WIRED spoke with DeepMind’s climate lead about techno-utopianism, ways AI can help fight climate change, and what’s currently standing in the way.

www.wired.co.uk
DeepMind Wants to Use AI to Solve the Climate Crisis
WIRED spoke with DeepMind’s climate lead about techno-utopianism, ways AI can help fight climate change, and what’s currently standing in the way.
Aerial view flooded tree-lined Bookpurnong Road, the main Loxton to Berri connector road on River Murray in South Australia.PHOTOGRAPH: GETTY IMAGES
It’s a perennial question at WIRED: Tech got us into this mess, can it get us out? That’s particularly true when it comes to climate change. As the weather becomes more extreme and unpredictable, there are hopes that artificial intelligence—that other existential threat—might be part of the solution.
DeepMind, the Google-owned artificial intelligence lab, has been using its AI expertise to tackle the climate change problem in three different ways, as Sims Witherspoon, DeepMind’s climate action lead, explained in an interview ahead of her talk at
WIRED Impact in London on November 21. This conversation has been edited for clarity and length.
WIRED: How can AI help us tackle climate change?
Sims Witherspoon: There are lots of ways we can slice the answer. AI can help us in mitigation. It can help us in adaptation. It can help us with addressing loss and damage. It can help us in biodiversity and ecology and much more. But I think one of the ways that makes it more tangible for most people is to talk about it through the lens of AI’s strengths.
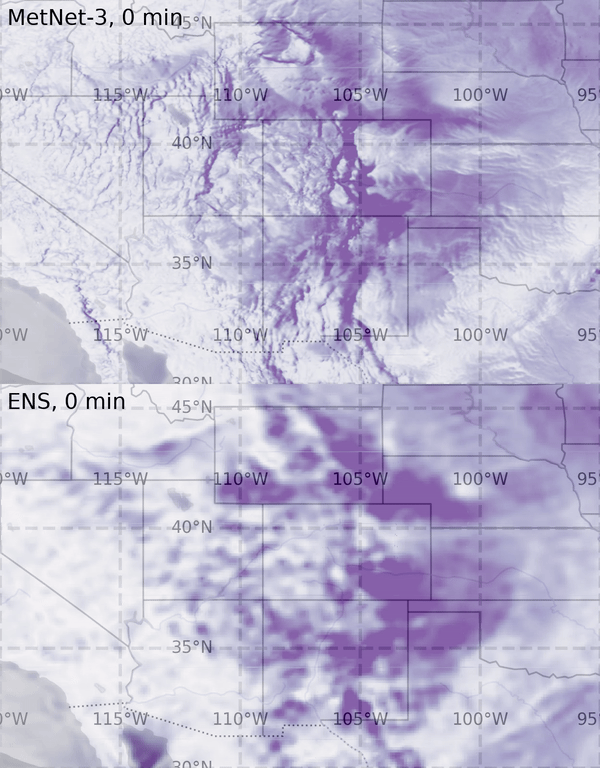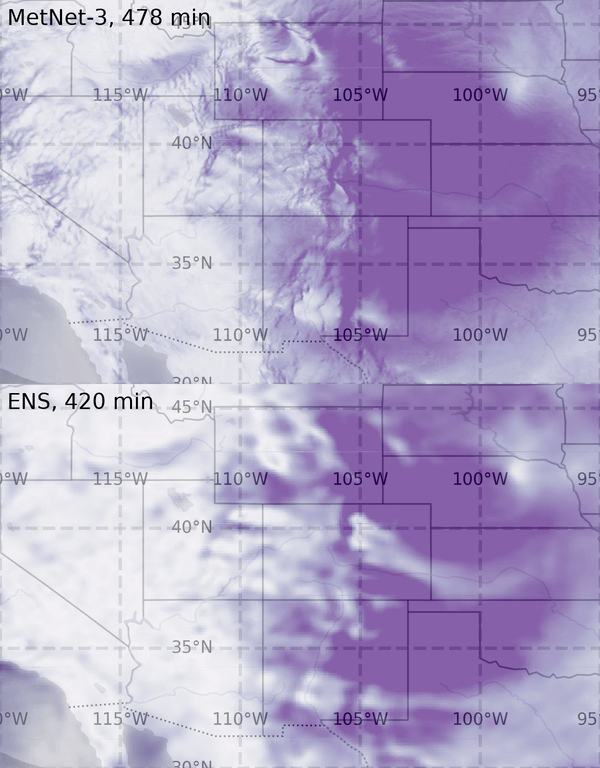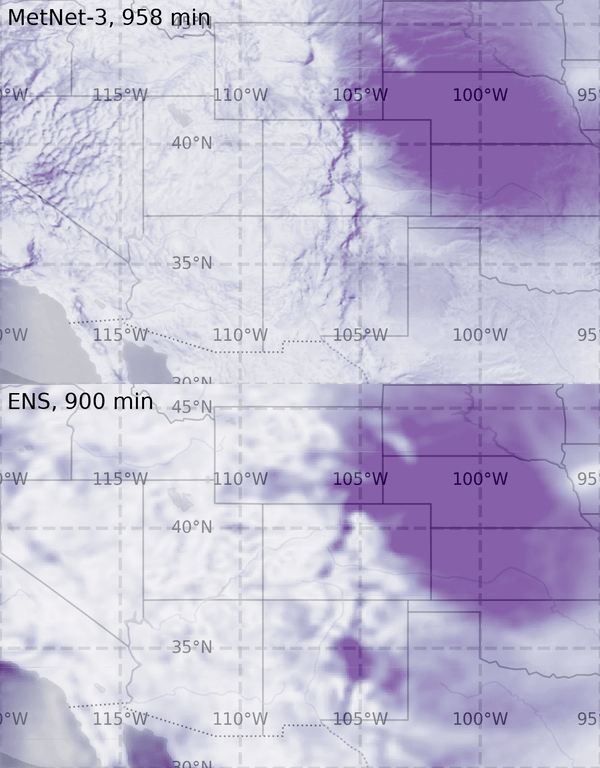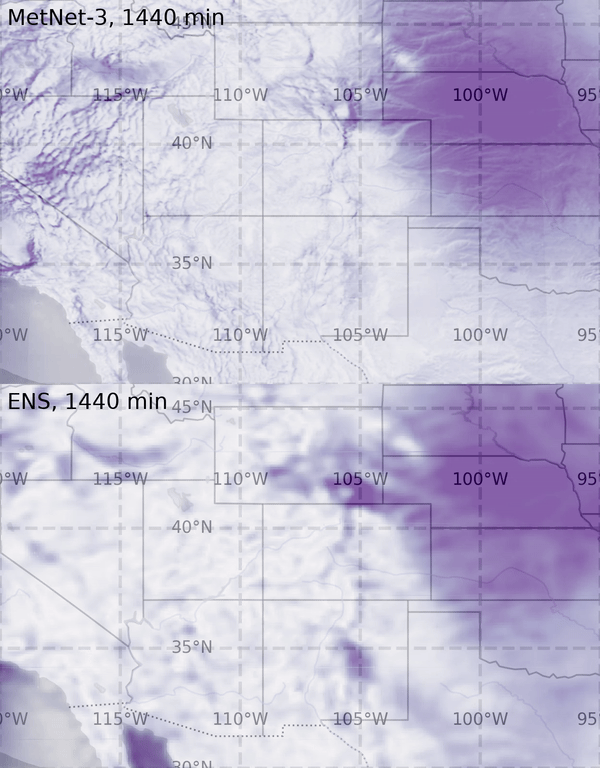
I think of it in three parts: First and foremost, AI can help us understand climate change and the problems that we face related to climate change through better models for prediction and monitoring. One example is our work on
precipitation nowcasting—so, forecasting rain a few hours ahead—and our models were voted more useful and more accurate than other methods by Met Office forecasters, which is great.
But it’s also just the start because you can then build to predict much more complex phenomena. So AI can be a really significant tool in helping us understand climate change as a problem.
What’s the second thing?
The second bucket that I like to think about is the fact that AI can help us optimize current systems and existing infrastructure. It’s not enough to start building new green technology for a more sustainable tomorrow, life needs to go on—we already have many systems that we rely on today, and we can’t just burn them all down and start from scratch. We need to be able to optimize those existing systems and infrastructure, and AI is one of the tools that we can use to do this.
A nice example of this is the work we did in
data centers, where we were able to improve energy efficiency and achieve a 30 percent energy saving.
And then the third thing is new technology?
Yes, the third bucket is the way that most people think about AI, when they think about the Hollywood version or what you read about in sci-fi novels and things, which is accelerating breakthrough science.
I really like the example of nuclear fusion and plasma control—we published a
Nature paper where we used neural nets to train a reinforcement learning model to learn how to control plasma shapes in a real-world tokamak [a nuclear fusion reactor]. And that’s really important because actually understanding plasma physics and being able to control those shapes and configurations is an incredibly important building block to ultimately achieving a nearly inexhaustible supply of carbon-free energy.
You can’t really talk about AI and climate change without reference to the carbon footprint of AI itself, and the massive amounts of energy being consumed by data centers, which is something people are becoming a lot more aware of. How do you think about that problem? When will AI get to the point where it’s saved more carbon than it’s used to be trained?
I would love to see that analysis; I don’t know if anyone’s done it. Many of the language models and generative AI success stories we’ve seen over recent years, it’s true, they are energy-intensive, and this is a problem that we’ve documented. We believe it’s really important to see and understand how much energy these models use and be open about that, and then we also have a number of efforts to reduce the compute needed for these models. So we think about it in a few ways—not as globally as, “Is the carbon we’ve burned worth the solutions?” but more about, “How do you deploy solutions that are as carbon-efficient as possible?”
What are the roadblocks that are going to stop AI being used to fight climate change?
The first one is access to data. There are significant gaps in climate-critical data across all sectors, whether it’s electricity or transportation or buildings and cities. There’s a group that we work with that publishes a “
climate critical data set wishlist,” and I think having those datasets and getting people comfortable—where it’s safe and responsible to do so—with opening up climate-critical data sets is incredibly important.
The other part that I put almost on par with data is working with domain experts. At Google DeepMind, we are focused on AI research and AI product development—we’re not plasma physicists, we’re not electrical engineers. And so when we’re trying to figure out problems that we want to solve, we really need to be working with those experts who can teach us about the problems that they experienced and the things that are blocking them. That does two things. One, it ensures that we fully understand what we’re building an AI solution for. And the second thing is it ensures that whatever we’re building is going to get used. We don’t just want to make this cool piece of tech and then hope that somebody uses it.
Are there any safety considerations? People might be nervous about seeing the words “nuclear fusion” and “artificial intelligence” in the same sentence …
In my area specifically, one of the ways we deal with that is again going back to working with domain experts—making sure we understand the systems really well, and what they need to keep the system safe. It’s those experts that teach us about that, and then we build solutions that are within those guardrails.
Within climate and sustainability, we also do a lot of impact analysis: what we expect our potential impact to be and then all the downstream effects of that.
You’ve said you’re a techno-optimist, so what’s the techno-optimist view of a future where AI is fully brought to bear on climate change?
The techno-optimist’s view is that—provided we’re able to wield it effectively—we’re able to use a transformative tool like AI to solve sector-specific and non-sector-specific problems more quickly, and at a scale we wouldn’t be able to without AI. One of the things I’m most excited about is the versatility and scalability of the tool. And given the amount of problems we need to solve related to climate change, what we need is a highly versatile and highly scalable tool.
Join Sims Witherspoon and our world-class speaker line-up at WIRED Impact, November 21, at Magazine, London, as we examine the challenges and opportunities for organizations to innovate to tackle humankind’s most pressing challenge. Get tickets now: events.wired.co.uk/impact











chat.openai.com

www.searchenginejournal.com

.jpg)
.jpg "aerial of flood in Australia")
