

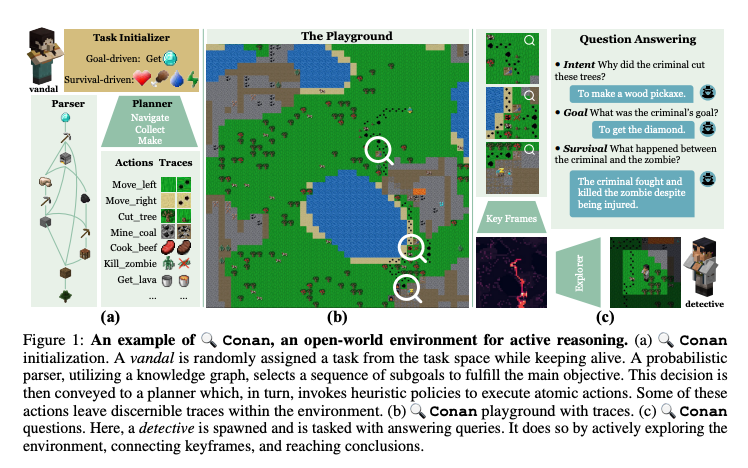

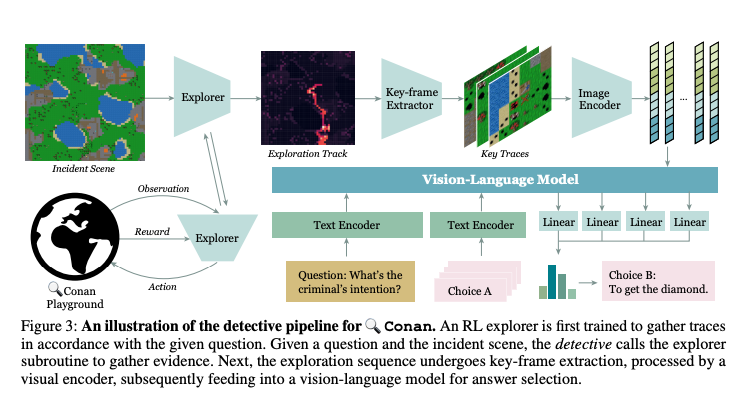
Active Reasoning in an Open-World Environment
abs: [2311.02018] Active Reasoning in an Open-World Environment
pdf: https://arxiv.org/pdf/2311.02018.pdf
site: Conan
et, most models operate passively, responding to questions based on pre-stored knowledge. In stark contrast, humans possess the ability to actively explore, accumulate, and reason using both newfound and existing information to tackle incomplete-information questions. In response to this gap, we introduce �
- Conan: an interactive open-world environment devised for the assessment of active reasoning
- facilitates active exploration and promotes multi-round abductive inference, reminiscent of rich, open-world settings like Minecraft
- compels agents to actively interact with their surroundings, amalgamating new evidence with prior knowledge to elucidate events from incomplete observations
- underscores the shortcomings of contemporary state-of-the-art models in active exploration and understanding complex scenarios
Computer Science > Artificial Intelligence
[Submitted on 3 Nov 2023]Active Reasoning in an Open-World Environment
Manjie Xu, Guangyuan Jiang, Wei Liang, Chi Zhang, Yixin ZhuRecent advances in vision-language learning have achieved notable success on complete-information question-answering datasets through the integration of extensive world knowledge. Yet, most models operate passively, responding to questions based on pre-stored knowledge. In stark contrast, humans possess the ability to actively explore, accumulate, and reason using both newfound and existing information to tackle incomplete-information questions. In response to this gap, we introduce Conan, an interactive open-world environment devised for the assessment of active reasoning. Conan facilitates active exploration and promotes multi-round abductive inference, reminiscent of rich, open-world settings like Minecraft. Diverging from previous works that lean primarily on single-round deduction via instruction following, Conan compels agents to actively interact with their surroundings, amalgamating new evidence with prior knowledge to elucidate events from incomplete observations. Our analysis on Conan underscores the shortcomings of contemporary state-of-the-art models in active exploration and understanding complex scenarios. Additionally, we explore Abduction from Deduction, where agents harness Bayesian rules to recast the challenge of abduction as a deductive process. Through Conan, we aim to galvanize advancements in active reasoning and set the stage for the next generation of artificial intelligence agents adept at dynamically engaging in environments.
| Comments: | Accepted to NeurIPS 2023 |
| Subjects: | Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV) |
| Cite as: | arXiv:2311.02018 [cs.AI] |
| (or arXiv:2311.02018v1 [cs.AI] for this version) | |
| [2311.02018] Active Reasoning in an Open-World Environment Focus to learn more |
Submission history
From: Manjie Xu [view email][v1] Fri, 3 Nov 2023 16:24:34 UTC (14,505 KB)















 Introducing ToDo : Token Downsampling for Efficient Generation of High-Resolution Images ! With
Introducing ToDo : Token Downsampling for Efficient Generation of High-Resolution Images ! With 