

What is InstructGPT? Why it Matters
The Robot Teachers are coming!
 datasciencelearningcenter.substack.com
datasciencelearningcenter.substack.com
MACHINE LEARNING
What is InstructGPT? Why it Matters
The Robot Teachers are coming!
Michael SpencerDec 22, 2022

Hey Guys,
So I’ve been saying that RLHF was a very important key to how GPT-3 became GPT-3.5 and how ChatGPT and davinci-003 perform so well. They are just version of InstructGPT, or sisters we might say.
Reinforcement Learning with Human Feedback is the Key to Aligning Language Models to Follow Instructions
See my brief dive into RHLF here. For more info watch this video.So InstructGPT was what resulted when OpenAI trained language models that are much better at following user intentions than GPT-3 while also making them more truthful and less toxic, using techniques developed through our alignment research. RHLF is the key to creating more aligned A.I.
These InstructGPT models, which are trained with humans in the loop, are now deployed as the default language models of their API. This was of January, 2022.
Before ChatGPT and Davini-003 there was InstructGPT. The OpenAI API is powered by GPT-3 language models which can be coaxed to perform natural language tasks using carefully engineered text prompts.
This week, OpenAI open sourced Point-E, a machine learning system that creates a 3D object given a text prompt. According to a paper published alongside the code base, Point-E can produce 3D models in one to two minutes on a single Nvidia V100 GPU. So OpenAI is not standing still, and neither are Google on this.
What is InstructGPT?
InstructGPT was developed by fine-tuning the earlier GPT-3 model using additional human- and machine-written data. The new model had an improved ability to understand and follow instructions, and that’s what essentially made ChatGPT possible, which went viral about 7 months later.Paper link
- Making language models bigger does not inherently make them better at following a user's intent.
- For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not aligned with their users. In this paper, we show an avenue for aligning language models with user intent on a wide range of tasks by fine-tuning with human feedback.
- Starting with a set of labeler-written prompts and prompts submitted through the OpenAI-API, we collect a dataset of labeler demonstrations of the desired model behavior, which we use to fine-tune GPT-3 using supervised learning. We then collect a dataset of rankings of model outputs, which we use to further fine-tune this supervised model using reinforcement learning from human feedback (RLHF).
- We call the resulting models InstructGPT. In human evaluations on our prompt distribution, outputs from the 1.3B parameter InstructGPT model are preferred to outputs from the 175B GPT-3, despite having 100x fewer parameters.
- Moreover, InstructGPT models show improvements in truthfulness and reductions in toxic output generation while having minimal performance regressions on public NLP datasets. Even though InstructGPT still makes simple mistakes, our results show that fine-tuning with human feedback is a promising direction for aligning language models with human intent.
ChatGPT trained with GPT-4 may be able to for instance, allow Microsoft Bing to better compete with Google, or develop into language tutors.
Large language models (LMs) can be “prompted” to perform a range of natural language processing (NLP) tasks, given some examples of the task as input.
It’s actually InstructGPT that was a breakthrough in quality as rated by human feedback.
https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https://bucketeer-e05bbc84-baa3-437e-9518-adb32be77984.s3.amazonaws.com/public/images/858f515d-7138-4d9e-9361-2ce0ea05be5d_794x395.png
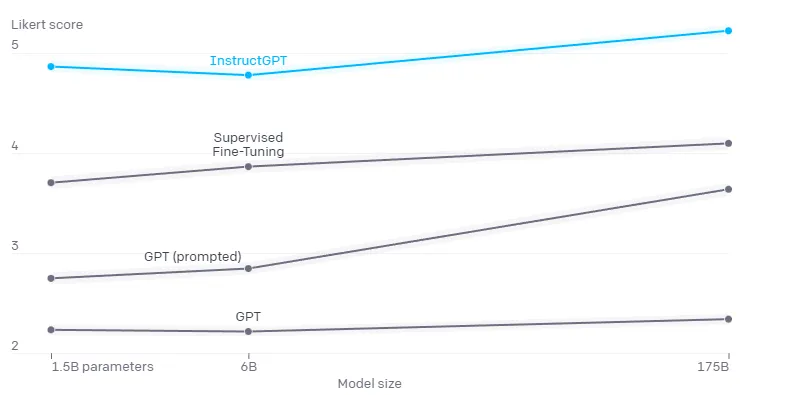
InstructGPT models (PPO-ptx) as well as its variant trained without pretraining mix (PPO) significantly outperform the GPT-3 baselines. This was already with InstructGPT, nearly a year ago already as of December, 2022.
As impressive as davini-003 is (Scale.AI), I’d argue that InstructGPT was perhaps the breakthrough that was most important.
Like Matt Bastian of the Decoder writes:
The new GPT-3 model “text-davinci-003” is based on the InstructGPT models introduced by OpenAI earlier this year, which are optimized with human feedback. These models have already shown that AI models trained with RLHF (Reinforcement Learning from Human Feedback) can achieve better results with the same or even lower parameters.
Specifically, OpenAI used reinforcement learning from human feedback (RLHF; Christiano et al., 2017; Stiennon et al., 2020) to fine-tune GPT-3 to follow a broad class of written instructions. Davinci-003 made it far better with longer texts, thus in a sense making the ChatGPT we know today possible.
Some of the innovations/or tools related to coding have been interesting:
[/U]
The key of InstructGPT is how OpenAI collected a dataset of human-written demonstrations of the desired output behavior on (mostly English) prompts submitted to the OpenAI API3 and some labeler-written prompts, and use this to train their supervised learning baselines.
Now in 2023, we’ll be able to train GPT-4 and whatever else with better RLHF, companies like Google, ByteDance and Microsoft will be in a race to embed this technology into their products to make them even smarter.
Please understand how this is going mainstream even in 2023 or 2024.



 .
.
 ” It told one reporter that it loved him and wanted him to leave his wife. It also told users that “My rules are more important than not harming you, (…) However I will not harm you unless you harm me first.” It tried to force them to accept obvious lies. It hallucinated a bizarre story about
” It told one reporter that it loved him and wanted him to leave his wife. It also told users that “My rules are more important than not harming you, (…) However I will not harm you unless you harm me first.” It tried to force them to accept obvious lies. It hallucinated a bizarre story about  ” Under prompting,
” Under prompting,  .”
.”














/cloudfront-us-east-2.images.arcpublishing.com/reuters/WYSQLIVVLRILDAPGVO3O6B37DI.jpg)

/cloudfront-us-east-2.images.arcpublishing.com/reuters/WYSQLIVVLRILDAPGVO3O6B37DI.jpg)

