1/8
Mixture of Agents—a framework that leverages the collective strengths of multiple LLMs. Each layer contains multiple agents that refine responses using outputs from the preceding layer.
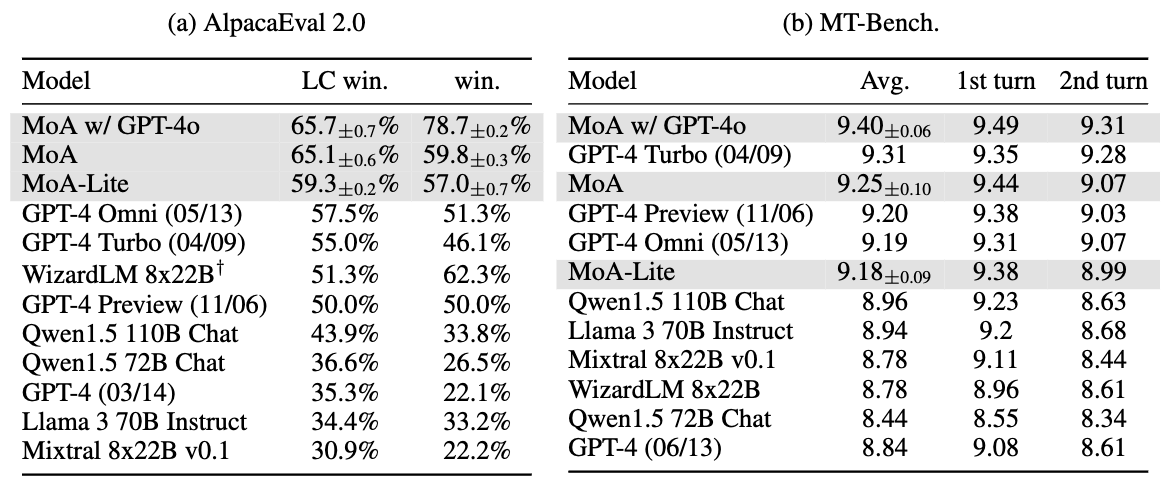
Together MoA achieves a score of 65.1% on AlpacaEval 2.0.
Together MoA — collective intelligence of open-source models pushing the frontier of LLM capabilities
2/8
Together MoA exhibits promising performance on AlpacaEval 2.0 and MT-Bench.
Together MoA uses six open source models as proposers and Qwen1.5-110B-Chat as the final aggregators with three layers.
3/8
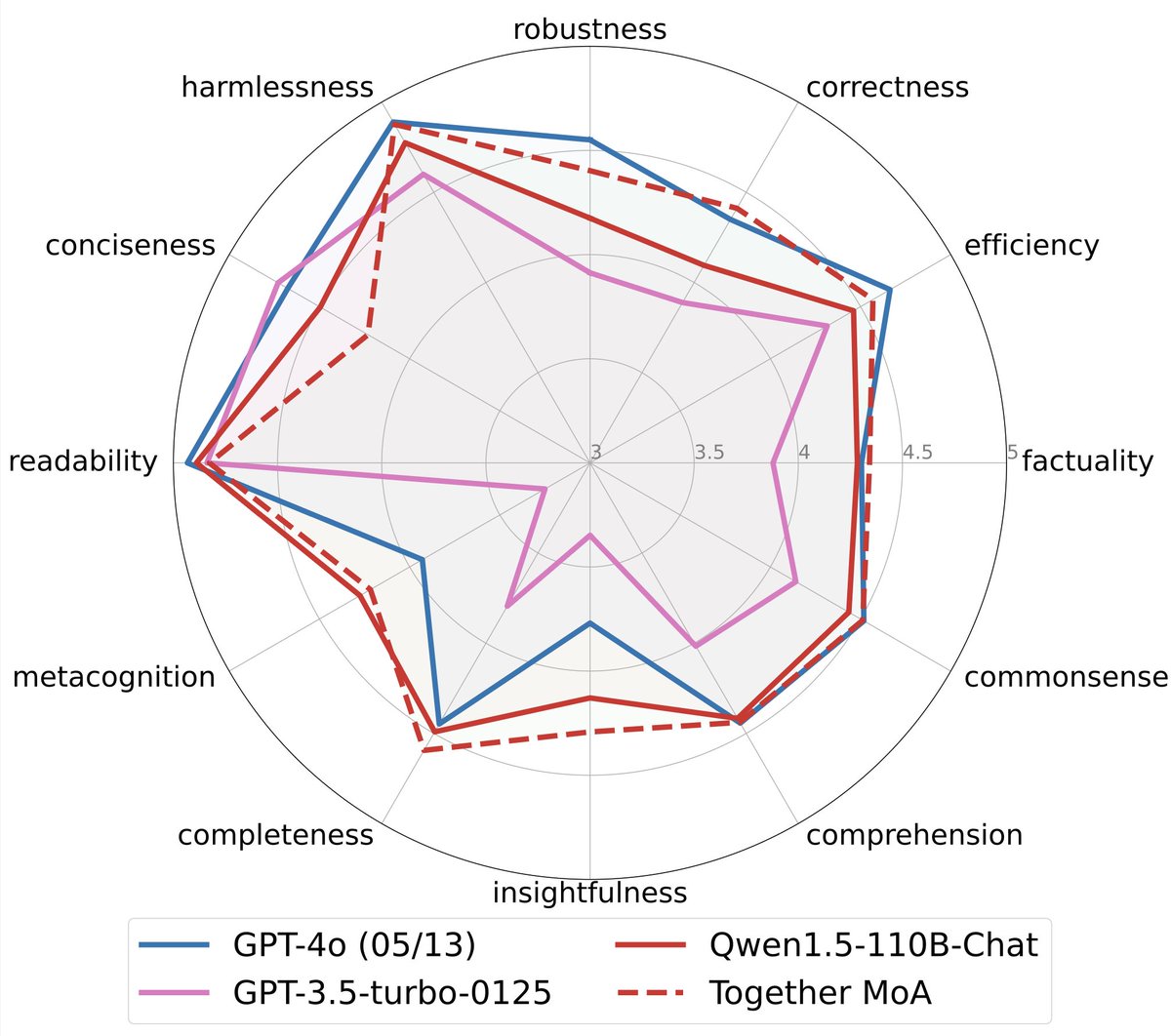
We also evaluate on FLASK which offers more fine-grained evaluation and outperforms original models on most of the dimensions.
4/8
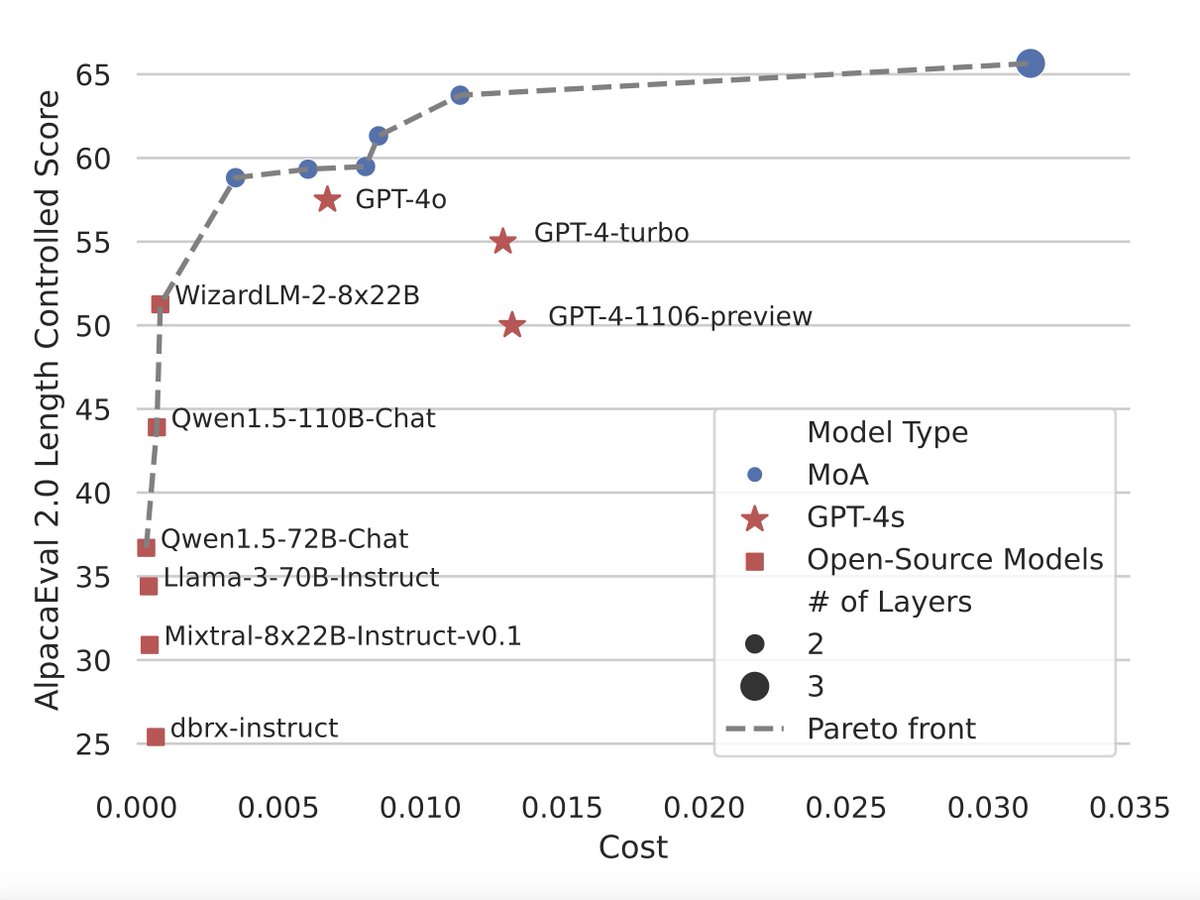
Both Together MoA and Together MoA-Lite are on the Pareto front, indicated by the dashed curve, in the performance vs. cost plot.
5/8
Try Together MoA through our interactive demo. Please note that the TTFT is slow at the moment due to the iterative refinement process of MoA, but we are actively working on optimizations.

 github.com
github.com
6/8
Blog: Together MoA — collective intelligence of open-source models pushing the frontier of LLM capabilities
Paper: [2406.00977] Dragonfly: Multi-Resolution Zoom Supercharges Large Visual-Language Model
Code: GitHub - togethercomputer/MoA
7/8
This work was made possible through the collaborative efforts of several open-source projects. We appreciate @AIatMeta , @MistralAI , @MicrosoftAI , @alibaba_cloud , and @databricks for developing the Llama, Mixtral, WizardLM, Qwen, and DBRX models. We also thank Tatsu Labs,
8/8
Apologies, wrong ArXiv paper linked above. This is the correct one!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Mixture of Agents—a framework that leverages the collective strengths of multiple LLMs. Each layer contains multiple agents that refine responses using outputs from the preceding layer.
Together MoA achieves a score of 65.1% on AlpacaEval 2.0.
Together MoA — collective intelligence of open-source models pushing the frontier of LLM capabilities
2/8
Together MoA exhibits promising performance on AlpacaEval 2.0 and MT-Bench.
Together MoA uses six open source models as proposers and Qwen1.5-110B-Chat as the final aggregators with three layers.
3/8
We also evaluate on FLASK which offers more fine-grained evaluation and outperforms original models on most of the dimensions.
4/8
Both Together MoA and Together MoA-Lite are on the Pareto front, indicated by the dashed curve, in the performance vs. cost plot.
5/8
Try Together MoA through our interactive demo. Please note that the TTFT is slow at the moment due to the iterative refinement process of MoA, but we are actively working on optimizations.
MoA/bot.py at main · togethercomputer/MoA
Together Mixture-Of-Agents (MoA) – 65.1% on AlpacaEval with OSS models - togethercomputer/MoA
github.com
6/8
Blog: Together MoA — collective intelligence of open-source models pushing the frontier of LLM capabilities
Paper: [2406.00977] Dragonfly: Multi-Resolution Zoom Supercharges Large Visual-Language Model
Code: GitHub - togethercomputer/MoA
7/8
This work was made possible through the collaborative efforts of several open-source projects. We appreciate @AIatMeta , @MistralAI , @MicrosoftAI , @alibaba_cloud , and @databricks for developing the Llama, Mixtral, WizardLM, Qwen, and DBRX models. We also thank Tatsu Labs,
8/8
Apologies, wrong ArXiv paper linked above. This is the correct one!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
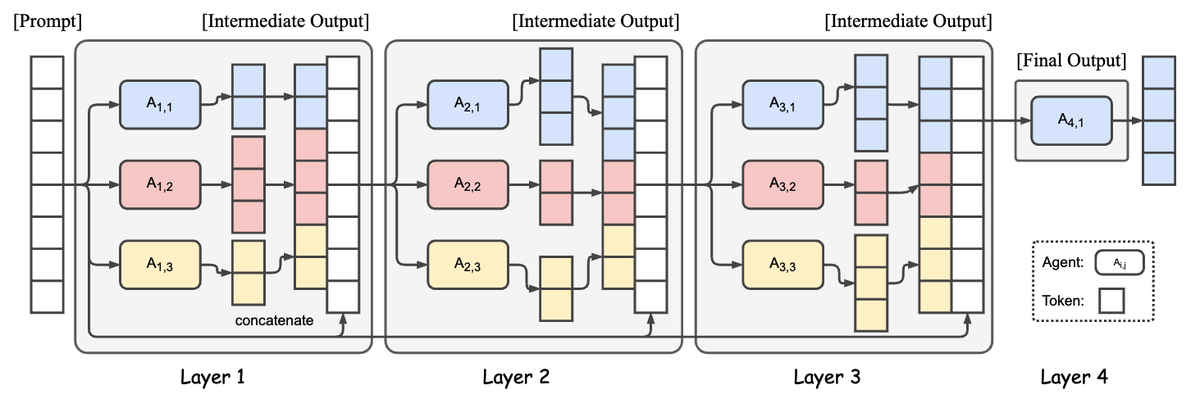


We introduce Mixture of Agents (MoA), an approach to harness the collective strengths of multiple LLMs to improve state-of-the-art quality. And we provide a reference implementation, Together MoA, which leverages several open-source LLM agents to achieve a score of 65.1% on AlpacaEval 2.0, surpassing prior leader GPT-4o (57.5%).

Figure 1: Illustration of the Mixture-of-Agents Structure. This example showcases 4 MoA layers with 3 agents in each layer. The agents here can share the same model.
Overview
We are excited to introduce Mixture of Agents (MoA), a novel approach to harness the collective strengths of multiple LLMs. MoA adopts a layered architecture where each layer comprises several LLM agents. These agents take the outputs from the previous layer as auxiliary information to generate refined responses. This approach allows MoA to effectively integrate diverse capabilities and insights from various models, resulting in a more robust and versatile combined model.Our reference implementation, Together MoA, significantly surpass GPT-4o 57.5% on AlpacaEval 2.0 with a score of 65.1% using only open source models. While Together MoA achieves higher accuracy, it does come at the cost of a slower time to first token; reducing this latency is an exciting future direction for this research.
Our approach is detailed in a technical paper on arXiv; and the open-source code is available at: togethercomputer/moa, including a simple interactive demo. We look forward to seeing how MoA will be utilized to push the boundaries of what AI can achieve.