
1/1
[CV] Understanding Alignment in Multimodal LLMs: A Comprehensive Study
[2407.02477] Understanding Alignment in Multimodal LLMs: A Comprehensive Study
- This paper examines alignment strategies for Multimodal Large Language Models (MLLMs) to reduce hallucinations and improve visual grounding. It categorizes alignment methods into offline (e.g. DPO) and online (e.g. Online-DPO).
- The paper reviews recently published multimodal preference datasets like POVID, RLHF-V, VLFeedback and analyzes their components: prompts, chosen responses, rejected responses.
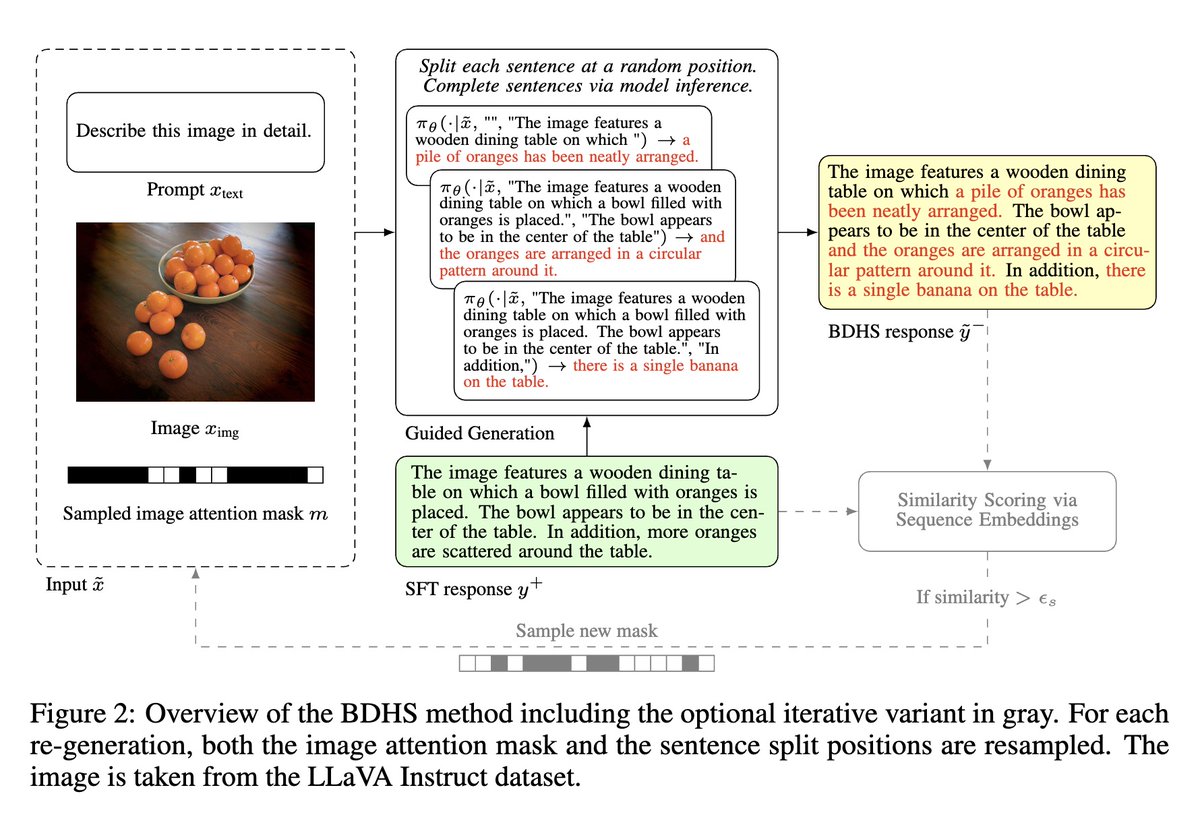
- It introduces a new preference data sampling method called Bias-Driven Hallucination Sampling (BDHS) which restricts image access to induce language model bias and trigger hallucinations.
- Experiments align the LLaVA 1.6 model and compare offline, online and mixed DPO strategies. Results show combining offline and online can yield benefits.
- The proposed BDHS method achieves strong performance without external annotators or preference data, just using self-supervised data.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
[CV] Understanding Alignment in Multimodal LLMs: A Comprehensive Study
[2407.02477] Understanding Alignment in Multimodal LLMs: A Comprehensive Study
- This paper examines alignment strategies for Multimodal Large Language Models (MLLMs) to reduce hallucinations and improve visual grounding. It categorizes alignment methods into offline (e.g. DPO) and online (e.g. Online-DPO).
- The paper reviews recently published multimodal preference datasets like POVID, RLHF-V, VLFeedback and analyzes their components: prompts, chosen responses, rejected responses.
- It introduces a new preference data sampling method called Bias-Driven Hallucination Sampling (BDHS) which restricts image access to induce language model bias and trigger hallucinations.
- Experiments align the LLaVA 1.6 model and compare offline, online and mixed DPO strategies. Results show combining offline and online can yield benefits.
- The proposed BDHS method achieves strong performance without external annotators or preference data, just using self-supervised data.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196


 SIGGRAPH 2024 Paper Alert
SIGGRAPH 2024 Paper Alert  Paper Title: CharacterGen: Efficient 3D Character Generation from Single Images with
Paper Title: CharacterGen: Efficient 3D Character Generation from Single Images with Few pointers from the paper
Few pointers from the paper In this paper authors have presented “CharacterGen”, a framework developed to efficiently generate 3D characters. CharacterGen introduces a streamlined generation pipeline along with an image-conditioned multi-view diffusion model.
In this paper authors have presented “CharacterGen”, a framework developed to efficiently generate 3D characters. CharacterGen introduces a streamlined generation pipeline along with an image-conditioned multi-view diffusion model. Organization: @Tsinghua_Uni , @VastAIResearch
Organization: @Tsinghua_Uni , @VastAIResearch  Paper Authors: Hao-Yang Peng, Jia-Peng Zhang, @MengHaoGuo1 , @yanpei_cao , Shi-Min Hu
Paper Authors: Hao-Yang Peng, Jia-Peng Zhang, @MengHaoGuo1 , @yanpei_cao , Shi-Min Hu Read the Full Paper here:
Read the Full Paper here:  Project Page:
Project Page:  Code:
Code:  Be sure to watch the attached Video-Sound on
Be sure to watch the attached Video-Sound on 
 ?
? QT and teach your network something new
QT and teach your network something new , @NaveenManwani17 , for the latest updates on Tech and AI-related news, insightful research papers, and exciting announcements.
, @NaveenManwani17 , for the latest updates on Tech and AI-related news, insightful research papers, and exciting announcements. Model:
Model:  Music by Breakz Studios from @pixabay
Music by Breakz Studios from @pixabay 


 “VOICE ISOLATOR”
“VOICE ISOLATOR” 
 In this paper authors have proposed “EquiBot”, a robust, data-efficient, and generalizable approach for robot manipulation task learning. Their approach combines SIM(3)-equivariant neural network architectures with diffusion models.
In this paper authors have proposed “EquiBot”, a robust, data-efficient, and generalizable approach for robot manipulation task learning. Their approach combines SIM(3)-equivariant neural network architectures with diffusion models. rolling-out sequences of continuous tokens, such as video, with lengths past the training horizon, where baselines diverge and
rolling-out sequences of continuous tokens, such as video, with lengths past the training horizon, where baselines diverge and