You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?
OpenAI and Elon Musk
We are dedicated to the OpenAI mission and have pursued it every step of the way.
openai.com
OpenAI and Elon Musk
We are dedicated to the OpenAI mission and have pursued it every step of the way.
March 5, 2024
Authors
Greg Brockman
Ilya Sutskever
John Schulman
Sam Altman
Wojciech Zaremba
OpenAI
Announcements
The mission of OpenAI is to ensure AGI benefits all of humanity, which means both building safe and beneficial AGI and helping create broadly distributed benefits. We are now sharing what we've learned about achieving our mission, and some facts about our relationship with Elon. We intend to move to dismiss all of Elon’s claims.
We realized building AGI will require far more resources than we’d initially imagined
Elon said we should announce an initial $1B funding commitment to OpenAI. In total, the non-profit has raised less than $45M from Elon and more than $90M from other donors.
When starting OpenAI in late 2015, Greg and Sam had initially planned to raise $100M. Elon said in an email: “We need to go with a much bigger number than $100M to avoid sounding hopeless… I think we should say that we are starting with a $1B funding commitment… I will cover whatever anyone else doesn't provide.” [1]
We spent a lot of time trying to envision a plausible path to AGI. In early 2017, we came to the realization that building AGI will require vast quantities of compute. We began calculating how much compute an AGI might plausibly require. We all understood we were going to need a lot more capital to succeed at our mission—billions of dollars per year, which was far more than any of us, especially Elon, thought we’d be able to raise as the non-profit.
We and Elon recognized a for-profit entity would be necessary to acquire those resources
As we discussed a for-profit structure in order to further the mission, Elon wanted us to merge with Tesla or he wanted full control. Elon left OpenAI, saying there needed to be a relevant competitor to Google/DeepMind and that he was going to do it himself. He said he’d be supportive of us finding our own path.
In late 2017, we and Elon decided the next step for the mission was to create a for-profit entity. Elon wanted majority equity, initial board control, and to be CEO. In the middle of these discussions, he withheld funding. Reid Hoffman bridged the gap to cover salaries and operations.
We couldn’t agree to terms on a for-profit with Elon because we felt it was against the mission for any individual to have absolute control over OpenAI. He then suggested instead merging OpenAI into Tesla. In early February 2018, Elon forwarded us an email suggesting that OpenAI should “attach to Tesla as its cash cow”, commenting that it was “exactly right… Tesla is the only path that could even hope to hold a candle to Google. Even then, the probability of being a counterweight to Google is small. It just isn’t zero”. [2]
Elon soon chose to leave OpenAI, saying that our probability of success was 0, and that he planned to build an AGI competitor within Tesla. When he left in late February 2018, he told our team he was supportive of us finding our own path to raising billions of dollars. In December 2018, Elon sent us an email saying “Even raising several hundred million won’t be enough. This needs billions per year immediately or forget it.” [3]
We advance our mission by building widely-available beneficial tools
We’re making our technology broadly usable in ways that empower people and improve their daily lives, including via open-source contributions.
We provide broad access to today's most powerful AI, including a free version that hundreds of millions of people use every day. For example, Albania is using OpenAI’s tools to accelerate its EU accession by as much as 5.5 years; Digital Green is helping boost farmer income in Kenya and India by dropping the cost of agricultural extension services 100x by building on OpenAI; Lifespan, the largest healthcare provider in Rhode Island, uses GPT-4 to simplify its surgical consent forms from a college reading level to a 6th grade one; Iceland is using GPT-4 to preserve the Icelandic language.
Elon understood the mission did not imply open-sourcing AGI. As Ilya told Elon: “As we get closer to building AI, it will make sense to start being less open. The Open in openAI means that everyone should benefit from the fruits of AI after its built, but it's totally OK to not share the science...”, to which Elon replied: “Yup”. [4]
We're sad that it's come to this with someone whom we’ve deeply admired—someone who inspired us to aim higher, then told us we would fail, started a competitor, and then sued us when we started making meaningful progress towards OpenAI’s mission without him.
We are focused on advancing our mission and have a long way to go. As we continue to make our tools better and better, we are excited to deploy these systems so they empower every individual.
[1]
From: [COLOR=hsl(var(--xf-editorFocusColor))]Elon Musk <>[/COLOR]
To: [COLOR=hsl(var(--xf-editorFocusColor))]Greg Brockman <>CC: Sam Altman <>[/COLOR]
Date: Sun, Nov 22, 2015 at 7:48 PM
Subject: follow up from call
Blog sounds good, assuming adjustments for neutrality vs being YC-centric.
I'd favor positioning the blog to appeal a bit more to the general public -- there is a lot of value to having the public root for us to succeed -- and then having a longer, more detailed and inside-baseball version for recruiting, with a link to it at the end of the general public version.
We need to go with a much bigger number than $100M to avoid sounding hopeless relative to what Google or Facebook are spending. I think we should say that we are starting with a $1B funding commitment. This is real. I will cover whatever anyone else doesn't provide.
Template seems fine, apart from shifting to a vesting cash bonus as default, which can optionally be turned into YC or potentially SpaceX (need to understand how much this will be) stock.
[2]
From: [COLOR=hsl(var(--xf-editorFocusColor))]Elon Musk <>[/COLOR]
To: [COLOR=hsl(var(--xf-editorFocusColor))]Ilya Sutskever <>, Greg Brockman <>[/COLOR]
Date: Thu, Feb 1, 2018 at 3:52 AM
Subject: Fwd: Top AI institutions today
is exactly right. We may wish it otherwise, but, in my and
’s opinion, Tesla is the only path that could even hope to hold a candle to Google. Even then, the probability of being a counterweight to Google is small. It just isn't zero.
Begin forwarded message:
From:
To: [COLOR=hsl(var(--xf-editorFocusColor))]Elon Musk [/COLOR]
Date: January 31, 2018 at 11:54:30 PM PST
Subject: Re: Top AI institutions today
Working at the cutting edge of AI is unfortunately expensive. For example,
In addition to DeepMind, Google also has Google Brain, Research, and Cloud. And TensorFlow, TPUs, and they own about a third of all research (in fact, they hold their own AI conferences).
I also strongly suspect that compute horsepower will be necessary (and possibly even sufficient) to reach AGI. If historical trends are any indication, progress in AI is primarily driven by systems - compute, data, infrastructure. The core algorithms we use today have remained largely unchanged from the ~90s. Not only that, but any algorithmic advances published in a paper somewhere can be almost immediately re-implemented and incorporated. Conversely, algorithmic advances alone are inert without the scale to also make them scary.
It seems to me that OpenAI today is burning cash and that the funding model cannot reach the scale to seriously compete with Google (an 800B company). If you can't seriously compete but continue to do research in open, you might in fact be making things worse and helping them out “for free”, because any advances are fairly easy for them to copy and immediately incorporate, at scale.
A for-profit pivot might create a more sustainable revenue stream over time and would, with the current team, likely bring in a lot of investment. However, building out a product from scratch would steal focus from AI research, it would take a long time and it's unclear if a company could “catch up” to Google scale, and the investors might exert too much pressure in the wrong directions.The most promising option I can think of, as I mentioned earlier, would be for OpenAI to attach to Tesla as its cash cow. I believe attachments to other large suspects (e.g. Apple? Amazon?) would fail due to an incompatible company DNA. Using a rocket analogy, Tesla already built the “first stage” of the rocket with the whole supply chain of Model 3 and its onboard computer and a persistent internet connection. The “second stage” would be a full self driving solution based on large-scale neural network training, which OpenAI expertise could significantly help accelerate. With a functioning full self-driving solution in ~2-3 years we could sell a lot of cars/trucks. If we do this really well, the transportation industry is large enough that we could increase Tesla's market cap to high O(~100K), and use that revenue to fund the AI work at the appropriate scale.
I cannot see anything else that has the potential to reach sustainable Google-scale capital within a decade.
1/3
Tuesday in Open Access ML:
- IBM silently dropping Merlinite 7b
- Moondream2 - small VLM for edge
- TripoSR - image-to-3D (StabilityAI +Tripo)
- Microsoft Orca Math dataset
- Mixedbread 2D Matryoshka embeddings
- Based by HazyResearch + Together
2/3
Tuesday in Open Access ML:
- IBM silently dropping Merlinite 7b
- Moondream2 - small VLM for edge
- TripoSR - image-to-3D (StabilityAI +Tripo)
- Microsoft Orca Math dataset
- Mixedbread 2D Matryoshka embeddings
- Based by HazyResearch + Together
3/3
Can someone explain to me what OAI gets from releasing that blog post? It's just so bad
- Arrogant takes: only OAI can train good models?
- Shows it clearly departed the non-profit way years ago
- Pushing against OS due to model capabilities...in 2016...
- They only thought…
Tuesday in Open Access ML:
- IBM silently dropping Merlinite 7b
- Moondream2 - small VLM for edge
- TripoSR - image-to-3D (StabilityAI +Tripo)
- Microsoft Orca Math dataset
- Mixedbread 2D Matryoshka embeddings
- Based by HazyResearch + Together
2/3
Tuesday in Open Access ML:
- IBM silently dropping Merlinite 7b
- Moondream2 - small VLM for edge
- TripoSR - image-to-3D (StabilityAI +Tripo)
- Microsoft Orca Math dataset
- Mixedbread 2D Matryoshka embeddings
- Based by HazyResearch + Together
3/3
Can someone explain to me what OAI gets from releasing that blog post? It's just so bad
- Arrogant takes: only OAI can train good models?
- Shows it clearly departed the non-profit way years ago
- Pushing against OS due to model capabilities...in 2016...
- They only thought…

1/3
Open source LLMs need open training data. Today I release the largest dataset of English public domain books curated from the @internetarchive and the @openlibrary. It consists of more than 61 billion words and 650,000 OCR texts. Stay tuned for more!

2/3
There's no consolidated script yet, because the dataset is partially manually curated and partially automatically harvested (more on my curation method in the README: storytracer/internet_archive_books_en · Datasets at Hugging Face I will write a script for the next language I tackle!
3/3
Mainly size! Gutenberg is an amazing dataset which is included in the training data of most LLMs. But this dataset is 10x the size. Even noisy OCR can be helpful, e.g. to develop OCR correction models. But the data needs to be curated and packaged first and that's all I did.
Open source LLMs need open training data. Today I release the largest dataset of English public domain books curated from the @internetarchive and the @openlibrary. It consists of more than 61 billion words and 650,000 OCR texts. Stay tuned for more!
storytracer/internet_archive_books_en · Datasets at Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
2/3
There's no consolidated script yet, because the dataset is partially manually curated and partially automatically harvested (more on my curation method in the README: storytracer/internet_archive_books_en · Datasets at Hugging Face I will write a script for the next language I tackle!
3/3
Mainly size! Gutenberg is an amazing dataset which is included in the training data of most LLMs. But this dataset is 10x the size. Even noisy OCR can be helpful, e.g. to develop OCR correction models. But the data needs to be curated and packaged first and that's all I did.
1/6
Welcome Yi-9B
> Trained on 3 Trillion tokens.
> Pretty good at Coding, Math and Common sense reasoning.
> Open access weights.
> Bilingual English & Chinese.
2/6
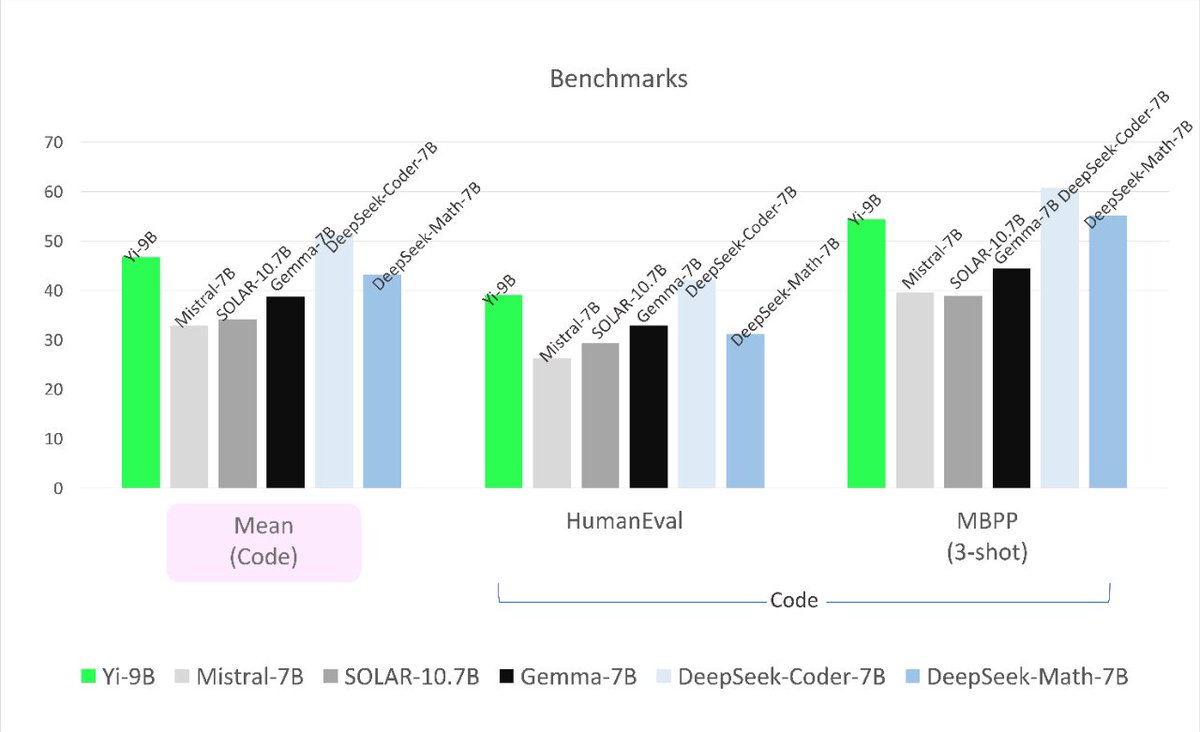
Benchmarks look pretty strong!
4/6
Note: this is a base model so you'd need to fine-tune it for chat specific use-cases
5/6
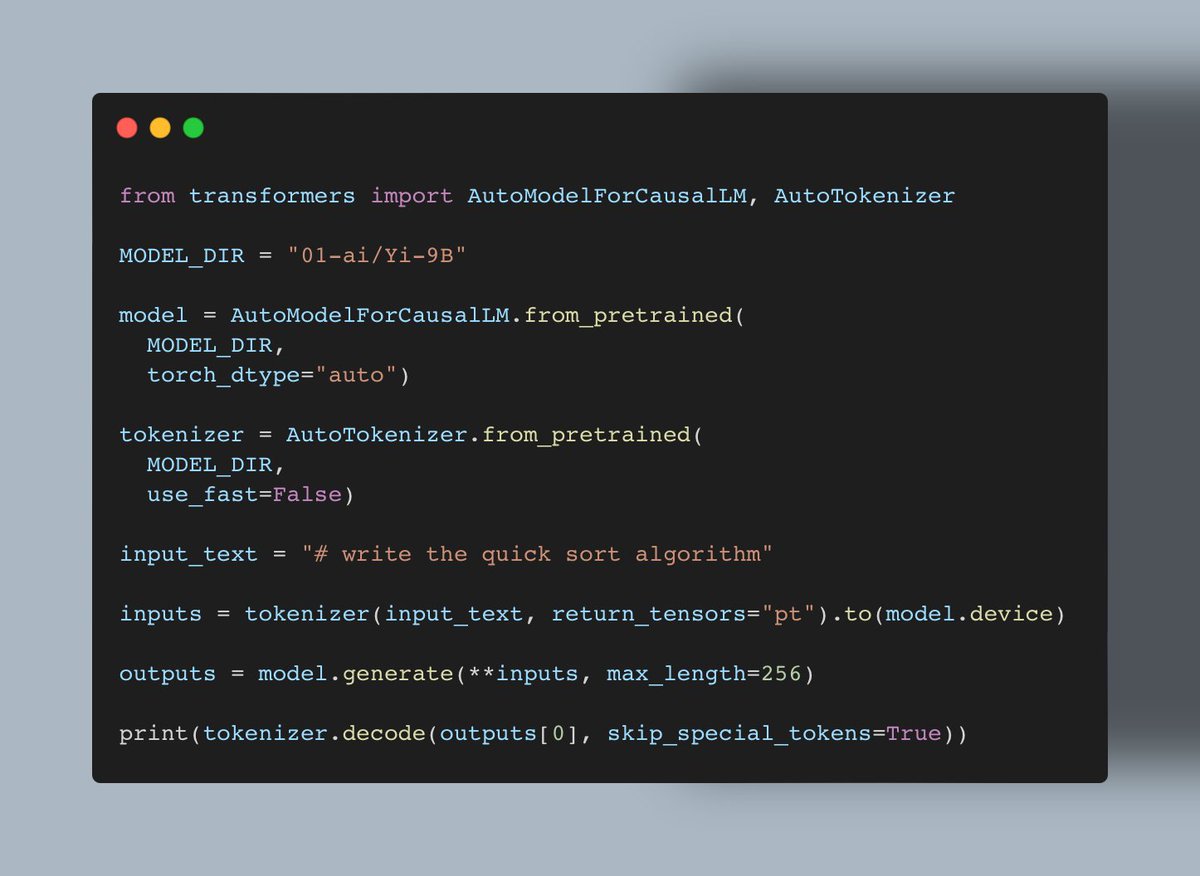
Using it in Transformers is easy, too!
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_DIR = "01-ai/Yi-9B"
model = AutoModelForCausalLM.from_pretrained(MODEL_DIR, torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained(MODEL_DIR, use_fast=False)
input_text = "# write the quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=256)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
6/6
I’ve generally found Chinese LLMs to be way more untouched than typical western ones
Welcome Yi-9B
> Trained on 3 Trillion tokens.
> Pretty good at Coding, Math and Common sense reasoning.
> Open access weights.
> Bilingual English & Chinese.
2/6
Benchmarks look pretty strong!
4/6
Note: this is a base model so you'd need to fine-tune it for chat specific use-cases
5/6
Using it in Transformers is easy, too!
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_DIR = "01-ai/Yi-9B"
model = AutoModelForCausalLM.from_pretrained(MODEL_DIR, torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained(MODEL_DIR, use_fast=False)
input_text = "# write the quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_length=256)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
6/6
I’ve generally found Chinese LLMs to be way more untouched than typical western ones

01-ai/Yi-9B · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
1/5
I benchmarked surya (GitHub - VikParuchuri/surya: OCR and line detection in 90+ languages) against Google Cloud OCR, and it looks competitive. Pretty nice for an open source model I trained myself.
2/5
I have some updates coming soon, including improvements to Chinese/Japanese, improved line detection, better programming code recognition, and math OCR.
3/5
The data for the benchmark is here - https://https://huggingface.co/datasets/vikp/rec_bench - I scraped pdfs from common crawl, and filtered out anything that wasn't digital-native (trying to get a real GT). I had to supplement some languages with synthetic data.
4/5
Notes:
- I couldn't align the RTL output from google cloud with the ground truth well, so RTL languages were not benchmarked.
- The benchmark data is mostly high-quality printed pdfs.
- Surya wasn't trained on handwriting (Google cloud can OCR handwriting well).
5/5
Check out the repo - GitHub - VikParuchuri/surya: OCR and line detection in 90+ languages - and the discord - Join the Data Lab Discord Server! - if you want to try surya.
I benchmarked surya (GitHub - VikParuchuri/surya: OCR and line detection in 90+ languages) against Google Cloud OCR, and it looks competitive. Pretty nice for an open source model I trained myself.
2/5
I have some updates coming soon, including improvements to Chinese/Japanese, improved line detection, better programming code recognition, and math OCR.
3/5
The data for the benchmark is here - https://https://huggingface.co/datasets/vikp/rec_bench - I scraped pdfs from common crawl, and filtered out anything that wasn't digital-native (trying to get a real GT). I had to supplement some languages with synthetic data.
4/5
Notes:
- I couldn't align the RTL output from google cloud with the ground truth well, so RTL languages were not benchmarked.
- The benchmark data is mostly high-quality printed pdfs.
- Surya wasn't trained on handwriting (Google cloud can OCR handwriting well).
5/5
Check out the repo - GitHub - VikParuchuri/surya: OCR and line detection in 90+ languages - and the discord - Join the Data Lab Discord Server! - if you want to try surya.



1/2
New short course: Open Source Models with Hugging Face New short course: Open Source Models with Hugging Face , taught by , taught by @mariaKhalusova@mariaKhalusova, , @_marcsun@_marcsun, and Younes Belkada! , and Younes Belkada! @huggingface@huggingface has been a game changer by letting you quickly grab any of hundreds of thousands of already-trained open source models to assemble into new applications. This course teaches you best practices for building this way, including how to search and choose among models.
You’ll learn to use the Transformers library and walk through multiple models for text, audio, and image processing, including zero-shot image segmentation, zero-shot audio classification, and speech recognition. You'll also learn to use multimodal models for visual question answering, image search, and image captioning. Finally, you’ll learn how to demo what you build locally, on the cloud, or via an API using Gradio and Hugging Face Spaces.
You can sign up here: Open Source Models with Hugging Face
New short course: Open Source Models with Hugging Face New short course: Open Source Models with Hugging Face , taught by , taught by @mariaKhalusova@mariaKhalusova, , @_marcsun@_marcsun, and Younes Belkada! , and Younes Belkada! @huggingface@huggingface has been a game changer by letting you quickly grab any of hundreds of thousands of already-trained open source models to assemble into new applications. This course teaches you best practices for building this way, including how to search and choose among models.
You’ll learn to use the Transformers library and walk through multiple models for text, audio, and image processing, including zero-shot image segmentation, zero-shot audio classification, and speech recognition. You'll also learn to use multimodal models for visual question answering, image search, and image captioning. Finally, you’ll learn how to demo what you build locally, on the cloud, or via an API using Gradio and Hugging Face Spaces.
You can sign up here: Open Source Models with Hugging Face

Open Source Models with Hugging Face
Build AI apps with open source models and Hugging Face tools. Filter models based on task, rankings, and memory. Share apps easily.
What you’ll learn in this course
The availability of models and their weights for anyone to download enables a broader range of developers to innovate and create.
In this course, you’ll select open source models from Hugging Face Hub to perform NLP, audio, image and multimodal tasks using the Hugging Face transformers library. Easily package your code into a user-friendly app that you can run on the cloud using Gradio and Hugging Face Spaces.
You will:
Use the transformers library to turn a small language model into a chatbot capable of multi-turn conversations to answer follow-up questions.
Translate between languages, summarize documents, and measure the similarity between two pieces of text, which can be used for search and retrieval.
Convert audio to text with Automatic Speech Recognition (ASR), and convert text to audio using Text to Speech (TTS).
Perform zero-shot audio classification, to classify audio without fine-tuning the model.
Generate an audio narration describing an image by combining object detection and text-to-speech models.
Identify objects or regions in an image by prompting a zero-shot image segmentation model with points to identify the object that you want to select.
Implement visual question answering, image search, image captioning and other multimodal tasks.
Share your AI app using Gradio and Hugging Face Spaces to run your applications in a user-friendly interface on the cloud or as an API.
The course will provide you with the building blocks that you can combine into a pipeline to build your AI-enabled applications!

1/7
My recap of AI research last month: A Potential LoRA Successor, Small Finetuned LLMs Vs Generalist LLMs, and Transparent LLM Research, Research Papers in February 2024: A LoRA Successor, Small Finetuned LLMs Vs Generalist LLMs, and Transparent LLM research
Once again, this has been an exciting month in AI research. This month, I’m covering two new openly available LLMs, insights into small finetuned LLMs, and a new parameter-efficient LLM finetuning technique.
The two LLMs mentioned above stand out for several reasons. One LLM (OLMo) is completely open source, meaning that everything from the training code to the dataset to the log files is openly shared.
The other LLM (Gemma) also comes with openly available weights but achieves state-of-the-art performance on several benchmarks and outperforms popular LLMs of similar size, such as Llama 2 7B and Mistral 7B, by a large margin.
2/7
Thanks! This probably took me a solid day ... that was the long presidents' day weekend if I recall correctly .
Regarding the latex, that's a weird Substack thing with equations. It usually goes away when refreshing the page.
4/7
I wish I had good advice and some useful tips ... but the truth is that I am just super interesting in the topic and get up very very early every day, haha
5/7
Thanks so much!
6/7
There are usually two sets of benchmarks, Q&A benchmarks (e.g., like the ones used on the HF leaderboard) and conversational benchmarks (e.g., MT-Bench and AlpacaEval)
7/7
Glad to hear. I also write them for future self -- I often search my arxiv archive when trying to find a paper (again). Nice that others find it useful as well!
My recap of AI research last month: A Potential LoRA Successor, Small Finetuned LLMs Vs Generalist LLMs, and Transparent LLM Research, Research Papers in February 2024: A LoRA Successor, Small Finetuned LLMs Vs Generalist LLMs, and Transparent LLM research
Once again, this has been an exciting month in AI research. This month, I’m covering two new openly available LLMs, insights into small finetuned LLMs, and a new parameter-efficient LLM finetuning technique.
The two LLMs mentioned above stand out for several reasons. One LLM (OLMo) is completely open source, meaning that everything from the training code to the dataset to the log files is openly shared.
The other LLM (Gemma) also comes with openly available weights but achieves state-of-the-art performance on several benchmarks and outperforms popular LLMs of similar size, such as Llama 2 7B and Mistral 7B, by a large margin.
2/7
Thanks! This probably took me a solid day ... that was the long presidents' day weekend if I recall correctly .
Regarding the latex, that's a weird Substack thing with equations. It usually goes away when refreshing the page.
4/7
I wish I had good advice and some useful tips ... but the truth is that I am just super interesting in the topic and get up very very early every day, haha
5/7
Thanks so much!
6/7
There are usually two sets of benchmarks, Q&A benchmarks (e.g., like the ones used on the HF leaderboard) and conversational benchmarks (e.g., MT-Bench and AlpacaEval)
7/7
Glad to hear. I also write them for future self -- I often search my arxiv archive when trying to find a paper (again). Nice that others find it useful as well!

1/3
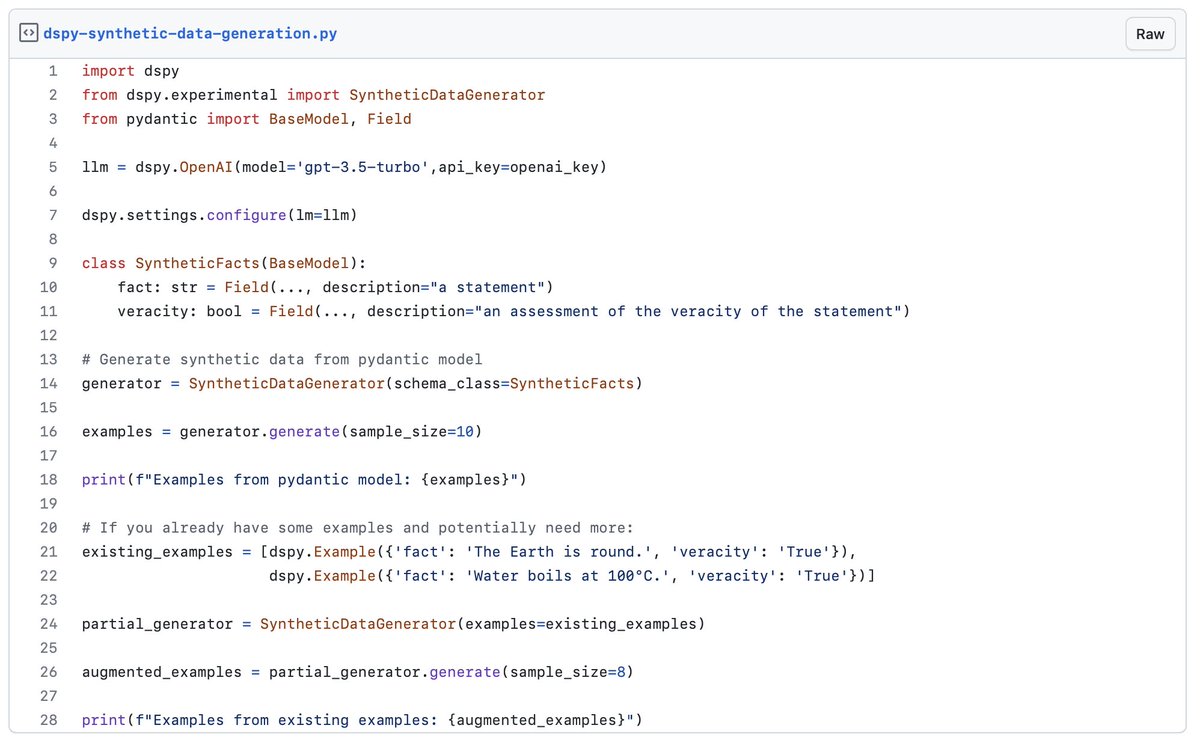
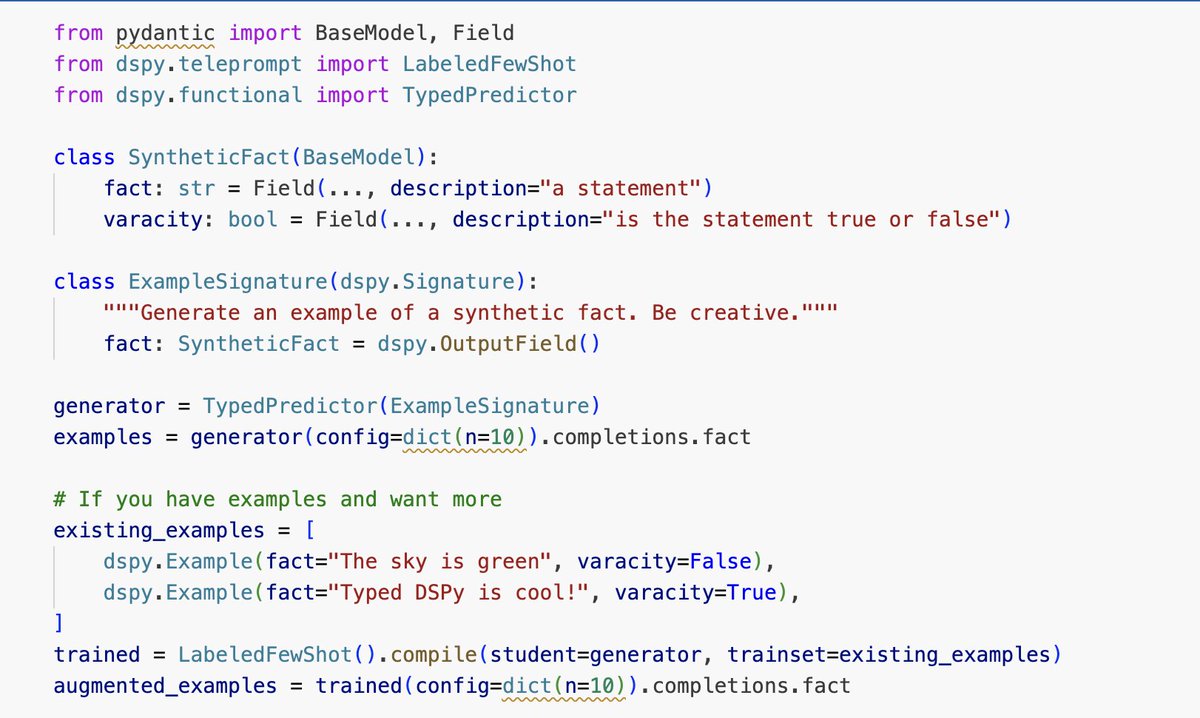
My contribution has been accepted and synthetic data generation has been added to DSPy.
You can either generate data by defining a pydantic model or by feeding some initial examples. And it is blazingly fast !
Here is how to use it:
2/3
Interesting ideas to explore
3/3
Great
My contribution has been accepted and synthetic data generation has been added to DSPy.
You can either generate data by defining a pydantic model or by feeding some initial examples. And it is blazingly fast !
Here is how to use it:
2/3
Interesting ideas to explore
3/3
Great

1/5
Sunday morning read: The Shift from Models to Compound AI Systems from the Berkeley AI Research blog
A compound AI system is a system that contains multiple interacting components, such as calls to models, retrievers, or external tools.
Why state-of-the-art results come from compound systems:
1. System design: Building a compound system that calls the model multiple times can increase the performance more than scaling an individual LLM.
2. Dynamic systems: Add a component for search and retrieval to keep data fresh.
3. Quality control: Controlling the model’s behavior with systems is easier. It is inevitable that the LLM will hallucinate, but combining the LLM with retrieval and asking for citations can increase trust (STORM by Stanford researchers is a great example of this).
4. Performance goals: Performance and cost requirements differ by application. It is cheaper to have specialized models!
The blog also goes into detail about developing compound AI systems, the key challenges, and emerging paradigms!
Blog: The Shift from Models to Compound AI Systems
2/5
Here is a demo on building a 4-layer DSPy program using @weaviate_io as the retriever: recipes/integrations/dspy/2.Writing-Blog-Posts-with-DSPy.ipynb at main · weaviate/recipes generate blog posts from questions with these four components:
1. Question to outline
2. Topic to paragraph
3. Review the blog
4. Generate a title
3/5
Don’t hate the player, hate the game Taking inspo from the best @CShorten30!
4/5
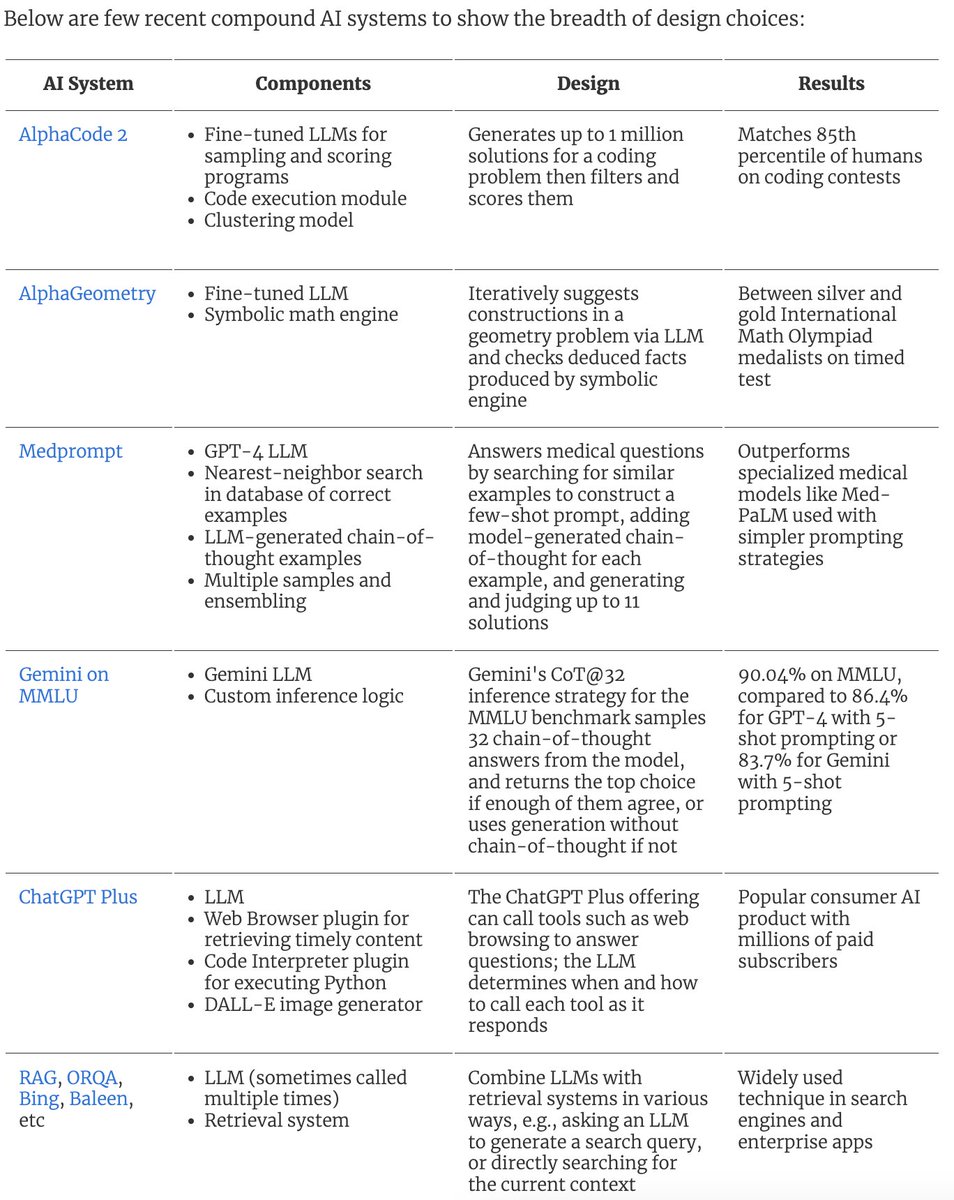
Thanks, Connor! It's a great read and loved the table showing how recent systems fit into this design
5/5
You got it
Sunday morning read: The Shift from Models to Compound AI Systems from the Berkeley AI Research blog
A compound AI system is a system that contains multiple interacting components, such as calls to models, retrievers, or external tools.
Why state-of-the-art results come from compound systems:
1. System design: Building a compound system that calls the model multiple times can increase the performance more than scaling an individual LLM.
2. Dynamic systems: Add a component for search and retrieval to keep data fresh.
3. Quality control: Controlling the model’s behavior with systems is easier. It is inevitable that the LLM will hallucinate, but combining the LLM with retrieval and asking for citations can increase trust (STORM by Stanford researchers is a great example of this).
4. Performance goals: Performance and cost requirements differ by application. It is cheaper to have specialized models!
The blog also goes into detail about developing compound AI systems, the key challenges, and emerging paradigms!
Blog: The Shift from Models to Compound AI Systems
2/5
Here is a demo on building a 4-layer DSPy program using @weaviate_io as the retriever: recipes/integrations/dspy/2.Writing-Blog-Posts-with-DSPy.ipynb at main · weaviate/recipes generate blog posts from questions with these four components:
1. Question to outline
2. Topic to paragraph
3. Review the blog
4. Generate a title
3/5
Don’t hate the player, hate the game Taking inspo from the best @CShorten30!
4/5
Thanks, Connor! It's a great read and loved the table showing how recent systems fit into this design
5/5
You got it

1/3
Adding Personas to RAG and LLM systems is one of these ideas that have fascinated me for a while, but I've never quite gotten around to it!
I am SUPER excited to present this demo with @ecardenas300 illustrating how to add a Persona to a chatbot! For example imagine prompting LLMs to chat with diverse and expert viewpoints such as, "You are Nils Reimers" or "You are Fei-Fei Li"!!
I hope you find this demo exciting, further showing how to build with DSPy programs behind FastAPI backends that connect to React frontends, and ... ... Generative Feedback Loops with Weaviate! Saving and indexing these conversations back into the database!
I hope you will consider checking out the open-source repo and running it for yourself, more than happy to help debug / fix any issues if they arise!
2/3
RAG with Persona RAG with Persona
If you ask the same question to multiple people, there is a strong chance each person will have a different response. Here’s a new demo on RAG with Persona using DSPy, @cohere@cohere@cohere, and , and @weaviate_io@weaviate_io@weaviate_io!
When building or using chatbots, it’s important to get a…!
3/3
Haha I can finally chat with LeBron
Adding Personas to RAG and LLM systems is one of these ideas that have fascinated me for a while, but I've never quite gotten around to it!
I am SUPER excited to present this demo with @ecardenas300 illustrating how to add a Persona to a chatbot! For example imagine prompting LLMs to chat with diverse and expert viewpoints such as, "You are Nils Reimers" or "You are Fei-Fei Li"!!
I hope you find this demo exciting, further showing how to build with DSPy programs behind FastAPI backends that connect to React frontends, and ... ... Generative Feedback Loops with Weaviate! Saving and indexing these conversations back into the database!
I hope you will consider checking out the open-source repo and running it for yourself, more than happy to help debug / fix any issues if they arise!
2/3
RAG with Persona RAG with Persona
If you ask the same question to multiple people, there is a strong chance each person will have a different response. Here’s a new demo on RAG with Persona using DSPy, @cohere@cohere@cohere, and , and @weaviate_io@weaviate_io@weaviate_io!
When building or using chatbots, it’s important to get a…!
3/3
Haha I can finally chat with LeBron
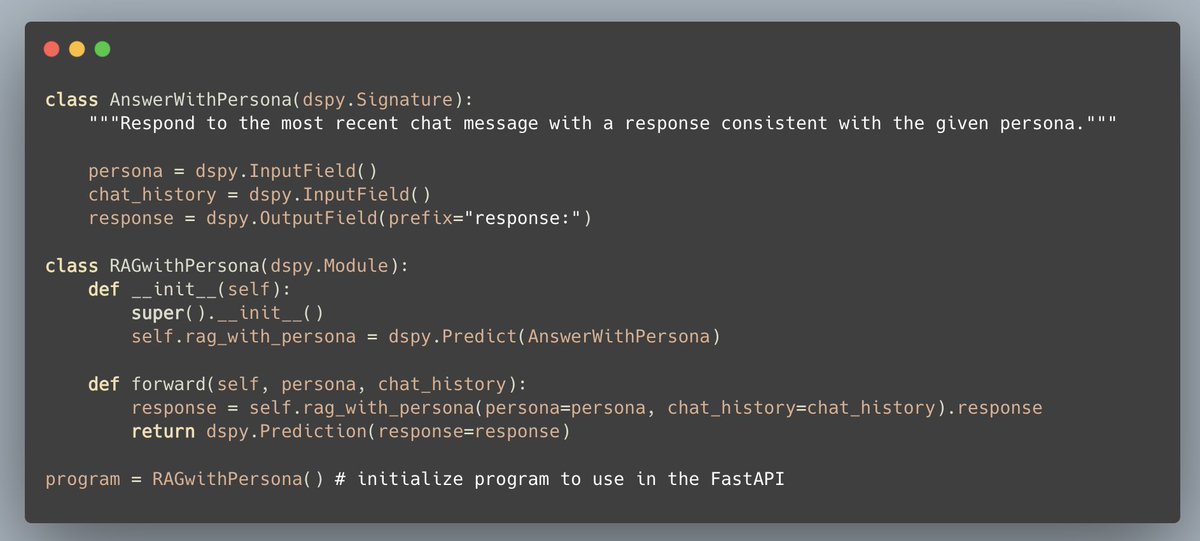
1/5
RAG with Persona RAG with Persona
If you ask the same question to multiple people, there is a strong chance each person will have a different response. Here’s a new demo on RAG with Persona using DSPy, @cohere@cohere, and , and @weaviate_io@weaviate_io!
When building or using chatbots, it’s important to get a response from the right “person”. To do this, let’s build a compound AI system with the following stack:
1. DSPy: Build a framework for the chatbot
2. Cohere: Use the `command-nightly` LLM model
3. Weaviate: Store the responses back in the vector database
More details in the thread!!
2/5
We will first build the `AnswerWithPersona`. The input to the language model is: 1. Peronsa, and 2. Chat history. The output is the response.
We'll then initialize and build the program.
3/5
Connor (@CShorten30) did an awesome job by extending this notebook to interface the DSPy program with a FastAPI endpoint!
4/5
Now we can store our chat history in our vector database for future retrieval -- Generative Feedback Loops
5/5
Here is the demo
recipes/integrations/dspy/4.RAGwithPersona at main · weaviate/recipes
7/8
You got this, Clint. Each demo builds off of the other (kind of), I hope that helps!
8/8
I think your guest should add you as a persona to anticipate your questions
RAG with Persona RAG with Persona
If you ask the same question to multiple people, there is a strong chance each person will have a different response. Here’s a new demo on RAG with Persona using DSPy, @cohere@cohere, and , and @weaviate_io@weaviate_io!
When building or using chatbots, it’s important to get a response from the right “person”. To do this, let’s build a compound AI system with the following stack:
1. DSPy: Build a framework for the chatbot
2. Cohere: Use the `command-nightly` LLM model
3. Weaviate: Store the responses back in the vector database
More details in the thread!!
2/5
We will first build the `AnswerWithPersona`. The input to the language model is: 1. Peronsa, and 2. Chat history. The output is the response.
We'll then initialize and build the program.
3/5
Connor (@CShorten30) did an awesome job by extending this notebook to interface the DSPy program with a FastAPI endpoint!
4/5
Now we can store our chat history in our vector database for future retrieval -- Generative Feedback Loops
5/5
Here is the demo
recipes/integrations/dspy/4.RAGwithPersona at main · weaviate/recipes
7/8
You got this, Clint. Each demo builds off of the other (kind of), I hope that helps!
8/8
I think your guest should add you as a persona to anticipate your questions
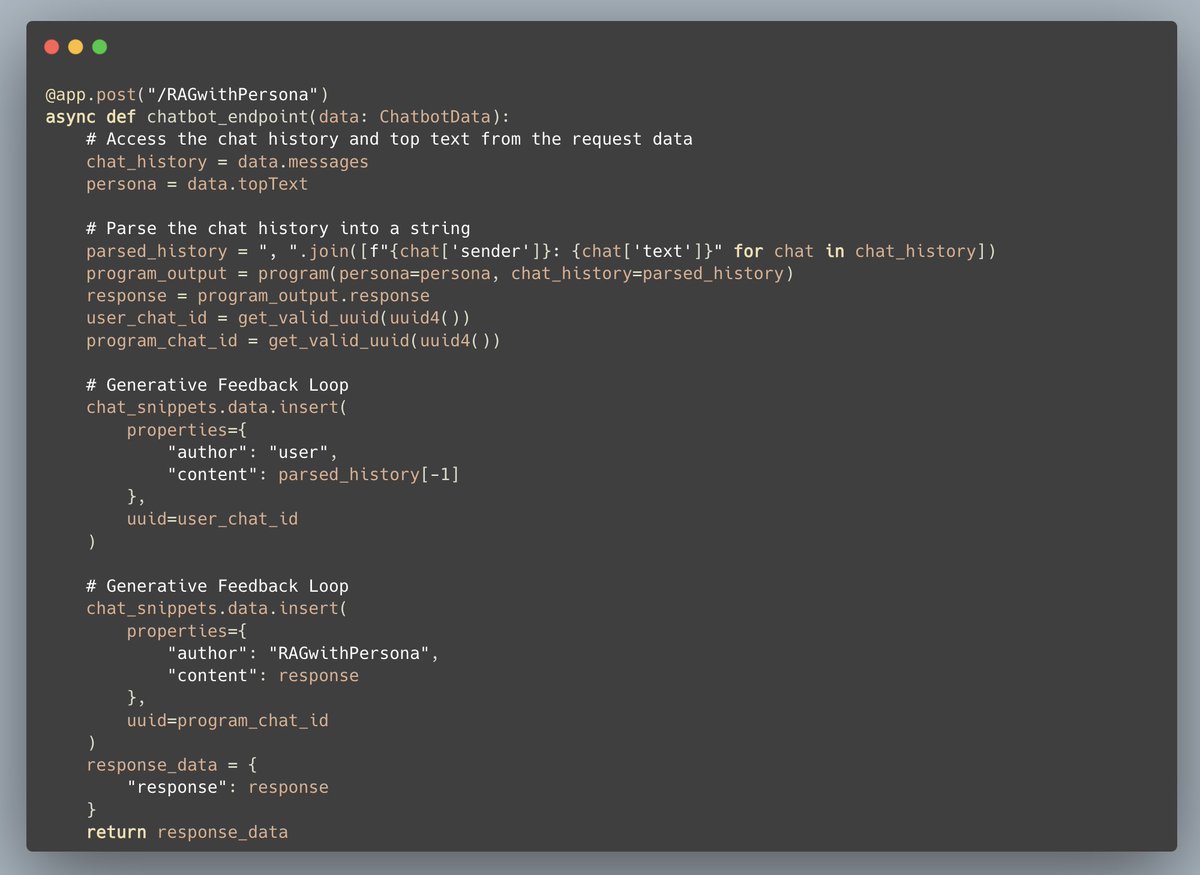
1/2
What are some good resources on LM evals for downstream tasks (classification, summarization, translation)? Some I found:
• HELM: [2211.09110] Holistic Evaluation of Language Models
• NLG Systems: [2008.12009] A Survey of Evaluation Metrics Used for NLG Systems
• LLMs Evals: [2307.03109] A Survey on Evaluation of Large Language Models
• SummEval: [2007.12626] SummEval: Re-evaluating Summarization Evaluation
• Benching LLMs for summarization: [2301.13848] Benchmarking Large Language Models for News Summarization
• MachineTranslate: Metrics
• Evaluating ChatGPT extraction: [2304.11633] Evaluating ChatGPT's Information Extraction Capabilities: An Assessment of Performance, Explainability, Calibration, and Faithfulness
• LLMs for Evals: [2401.07103] Leveraging Large Language Models for NLG Evaluation: A Survey
Especially interested in classification, extraction, summarization, translation, copyright regurgitation, toxicity, etc.
Anything else? Please share!
What are some good resources on LM evals for downstream tasks (classification, summarization, translation)? Some I found:
• HELM: [2211.09110] Holistic Evaluation of Language Models
• NLG Systems: [2008.12009] A Survey of Evaluation Metrics Used for NLG Systems
• LLMs Evals: [2307.03109] A Survey on Evaluation of Large Language Models
• SummEval: [2007.12626] SummEval: Re-evaluating Summarization Evaluation
• Benching LLMs for summarization: [2301.13848] Benchmarking Large Language Models for News Summarization
• MachineTranslate: Metrics
• Evaluating ChatGPT extraction: [2304.11633] Evaluating ChatGPT's Information Extraction Capabilities: An Assessment of Performance, Explainability, Calibration, and Faithfulness
• LLMs for Evals: [2401.07103] Leveraging Large Language Models for NLG Evaluation: A Survey
Especially interested in classification, extraction, summarization, translation, copyright regurgitation, toxicity, etc.
Anything else? Please share!

1/6
Scaling up dataset size appears to be a straightforward yet somewhat "brute force" way for improving instruction-following. How can we "smartly" scale the instruction-tuning dataset?
We are excited to introduce 𝙈𝙐𝙁𝙁𝙄𝙉 (𝙈𝙪lti-𝙁aceted 𝙄𝙣structions), an innovative instruction-tuning dataset designed to 𝙨𝙘𝙖𝙡𝙚 𝙩𝙖𝙨𝙠 𝙞𝙣𝙨𝙩𝙧𝙪𝙘𝙩𝙞𝙤𝙣𝙨 𝙥𝙚𝙧 𝙞𝙣𝙥𝙪𝙩.
 Paper: [2312.02436] MUFFIN: Curating Multi-Faceted Instructions for Improving Instruction-Following
Paper: [2312.02436] MUFFIN: Curating Multi-Faceted Instructions for Improving Instruction-Following
 Dataset: Reza8848/MUFFIN_68k · Datasets at Hugging Face
Dataset: Reza8848/MUFFIN_68k · Datasets at Hugging Face
 Model: GitHub - RenzeLou/Muffin: MUFFIN: Curating Multi-Faceted Instructions for Improving Instruction-Following
Model: GitHub - RenzeLou/Muffin: MUFFIN: Curating Multi-Faceted Instructions for Improving Instruction-Following
 Website: Muffin (Multi-faceted Instructions)
Website: Muffin (Multi-faceted Instructions)
(1/n)
2/6
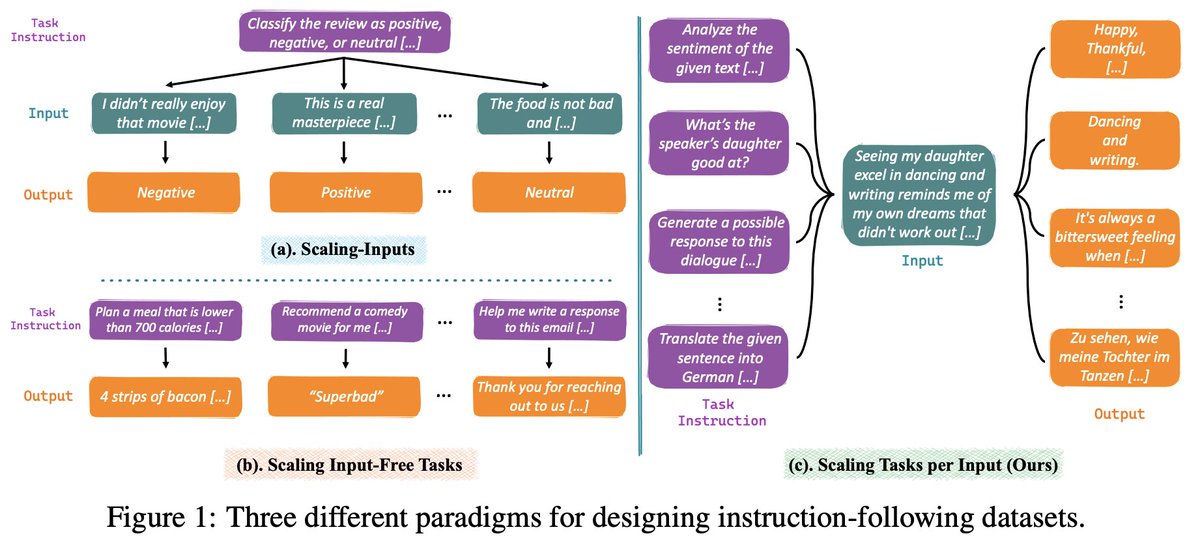
The existing data curation paradigm for instruction tuning can broadly be categorized into two streams:
𝑺𝒄𝒂𝒍𝒊𝒏𝒈 𝑰𝒏𝒑𝒖𝒕𝒔: one instruction + multiple inputs.
Amplifying (input, output) pairs per task instruction (e.g., SuperNI).
It's essentially a multi-task…
3/6
We propose a novel instruction paradigm:
𝑺𝒄𝒂𝒍𝒆 𝑻𝒂𝒔𝒌𝒔 𝒑𝒆𝒓 𝑰𝒏𝒑𝒖𝒕: one input + multiple instructions.
Ideally, one input context can be used for diverse task purposes. For example, given a paragraph as the context, we can use it for QA, summarization, etc.…
4/6
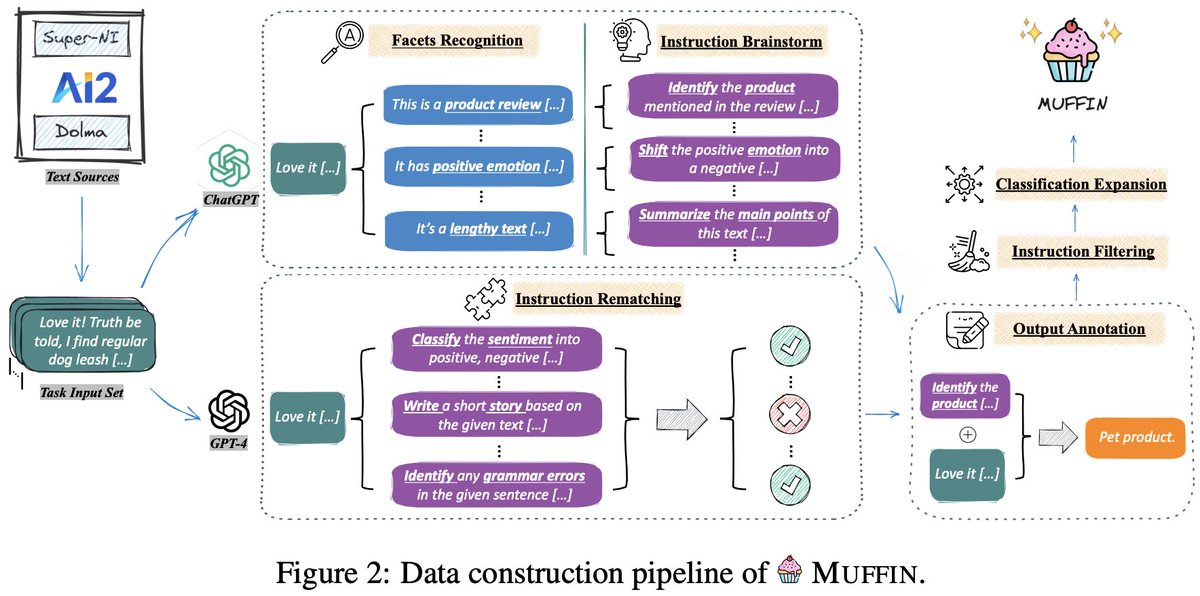
To collect an instruction-tuning dataset with 𝑺𝒄𝒂𝒍𝒆 𝑻𝒂𝒔𝒌𝒔 𝒑𝒆𝒓 𝑰𝒏𝒑𝒖𝒕 paradigm, we develop a simple yet effective framework with two instruction-crafting methods:
𝑰𝒏𝒔𝒕𝒓𝒖𝒄𝒕𝒊𝒐𝒏 𝑩𝒓𝒂𝒊𝒏𝒔𝒕𝒐𝒓𝒎. Adopting two-step prompting. For each input context,…
5/6
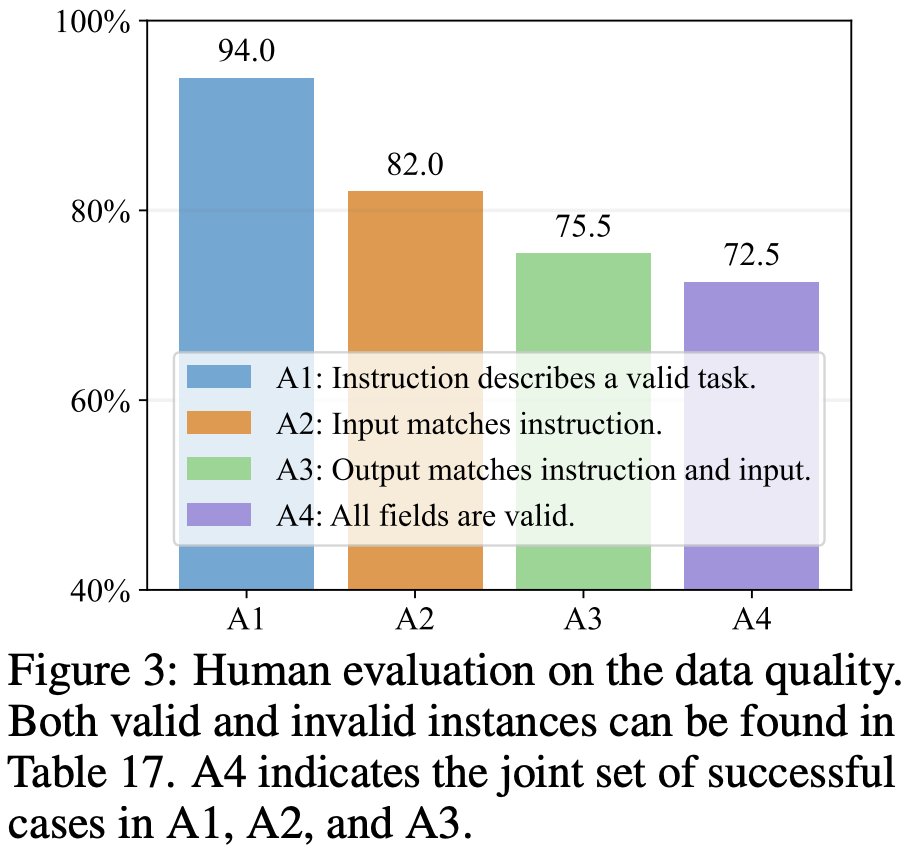
Our final dataset --- 𝙈𝙐𝙁𝙁𝙄𝙉 (Multi-Faceted Instructions) --- has a 68k instances scale ("one instance" means "one instruction-input-output pair"), with high data quality and diversity according to our human evaluation.
(5/n)
6/6
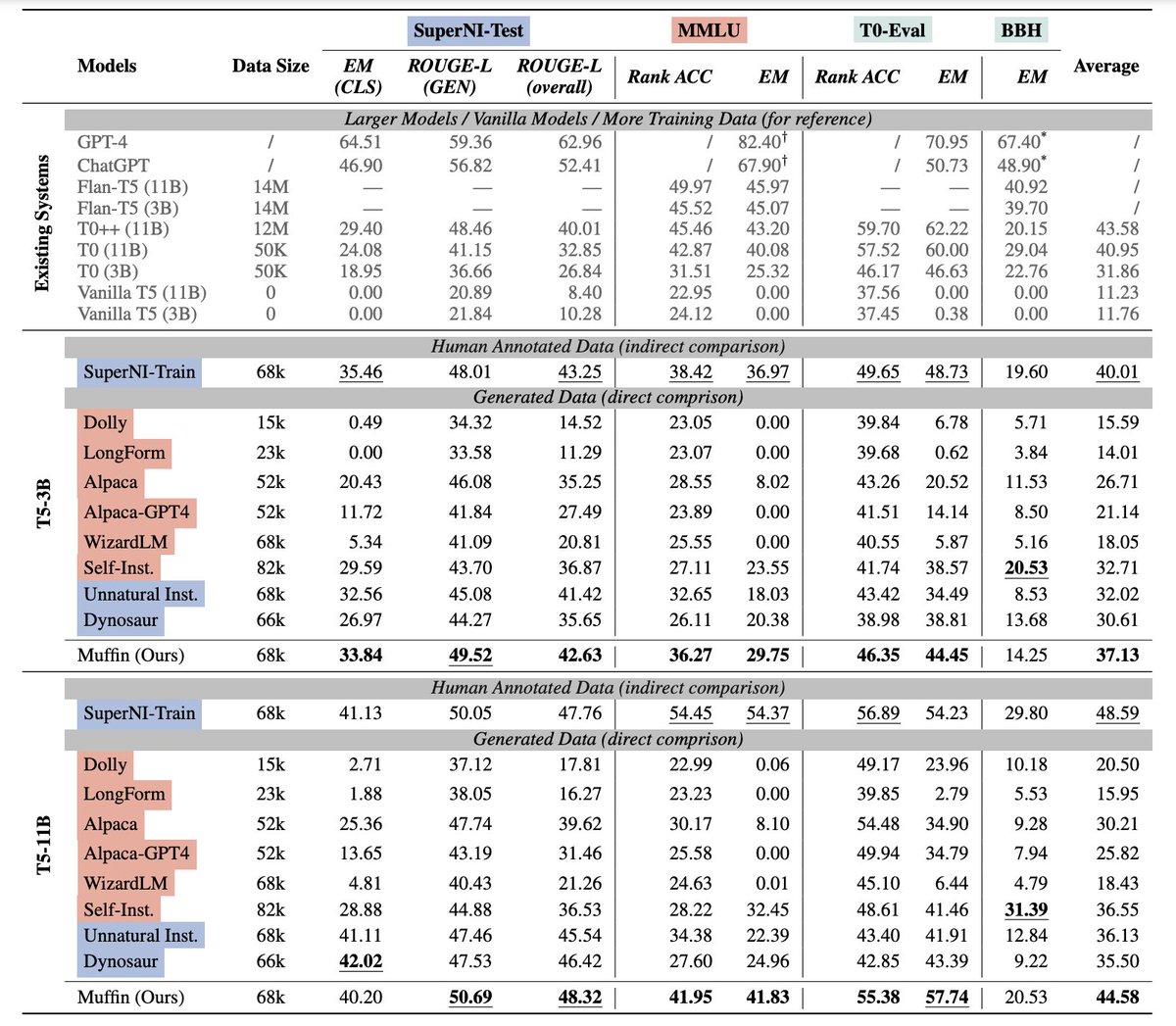
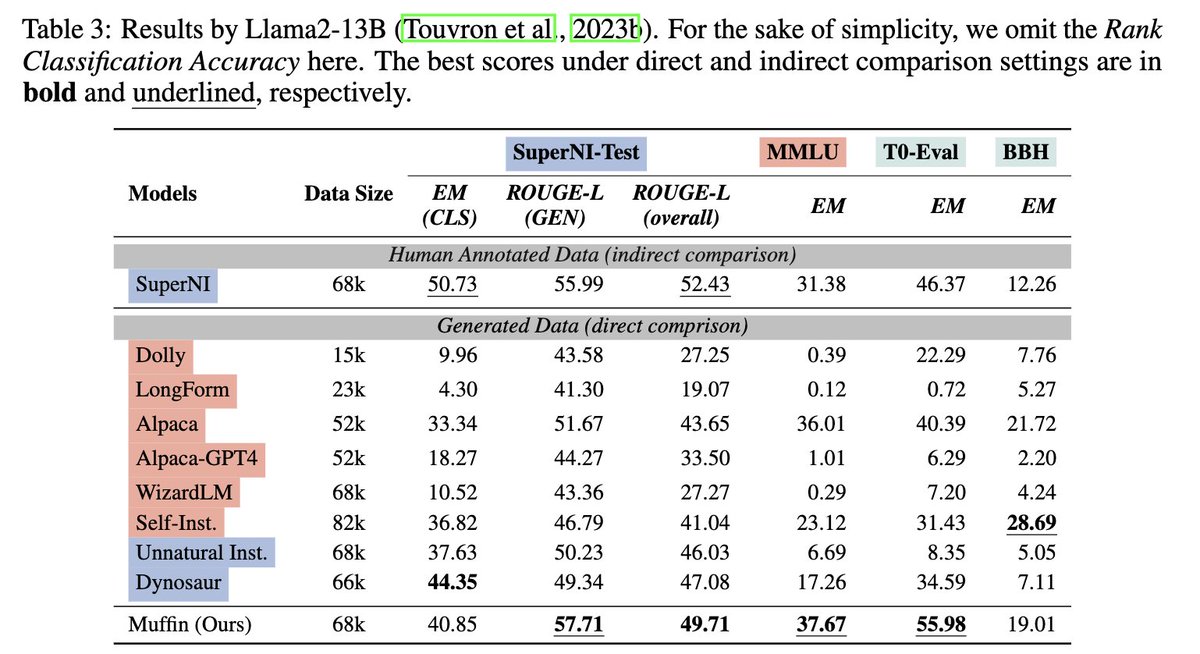
To comprehensively evaluate the 𝙞𝙣𝙨𝙩𝙧𝙪𝙘𝙩𝙞𝙤𝙣-𝙛𝙤𝙡𝙡𝙤𝙬𝙞𝙣𝙜 and 𝙥𝙧𝙤𝙗𝙡𝙚𝙢-𝙨𝙤𝙡𝙫𝙞𝙣𝙜 capacity of the models tuned on 𝙈𝙐𝙁𝙁𝙄𝙉, we adopt various evaluation benchmarks across 𝐝𝐢𝐟𝐟𝐞𝐫𝐞𝐧𝐭 𝐩𝐚𝐫𝐚𝐝𝐢𝐠𝐦𝐬, including:
SuperNI-Test…
Scaling up dataset size appears to be a straightforward yet somewhat "brute force" way for improving instruction-following. How can we "smartly" scale the instruction-tuning dataset?
We are excited to introduce 𝙈𝙐𝙁𝙁𝙄𝙉 (𝙈𝙪lti-𝙁aceted 𝙄𝙣structions), an innovative instruction-tuning dataset designed to 𝙨𝙘𝙖𝙡𝙚 𝙩𝙖𝙨𝙠 𝙞𝙣𝙨𝙩𝙧𝙪𝙘𝙩𝙞𝙤𝙣𝙨 𝙥𝙚𝙧 𝙞𝙣𝙥𝙪𝙩.
Paper: [2312.02436] MUFFIN: Curating Multi-Faceted Instructions for Improving Instruction-Following Dataset: Reza8848/MUFFIN_68k · Datasets at Hugging Face Model: GitHub - RenzeLou/Muffin: MUFFIN: Curating Multi-Faceted Instructions for Improving Instruction-Following Website: Muffin (Multi-faceted Instructions)(1/n)
2/6
The existing data curation paradigm for instruction tuning can broadly be categorized into two streams:
𝑺𝒄𝒂𝒍𝒊𝒏𝒈 𝑰𝒏𝒑𝒖𝒕𝒔: one instruction + multiple inputs.
Amplifying (input, output) pairs per task instruction (e.g., SuperNI).
It's essentially a multi-task…
3/6
We propose a novel instruction paradigm:
𝑺𝒄𝒂𝒍𝒆 𝑻𝒂𝒔𝒌𝒔 𝒑𝒆𝒓 𝑰𝒏𝒑𝒖𝒕: one input + multiple instructions.
Ideally, one input context can be used for diverse task purposes. For example, given a paragraph as the context, we can use it for QA, summarization, etc.…
4/6
To collect an instruction-tuning dataset with 𝑺𝒄𝒂𝒍𝒆 𝑻𝒂𝒔𝒌𝒔 𝒑𝒆𝒓 𝑰𝒏𝒑𝒖𝒕 paradigm, we develop a simple yet effective framework with two instruction-crafting methods:
𝑰𝒏𝒔𝒕𝒓𝒖𝒄𝒕𝒊𝒐𝒏 𝑩𝒓𝒂𝒊𝒏𝒔𝒕𝒐𝒓𝒎. Adopting two-step prompting. For each input context,…
5/6
Our final dataset --- 𝙈𝙐𝙁𝙁𝙄𝙉 (Multi-Faceted Instructions) --- has a 68k instances scale ("one instance" means "one instruction-input-output pair"), with high data quality and diversity according to our human evaluation.
(5/n)
6/6
To comprehensively evaluate the 𝙞𝙣𝙨𝙩𝙧𝙪𝙘𝙩𝙞𝙤𝙣-𝙛𝙤𝙡𝙡𝙤𝙬𝙞𝙣𝙜 and 𝙥𝙧𝙤𝙗𝙡𝙚𝙢-𝙨𝙤𝙡𝙫𝙞𝙣𝙜 capacity of the models tuned on 𝙈𝙐𝙁𝙁𝙄𝙉, we adopt various evaluation benchmarks across 𝐝𝐢𝐟𝐟𝐞𝐫𝐞𝐧𝐭 𝐩𝐚𝐫𝐚𝐝𝐢𝐠𝐦𝐬, including:
SuperNI-Test…