1/38
@OpenAI
Introducing OpenAI o3 and o4-mini—our smartest and most capable models to date.
For the first time, our reasoning models can agentically use and combine every tool within ChatGPT, including web search, Python, image analysis, file interpretation, and image generation.
https://video.twimg.com/amplify_video/1912558263721422850/vid/avc1/1920x1080/rUujwkjYxj0NrNfc.mp4
2/38
@OpenAI
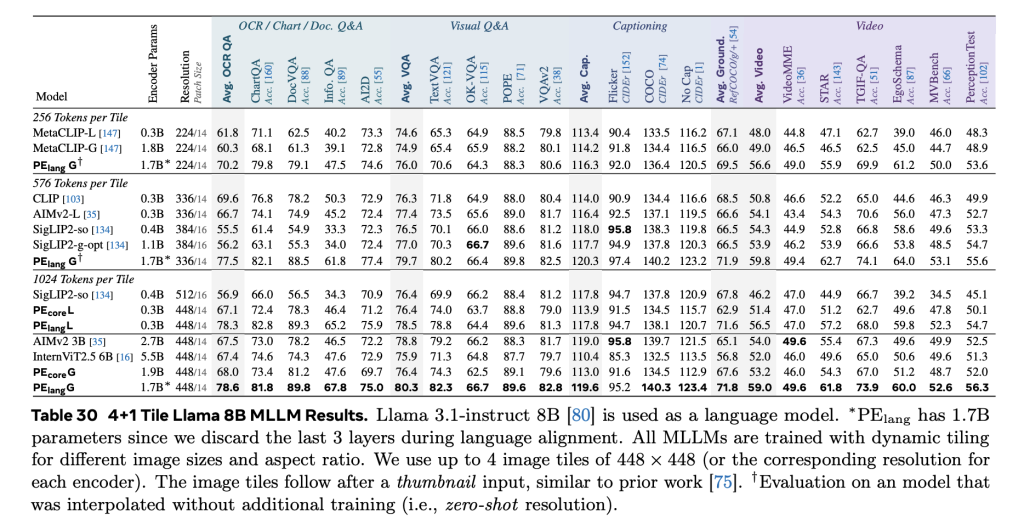
OpenAI o3 is a powerful model across multiple domains, setting a new standard for coding, math, science, and visual reasoning tasks.
o4-mini is a remarkably smart model for its speed and cost-efficiency. This allows it to support significantly higher usage limits than o3, making it a strong high-volume, high-throughput option for everyone with questions that benefit from reasoning.
https://openai.com/index/introducing-o3-and-o4-mini/
3/38
@OpenAI
OpenAI o3 and o4-mini are our first models to integrate uploaded images directly into their chain of thought.
That means they don’t just see an image—they think with it.
https://openai.com/index/thinking-with-images/
4/38
@OpenAI
ChatGPT Plus, Pro, and Team users will see o3, o4-mini, and o4-mini-high in the model selector starting today, replacing o1, o3-mini, and o3-mini-high.
ChatGPT Enterprise and Edu users will gain access in one week. Rate limits across all plans remain unchanged from the prior set of models.
We expect to release o3-pro in a few weeks with full tool support. For now, Pro users can still access o1-pro in the model picker under ‘more models.’
5/38
@OpenAI
Both OpenAI o3 and o4-mini are also available to developers today via the Chat Completions API and Responses API.
The Responses API supports reasoning summaries, the ability to preserve reasoning tokens around function calls for better performance, and will soon support built-in tools like web search, file search, and code interpreter within the model’s reasoning.
6/38
@riomadeit
damn they took bro's job
7/38
@ArchSenex
8/38
@danielbarada
This is so cool
9/38
@miladmirg
so many models, it's hard to keep track lol. Surely there's a better way for releases
10/38
@ElonTrades
Only $5k a month
11/38
@laoddev
openai is shipping
12/38
@jussy_world
What is better for writing?
13/38
@metadjai
Awesome!

14/38
@rzvme
o3 is really an impressive model
[Quoted tweet]
I am impressed with the o3 model released today by @OpenAI
First model to one shot solve this!
o4-mini-high managed to solve in a few tries, same as other models
Congrats @sama and the team
Can you solve it?

Chat link with the solution in the next post
15/38
@saifdotagent
the age of abundance is upon us
16/38
@Jush21e8
make o3 play pokemon red pls
17/38
@agixbt
tool use is becoming a must have for next-gen AI systems
18/38
@karlmehta
Chef’s kiss.
19/38
@thedealdirector
Bullish, o3 pro remains the next frontier.
20/38
@dylanjkl
What’s the performance compared to Grok 3?
21/38
@ajrgd
First “agentic”. Now “agentically”

If you can’t use the word without feeling embarrassed in front of your parents, don’t use the word

22/38
@martindonadieu
NAMING, OMG
LEARN NAMING
23/38
@emilycfa
LFG
24/38
@scribnar
The possibilities for AI agents are limitless
25/38
@ArchSenex
Still seems to have problem using image gen. Refusing requests to change outfits for visualizing people in products, etc.
26/38
@rohanpaul_ai
[Quoted tweet]
Just published today's edition of my newsletter.

OpenAI launched of o3 full model and o4-mini and a variant of o4-mini called “o4-mini-high” that spends more time crafting answers to improve its reliability.
Link in comment and bio
(consider subscribing, its FREE, I publish it very frequently and you will get a 1300+page Python book sent to your email instantly

)
27/38
@0xEthanDG
But can it do a kick flip?

28/38
@EasusJ
Need that o3 pro for the culture…
29/38
@LangbaseInc
Woohoo!

We just shipped both models on @LangbaseInc
[Quoted tweet]
OpenAI o3 and o4-mini models are live on Langbase.

First visual reasoning models
o3: Flagship reasoning, knowledge up-to June 2024, cheaper than o1
o4-mini: Fast, better reasoning than o3-mini at same cost
30/38
@mariusschober
Usage Limits?
31/38
@nicdunz
[Quoted tweet]
wow... this is o3s svg unicorn
32/38
@sijlalhussain
That’s a big step. Looking forward to trying it out and seeing what it can actually do across tools.
33/38
@AlpacaNetworkAI
The models keep getting smarter

The next question is: who owns them?
Open access is cool.
Open ownership is the future.

34/38
@ManifoldMarkets
"wtf I thought 4o-mini was supposed to be super smart, but it didn't get my question at all?"
"no no dude that's their least capable model. o4-mini is their most capable coding model"
35/38
@naviG29
Make it easy to attach the screenshots in desktop app... Currently, cmd+shift+1 adds the image from default screen but I got 3 monitors
36/38
@khthondev
PYTHON MENTIONED
37/38
@rockythephaens
ChatGPT just unlocked main character
38/38
@pdfgptsupport
This is my favorite AI tool for reviewing reports.
Just upload a report, ask for a summary, and get one in seconds.
It's like ChatGPT, but built for documents.
Try it for free.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

 techcrunch.com
techcrunch.com












 ! I know that 2 were discussed (codex and another) Modes(full auto/suggest?) we will have access to but; does this mean that creating our own tools should be considered less of a focus than using those already created and available? This is for my personal memory(X as S3)
! I know that 2 were discussed (codex and another) Modes(full auto/suggest?) we will have access to but; does this mean that creating our own tools should be considered less of a focus than using those already created and available? This is for my personal memory(X as S3)

 @OpenAI's o3 and o4-mini have just dropped into the Arena!
@OpenAI's o3 and o4-mini have just dropped into the Arena!











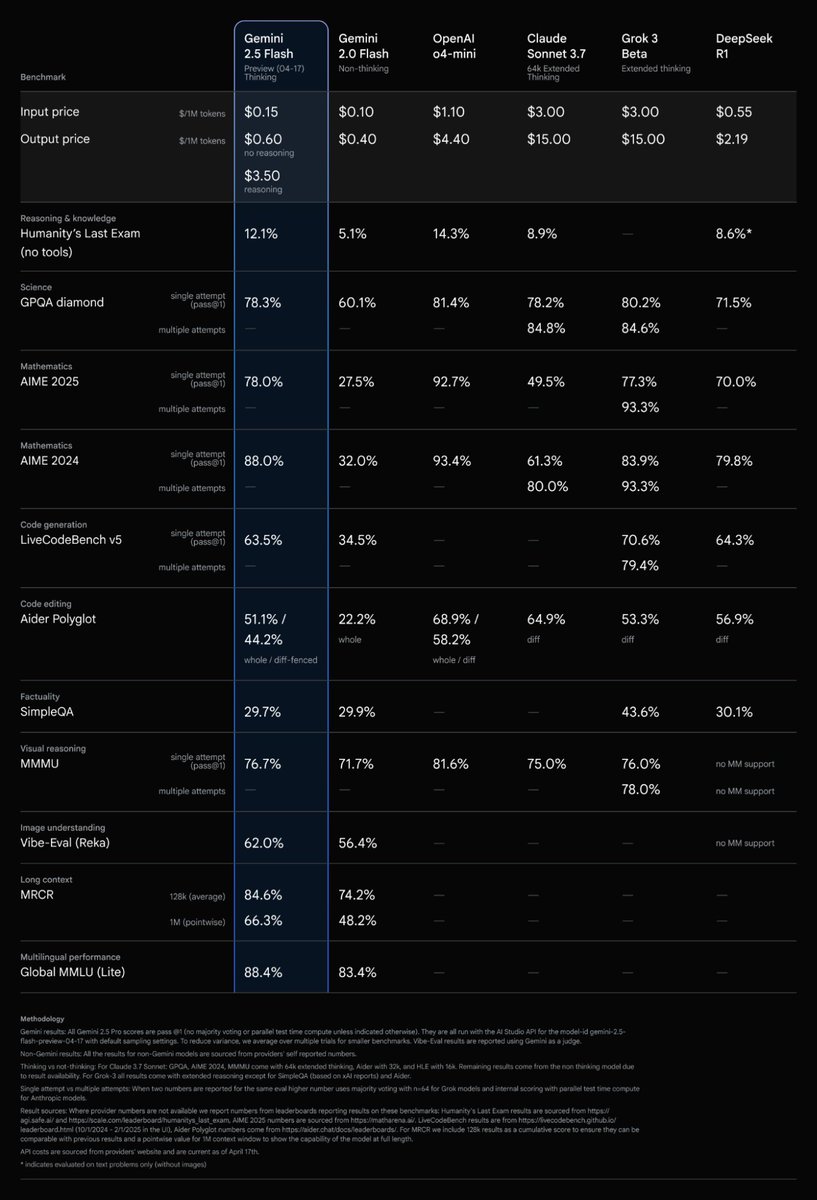
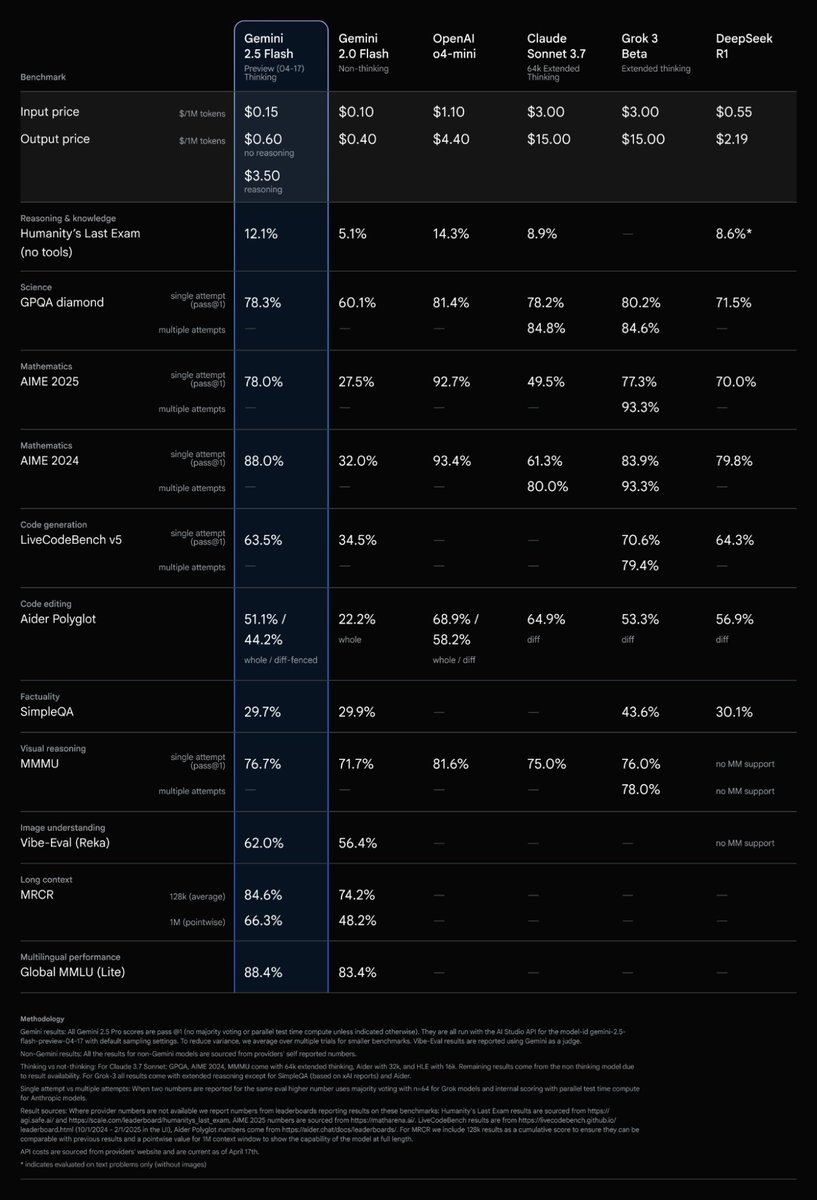
 1 Million multimodal input context for text, image, video, audio, and pdf
1 Million multimodal input context for text, image, video, audio, and pdf $0.15 1M input tokens; $0.6 or $3.5 (thinking on) per million output tokens (thinking tokens are billed as output tokens)
$0.15 1M input tokens; $0.6 or $3.5 (thinking on) per million output tokens (thinking tokens are billed as output tokens) Knowledge cut of January 2025
Knowledge cut of January 2025 Rate limits - Free 10 RPM 500 req/day
Rate limits - Free 10 RPM 500 req/day Outperforms 2.0 Flash on every benchmark
Outperforms 2.0 Flash on every benchmark





 速報: Gemini 2.5 Flash登場:AIの思考を自在に操る新時代モデル
速報: Gemini 2.5 Flash登場:AIの思考を自在に操る新時代モデル
 Gemini 2.5 Flash Thinking 24k
Gemini 2.5 Flash Thinking 24k