

Beyond GPUs: Innatera and the quiet uprising in AI hardware
The brain-inspired architecture gives neuromorphic systems distinct advantages, particularly for edge computing applications in consumer devices and industrial IoT.
 venturebeat.com
venturebeat.com
Beyond GPUs: Innatera and the quiet uprising in AI hardware
James Thomason @jathomasonJuly 6, 2024 6:30 AM

Innatera Spiking Neural Processor
We want to hear from you! Take our quick AI survey and share your insights on the current state of AI, how you’re implementing it, and what you expect to see in the future. Learn More
While much of the tech world remains fixated on the latest large language models (LLMs) powered by Nvidia GPUs, a quieter revolution is brewing in AI hardware. As the limitations and energy demands of traditional deep learning architectures become increasingly apparent, a new paradigm called neuromorphic computing is emerging – one that promises to slash the computational and power requirements of AI by orders of magnitude.
Mimicking nature’s masterpiece: How neuromorphic chips work
But what exactly are neuromorphic systems? To find out, VentureBeat spoke with Sumeet Kumar, CEO and founder of Innatera, a leading startup in the neuromorphic chip space.“Neuromorphic processors are designed to mimic the way biological brains process information,” Kumar explained. “Rather than performing sequential operations on data stored in memory, neuromorphic chips use networks of artificial neurons that communicate through spikes, much like real neurons.”
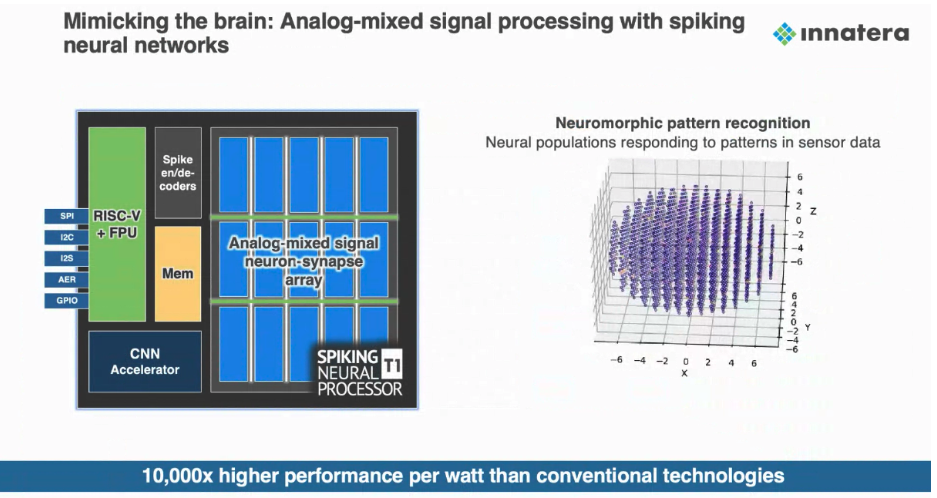
This brain-inspired architecture gives neuromorphic systems distinct advantages, particularly for edge computing applications in consumer devices and industrial IoT. Kumar highlighted several compelling use cases, including always-on audio processing for voice activation, real-time sensor fusion for robotics and autonomous systems, and ultra-low power computer vision.
“The key is that neuromorphic processors can perform complex AI tasks using a fraction of the energy of traditional solutions,” Kumar noted. “This enables capabilities like continuous environmental awareness in battery-powered devices that simply weren’t possible before.”
From doorbell to data center: Real-world applications emerge
Innatera’s flagship product, the Spiking Neural Processor T1, unveiled in January 2024, exemplifies these advantages. The T1 combines an event-driven computing engine with a conventional CNN accelerator and RISC-V CPU, creating a comprehensive platform for ultra-low-power AI in battery-powered devices.“Our neuromorphic solutions can perform computations with 500 times less energy compared to conventional approaches,” Kumar stated. “And we’re seeing pattern recognition speeds about 100 times faster than competitors.”
Kumar illustrated this point with a compelling real-world application. Innatera has partnered with Socionext, a Japanese sensor vendor, to develop an innovative solution for human presence detection. This technology, which Kumar demonstrated at CES in January, combines a radar sensor with Innatera’s neuromorphic chip to create highly efficient, privacy-preserving devices.
“Take video doorbells, for instance,” Kumar explained. “Traditional ones use power-hungry image sensors that need frequent recharging. Our solution uses a radar sensor, which is far more energy-efficient.” The system can detect human presence even when a person is motionless, as long as they have a heartbeat. Being non-imaging, it preserves privacy until it’s necessary to activate a camera.

This technology has wide-ranging applications beyond doorbells, including smart home automation, building security and even occupancy detection in vehicles. “It’s a perfect example of how neuromorphic computing can transform everyday devices,” Kumar noted. “We’re bringing AI capabilities to the edge while actually reducing power consumption and enhancing privacy.”
Doing more with less in AI compute
These dramatic improvements in energy efficiency and speed are driving significant industry interest. Kumar revealed that Innatera has multiple customer engagements, with traction for neuromorphic technologies growing steadily. The company is targeting the sensor-edge applications market, with an ambitious goal of bringing intelligence to a billion devices by 2030.To meet this growing demand, Innatera is ramping up production. The Spiking Neural Processor is slated to enter production later in 2024, with high-volume deliveries starting in Q2 of 2025. This timeline reflects the rapid progress the company has made since spinning out from Delft University of Technology in 2018. In just six years, Innatera has grown to about 75 employees and recently appointed Duco Pasmooij, former VP at Apple, to their advisory board.
The company recently closed a $21 million Series A round to accelerate the development of its spiking neural processors. The round, which was oversubscribed, included investors like Innavest, InvestNL, EIC Fund and MIG Capital. This strong investor backing underscores the growing excitement around neuromorphic computing.
Kumar envisions a future where neuromorphic chips increasingly handle AI workloads at the edge, while larger foundational models remain in the cloud. “There’s a natural complementarity,” he said. “Neuromorphics excel at fast, efficient processing of real-world sensor data, while large language models are better suited for reasoning and knowledge-intensive tasks.”
“It’s not just about raw computing power,” Kumar observed. “The brain achieves remarkable feats of intelligence with a fraction of the energy our current AI systems require. That’s the promise of neuromorphic computing – AI that’s not only more capable but dramatically more efficient.”
Seamless integration with existing tools
Kumar emphasized a key factor that could accelerate the adoption of their neuromorphic technology: developer-friendly tools. “We’ve built a very extensive software development kit that allows application developers to easily target our silicon,” Kumar explained.Innatera’s SDK uses PyTorch as a front end. “You actually develop your neural networks completely in a standard PyTorch environment,” Kumar noted. “So if you know how to build neural networks in PyTorch, you can already use the SDK to target our chips.”
This approach significantly lowers the barrier to entry for developers already familiar with popular machine learning frameworks. It allows them to leverage their existing skills and workflows while tapping into the power and efficiency of neuromorphic computing.
“It is a simple turnkey, standard, and very fast way of building and deploying applications onto our chips,” Kumar added, highlighting the potential for rapid adoption and integration of Innatera’s technology into a wide range of AI applications.

Silicon Valley’s stealth game
While LLMs capture the headlines, industry leaders are quietly acknowledging the need for radically new chip architectures. Notably, OpenAI CEO Sam Altman, who has been vocal about the imminent arrival of artificial general intelligence (AGI) and the need for massive investments in chip manufacturing, personally invested in Rain, another neuromorphic chip startup.This move is telling. Despite Altman’s public statements about scaling up current AI technologies, his investment suggests a recognition that the path to more advanced AI may require a fundamental shift in computing architecture. Neuromorphic computing could be one of the keys to bridging the efficiency gap that current architectures face.
Bridging the gap between artificial and biological intelligence
As AI continues to diffuse into every facet of our lives, the need for more efficient hardware solutions will only grow. Neuromorphic computing represents one of the most exciting frontiers in chip design today, with the potential to enable a new generation of intelligent devices that are both more capable and more sustainable.While large language models capture the headlines, the real future of AI may lie in chips that think more like our own brains. As Kumar put it: “We’re just scratching the surface of what’s possible with neuromorphic systems. The next few years are going to be very exciting.”
As these brain-inspired chips make their way into consumer devices and industrial systems, we may be on the cusp of a new era in artificial intelligence – one that’s faster, more efficient, and more closely aligned with the remarkable abilities of biological brains.





















")













