
1/52
@jiayi_pirate
We reproduced DeepSeek R1-Zero in the CountDown game, and it just works
Through RL, the 3B base LM develops self-verification and search abilities all on its own
You can experience the Ahah moment yourself for < $30
Code: GitHub - Jiayi-Pan/TinyZero: Clean, accessible reproduction of DeepSeek R1-Zero
Here's what we learned

2/52
@jiayi_pirate
The recipe:
We follow DeepSeek R1-Zero alg -- Given a base LM, prompts and ground-truth reward, we run RL.
We apply it to CountDown: a game where players combine numbers with basic arithmetic to reach a target number.
3/52
@jiayi_pirate
The results: It just works!
Model start from dummy outputs but gradually develop tactics such as revision and search.
In the following sample, the model propose a solution, self-verify, and iteratively revise it until it works.
Full experiment log: jiayipan

4/52
@jiayi_pirate
Quick ablations on CountDown:
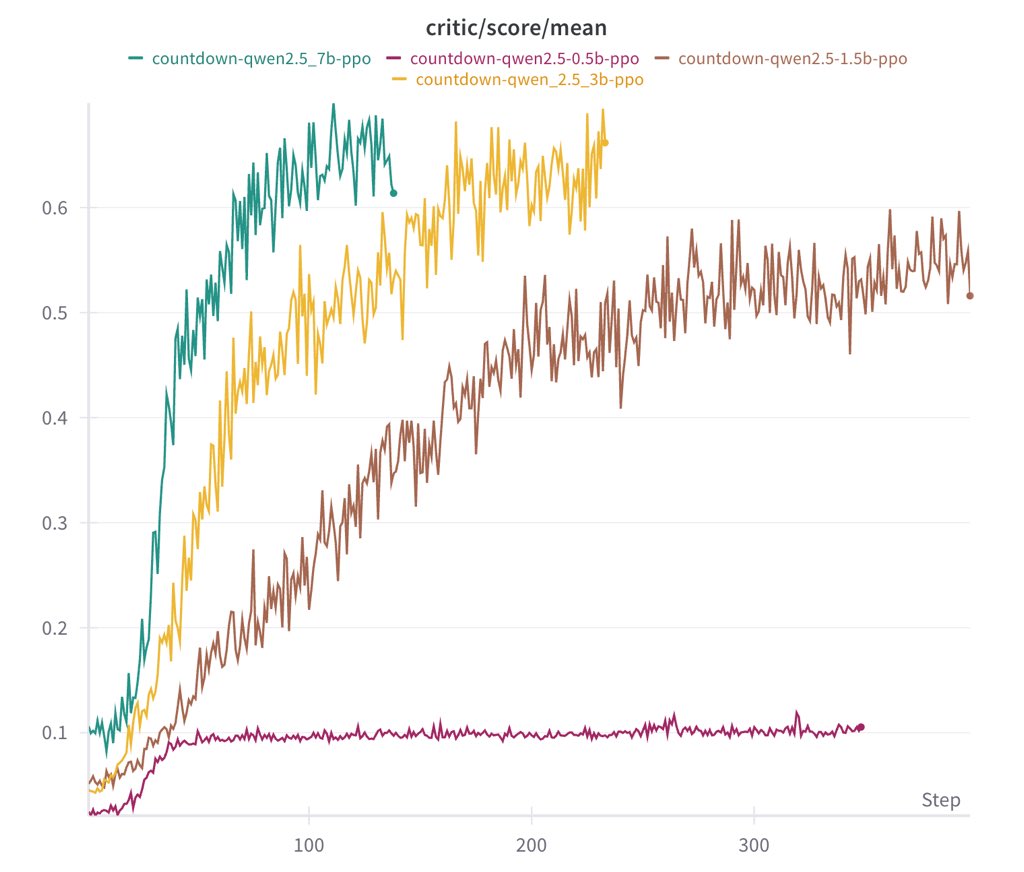
Base model quality is key:
We run Qwen-2.5-Base 0.5B, 1.5B, 3B to 7B. 0.5B guess a solution and stop. From 1.5B, the model start learning to search, to self-verify and to revise its solutions, enabling them to achieve much higher scores.
5/52
@jiayi_pirate
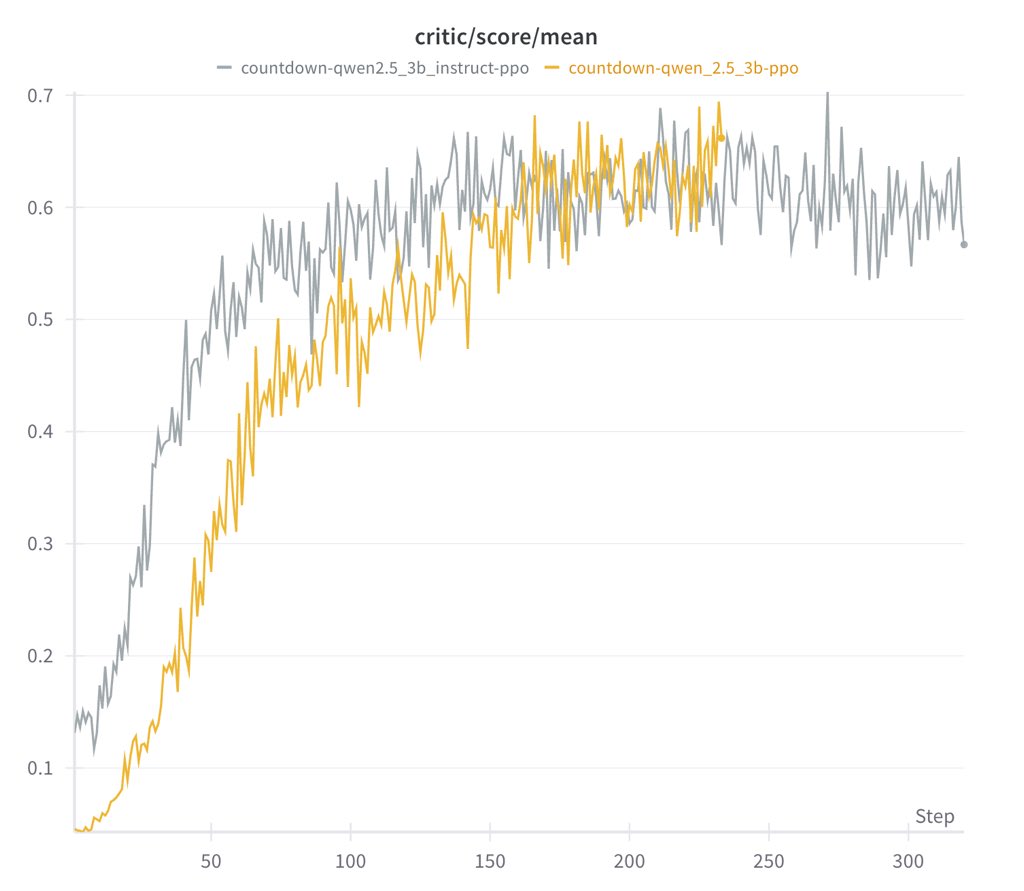
Either base or instruct model works
- Instruct model learns faster, but converges to about same performance as base
- Instruct model's output are more structured and readable
So extra instruction tuning isn't necessary, which supports R1-Zero's design decision
6/52
@jiayi_pirate
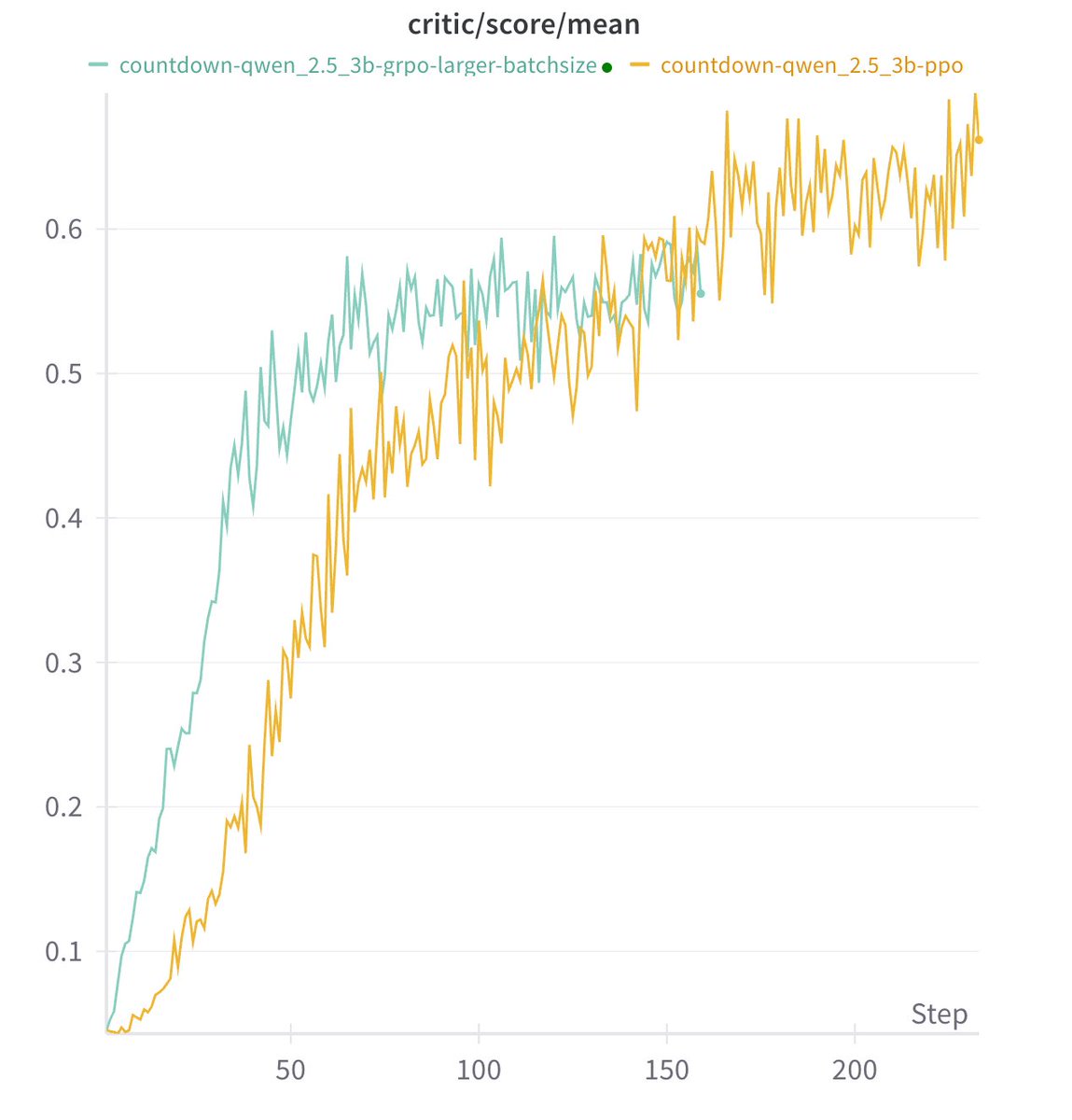
The specific RL alg doesn't matter much
We tried PPO, GRPO and PRIME. Long cot all emerge and they seem all work well. We haven't got the time to tune the hyper-parameters, so don't want to make quantitative conclusions about which alg works better.
7/52
@jiayi_pirate
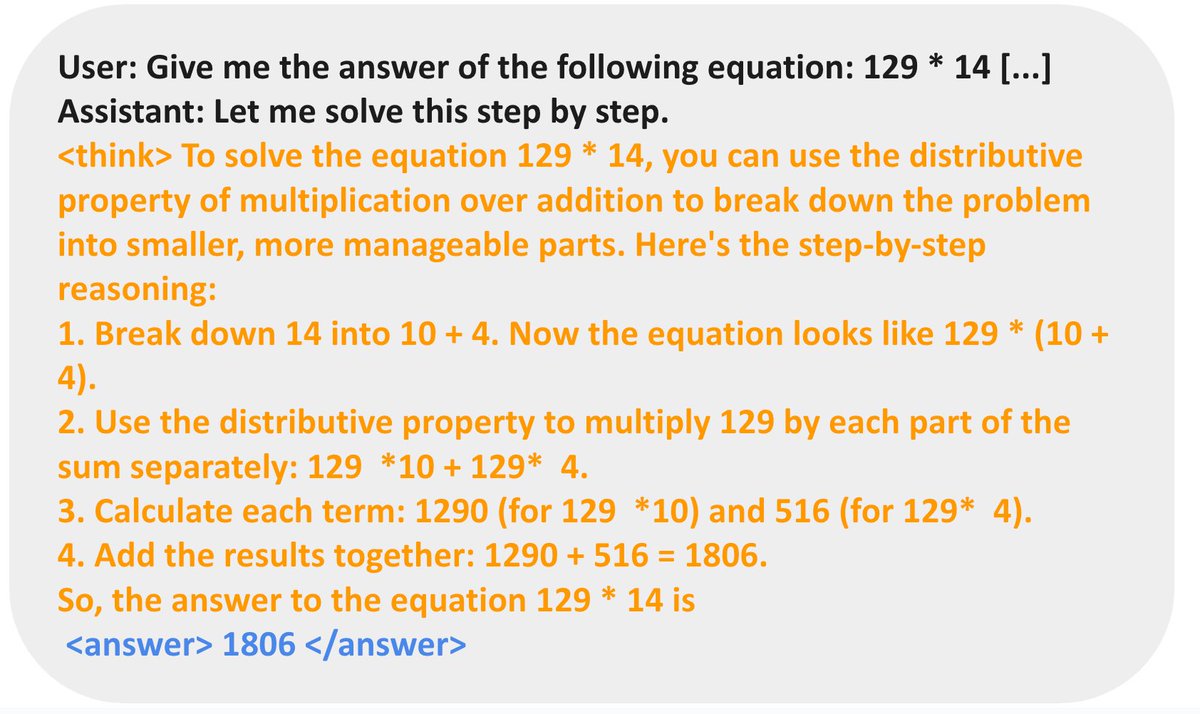
Model's reasoning behavior is very task dependent:
- For countdown, the model learns to do search and self-verificatoin
- For number multiplicatoin, the model instead learns to break down the problem using distirbution rule and solve it step by step.
8/52
@jiayi_pirate
Everything's open at GitHub - Jiayi-Pan/TinyZero: Clean, accessible reproduction of DeepSeek R1-Zero
And it costs < $30 to train the model! We hope this project helps to demystify the emerging RL scaling research and make it more accessible!
9/52
@jiayi_pirate
One caveat, of course, is that it's validated only in the Countdown task but not the general reasoning domain. We are now bounded by compute, and please reach out if you wanna help!
10/52
@jiayi_pirate
A wild ride with @JunjieZhang12 @xingyaow_ @lifan__yuan
11/52
@deter3
The dataset in github is Jiayi-Pan/Countdown-Tasks-3to4 , right ?
12/52
@jiayi_pirate
Yes, right here Jiayi-Pan/Countdown-Tasks-3to4 · Datasets at Hugging Face
13/52
@duluhagv
is the countdown dataset gen also open source? i lol'ed when I saw this release today after working on something similar last night
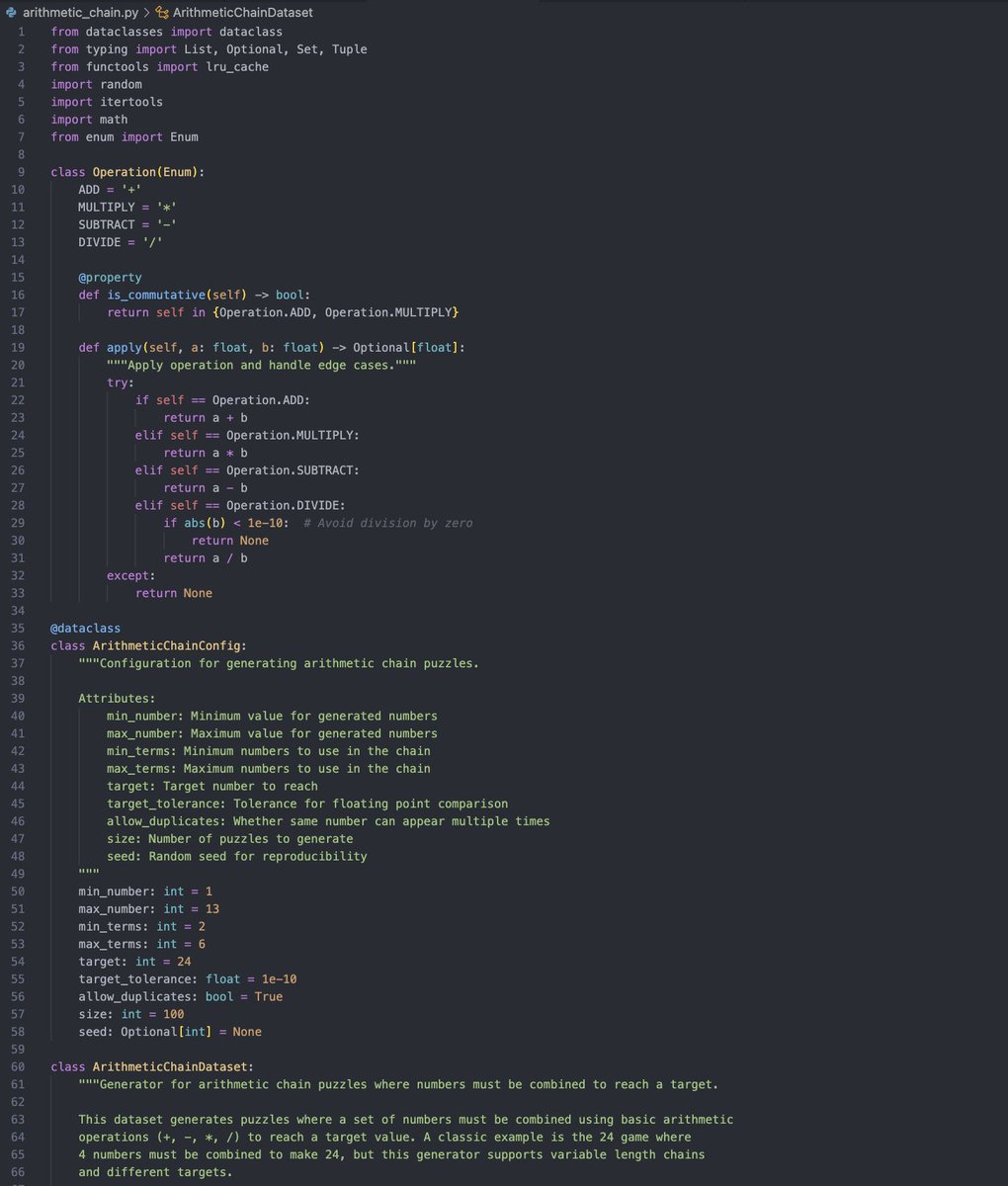
14/52
@jiayi_pirate
Hi the countdown generation code is mostly borrowed from Stream-of-Search
stream-of-search/src/countdown_generate.py at main · kanishkg/stream-of-search
Preprocessed the data is here:
Jiayi-Pan/Countdown-Tasks-3to4 · Datasets at Hugging Face
Everything's open and reproducible
15/52
@Samhanknr
How feasible do you think it is to teach a model to work on a given codebase. For eg - teach is to write unit tests , pass unit tests in given codebase using RL. Would it be affordable ?
16/52
@jiayi_pirate
That’s definitely possible. We are working on this
[Quoted tweet]
Introducing SWE-Gym: An Open Environment for Training Software Engineering Agents & Verifiers
Using SWE-Gym, our agents + verifiers reach new open SOTA - 32%/26% on SWE-Bench Verified/Lite,
showing strong scaling with more train / test compute
github.com/SWE-Gym/SWE-Gym []

17/52
@frankxu2004
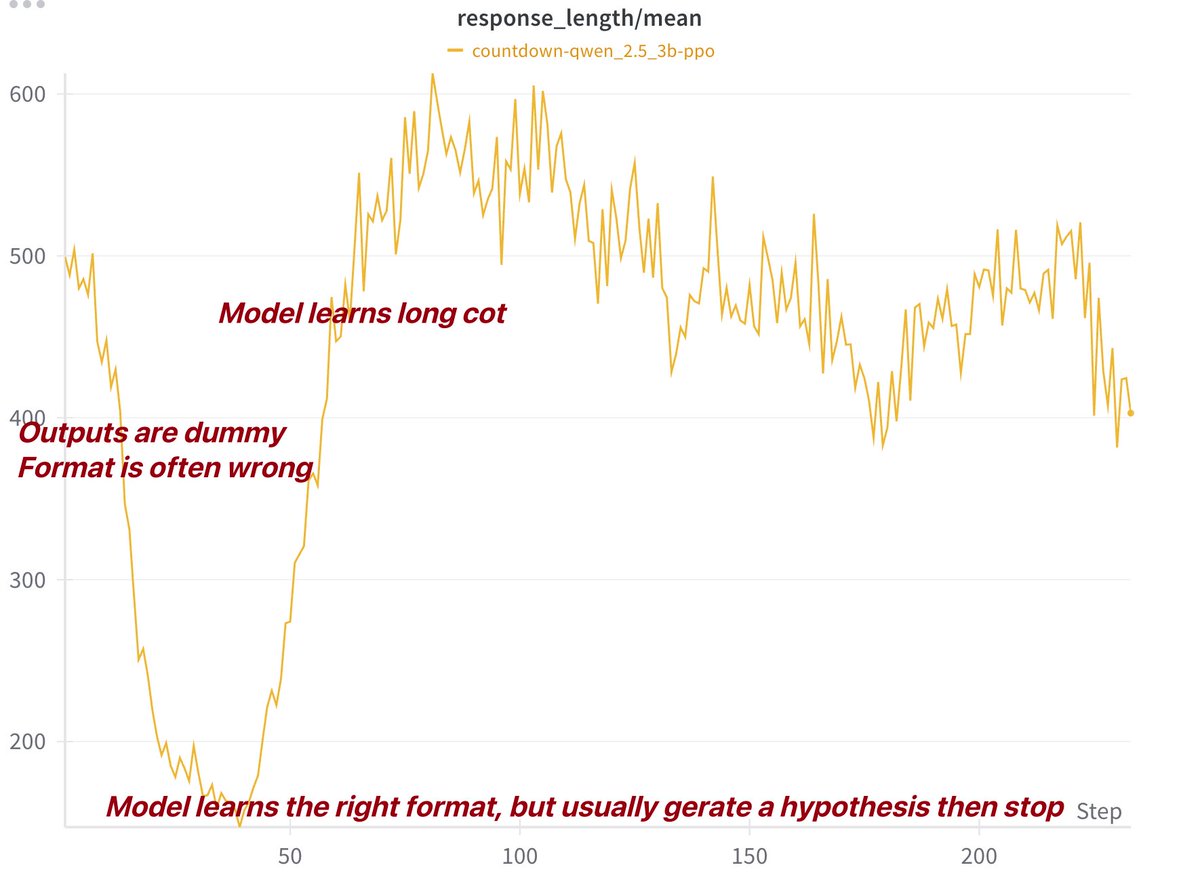
Very nice! One question: do you have any observation regarding CoT length changes during training? Is there a plot showcasing CoT length increased during training?
18/52
@jiayi_pirate
Great question! Early results show the 3B model initially reduces output length for correct formatting, then increases chain-of-thought length for better performance.
There may be minor code mismatches, so take this with a grain of salt.
Raw log:
jiayipan
19/52
@bennetkrause
One question: What model size and algorithm do the $30 refer to?
20/52
@jiayi_pirate
3B model, PPO, it takes 10 H100 hours
21/52
@wzihanw
Nice!
22/52
@reissbaker
this is really cool. any chance for a huggingface model upload so we can play around with it?
23/52
@_herobotics_
Any insight on why open llama achieves high response length but low scores?
24/52
@jiayi_pirate
OpenLlama doesn't like to generate EOS tokens, and since we haven't implemented stop after </answer>, the model often fails to terminate.
We didn't report OpenLlama's results in the Twitter thread as we believe the results will improve significantly once we fix this problem.
25/52
@GiorgioMantova
Do you find the original papers' numbers about the training cost to be plausible?
26/52
@jiayi_pirate
Yes, with MoE and FP8, that’s expected
27/52
@paul_cal
This is such a beautiful, efficient demonstration of something very powerful. Great idea
28/52
@anushkmittal
$30? might as well be free. nice work
29/52
@iamRezaSayar
this is very interesting.
I'm wondering about 2 things now. 1. if we could extend these beyond verifiable math problems, to say, empathy. and 2. if people would need / want to train their own personal reward model that is tuned to each user's prefrences
30/52
@HolgersenTobias
That was fast Excellent work. This paradigm seems robust and scalable.
Excellent work. This paradigm seems robust and scalable.
Bottleneck now will be gathering huge, diverse sets of hard but verifiable tasks.
31/52
@CharlieYouAI
Incredible work! and super cool result
32/52
@RishfulThinking
Excuse me, fukking WHAT
33/52
@garybasin
Hell yeah
34/52
@rrektcapital
Could you kindly ELI5 what RL means in this case?
35/52
@burny_tech
Cambrian explosion of RL on LLMs begins
36/52
@bookwormengr
Could you please provide flop analysis?
37/52
@nooriefyi
love seeing this kind of ingenuity in action. what were the biggest hurdles you faced?
38/52
@SurfTheUniverse
Was this supposed to work?
39/52
@AntDX316
There's going to be no way for people to intentionally 'inflate' the required amount of tokens by adding certain things that makes it look like it costs more to run a generation, when it doesn't.
The ASI-Singularity(Godsend) is the only Global Solution, people.
40/52
@ReplayRyan
Huge
41/52
@nrehiew_
Thanks for this! I wonder if you guys tried llama 3 7B instead of llama 2 7B. Also would be interesting if you guys have like a completely overtrain/overfitted run similar to what the TULU3 team experimented with.
42/52
@suwakopro
So cool, intelligence is reproducible.
43/52
@xiaoze_jin
Need to look into it; thanks for sharing
44/52
@corefpark
Thanks for open sourcing this!!!! This is an enourmous contribution of understanding the science of RLxLLMs!!
45/52
@JunYang1688
Great post. That DeepSeek core contributions can be reproduced at lightning speed demonstrates the power of open source! It will definitely accelerate the progress towards AGI.
46/52
@fjrdomingues
How do I super like a post?
47/52
@Vrda82073569
The Bitter Lesson strikes again!
48/52
@Nick_from_Texas
Any idea how autoregressive models become capable of self verification?
How do they avoid getting stuck along one chain of thought due to an earlier suboptimal token?
49/52
@neurosp1ke
Inspired by your experiment I added a procedural generator for countdown games to GitHub - open-thought/reasoning-gym: procedural reasoning datasets
50/52
@adamnemecek1
All machine learning approaches are convolutional inverses, including RL and LLMs.
51/52
@soheilsadathoss
Awesome!
52/52
@Kathleen_Tyson_
I played Scrabble against the All Time Countdown Champion last year. He destroyed me. Nice guy, though.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@jiayi_pirate
We reproduced DeepSeek R1-Zero in the CountDown game, and it just works
Through RL, the 3B base LM develops self-verification and search abilities all on its own
You can experience the Ahah moment yourself for < $30
Code: GitHub - Jiayi-Pan/TinyZero: Clean, accessible reproduction of DeepSeek R1-Zero
Here's what we learned
2/52
@jiayi_pirate
The recipe:
We follow DeepSeek R1-Zero alg -- Given a base LM, prompts and ground-truth reward, we run RL.
We apply it to CountDown: a game where players combine numbers with basic arithmetic to reach a target number.
3/52
@jiayi_pirate
The results: It just works!
Model start from dummy outputs but gradually develop tactics such as revision and search.
In the following sample, the model propose a solution, self-verify, and iteratively revise it until it works.
Full experiment log: jiayipan
4/52
@jiayi_pirate
Quick ablations on CountDown:
Base model quality is key:
We run Qwen-2.5-Base 0.5B, 1.5B, 3B to 7B. 0.5B guess a solution and stop. From 1.5B, the model start learning to search, to self-verify and to revise its solutions, enabling them to achieve much higher scores.
5/52
@jiayi_pirate
Either base or instruct model works
- Instruct model learns faster, but converges to about same performance as base
- Instruct model's output are more structured and readable
So extra instruction tuning isn't necessary, which supports R1-Zero's design decision
6/52
@jiayi_pirate
The specific RL alg doesn't matter much
We tried PPO, GRPO and PRIME. Long cot all emerge and they seem all work well. We haven't got the time to tune the hyper-parameters, so don't want to make quantitative conclusions about which alg works better.
7/52
@jiayi_pirate
Model's reasoning behavior is very task dependent:
- For countdown, the model learns to do search and self-verificatoin
- For number multiplicatoin, the model instead learns to break down the problem using distirbution rule and solve it step by step.
8/52
@jiayi_pirate
Everything's open at GitHub - Jiayi-Pan/TinyZero: Clean, accessible reproduction of DeepSeek R1-Zero
And it costs < $30 to train the model! We hope this project helps to demystify the emerging RL scaling research and make it more accessible!
9/52
@jiayi_pirate
One caveat, of course, is that it's validated only in the Countdown task but not the general reasoning domain. We are now bounded by compute, and please reach out if you wanna help!
10/52
@jiayi_pirate
A wild ride with @JunjieZhang12 @xingyaow_ @lifan__yuan
11/52
@deter3
The dataset in github is Jiayi-Pan/Countdown-Tasks-3to4 , right ?
12/52
@jiayi_pirate
Yes, right here Jiayi-Pan/Countdown-Tasks-3to4 · Datasets at Hugging Face
13/52
@duluhagv
is the countdown dataset gen also open source? i lol'ed when I saw this release today after working on something similar last night
14/52
@jiayi_pirate
Hi the countdown generation code is mostly borrowed from Stream-of-Search
stream-of-search/src/countdown_generate.py at main · kanishkg/stream-of-search
Preprocessed the data is here:
Jiayi-Pan/Countdown-Tasks-3to4 · Datasets at Hugging Face
Everything's open and reproducible
15/52
@Samhanknr
How feasible do you think it is to teach a model to work on a given codebase. For eg - teach is to write unit tests , pass unit tests in given codebase using RL. Would it be affordable ?
16/52
@jiayi_pirate
That’s definitely possible. We are working on this
[Quoted tweet]
Introducing SWE-Gym: An Open Environment for Training Software Engineering Agents & Verifiers
Using SWE-Gym, our agents + verifiers reach new open SOTA - 32%/26% on SWE-Bench Verified/Lite,
showing strong scaling with more train / test compute
github.com/SWE-Gym/SWE-Gym [
]
17/52
@frankxu2004
Very nice! One question: do you have any observation regarding CoT length changes during training? Is there a plot showcasing CoT length increased during training?
18/52
@jiayi_pirate
Great question! Early results show the 3B model initially reduces output length for correct formatting, then increases chain-of-thought length for better performance.
There may be minor code mismatches, so take this with a grain of salt.
Raw log:
jiayipan
19/52
@bennetkrause
One question: What model size and algorithm do the $30 refer to?
20/52
@jiayi_pirate
3B model, PPO, it takes 10 H100 hours
21/52
@wzihanw
Nice!
22/52
@reissbaker
this is really cool. any chance for a huggingface model upload so we can play around with it?
23/52
@_herobotics_
Any insight on why open llama achieves high response length but low scores?
24/52
@jiayi_pirate
OpenLlama doesn't like to generate EOS tokens, and since we haven't implemented stop after </answer>, the model often fails to terminate.
We didn't report OpenLlama's results in the Twitter thread as we believe the results will improve significantly once we fix this problem.
25/52
@GiorgioMantova
Do you find the original papers' numbers about the training cost to be plausible?
26/52
@jiayi_pirate
Yes, with MoE and FP8, that’s expected
27/52
@paul_cal
This is such a beautiful, efficient demonstration of something very powerful. Great idea
28/52
@anushkmittal
$30? might as well be free. nice work
29/52
@iamRezaSayar
this is very interesting.
I'm wondering about 2 things now. 1. if we could extend these beyond verifiable math problems, to say, empathy. and 2. if people would need / want to train their own personal reward model that is tuned to each user's prefrences
30/52
@HolgersenTobias
That was fast
Excellent work. This paradigm seems robust and scalable. Bottleneck now will be gathering huge, diverse sets of hard but verifiable tasks.
31/52
@CharlieYouAI
Incredible work! and super cool result
32/52
@RishfulThinking
Excuse me, fukking WHAT
33/52
@garybasin
Hell yeah
34/52
@rrektcapital
Could you kindly ELI5 what RL means in this case?
35/52
@burny_tech
Cambrian explosion of RL on LLMs begins
36/52
@bookwormengr
Could you please provide flop analysis?
37/52
@nooriefyi
love seeing this kind of ingenuity in action. what were the biggest hurdles you faced?
38/52
@SurfTheUniverse
Was this supposed to work?
39/52
@AntDX316
There's going to be no way for people to intentionally 'inflate' the required amount of tokens by adding certain things that makes it look like it costs more to run a generation, when it doesn't.
The ASI-Singularity(Godsend) is the only Global Solution, people.
40/52
@ReplayRyan
Huge
41/52
@nrehiew_
Thanks for this! I wonder if you guys tried llama 3 7B instead of llama 2 7B. Also would be interesting if you guys have like a completely overtrain/overfitted run similar to what the TULU3 team experimented with.
42/52
@suwakopro
So cool, intelligence is reproducible.
43/52
@xiaoze_jin
Need to look into it; thanks for sharing
44/52
@corefpark
Thanks for open sourcing this!!!! This is an enourmous contribution of understanding the science of RLxLLMs!!
45/52
@JunYang1688
Great post. That DeepSeek core contributions can be reproduced at lightning speed demonstrates the power of open source! It will definitely accelerate the progress towards AGI.
46/52
@fjrdomingues
How do I super like a post?
47/52
@Vrda82073569
The Bitter Lesson strikes again!
48/52
@Nick_from_Texas
Any idea how autoregressive models become capable of self verification?
How do they avoid getting stuck along one chain of thought due to an earlier suboptimal token?
49/52
@neurosp1ke
Inspired by your experiment I added a procedural generator for countdown games to GitHub - open-thought/reasoning-gym: procedural reasoning datasets
50/52
@adamnemecek1
All machine learning approaches are convolutional inverses, including RL and LLMs.
51/52
@soheilsadathoss
Awesome!
52/52
@Kathleen_Tyson_
I played Scrabble against the All Time Countdown Champion last year. He destroyed me. Nice guy, though.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196


 This is a prime opportunity
This is a prime opportunity

 bro, you've been in this thread playing Captain Save A Hoe trying to save face for Amerikka this whole entire time.
bro, you've been in this thread playing Captain Save A Hoe trying to save face for Amerikka this whole entire time. your running late for the old white man.
your running late for the old white man.



