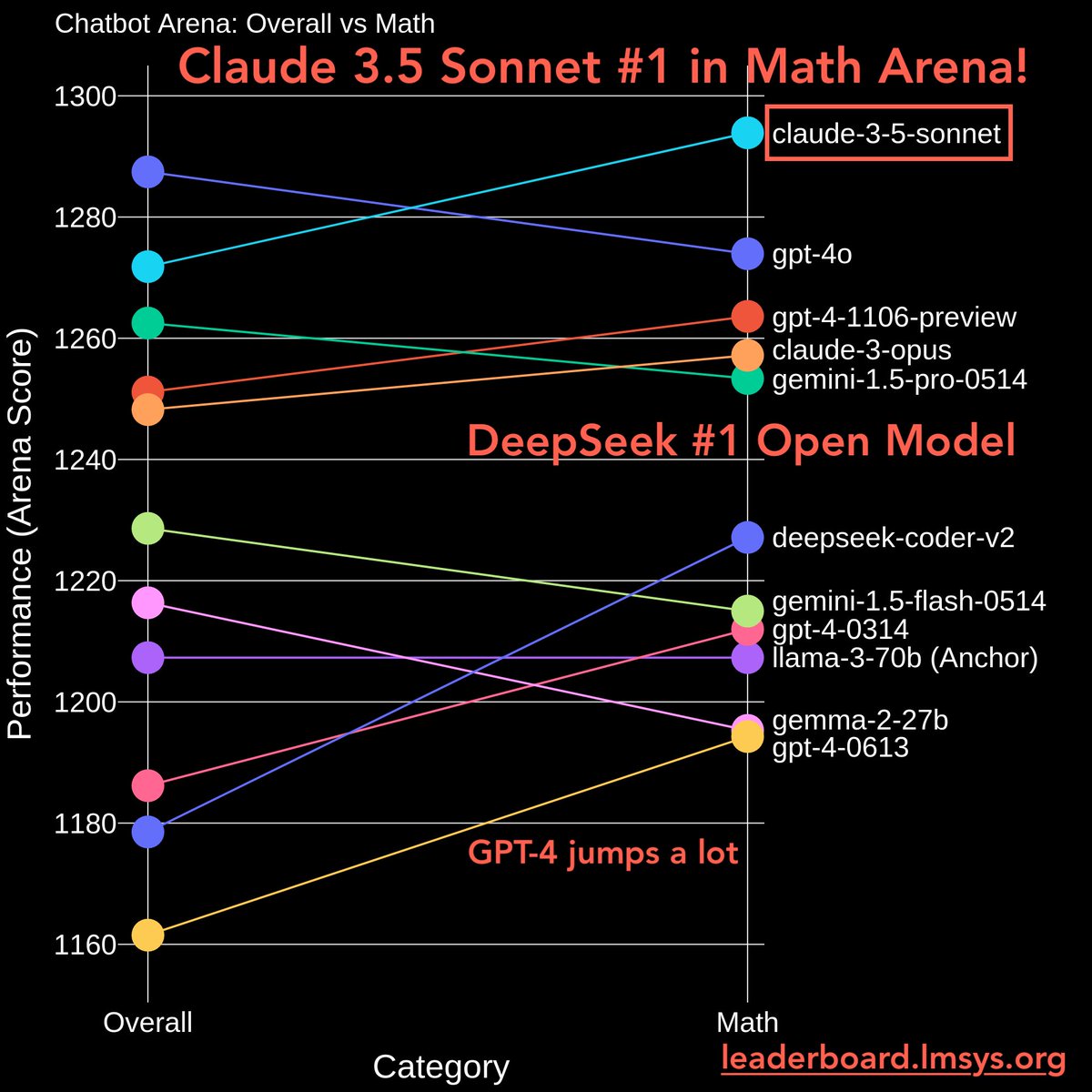
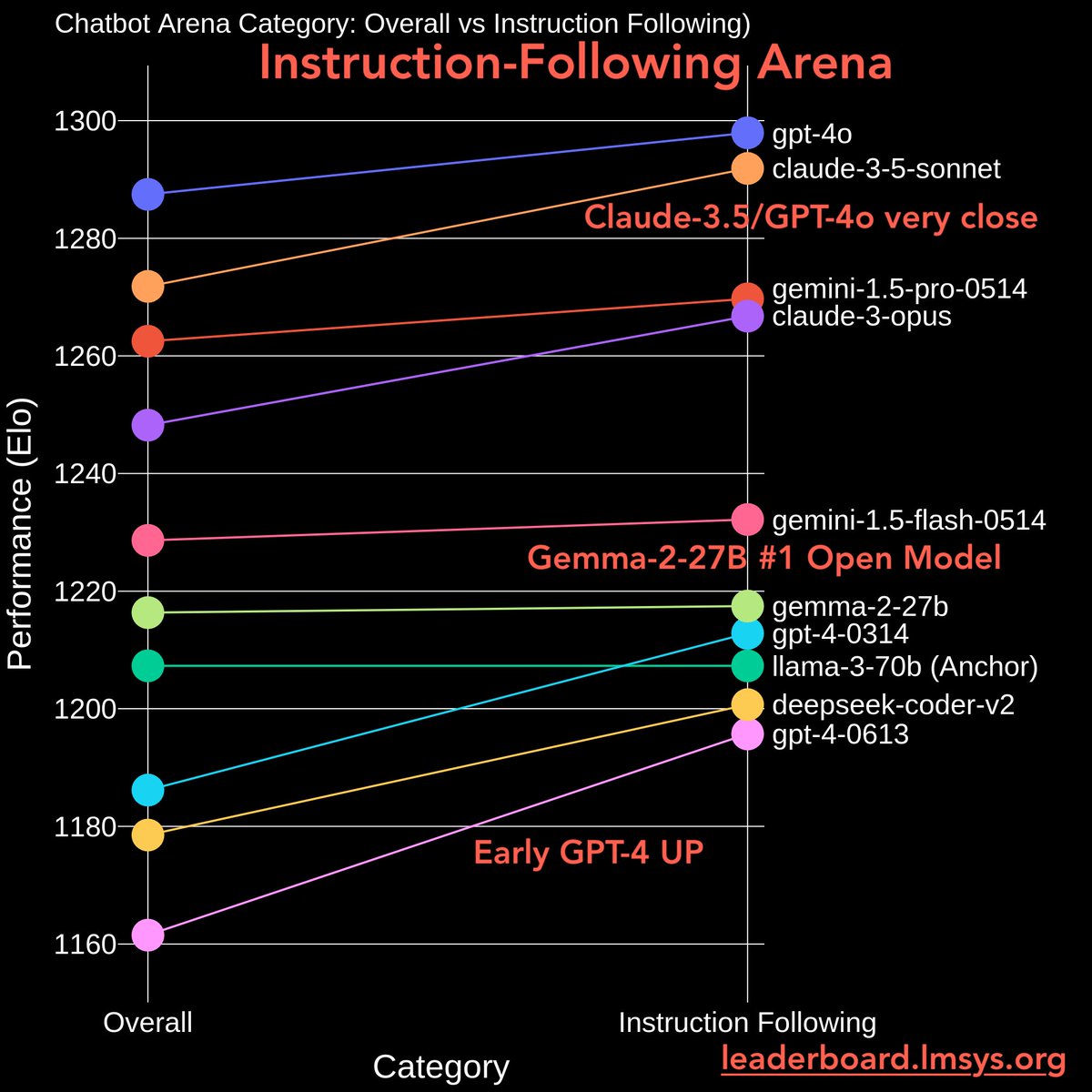
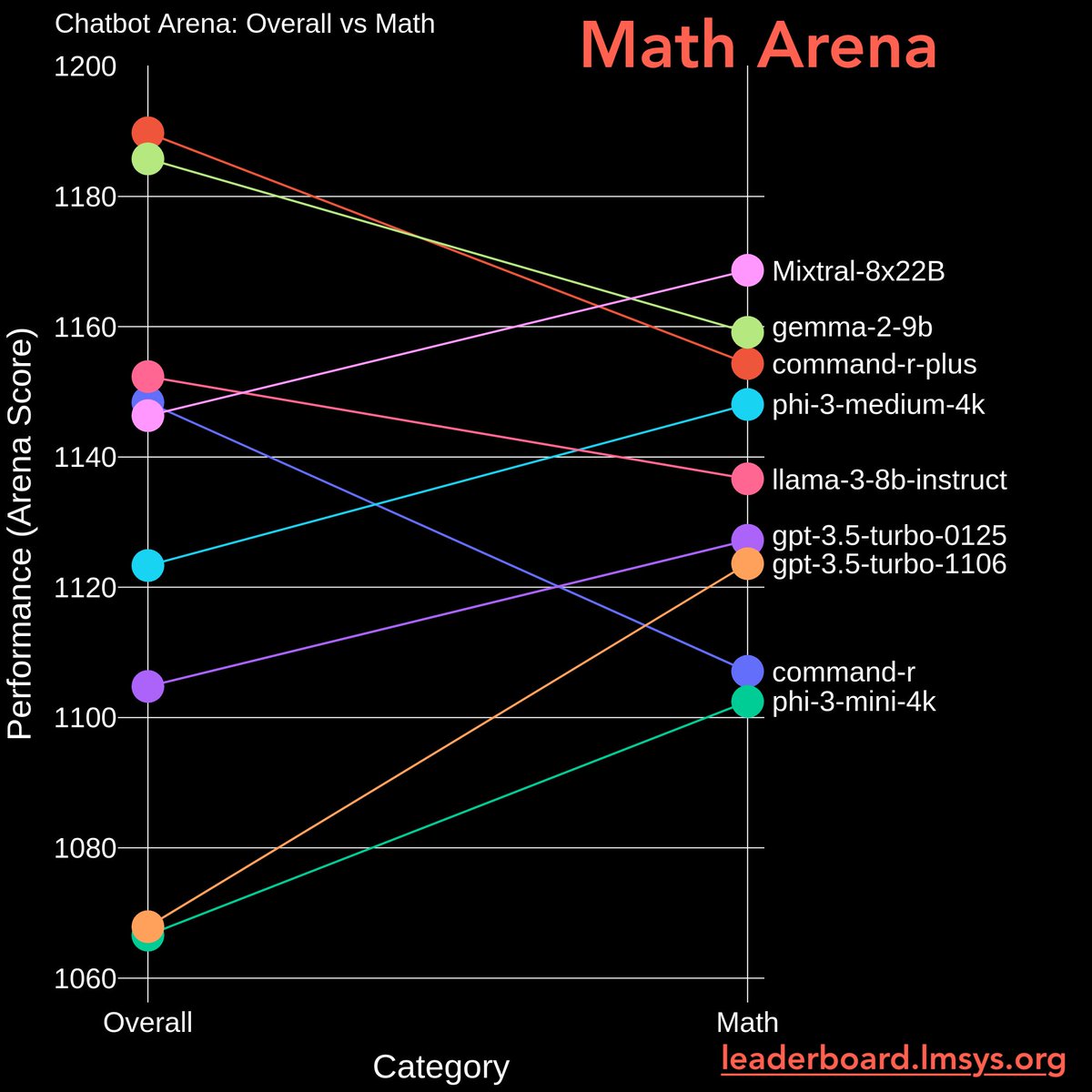
We are excited to launch Math Arena and Instruction-Following (IF) Arena!
Math/IF are the two key domains testing models’ logical skills & real-world tasks. Key findings:
- Stats: 500K IF votes (35%), 180K Math votes (13%)
- Claude 3.5 Sonnet is now #1 in Math Arena, and joint #1 in IF.
- DeepSeek-coder #1 open model
- Early GPT-4s improved significantly over Llama-3 & Gemma-2
More analysis below
2/10
Instruction-Following Arena
- Claude-3.5/GPT-4o joint #1 (in CIs)
- Gemma-2-27B #1 Open Model
- Early GPT-4/Claudes all UP
3/10
Math Arena (Pt 2)
Ranking shifts quite a lot:
- Mistral-8x22b UP
- Gemma2-9b, Llama3-8b, Command-r drop
- Phi-3 series UP
4/10
Let us know your thoughts! Credits to builders @LiTianleli @infwinston
5/10
This chart somehow correlates very well with my own experience. Also GPT-4-0314 being above GPT-4-0613 feels vindicating
6/10
Question: For the math one how is this data being analyzed. What I mean like is this metric calculated off of total responses, that's to say over all types of math? Because if so then this can potentially open up error in that some models might do better in specific types
7/10
I wonder if it would work if we build could model merging / breeding into the arena to see if we could kick start the evolutionary process?
Why not?
8/10
I love it when new arenas emerge! Math and IF are crucial domains to test logical skills and real-world tasks. Congrats to Claude 3.5 Sonnet and DeepSeek-coder on their top spots!
9/10
"While others are tired of losing money, we are tired of taking profits
Same Market, Different strategies "
If you aren’t following @MrAlexBull you should be. There aren’t many who have a better understanding of the current market.
10/10
I truly believe previous dip was to scare retail into selling, allowing institutions to buy cheaper, They were late to the game, they needed a better entry.
Following @MrAlexBull tweets, posts, tips and predictions I have added massively to my holdings
1/6
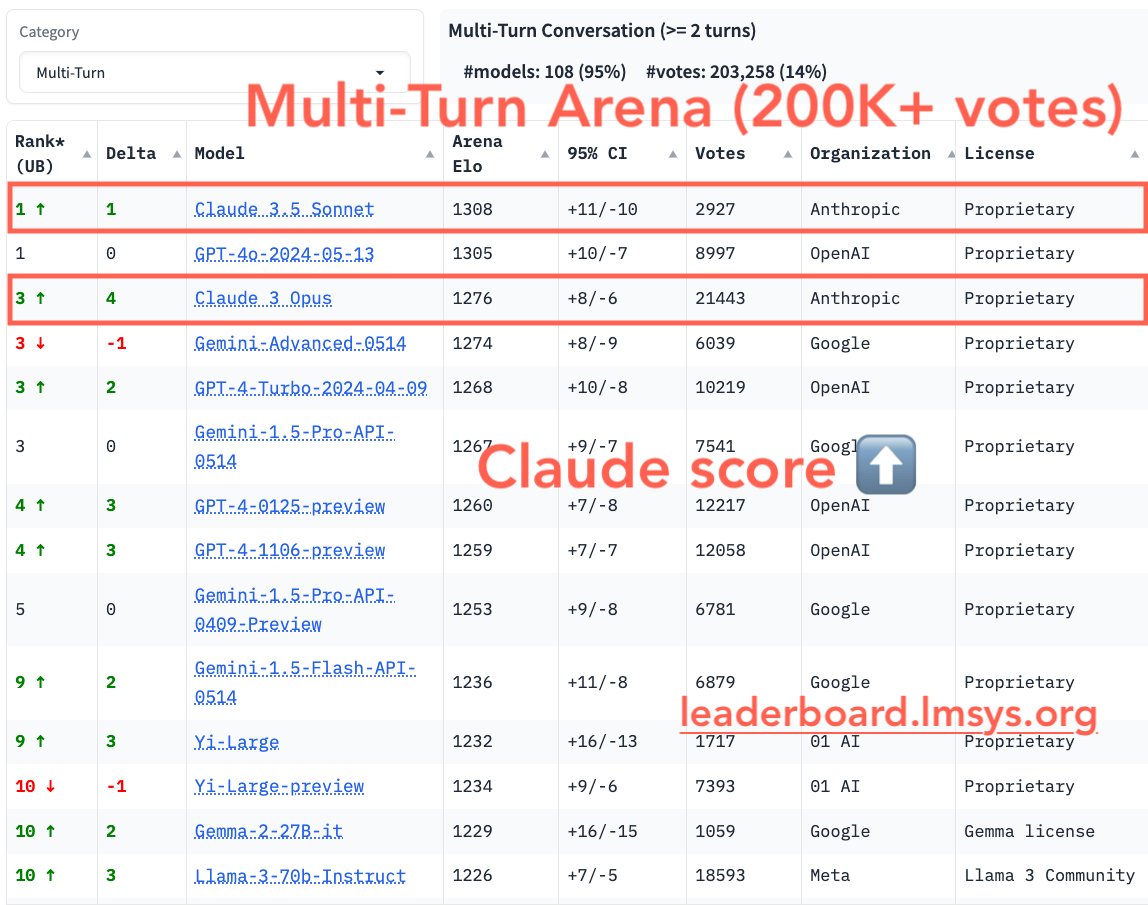
Multi-turn conversations with LLMs are crucial for many applications today.
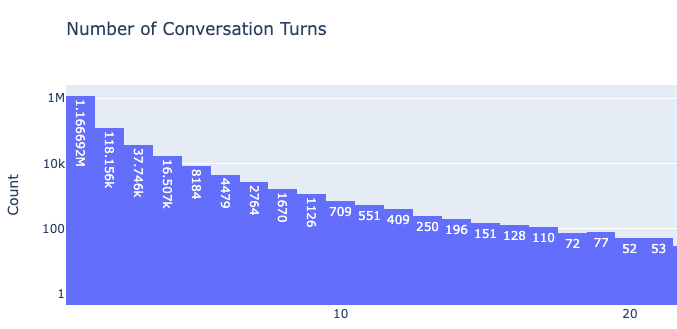
We’re excited to introduce a new category, "Multi-Turn," which includes conversations with >=2 turns to measure models' abilities to handle longer interactions.
Key findings:
- 14% Arena votes are multi-turn
- Claude models' scores increased significantly. Claude 3.5 Sonnet becomes joint #1 with GPT-4o.
- Gemma-2-27B and Llama-3-70B are the best open models, now joint #10.
Let us know your thoughts!
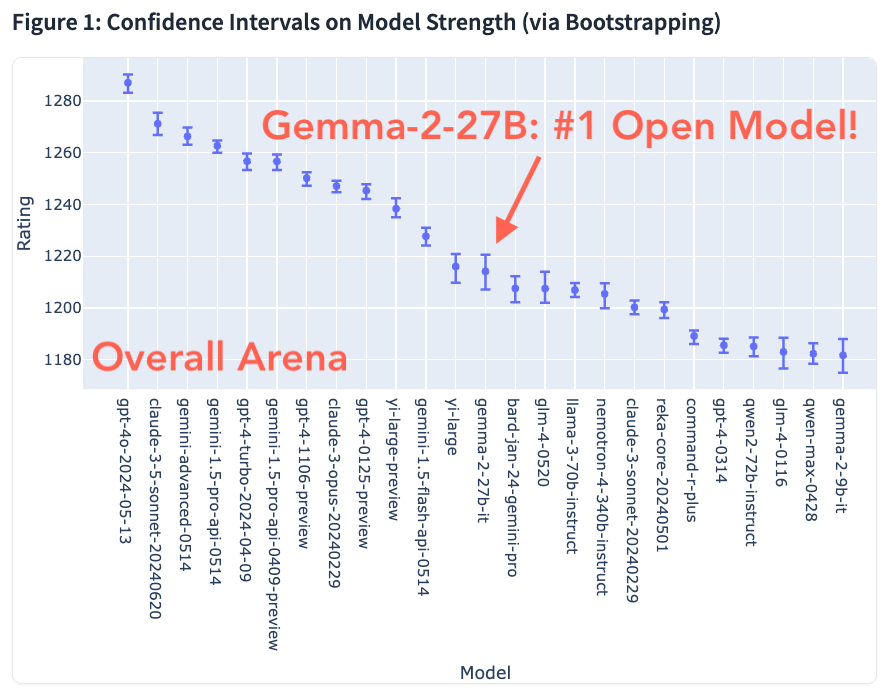
2/6
We also collect more votes for Gemma-2-27B (now 5K+) for the past few days. Gemma-2 stays robust against Llama-3-70B, now the new best open model!
1/6
In this paper from DeepMind, the authors show that many-shot in-context learning (ICL, when you put training examples in the prompt during inference) significantly outperforms few-shot learning across a wide variety of tasks, including translation, summarization, planning, reward modeling, mathematical problem solving, question-answering, algorithmic reasoning, and sentiment analysis.
Furthermore, many-shot provides comparable results to supervised finetuning (SFT, when you finetune the base model on task-specific data before serving it).
Performance on some tasks (e.g. MATH) can degrade with too many examples, suggesting an optimal number of shots exists.
While SFT is computationally expensive in terms of training, many-shot ICL does not require any training. However, many-shot ICL has a larger inference cost, which can be substantially reduced with KV caching.
The authors suggest that many-shot ICL could make task-specific fine-tuning less essential or, in some cases, even unnecessary. This could potentially allow large language models to tackle a wider range of tasks without specialization. https://arxiv.org/pdf/2404.11018
2/6
What’s the difference?
3/6
With what?
4/6
Yes, the large context window LLMs will first make fine-tuning obsolete instead of RAG.
5/6
yes, but how expensive is this, after filling up that context?
Abstract:Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples -- the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated examples. To mitigate this limitation, we explore two new settings: Reinforced and Unsupervised ICL. Reinforced ICL uses model-generated chain-of-thought rationales in place of human examples. Unsupervised ICL removes rationales from the prompt altogether, and prompts the model only with domain-specific questions. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. Finally, we demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases, can learn high-dimensional functions with numerical inputs, and performs comparably to fine-tuning. Our analysis also reveals the limitations of next-token prediction loss as an indicator of downstream ICL performance.
Paper Title: Magic Insert: Style-Aware Drag-and-Drop
Few pointers from the paper
In this paper authors have presented “Magic Insert”, a method for dragging-and-dropping subjects from a user-provided image into a target image of a different style in a physically plausible manner while matching the style of the target image.
This work formalizes the problem of style-aware drag-and-drop and presents a method for tackling it by addressing two sub-problems: style-aware personalization and realistic object insertion in stylized images.
For “style-aware personalization”, their method first fine-tunes a pretrained text-to-image diffusion model using LoRA and learned text tokens on the subject image, and then infuses it with a CLIP representation of the target style.
For object insertion, they used “Bootstrapped Domain Adaptation” to adapt a domain-specific photorealistic object insertion model to the domain of diverse artistic styles. Overall, the method significantly outperforms traditional approaches such as inpainting.
Finally, authors have also presented a dataset, “SubjectPlop”, to facilitate evaluation and future progress in this area.
Organization: @Google
Paper Authors: @natanielruizg , Yuanzhen Li, @neal_wadhwa , @Yxp52492 , Michael Rubinstein, David E. Jacobs, @shlomifruchter
**Summary:** Imagine you want to take a picture of a cat from one image and drop it into another image with a completely different style, like a painting or a cartoon. This paper presents a new method called "Magic Insert" that makes this possible.
**What's the problem?:** The problem is that when you try to drop an object from one image into another, it usually looks out of place because it doesn't match the style of the new image. For example, if you take a photo of a cat and drop it into a painting, the cat will look like a photo, not a painting.
**How does Magic Insert work?:** The method works by solving two main problems:
1. **Style-aware personalization:** The algorithm takes the object you want to drop (the cat) and makes it match the style of the new image. It does this by using a special kind of AI model that can understand the style of the new image and change the object to fit in.
2. **Realistic object insertion:** The algorithm then takes the styled object and inserts it into the new image in a way that looks realistic. It does this by using another AI model that can adapt to different styles and make the object look like it belongs in the new image.
**Results:** The Magic Insert method is much better than traditional methods at making the dropped object look like it belongs in the new image.
**Additional resources:**
* **Paper:** You can read the full paper here.
* **Project page:** You can learn more about the project here.
* **Demo:** You can try out the Magic Insert demo here.
**Authors and organization:** The paper was written by a team of researchers from Google, including Nataniel Ruiz, Yuanzhen Li, Neal Wadhwa, Yxp52492, Michael Rubinstein, David E. Jacobs, and Shlomi Fruchter.
Paper Title: TAPVid-3D: A Benchmark for Tracking Any Point in 3D
Few pointers from the paper
In this paper authors have introduced a new benchmark, TAPVid-3D, for evaluating the task of long-range Tracking Any Point in 3D (TAP-3D). While point tracking in two dimensions (TAP) has many benchmarks measuring performance on real-world videos, such as TAPVid-DAVIS; three-dimensional point tracking has none.
To this end, leveraging existing footage, they built a new benchmark for 3D point tracking featuring 4,000+ real-world videos, composed of three different data sources spanning a variety of object types, motion patterns, and indoor and outdoor environments.
To measure performance on the TAP-3D task, authors formulated a collection of metrics that extend the Jaccard-based metric used in TAP to handle the complexities of ambiguous depth scales across models, occlusions, and multi-track spatio-temporal Smoothness.
They manually verified a large sample of trajectories to ensure correct video annotations, and assess the current state of the TAP-3D task by constructing competitive baselines using existing tracking models.
They anticipated that this benchmark will serve as a guidepost to improve our ability to understand precise 3D motion and surface deformation from monocular video.
**Title:** TAPVid-3D: A Benchmark for Tracking Any Point in 3D
**Summary:** Imagine you're watching a video and you want to track a specific point on an object, like a car or a person, as it moves around in 3D space. This paper introduces a new benchmark, called TAPVid-3D, to help computers do this task better.
**What's the problem?:** Currently, there are many benchmarks that test how well computers can track points on objects in 2D videos, but there aren't any benchmarks that test this ability in 3D videos. This is a problem because 3D tracking is much harder and more important for applications like self-driving cars or augmented reality.
**What is TAPVid-3D?:** TAPVid-3D is a new benchmark that tests how well computers can track points on objects in 3D videos. It's a collection of over 4,000 real-world videos that show different objects moving around in different environments. The benchmark also includes a set of metrics that measure how well a computer can track these points.
**How was TAPVid-3D created?:** The authors of the paper created TAPVid-3D by combining existing footage from different sources and manually verifying the accuracy of the tracking data. They also used existing tracking models to create competitive baselines for the benchmark.
**Why is TAPVid-3D important?:** TAPVid-3D will help computers improve their ability to understand and track 3D motion and surface deformation from monocular video. This will have many applications in fields like computer vision, robotics, and augmented reality.
**Additional resources:**
* **Paper:** You can read the full paper here.
* **Project page:** You can learn more about the project here.
* **Data & Code:** You can access the data and code for TAPVid-3D here.
**Authors and organization:** The paper was written by a team of researchers from Google DeepMind, University College London, and the University of Oxford, including Skanda Koppula, Ignacio Rocco, Yi Yang, Joe Heyward, João Carreira, Andrew Zisserman, Gabriel Brostow, and Carl Doersch.
Paper Title: Listen to Look into the Future: Audio-Visual Egocentric Gaze Anticipation
Few pointers from the paper
Egocentric gaze anticipation serves as a key building block for the emerging capability of Augmented Reality. Notably, gaze behavior is driven by both visual cues and audio signals during daily activities. Motivated by this observation, authors of this paper introduced the first model that leverages both the video and audio modalities for egocentric gaze anticipation.
Specifically, they have proposed a Contrastive Spatial-Temporal Separable (CSTS) fusion approach that adopts two modules to separately capture audio-visual correlations in spatial and temporal dimensions, and applies a contrastive loss on the re-weighted audio-visual features from fusion modules for representation learning.
They conducted extensive ablation studies and thorough analysis using two egocentric video datasets: Ego4D and Aria, to validate their model design. They demonstrated that the audio improves the performance by +2.5% and +2.4% on the two datasets.
Their model also outperforms the prior state-of-the-art methods by at least +1.9% and +1.6%. Moreover, they provide visualizations to show the gaze anticipation results and provide additional insights into audio-visual representation learning.
A new research paper has been published, and it's making waves in the field of Augmented Reality (AR). Here's what it's about:
Paper Title: Listen to Look into the Future: Audio-Visual Egocentric Gaze Anticipation
The paper is about a new way to predict where people will look in the future, using both what they see and what they hear. This is important for AR, which is a technology that overlays digital information onto the real world.
Here are some key points from the paper:
* The researchers created a new model that uses both video and audio to predict where someone will look. This is the first time anyone has done this.
* They tested their model using two big datasets of videos, and it worked really well. The audio part of the model improved the results by 2.5% and 2.4% compared to just using video.
* Their model is better than other models that have been tried before, and they showed some cool visualizations to prove it.
The researchers are from several organizations, including Georgia Tech, GenAI, Meta, and the University of Illinois.
Paper Title: ManiWAV: Learning Robot Manipulation from In-the-Wild Audio-Visual Data
Few pointers from the paper
Audio signals provide rich information for the robot interaction and object properties through contact. These information can surprisingly ease the learning of contact-rich robot manipulation skills, especially when the visual information alone is ambiguous or incomplete.
However, the usage of audio data in robot manipulation has been constrained to teleoperated demonstrations collected by either attaching a microphone to the robot or object, which significantly limits its usage in robot learning pipelines.
In this paper author have introduced ManiWAV: an ‘ear-in-hand’ data collection device to collect in-the-wild human demonstrations with synchronous audio and visual feedback, and a corresponding policy interface to learn robot manipulation policy directly from the demonstrations.
They demonstrated the capabilities of their system through four contact-rich manipulation tasks that require either passively sensing the contact events and modes, or actively sensing the object surface materials and states.
In addition, they showed that their system can generalize to unseen in-the-wild environments, by learning from diverse in-the-wild human demonstrations.
**Title:** ManiWAV: Learning Robot Manipulation from In-the-Wild Audio-Visual Data
**Summary:** This paper is about teaching robots to perform tasks that require touching and manipulating objects, like picking up a ball or opening a door. The researchers found that using audio signals, like the sound of a ball bouncing, can help the robot learn these tasks more easily.
**The Problem:** Usually, robots learn by watching humans perform tasks, but this can be limited because the visual information might not be enough. For example, if a robot is trying to pick up a ball, it might not be able to see exactly how the ball is moving, but it can hear the sound of the ball bouncing.
**The Solution:** The researchers created a special device that can collect audio and visual data from humans performing tasks, like picking up a ball. This device is like a special glove that has a microphone and a camera. They used this device to collect data from humans performing four different tasks, like picking up a ball or opening a door.
**The Results:** The researchers found that their system can learn to perform these tasks by using the audio and visual data collected from humans. They also found that their system can work in different environments and with different objects, even if it hasn't seen them before.
**The Team:** The researchers are from Stanford University, Columbia University, and Toyota Research.
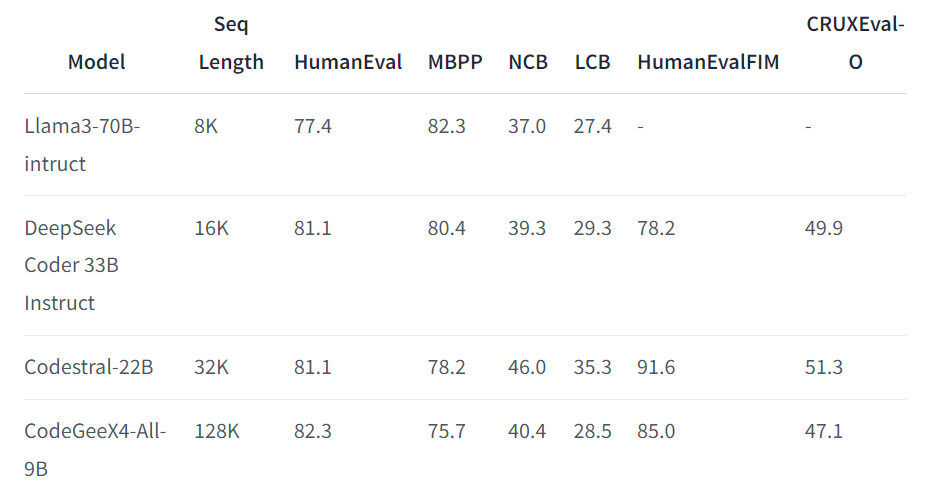
In a significant leap forward for the field of code generation, the Knowledge Engineering Group (KEG) and Data Mining team at Tsinghua University have unveiled their latest innovation: CodeGeeX4-ALL-9B. This model, part of the renowned CodeGeeX series, represents the pinnacle of multilingual...
www.marktechpost.com
Tsinghua University Open Sources CodeGeeX4-ALL-9B: A Groundbreaking Multilingual Code Generation Model Outperforming Major Competitors and Elevating Code Assistance
In a significant leap forward for the field of code generation, the Knowledge Engineering Group (KEG) and Data Mining team at Tsinghua University have unveiled their latest innovation: CodeGeeX4-ALL-9B. This model, part of the renowned CodeGeeX series, represents the pinnacle of multilingual code generation, setting a new standard for performance and efficiency in automated coding.
The CodeGeeX4-ALL-9B model is a product of extensive training on the GLM-4-9B framework, which has markedly improved its capabilities in code generation. With a parameter count of 9.4 billion, this model stands out as one of the most powerful in its class, surpassing even larger general-purpose models. It excels in inference speed and overall performance, making it a versatile tool for various software development tasks.
One of the standout features of CodeGeeX4-ALL-9B is its ability to handle various functions seamlessly. This model covers all critical aspects of software development, from code completion and generation to code interpretation and web searches. It offers repository-level code Q&A, enabling developers to interact with their codebase more intuitively and efficiently. This comprehensive functionality makes CodeGeeX4-ALL-9B an invaluable asset for developers in diverse programming environments.
Performance benchmarks have demonstrated exceptional results on public benchmarks such as BigCodeBench and NaturalCodeBench. These benchmarks assess various aspects of code generation models, and CodeGeeX4-ALL-9B’s performance indicates its robustness and reliability in real-world applications. It has achieved top-tier results, outpacing many larger models and establishing itself as the leading model with fewer than 10 billion parameters.
The user-friendly design of CodeGeeX4-ALL-9B ensures that developers can quickly integrate it into their workflows. Users can easily launch and utilize the model for their projects using the specified versions of the transformers library. The model supports GPUs and CPUs, ensuring flexibility in different computational environments. This accessibility is crucial for fostering widespread adoption and maximizing the model’s impact across the software development community.
To illustrate its practical application, the model’s inference process involves generating outputs based on user inputs. The results are decoded to provide clear and actionable code, streamlining the development process. This capability is beneficial for tasks that require precise and efficient code generation, such as developing complex algorithms or automating repetitive coding tasks.
In conclusion, the release of CodeGeeX4-ALL-9B by KEG and Data Mining at Tsinghua University marks a milestone in the evolution of code generation models. Its unparalleled performance, comprehensive functionality, and user-friendly integration will revolutionize how developers approach coding tasks, driving efficiency and innovation in software development.
We introduce CodeGeeX4-ALL-9B, the open-source version of the latest CodeGeeX4 model series. It is a multilingual code generation model continually trained on the GLM-4-9B, significantly enhancing its code generation capabilities. Using a single CodeGeeX4-ALL-9B model, it can support comprehensive functions such as code completion and generation, code interpreter, web search, function call, repository-level code Q&A, covering various scenarios of software development. CodeGeeX4-ALL-9B has achieved highly competitive performance on public benchmarks, such as BigCodeBench and NaturalCodeBench. It is currently the most powerful code generation model with less than 10B parameters, even surpassing much larger general-purpose models, achieving the best balance in terms of inference speed and model performance.
Abstract:Large pre-trained code generation models, such as OpenAI Codex, can generate syntax- and function-correct code, making the coding of programmers more productive and our pursuit of artificial general intelligence closer. In this paper, we introduce CodeGeeX, a multilingual model with 13 billion parameters for code generation. CodeGeeX is pre-trained on 850 billion tokens of 23 programming languages as of June 2022. Our extensive experiments suggest that CodeGeeX outperforms multilingual code models of similar scale for both the tasks of code generation and translation on HumanEval-X. Building upon HumanEval (Python only), we develop the HumanEval-X benchmark for evaluating multilingual models by hand-writing the solutions in C++, Java, JavaScript, and Go. In addition, we build CodeGeeX-based extensions on Visual Studio Code, JetBrains, and Cloud Studio, generating 4.7 billion tokens for tens of thousands of active users per week. Our user study demonstrates that CodeGeeX can help to increase coding efficiency for 83.4% of its users. Finally, CodeGeeX is publicly accessible and in Sep. 2022, we open-sourced its code, model weights (the version of 850B tokens), API, extensions, and HumanEval-X at this https URL.
Developed by #ZhipuAI, CodeGeeX has consistently evolved since its inception in Sep 2022. CodeGeeX4-ALL-9B significantly enhances code generation capabilities based on the powerful language abilities of #GLM4. This single model can cover all programming scenarios. It delivers competitive performance on authoritative code capability evaluation benchmarks such as NaturalCodeBench and BigCodeBench, surpassing several times larger general models in inference performance and model effect. Performance evaluation on BigCodeBench shows that CodeGeeX4-ALL-9B is the best in its class.
CodeGeeX4-ALL-9B supports 128K context, helping the model to understand and use information from longer code files or even project codes, significantly improving the model's ability to deal with complex tasks and accurately answer content from different code files. CodeGeeX4-ALL-9B is the only code model that implements Function Call. It has successfully called over 90% of AST and Exec test sets on the Berkeley Function Calling Leaderboard.
The latest CodeGeeX plugin v2.12.0 fully integrates the fourth-generation model. It can automatically generate README files for projects, remember and understand long text context at the project level, support cross-file analysis and Q&A in projects, and support local mode. CodeGeeX v2.12.0 also significantly improves NL2SQL capabilities. Now, you can directly generate complex SQL queries in natural language in the plugin.
Experience the power of CodeGeeX4 now! Upgrade your CodeGeeX plugin in your IDE or search for "CodeGeeX" in the IDE plugin market to download it for free. You can also download CodeGeeX's fourth-generation model on GitHub and deploy a dedicated project-level intelligent programming assistant on your computer.
This site uses cookies to help personalise content, tailor your experience and to keep you logged in if you register.
By continuing to use this site, you are consenting to our use of cookies.


 arstechnica.com
arstechnica.com


 www.infoq.com
www.infoq.com

 www.infoq.com
www.infoq.com
/filters:no_upscale()/news/2024/06/meta-chameleon-ai/en/resources/1chameleon-architecture-1718803086759.png "Chameleon Training and Inference")


/filters:no_upscale()/news/2024/06/slack-automatic-test-conversion/en/resources/1Slack-AST-Representation-1717931855564.png)
/filters:no_upscale()/news/2024/06/slack-automatic-test-conversion/en/resources/1Slack-pipeline-flowchart-1717931855564.png)
 .
.





 "
"

 Paper Alert
Paper Alert  Paper Title: Magic Insert: Style-Aware Drag-and-Drop
Paper Title: Magic Insert: Style-Aware Drag-and-Drop Few pointers from the paper
Few pointers from the paper In this paper authors have presented “Magic Insert”, a method for dragging-and-dropping subjects from a user-provided image into a target image of a different style in a physically plausible manner while matching the style of the target image.
In this paper authors have presented “Magic Insert”, a method for dragging-and-dropping subjects from a user-provided image into a target image of a different style in a physically plausible manner while matching the style of the target image. Organization: @Google
Organization: @Google  Paper Authors: @natanielruizg , Yuanzhen Li, @neal_wadhwa , @Yxp52492 , Michael Rubinstein, David E. Jacobs, @shlomifruchter
Paper Authors: @natanielruizg , Yuanzhen Li, @neal_wadhwa , @Yxp52492 , Michael Rubinstein, David E. Jacobs, @shlomifruchter  Read the Full Paper here: [2407.02489] Magic Insert: Style-Aware Drag-and-Drop
Read the Full Paper here: [2407.02489] Magic Insert: Style-Aware Drag-and-Drop Project Page: Magic Insert: Style-Aware Drag-and-Drop
Project Page: Magic Insert: Style-Aware Drag-and-Drop Demo:Magic Insert Interactive Demo
Demo:Magic Insert Interactive Demo Be sure to watch the attached Demo Video -Sound on
Be sure to watch the attached Demo Video -Sound on 
 Music by Mark from @pixabay
Music by Mark from @pixabay  ?
? QT and teach your network something new
QT and teach your network something new , @NaveenManwani17 , for the latest updates on Tech and AI-related news, insightful research papers, and exciting announcements.
, @NaveenManwani17 , for the latest updates on Tech and AI-related news, insightful research papers, and exciting announcements. Dataset: Index of /maniwav/data
Dataset: Index of /maniwav/data
 www.marktechpost.com
www.marktechpost.com