1/18
Finally, I present you my first ever preprint:
MLKV: Multi-Layer Key-Value Heads for Memory Efficient Transformer Decoding
We show that sharing KV heads between layers allows for KV cache smaller than GQA/MQA allowed for, with reasonable acc/mem tradeoff
[2406.09297] MLKV: Multi-Layer Key-Value Heads for Memory Efficient Transformer Decoding
2/18
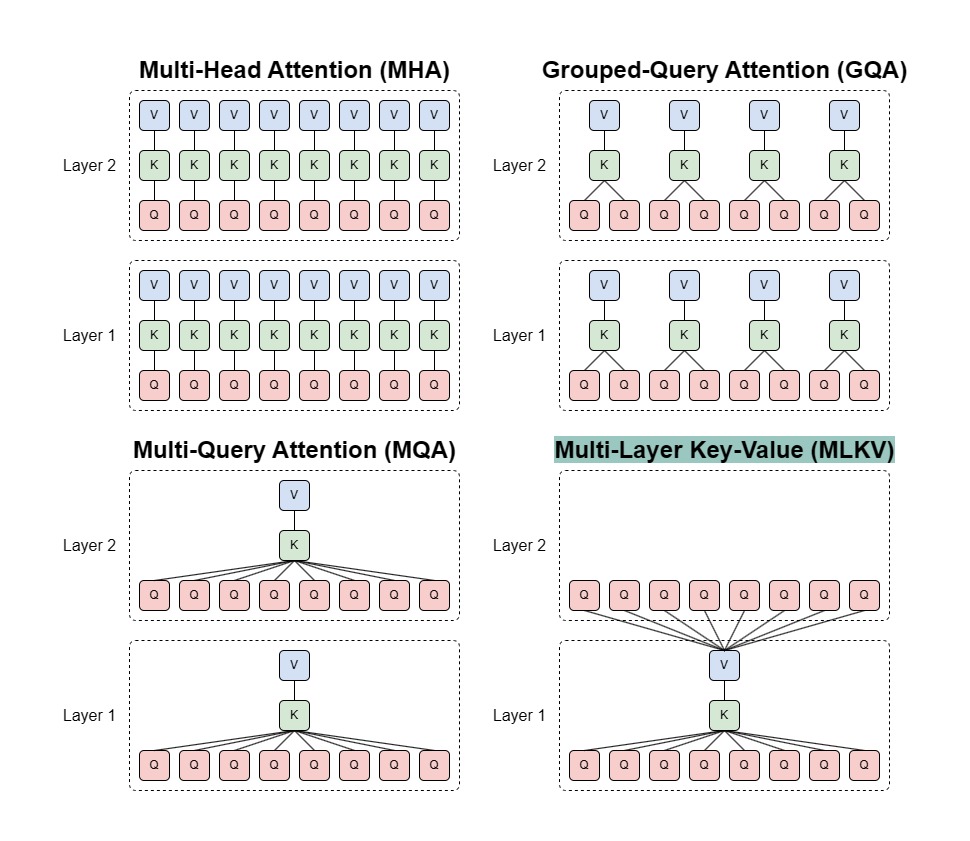
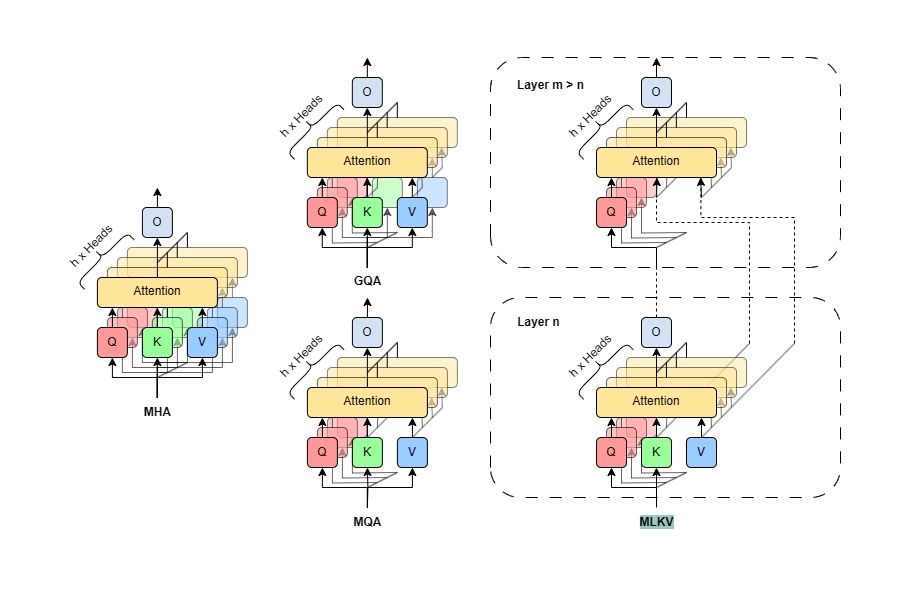
As described by the name, MLKV allows for configurations that share KV heads of lower layers to layers above. While MQA was limited to reducing the KV cache to 1/n_layers the size, here MLKV, at the most extreme, can go down to 1/n_layers the vanilla cache size.
3/18
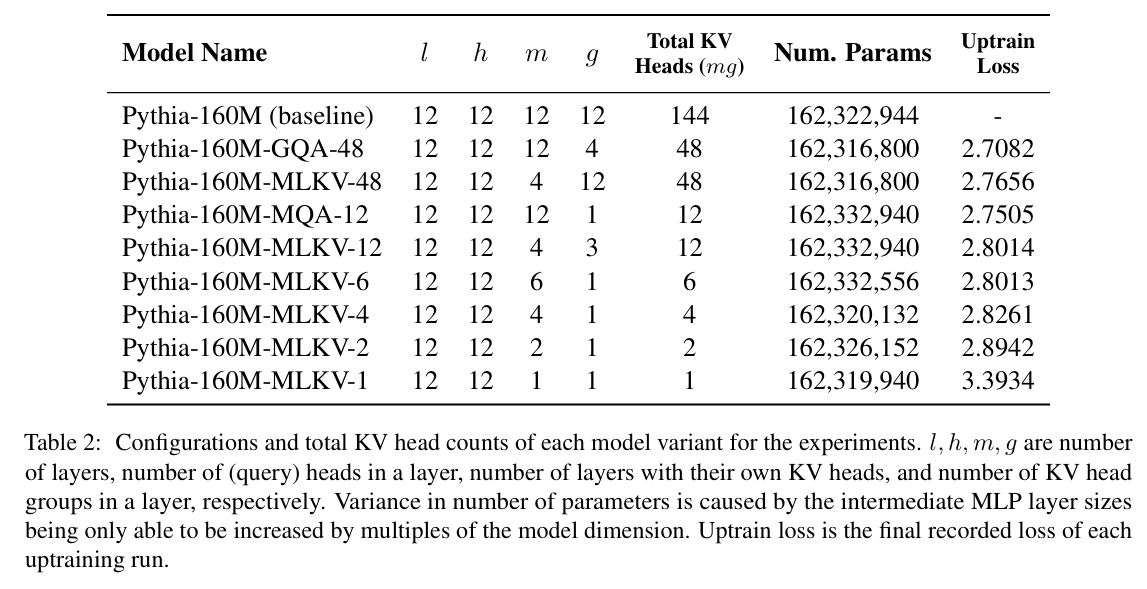
We uptrain 8 variants of Pythia-160M in different configs with different total KV head counts, from GQA/MQA equivalents to MLKV setups that go beyond what was possible. Uptrain loss is reported in Table 2.
4/18
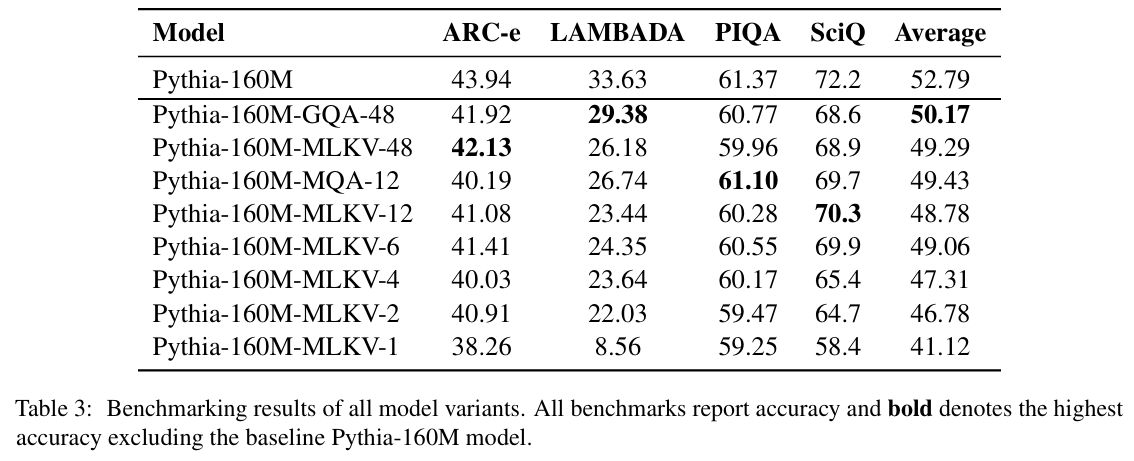
The benchmark results show that there is a price to pay for reducing KV heads, as the avg accuracy goes down slightly. The most extreme config with 1 KV head collapses, but all other variants are very much usable.
5/18
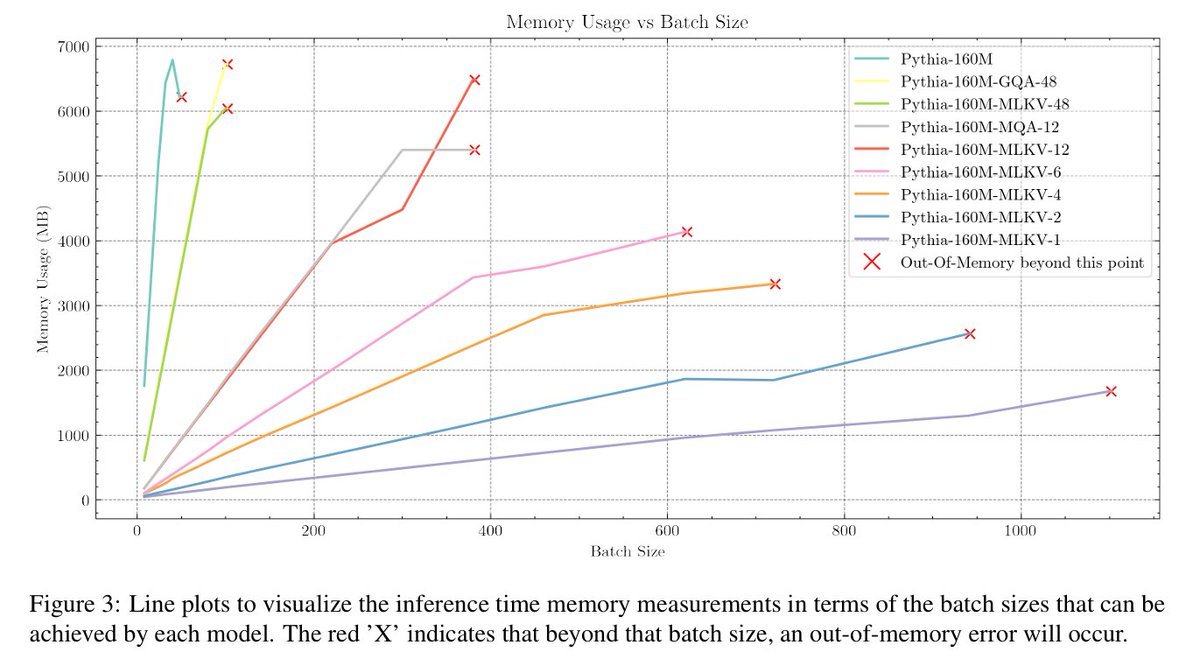
Now to the good part. This plot can be predicted from the theoretical cache sizes, but it is really cool to see it in practice, when inferencing IRL. You can clearly see the benefit in going down with MLKV. IMPORTANT: This plot also applies for longer context lengths!
6/18
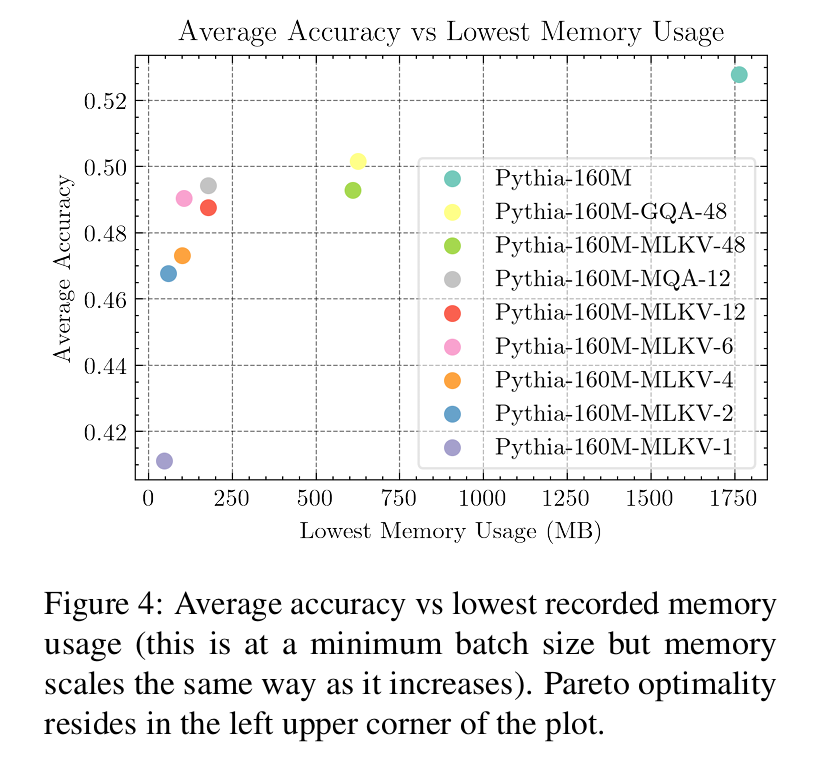
We can plot the accuracy/memory trade-off. We show that configurations with half the KV heads of MQA is right with MQA on the pareto optimal part of the curve. Even going below that is possible if needed.
7/18
Some limitations to curb your enthusiasm for those who have been following since the start:
1. Small scale at 160M params
2. Uptrain instead of train from scratch
Keep in mind this was my "final project" for a bachelors degree. My first priority was to get this degree as safely..
8/18
..and quickly as possible. This scale allowed me to iterate and experiment more in a limited timeframe, which I really needed. I'm certain it is possible to scale MLKV up as was done with GQA. If you are interested in optimizing your model, lmk and I'll help you
9/18
About CLA. This idea is pretty obvious if you know the literature, so it was bound to happen. There are still some differences, e.g. we uptrain models (which is more practical) and see the effects. Also, we tested more extreme configurations too.
10/18
This pre-print is planned to be submitted to EMNLP. I am not 100% confident in getting in (given limitations and CLA) but I do want to give it a shot. But what I really wanted was to get this up on arXiv and share it to you all, which is what I'm doing now.
11/18
Which is super satisfying and I'm happy with the outcome! I thank everyone who has been following and showing interest in this project since the start, nearly a year ago. You guys are cool, thank you!
12/18
Big thanks and credits to co-authors and supervisors @faridlazuarda , @AyuP_AI, and @AlhamFikri
13/18
yep lots of these KV optimizations are stackable. but also beware of the accuracy tradeoff
14/18
thank youu
15/18
thank you! here's to hoping
16/18
Thank you!
Yes you got it exactly right, no free lunch. I've tried and well, the benchmark results are worse ofc
17/18
Yes, they can in fact be used simultaneously! MHLA just compresses any KV cache that is used, so reducing KV cache size will also reduce the compressed representation. It is to be seen how well they work together, or if it is even necessary to do both, but it theoretically works
18/18
There are many in depth explanations out there on the attention mechanism, but I really recommend you trying attention hands-on through something like nanoGPT. I only started to really understand after trying it for myself
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Finally, I present you my first ever preprint:
MLKV: Multi-Layer Key-Value Heads for Memory Efficient Transformer Decoding
We show that sharing KV heads between layers allows for KV cache smaller than GQA/MQA allowed for, with reasonable acc/mem tradeoff
[2406.09297] MLKV: Multi-Layer Key-Value Heads for Memory Efficient Transformer Decoding
2/18
As described by the name, MLKV allows for configurations that share KV heads of lower layers to layers above. While MQA was limited to reducing the KV cache to 1/n_layers the size, here MLKV, at the most extreme, can go down to 1/n_layers the vanilla cache size.
3/18
We uptrain 8 variants of Pythia-160M in different configs with different total KV head counts, from GQA/MQA equivalents to MLKV setups that go beyond what was possible. Uptrain loss is reported in Table 2.
4/18
The benchmark results show that there is a price to pay for reducing KV heads, as the avg accuracy goes down slightly. The most extreme config with 1 KV head collapses, but all other variants are very much usable.
5/18
Now to the good part. This plot can be predicted from the theoretical cache sizes, but it is really cool to see it in practice, when inferencing IRL. You can clearly see the benefit in going down with MLKV. IMPORTANT: This plot also applies for longer context lengths!
6/18
We can plot the accuracy/memory trade-off. We show that configurations with half the KV heads of MQA is right with MQA on the pareto optimal part of the curve. Even going below that is possible if needed.
7/18
Some limitations to curb your enthusiasm for those who have been following since the start:
1. Small scale at 160M params
2. Uptrain instead of train from scratch
Keep in mind this was my "final project" for a bachelors degree. My first priority was to get this degree as safely..
8/18
..and quickly as possible. This scale allowed me to iterate and experiment more in a limited timeframe, which I really needed. I'm certain it is possible to scale MLKV up as was done with GQA. If you are interested in optimizing your model, lmk and I'll help you
9/18
About CLA. This idea is pretty obvious if you know the literature, so it was bound to happen. There are still some differences, e.g. we uptrain models (which is more practical) and see the effects. Also, we tested more extreme configurations too.
10/18
This pre-print is planned to be submitted to EMNLP. I am not 100% confident in getting in (given limitations and CLA) but I do want to give it a shot. But what I really wanted was to get this up on arXiv and share it to you all, which is what I'm doing now.
11/18
Which is super satisfying and I'm happy with the outcome! I thank everyone who has been following and showing interest in this project since the start, nearly a year ago. You guys are cool, thank you!
12/18
Big thanks and credits to co-authors and supervisors @faridlazuarda , @AyuP_AI, and @AlhamFikri
13/18
yep lots of these KV optimizations are stackable. but also beware of the accuracy tradeoff
14/18
thank youu
15/18
thank you! here's to hoping
16/18
Thank you!
Yes you got it exactly right, no free lunch. I've tried and well, the benchmark results are worse ofc
17/18
Yes, they can in fact be used simultaneously! MHLA just compresses any KV cache that is used, so reducing KV cache size will also reduce the compressed representation. It is to be seen how well they work together, or if it is even necessary to do both, but it theoretically works
18/18
There are many in depth explanations out there on the attention mechanism, but I really recommend you trying attention hands-on through something like nanoGPT. I only started to really understand after trying it for myself
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196