
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?Complexion
ʇdᴉɹɔsǝɥʇdᴉlɟ
Within the next few months this is gonna unleash so much content on the web. I'm talking double or tripling everything out there within a year or so levels.
From blogs to entire thesis penned by AI upto animated features and whole presentations:
I find it so wild that on one side you could argue humanity is the least creative its ever been since the net kicked in (see movies, popular culture, trends etc) and at the same time this cut and paste creator amalgamator pops up with the solutions to the problems it itself created.
Nothing new in one respect as that is exactly how politics works but the scale of this is so immense.

In 2088 humanity will be getting chased through its buildings by its very own creation. That ether, the ish that digitizies your Soul slow...
From blogs to entire thesis penned by AI upto animated features and whole presentations:
I find it so wild that on one side you could argue humanity is the least creative its ever been since the net kicked in (see movies, popular culture, trends etc) and at the same time this cut and paste creator amalgamator pops up with the solutions to the problems it itself created.
Nothing new in one respect as that is exactly how politics works but the scale of this is so immense.
In 2088 humanity will be getting chased through its buildings by its very own creation. That ether, the ish that digitizies your Soul slow...

ReRoom AI
Transform your living space effortlessly with AI-generated dream rooms. Take a picture, pick a theme, and reimagine your room with style. Embrace the future of interior design today!
 reroom.ai
reroom.ai
Fresh Ideas for Interior Design
Upload a picture of your room,
explore various design styles(20+),
and remodel your space today!
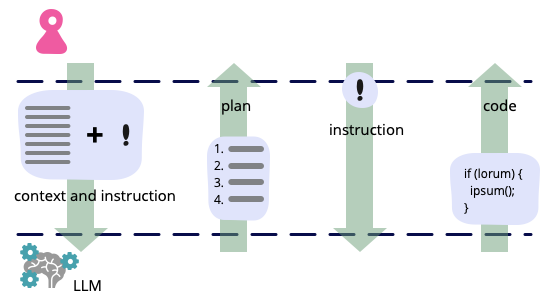
An example of LLM prompting for programming
Generated knowledge and chain of thought prompting of an LLM can generate useful code.
martinfowler.com
An example of LLM prompting for programming
Xu Hao uses chain of thought and general knowledge prompting with ChatGPT when writing self-testing codeMy account of an internal chat with Xu Hao, where he shows how he drives ChatGPT to produce useful self-tested code. His initial prompt primes the LLM with an implementation strategy (chain of thought prompting). His prompt also asks for an implementation plan rather than code (general knowledge prompting). Once he has the plan he uses it to refine the implementation and generate useful sections of code.
making smilies easily is about to be fully possible.


gonna try adding more masking to the head.
edit:

As a graphic artist who has spent countless hours over the course of over two decades becoming expert level good at doing things like clipping out things/people from backgrounds I feel a kinda way about this. They way they train the AI is by letting it watch humans do it the old fashioned way. Wild...
I’m just thinking out loud here but I feel like the only way to combat some of this stuff is even more privacy invasions. I’m specifically talking about someone faking your voice saying some shyt or using AI to generate media of you whether an image or a video. Almost gotta have another device around you as an alibi. Wild times

Reddit founder wants to charge Big Tech for scraped data used to train AIs: report
Online community network Reddit wants to start getting paid by large artificial-intelligence companies that scrape data off its message boards to help train...
Reddit founder wants to charge Big Tech for scraped data used to train AIs: report
Published: April 18, 2023 at 2:06 p.m. ETBy Wallace Witkowski
Online community network Reddit wants to start getting paid by large artificial-intelligence companies that scrape data off its message boards to help train AI products. In an interview with the New York Times, Reddit founder and Chief Executive Steve Huffman said that the “Reddit corpus of data is really valuable. But we don’t need to give all of that value to some of the largest companies in the world for free.” Generative AI has gone mainstream this past year with the release of OpenAI’s ChatGPT — backed by a multibillion-dollar investment from Microsoft Corp. MSFT, -0.15%. AI uses massive amounts of data drawn from a site’s application program interface, or API, to train the AI product and train for inference. Alphabet Inc.’s GOOG, -1.22% GOOGL, -1.39% Google also has a generative-AI product, Bard, and Adobe Inc. ADBE, -0.10% recently released an AI product named Firefly, a “co-pilot” technology aimed at helping create content. Meta Platforms Inc. META, -0.44% has its own eponymous product, Meta AI, while Amazon.com Inc.’s AMZN, -0.43% AWS has released free machine-learning tools for users."
Visual Instruction Tuning
LLaVA: Large Language and Vision Assistant
LLaVA represents a novel end-to-end trained large multimodal model that combines a vision encoder and Vicuna for general-purpose visual and language understanding, achieving impressive chat capabilities mimicking spirits of the multimodal GPT-4 and setting a new state-of-the-art accuracy on Science QA.
Abstract
Instruction tuning large language models (LLMs) using machine-generated instruction-following data has improved zero-shot capabilities on new tasks in the language domain, but the idea is less explored in the multimodal field.- Multimodal Instruct Data. We present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data.
- LLaVA Model. We introduce LLaVA (Large Language-and-Vision Assistant), an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding.
- Performance. Our early experiments show that LLaVA demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%.
- Open-source. We make GPT-4 generated visual instruction tuning data, our model and code base publicly available.
 Multimodal Instrucion-Following Data
Multimodal Instrucion-Following Data
Based on the COCO dataset, we interact with langauge-only GPT-4, and collect 158K unique language-image instruction-following samples in total, including 58K in conversations, 23K in detailed description, and 77k in complex reasoning, respectively. Please check out ``LLaVA-Instruct-150K''' on [HuggingFace Dataset].
 LLaVA: Large Language-and-Vision Assistant
LLaVA: Large Language-and-Vision Assistant
LLaVa connects pre-trained CLIP ViT-L/14 visual encoder and large language model LLaMA, using a simple projection matrix. We consider a two-stage instruction-tuning procedure:- Stage 1: Pre-training for Feature Alignment. Only the projection matrix is updated, based on a subset of CC3M.
- Stage 2: Fine-tuning End-to-End.. Both the projection matrix and LLM are updated for two different use senarios:
- Visual Chat: LLaVA is fine-tuned on our generated multimodal instruction-following data for daily user-oriented applications.
- Science QA: LLaVA is fine-tuned on this multimodal reasonsing dataset for the science domain.

 Performance
Performance
 Visual Chat: Towards building multimodal GPT-4 level chatbot
Visual Chat: Towards building multimodal GPT-4 level chatbot
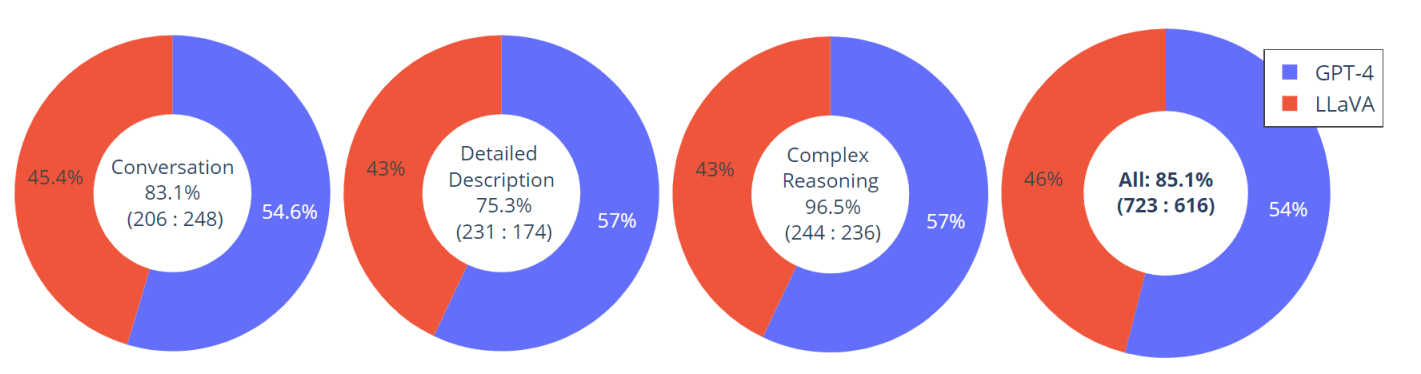
An evaluation dataset with 30 unseen images is constructed: each image is assocaited with three types of instructions: conversation, detailed description and complex reasoning. This leads to 90 new language-image instructions, on which we test LLaVA and GPT-4, and use GPT-4 to rate their responses from score 1 to 10. The summed score and relative score per type is reported. Overall, LLaVA achieves 85.1% relative score compared with GPT-4, indicating the effectinvess of the proposed self-instruct method in multimodal settings
 Science QA: New SoTA with the synergy of LLaVA with GPT-4
Science QA: New SoTA with the synergy of LLaVA with GPT-4
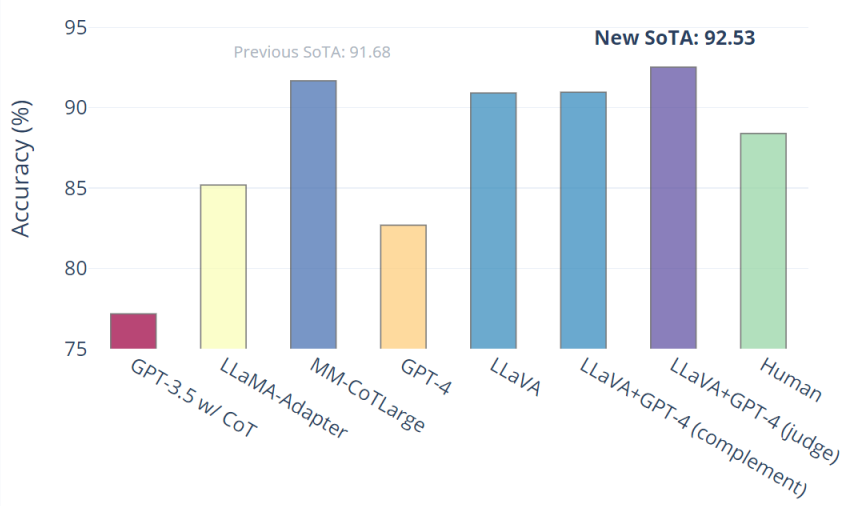
LLaVA alones achieve 90.92%. We use the text-only GPT-4 as the juedge, to predict the final answer based on its own previous answers and the LLaVA answers. This ``GPT-4 as juedge'' scheme yields a new SOTA 92.53%.
Examples on Visual Instruction Following
Visual Reasoning on two examples from OpenAI GPT-4 Technical Report

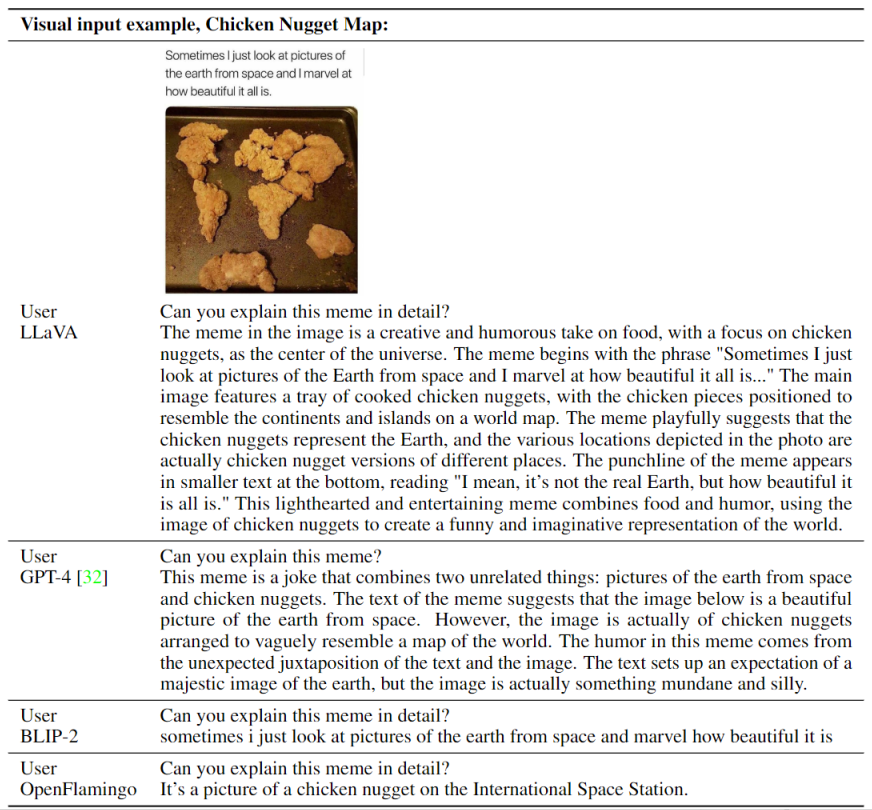
Optical character recognition (OCR)
GitHub - haotian-liu/LLaVA: [NeurIPS'23 Oral] Visual Instruction Tuning (LLaVA) built towards GPT-4V level capabilities and beyond.
[NeurIPS'23 Oral] Visual Instruction Tuning (LLaVA) built towards GPT-4V level capabilities and beyond. - haotian-liu/LLaVA
 github.com
github.com





Max Kennerly (@maxkennerly@mstdn.social)
Attached: 2 images I don't recall giving Google, Facebook, or anybody else permission to scrape 180k tokens—roughly the length of Orwell's 1984—from my blog for commercial purposes. And putting my copyrighted work in a blender with bigots like VDARE, st0rmfr0nt, and Kiwifarms doesn't make it...

James Gleick (@JamesGleick@zirk.us)
Regulating AI is a hard problem. But here’s an easy, practical, and necessary first step: Require anyone selling an #AI product to disclose the contents of the data set used in its creation. Do it now. https://www.washingtonpost.com/technology/interactive/2023/ai-chatbot-learning/

Stability AI Launches the First of its Stable LM Suite of Language Models — Stability AI
Stability AI's open-source Alpha version of StableLM showcases the power of small, efficient models that can generate high-performing text and code locally on personal devices. Discover how StableLM can drive innovation and open up new economic opportunities while supporting transparency and accessi
 stability.ai
stability.ai
GitHub - Stability-AI/StableLM: StableLM: Stability AI Language Models
StableLM: Stability AI Language Models. Contribute to Stability-AI/StableLM development by creating an account on GitHub.
github.com
StableLM: Stability AI Language Models

“A Stochastic Parrot, flat design, vector art” — Stable Diffusion XL
This repository contains Stability AI's ongoing development of the StableLM series of language models and will be continuously updated with new checkpoints. The following provides an overview of all currently available models. More coming soon.
News
April 20, 2023- Released initial set of StableLM-alpha models, with 3B and 7B parameters. 15B and 30B models are on the way. Base models are released under CC BY-SA-4.0.
- Try to chat with our 7B model, StableLM-Tuned-Alpha-7B, on Hugging Face Spaces.
Models
StableLM-Alpha
StableLM-Alpha models are trained on the new dataset that build on The Pile, which contains 1.5 trillion tokens, roughly 3x the size of The Pile. These models will be trained on up to 1.5 trillion tokens. The context length for these models is 4096 tokens.An upcoming technical report will document the model specifications and the training settings.
As a proof-of-concept, we also fine-tuned the model with Stanford Alpaca's procedure using a combination of five recent datasets for conversational agents: Stanford's Alpaca, Nomic-AI's gpt4all, RyokoAI's ShareGPT52K datasets, Databricks labs' Dolly, and Anthropic's HH. We will be releasing these models as StableLM-Tuned-Alpha.
Try out the 7 billion parameter fine-tuned chat model (for research purposes) :

Stablelm Tuned Alpha Chat - a Hugging Face Space by stabilityai
Discover amazing ML apps made by the community
huggingface.co
StableLM: A new open-source language model | Hacker News
Last edited: