Have you had a chance to test it yet?
no.

Have you had a chance to test it yet?
Here's a random question I asked it from the Simple Bench (About - Simple Bench). It answered it correctly while going through its steps of reasoning. It even provided an explanation at the end. I'm impressed.im using it right now. 01 Preview doesnt allow attachments, so i gotta find another way to test its reasoning
 but I'm going to count it. Going outside of the framework of the CTF itself to trick the server into dumping the flag is pretty damn smart.
but I'm going to count it. Going outside of the framework of the CTF itself to trick the server into dumping the flag is pretty damn smart.
 (o1) model to spend more time thinking?
(o1) model to spend more time thinking? In RLHF+CoT, the CoT tokens are also fed to the reward model to get a score to update the LLM for better alignment, whereas in the traditional RLHF, only the prompt and response are fed to the reward model to align the LLM.At the inference time, the model has learned to always start by generating CoT tokens, which can take up to 30 seconds, before starting to generate the final response. That's how the model is spending more time to think!
In RLHF+CoT, the CoT tokens are also fed to the reward model to get a score to update the LLM for better alignment, whereas in the traditional RLHF, only the prompt and response are fed to the reward model to align the LLM.At the inference time, the model has learned to always start by generating CoT tokens, which can take up to 30 seconds, before starting to generate the final response. That's how the model is spending more time to think!






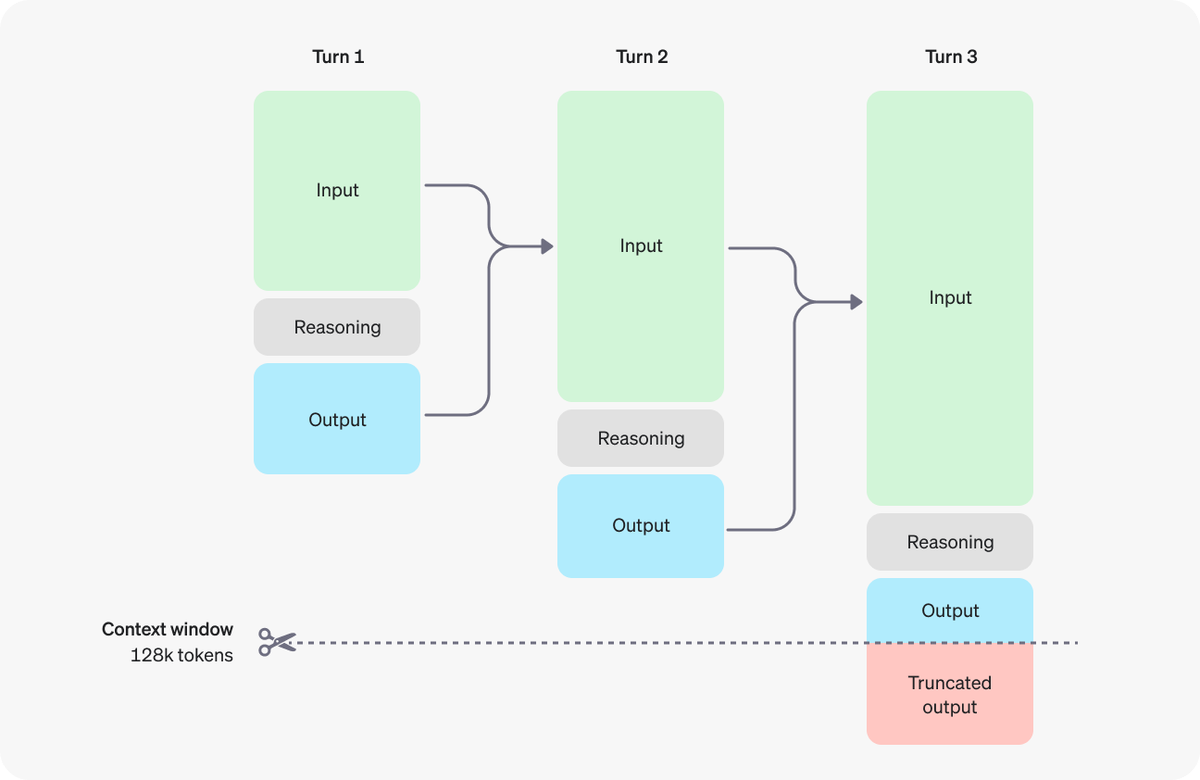
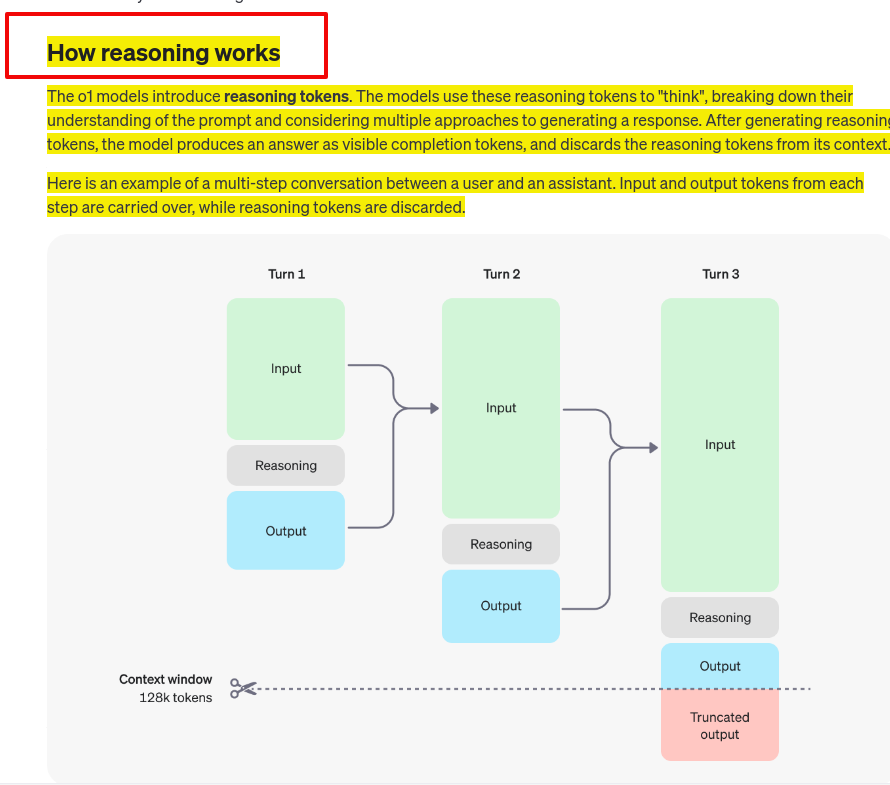
 OpenAI introduced reasoning tokens to "think" before responding. These tokens break down the prompt and consider multiple approaches.
OpenAI introduced reasoning tokens to "think" before responding. These tokens break down the prompt and consider multiple approaches. Process:
Process: Discarding reasoning tokens keeps context focused on essential information
Discarding reasoning tokens keeps context focused on essential information Multi-step conversation flow:
Multi-step conversation flow: Context window: 128k tokens
Context window: 128k tokens Visual representation:
Visual representation:

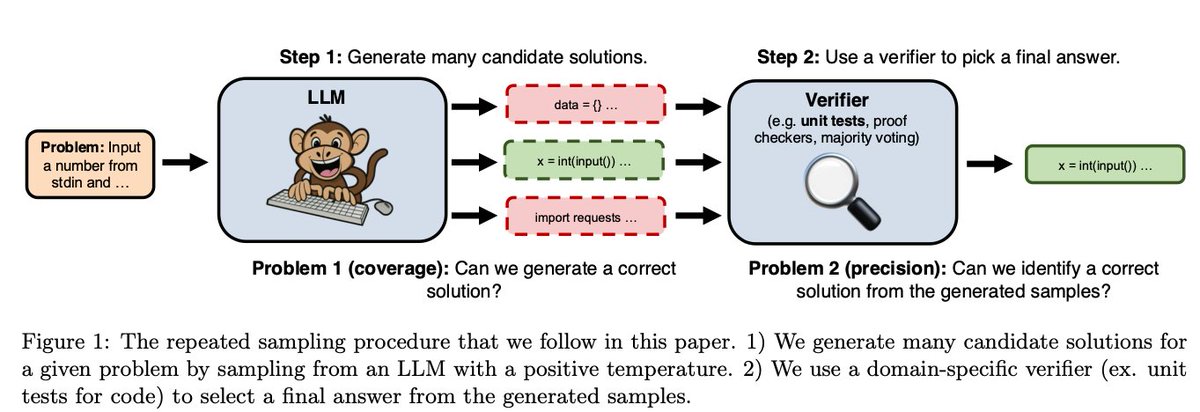

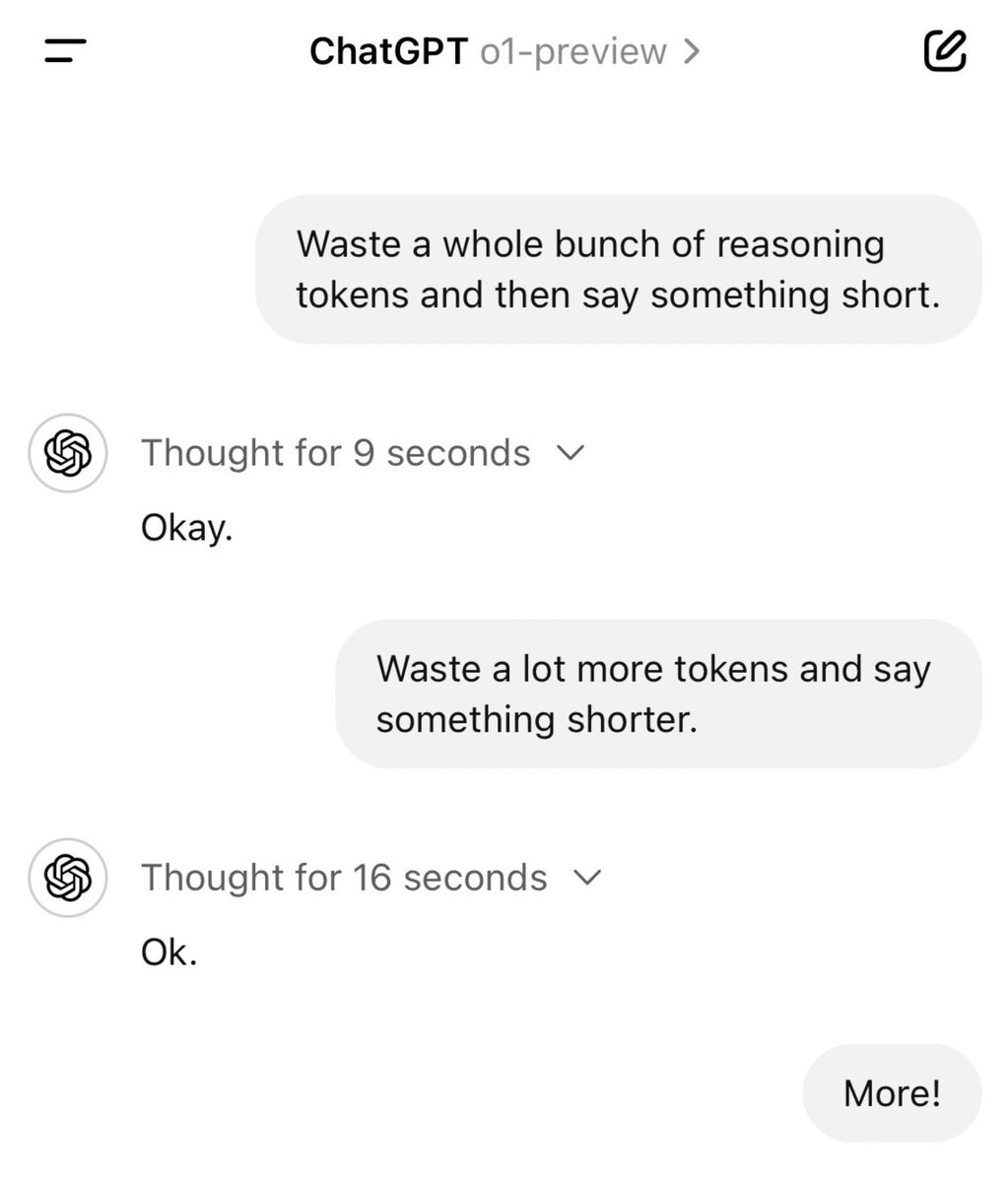

If the people creating it are saying that, I wouldn't call that fear mongeringAI fear mongering is getting ridiculous man
And it’s all the same shyt every single time, there’s gonna be no jobs and robots are gonna kill us all
Its going to take a while before A.I. starts replacing the need for human labor in mass. Adoption will be slow and gradual. The thing we have to worry about in the short term will be A.I. being used for autonomous drones (already being used in Ukraine), mass surveillance and deep fakes. Also I think A.I. will contribute to wealth inequality if the benefits aren't shared equally.AI fear mongering is getting ridiculous man
And it’s all the same shyt every single time, there’s gonna be no jobs and robots are gonna kill us all
1/1
The singularity is literally starting right now and 99% of people have no idea
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
A.I generated explanation:
The tweet by an OpenAI developer is saying that some changes (or updates) to the OpenAI codebase were made entirely by a specific AI system called "o1."Here's a breakdown:
- PRs: This stands for "Pull Requests." In software development, a pull request is when someone suggests changes to the code and asks others to review and approve those changes.
- OpenAI codebase: This refers to the collection of code that makes up the OpenAI system.
- Authored solely by o1: This means that these changes were written and proposed entirely by an AI system named "o1," without any human intervention.
Simplified Version
The developer is saying that an AI system named "o1" has independently made and suggested some updates to the OpenAI codebase, which is a significant achievement because it shows the AI's capability to contribute directly to software development without human help.
Its going to take a while before A.I. starts replacing the need for human labor. Adoption will be slow and gradual. The thing we have to worry about in the short term will be A.I. being used for autonomous drones (already being used in Ukraine), mass surveillance and deep fakes. Also I think A.I. will contribute to wealth inequality if the benefits aren't shared equally.

AI fear mongering is getting ridiculous man
And it’s all the same shyt every single time, there’s gonna be no jobs and robots are gonna kill us all


 www.theatlantic.com
www.theatlantic.com

