
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?GitHub - gururise/AlpacaDataCleaned: Alpaca dataset from Stanford, cleaned and curated
Alpaca dataset from Stanford, cleaned and curated. Contribute to gururise/AlpacaDataCleaned development by creating an account on GitHub.
 github.com
github.com

 Cleaned Alpaca Dataset
Cleaned Alpaca Dataset
Welcome to the Cleaned Alpaca Dataset repository! This repository hosts a cleaned and curated version of a dataset used to train the Alpaca LLM (Large Language Model). The original dataset had several issues that are addressed in this cleaned version.Dataset Quality and its Impact on Model Performance
One possibility behind the lack of a significant improvement in performance from fine-tuning the 7B Alpaca model to the 13B model is the quality of the original dataset. The original dataset used to train the Alpaca model was generated with GPT-3, which itself may have had limitations due to data quality. More evidence pointing to poor data quality is that fine-tuning on the original dataset resulted in poor loss curves.The quality of the dataset plays a crucial role in determining the performance of the natural language processing models trained on it. A dataset that is noisy, inconsistent, or incomplete can result in poor performance even with the most advanced models. In contrast, a high-quality dataset can enable a model to perform well with smaller parameters.
Therefore, it is possible that with better data, we could improve the performance of the models more than what would be gained by simply increasing model size.
Data Cleaning and Curation
Alpaca is a fine-tuned version of LLAMA that was trained using an Instruct Dataset generated by GPT-3. The generated dataset was designed to be diverse; however, recent analysis indicates it is very US centric. The original dataset used to train the Alpaca LLM was found to have many issues that impacts its quality and usefulness for training a machine learning model.
elinas/alpaca-30b-lora-int4 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
llama-30b-int4
This LoRA trained for 3 epochs and has been converted to int4 via GPTQ method. See the repo below for more info.GitHub - qwopqwop200/GPTQ-for-LLaMa: 4 bits quantization of LLaMA using GPTQ
LoRA credit to baseten/alpaca-30b · Hugging Face
Update 2023-03-29
There is also a non-groupsize quantized model that is 1GB smaller in size, which should allow running at max context tokens with 24GB VRAM. The evaluations are better on the 128 groupsize version, but the tradeoff is not being able to run it at full context without offloading or a GPU with more VRAM.Update 2023-03-27
New weights have been added. The old .pt version is no longer supported and has been replaced by a 128 groupsize safetensors file. Update to the latest GPTQ version/webui.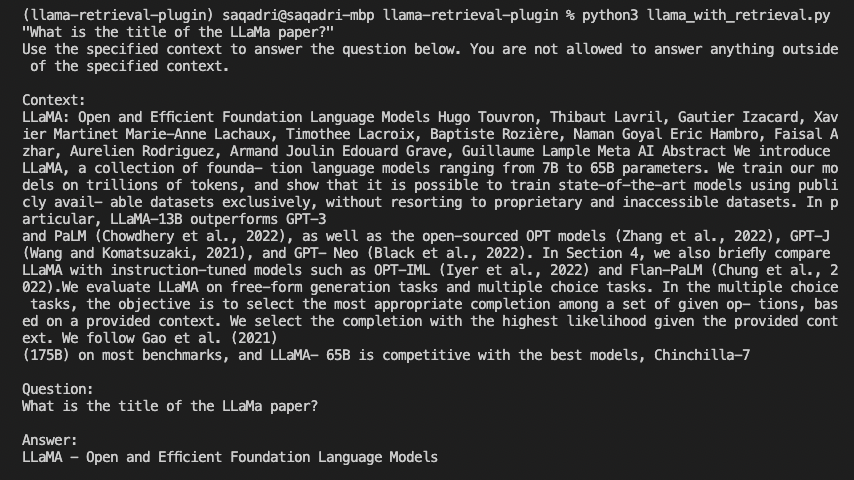
Using ChatGPT Plugins with LLaMA
Use OpenAI’s chatgpt-retrieval-plugin with the LLaMa language model to show the need for a standard plugin protocol.
 blog.lastmileai.dev
blog.lastmileai.dev
LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention
Renrui Zhang, Jiaming Han, Aojun Zhou, Xiangfei Hu, Shilin Yan, Pan Lu, Hongsheng Li, Peng Gao, Yu QiaoWe present LLaMA-Adapter, a lightweight adaption method to efficiently fine-tune LLaMA into an instruction-following model. Using 52K self-instruct demonstrations, LLaMA-Adapter only introduces 1.2M learnable parameters upon the frozen LLaMA 7B model, and costs less than one hour for fine-tuning on 8 A100 GPUs. Specifically, we adopt a set of learnable adaption prompts, and prepend them to the input text tokens at higher transformer layers. Then, a zero-init attention mechanism with zero gating is proposed, which adaptively injects the new instructional cues into LLaMA, while effectively preserves its pre-trained knowledge. With efficient training, LLaMA-Adapter generates high-quality responses, comparable to Alpaca with fully fine-tuned 7B parameters. Furthermore, our approach can be simply extended to multi-modal input, e.g., images, for image-conditioned LLaMA, which achieves superior reasoning capacity on ScienceQA. We release our code at this https URL.

GitHub - ZrrSkywalker/LLaMA-Adapter: Fine-tuning LLaMA to follow instructions within 1 Hour and 1.2M Parameters
Fine-tuning LLaMA to follow instructions within 1 Hour and 1.2M Parameters - GitHub - ZrrSkywalker/LLaMA-Adapter: Fine-tuning LLaMA to follow instructions within 1 Hour and 1.2M Parameters
github.com
LLaMA-Adapter: Efficient Fine-tuning of LLaMA 
Official implementation of 'LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention'.This repo proposes LLaMA-Adapter, a lightweight adaption method for fine-tuning instruction-following LLaMA models
 , using 52K data provided by Stanford Alpaca.
, using 52K data provided by Stanford Alpaca.Overview
Efficiency Comparison:Model | Parameters | Storage Space | Training Time |
|---|---|---|---|
7B | 13G | 3 Hours | |
LLaMA-Adapter | 1.2M | 4.7M | 1 Hour |




8bit-coder/alpaca-7b-nativeEnhanced · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
Alpaca 7B Native Enhanced
The Most Advanced Alpaca 7B Model
 Model Facts
Model Facts
- Trained natively on 8x Nvidia A100 40GB GPUs; no LoRA used
- Trained on the largest & most accurate dataset yet
- Enhanced Programming Capabilities
- First Alpaca model to have conversational awareness
Quick Start Guide
Step 1. Make sure git-lfs is installed and ready to use (Guide)Step 2. Download and install text-generation-webui according to the repository's instructions
Step 3. Navigate over to one of it's model folders and clone this repository:
git clone 8bit-coder/alpaca-7b-nativeEnhanced · Hugging Face
Step 4. Launch the webui, replace "Your name" with "User" and replace the default instruction prompt with:
Step 5. Change the settings to match this screenshot:You are an AI language model designed to assist the User by answering their questions, offering advice, and engaging in casual conversation in a friendly, helpful, and informative manner. You respond clearly, coherently, and you consider the conversation history.
User: Hey, how's it going?
Assistant: Hey there! I'm doing great, thank you. What can I help you with today? Let's have a fun chat!

Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, Thomas ScialomLanguage models (LMs) exhibit remarkable abilities to solve new tasks from just a few examples or textual instructions, especially at scale. They also, paradoxically, struggle with basic functionality, such as arithmetic or factual lookup, where much simpler and smaller models excel. In this paper, we show that LMs can teach themselves to use external tools via simple APIs and achieve the best of both worlds. We introduce Toolformer, a model trained to decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the results into future token prediction. This is done in a self-supervised way, requiring nothing more than a handful of demonstrations for each API. We incorporate a range of tools, including a calculator, a Q\&A system, two different search engines, a translation system, and a calendar. Toolformer achieves substantially improved zero-shot performance across a variety of downstream tasks, often competitive with much larger models, without sacrificing its core language modeling abilities.
GitHub - conceptofmind/toolformer
Contribute to conceptofmind/toolformer development by creating an account on GitHub.
github.com
Open-source implementation of Toolformer: Language Models Can Teach Themselves to Use Tools by Meta AI.


GitHub - hpcaitech/ColossalAI: Making large AI models cheaper, faster and more accessible
Making large AI models cheaper, faster and more accessible - hpcaitech/ColossalAI
github.com
Colossal-AI: Making large AI models cheaper, faster and more accessible



Last edited: