1/1
Meet our “Tiny Giant.” Our 1B parameter model xLAM-1B is now the best micro model for function calling, outperforming models 7x its size, including GPT-3.5 & Claude. On-device agentic AI is here. #AIResearch #SLM #TinyButMighty
1/1
I've just uploaded llamafiles for Google's new Gemma2 language model. This is the 27B model that folks have been saying is better than 70B and 104B models like LLaMA3 and Command-R+. People are even saying it's better than the original GPT4! Now you can run it air-gapped on your own computer, using a single file.
Your ./gemma-2-27b-it.Q6_K.llamafile is 22gb and we put a lot of work into making sure it produces outputs consistent with Google's hosted version. It's great for coding, roleplaying, admiring the quality of Google engineering, and more.
The tradeoff is that license is a bit cray. It's not open source. Like the Cohere license, Gemma's license is about as bad as they come. Its list of unacceptable uses is unacceptably broad. The terms of the license can be changed by Google at any time. They also refer to this as a Gemma Service (which they don't define) and say they reserve the right to "remotely" disable it if you violate the agreement.
It's totally a good look for the one company on Earth that has a backdoor into literally everything I own to remind me they might execute Order 66 with Chrome and hack into my computer to remotely disable the floating point array file I just downloaded.
When Gemma v1 was released back in February, we saw how certain Googlers responsible for RLHF training brought great shame and embarrassment to everyone in AI who cares about safety. Perhaps Google's legal team deserves a closer look too.
For the past couple of years, innovation has been accelerating in new materials development. And a new French startup called Altrove plans to play a role
techcrunch.com
Altrove uses AI models and lab automation to create new materials
For the past couple of years, innovation has been accelerating in new materials development. And a new French startup called Altrove plans to play a role in this innovation cycle. The deep tech startup has already raised €3.7 million (around $4 million at current exchange rates).
If you’re interested in new materials development, you may have noticed that several teams have shared important breakthroughs with the research community when it comes to materials prediction.
“Historically, over the last 50 years, R&D to find new materials has advanced at a very slow pace,” Altrove co-founder and CEO Thibaud Martin told TechCrunch. There have been several bottlenecks. And an important one has been the starting point — how can you predict if materials made out of a handful of elements can theoretically exist?
When you assemble two different chemical elements, there are tens of thousands of possibilities. When you want to work with three different elements, there are tens of thousands of combinations. With four elements, you get millions of possibilities.
Teams working for DeepMind, Microsoft, Meta or Orbital Materials have been developing artificial intelligence models to overcome calculation constraints and predict new materials that could potentially exist in a stable state. “More stable materials have been predicted in the last nine months than in the previous 49 years,” Martin said.
But solving this bottleneck is just one part of the equation. Knowing that new materials can exist isn’t enough when it comes to making new materials. You have to come up with the recipe.
“A recipe isn’t just about what you put together. It’s also about the proportions, at what temperature, in what order, for how long. So there are lots of factors, lots of variables involved in how you make new materials,” Martin said.
Altrove is focusing on inorganic materials and starting with rare earth elements more specifically. There’s a market opportunity here with rare earth elements because they are hard to source, pricing greatly varies and they often come from China. Many companies try to rely less on China as part of their supply chain to avoid regulatory uncertainties.
Creating an automated iteration loop
The company doesn’t invent new materials from scratch but it selects interesting candidates out of all the new materials that have been predicted. Altrove then uses its own AI models to generate potential recipes for these materials.
Right now, the company tests these recipes one by one and produces a tiny sample of each material. After that, Altrove has developed a proprietary characterization technology that uses an X-ray diffractometer to understand if the output material performs as expected.
“It sounds trivial but it’s actually very complicated to check what you’ve made and understand why. In most cases, what you’ve made isn’t exactly what you were looking for in the first place,” Martin said.
This is where Altrove shines, as the company’s co-founder and CTO Joonatan Laulainen has a PhD in materials science and is an expert in characterization. The startup owns IP related to characterization.
Learning from the characterization step to improve your recipe is key when it comes to making new materials. That’s why Altrove wants to automate its lab so that it can test more recipes at once and speed up the feedback loop.
“We want to build the first high throughput methodology. In other words, pure prediction only takes you 30% of the way to having a material that can really be used industrially. The other 70% involves iterating in real life. That’s why it’s so important to have an automated lab because you increase the throughput and you can parallelize more experiments,” Martin said.
Altrove defines itself as a hardware-enabled AI company. It thinks it will sell licenses for its newly produced materials or make those materials itself with third-party partners. The company raised €3.7 million in a round led by Contrarian Ventures with Emblem also participating. Several business angels also invested in the startup, such as Thomas Clozel (Owkin CEO), Julien Chaumond (Hugging Face CTO) and Nikolaj Deichmann (3Shape founder).
The startup draws inspiration from biotech companies that have turned to AI to find new drugs and treatments — but this time for new materials. Altrove plans to build its automated lab by the end of the year and sell its first asset within 18 months.
Figma CEO Dylan Field says the company will temporarily disable its “Make Design” AI feature that was said to be ripping off the designs of Apple’s own Weather app. The problem was first spotted by Andy Allen, the founder of NotBoring Software, which makes a suite of apps that includes a popular, skinnable Weather app and other utilities. He found by testing Figma’s tool that it would repeatedly reproduce Apple’s Weather app when used as a design aid.
Allen had taken to X, formerly Twitter, to accuse Figma of “heavily” training its tool on existing apps — an accusation Field now denies.
The Make Design feature is available within Figma’s software and will generate UI (user interface) layouts and components from text prompts. “Just describe what you need, and the feature will provide you with a first draft,” is how the company explained it when the feature launched.
The idea was that developers could use the feature to help get their ideas down quickly to begin exploring different design directions and then arrive at a solution faster, Figma said.
The feature was introduced at Figma’s Config conference last week, where the company explained that it was not trained on Figma content, community files or app designs, Field notes in his response on X.
“In other words, the accusations around data training in this tweet are false,” he said.
But in its haste to launch new AI features to remain competitive, the quality assurance work that should accompany new additions seems to have been overlooked.
Mirroring complaints in other industries, some designers immediately argued that Figma’s AI tools, like Make Design, would wipe out jobs by bringing digital design to the mass market, while others countered that AI would simply help to eliminate a lot of the repetitive work that went into design, allowing more interesting ideas to emerge.
Allen’s discovery that Figma essentially seemed to be copying other apps led to increased concern among the design community.
“Just a heads up to any designers using the new Make Designs feature that you may want to thoroughly check existing apps or modify the results heavily so that you don’t unknowingly land yourself in legal trouble,” Allen warned others on X.
Field responded by clarifying that Make Design uses off-the-shelf large language models, combined with “systems we commissioned to be used by these models.” He said the problem with this approach is that the variability is too low.
“Within hours of seeing [Allen’s] tweet, we identified the issue, which was related to the underlying design systems that were created,” Field wrote on X. “Ultimately it is my fault for not insisting on a better QA process for this work and pushing our team hard to hit a deadline for Config.”
Apple was not immediately available for comment. Figma pointed to Field’s tweets as its statement on the matter.
Field says Figma will temporarily disable the Make Design feature until the team is confident it can “stand behind its output.” The feature will be disabled as of Tuesday and will not be re-enabled until Figma has completed a full QA pass on the feature’s underlying design system.
Anthropic is launching a program to fund the development of new types of benchmarks capable of evaluating the performance and impact of AI models, including generative models like its own Claude.
Unveiled on Monday, Anthropic’s program will dole out payments to third-party organizations that can, as the company puts it in a blog post, “effectively measure advanced capabilities in AI models.” Those interested can submit applications to be evaluated on a rolling basis.
“Our investment in these evaluations is intended to elevate the entire field of AI safety, providing valuable tools that benefit the whole ecosystem,” Anthropic wrote on its official blog. “Developing high-quality, safety-relevant evaluations remains challenging, and the demand is outpacing the supply.”
As we’ve highlighted before, AI has a benchmarking problem. The most commonly cited benchmarks for AI today do a poor job of capturing how the average person actually uses the systems being tested. There are also questions as to whether some benchmarks, particularly those released before the dawn of modern generative AI, even measure what they purport to measure, given their age.
The very-high-level, harder-than-it-sounds solution Anthropic is proposing is creating challenging benchmarks with a focus on AI security and societal implications via new tools, infrastructure and methods.
The company calls specifically for tests that assess a model’s ability to accomplish tasks like carrying out cyberattacks, “enhance” weapons of mass destruction (e.g. nuclear weapons) and manipulate or deceive people (e.g. through deepfakes or misinformation). For AI risks pertaining to national security and defense, Anthropic says it’s committed to developing an “early warning system” of sorts for identifying and assessing risks, although it doesn’t reveal in the blog post what such a system might entail.
Anthropic also says it intends its new program to support research into benchmarks and “end-to-end” tasks that probe AI’s potential for aiding in scientific study, conversing in multiple languages and mitigating ingrained biases, as well as self-censoring toxicity.
To achieve all this, Anthropic envisions new platforms that allow subject-matter experts to develop their own evaluations and large-scale trials of models involving “thousands” of users. The company says it’s hired a full-time coordinator for the program and that it might purchase or expand projects it believes have the potential to scale.
“We offer a range of funding options tailored to the needs and stage of each project,” Anthropic writes in the post, though an Anthropic spokesperson declined to provide any further details about those options. “Teams will have the opportunity to interact directly with Anthropic’s domain experts from the frontier red team, fine-tuning, trust and safety and other relevant teams.”
Anthropic’s effort to support new AI benchmarks is a laudable one — assuming, of course, there’s sufficient cash and manpower behind it. But given the company’s commercial ambitions in the AI race, it might be a tough one to completely trust.
In the blog post, Anthropic is rather transparent about the fact that it wants certain evaluations it funds to align with the AI safety classifications it developed (with some input from third parties like the nonprofit AI research org METR). That’s well within the company’s prerogative. But it may also force applicants to the program into accepting definitions of “safe” or “risky” AI that they might not agree with.
A portion of the AI community is also likely to take issue with Anthropic’s references to “catastrophic” and “deceptive” AI risks, like nuclear weapons risks. Many experts say there’s little evidence to suggest AI as we know it will gain world-ending, human-outsmarting capabilities anytime soon, if ever. Claims of imminent “superintelligence” serve only to draw attention away from the pressing AI regulatory issues of the day, like AI’s hallucinatory tendencies, these experts add.
In its post, Anthropic writes that it hopes its program will serve as “a catalyst for progress towards a future where comprehensive AI evaluation is an industry standard.” That’s a mission the many open, corporate-unaffiliated efforts to create better AI benchmarks can identify with. But it remains to be seen whether those efforts are willing to join forces with an AI vendor whose loyalty ultimately lies with shareholders.
Giving AI systems the ability to focus on particular brain regions can make them much better at reconstructing images of what a monkey is looking at from brain recordings
www.newscientist.com
Mind-reading AI recreates what you're looking at with amazing accuracy
Giving AI systems the ability to focus on particular brain regions can make them much better at reconstructing images of what a monkey is looking at from brain recordings
Top row: original images. Second row: images reconstructed by AI based on brain recordings from a macaque. Bottom row: images reconstructed by the AI system without an attention mechanism
Thirza Dado et al.
Artificial intelligence systems can now create remarkably accurate reconstructions of what someone is looking at based on recordings of their brain activity. These reconstructed images are greatly improved when the AI learns which parts of the brain to pay attention to.
“As far as I know, these are the closest, most accurate reconstructions,” says Umut Güçlü at Radboud University in the Netherlands.
In another study, the team used implanted electrode arrays to directly record the brain activity of a single macaque monkey as it looked at AI-generated images. This implant was done for other purposes by another team, says Güçlü’s colleague Thirza Dado, also at Radboud University. “The macaque was not implanted so that we can do reconstruction of perception,” she says. “That is not a good argument to do surgery on animals.”
The team has now reanalysed the data from these previous studies using an improved AI system that can learn which parts of the brain it should pay most attention to.
“Basically, the AI is learning when interpreting the brain signals where it should direct its attention,” says Güçlü. “Of course, that reflects in a way what that brain signal captures in the environment.”
With the direct recordings of brain activity, some of the reconstructed images are now remarkably close to the images that the macaque saw, which were produced by the StyleGAN-XL image-generating AI. However, it is easier to accurately reconstruct AI-generated images than real ones, says Dado, as aspects of the process used to generate the images can be included in the AI learning to reconstruct those images.
With the fMRI scans, there was also a marked improvement when the attention-directing system was used, but the reconstructed images were less accurate than those involving the macaque. This is partly because real photographs were used, but reconstructing images from fMRI scans is also much harder, says Dado. “It’s non-invasive, but very noisy.”
“You can directly stimulate that part that corresponds to a dog, for example,” says Güçlü. “In that way, we can create much richer visual experiences that are closer to those of sighted individuals.”
1/1
In April we published a paper on a new training approach for better & faster LLMs using multi-token prediction. To enable further exploration by researchers, we’ve released pre-trained models for code completion using this approach on
@HuggingFace
Autoregressive models, such as the GPT family, use a fixed order, usually left-to-right, to generate sequences. However, this is not a necessity. In this paper, we challenge this assumption and show that by simply adding a positional encoding for the output, this order can be modulated...
Meta revolutionizes AI with multi-token prediction models, promising faster, more efficient language processing and potentially reshaping the tech landscape while raising questions about AI democratization and ethics.
venturebeat.com
Meta drops AI bombshell: Multi-token prediction models now open for research
We want to hear from you! Take our quick AI survey and share your insights on the current state of AI, how you’re implementing it, and what you expect to see in the future. Learn More
Meta has thrown down the gauntlet in the race for more efficient artificial intelligence. The tech giant released pre-trained models on Wednesday that leverage a novel multi-token prediction approach, potentially changing how large language models (LLMs) are developed and deployed.
This new technique, first outlined in a Meta research paper in April, breaks from the traditional method of training LLMs to predict just the next word in a sequence. Instead, Meta’s approach tasks models with forecasting multiple future words simultaneously, promising enhanced performance and drastically reduced training times.
The implications of this breakthrough could be far-reaching. As AI models balloon in size and complexity, their voracious appetite for computational power has raised concerns about cost and environmental impact. Meta’s multi-token prediction method might offer a way to curb this trend, making advanced AI more accessible and sustainable.
Democratizing AI: The promise and perils of efficient language models
The potential of this new approach extends beyond mere efficiency gains. By predicting multiple tokens at once, these models may develop a more nuanced understanding of language structure and context. This could lead to improvements in tasks ranging from code generation to creative writing, potentially bridging the gap between AI and human-level language understanding.
However, the democratization of such powerful AI tools is a double-edged sword. While it could level the playing field for researchers and smaller companies, it also lowers the barrier for potential misuse. The AI community now faces the challenge of developing robust ethical frameworks and security measures that can keep pace with these rapid technological advancements.
Meta’s decision to release these models under a non-commercial research license on Hugging Face, a popular platform for AI researchers, aligns with the company’s stated commitment to open science. But it’s also a strategic move in the increasingly competitive AI landscape, where openness can lead to faster innovation and talent acquisition.
The initial release focuses on code completion tasks, a choice that reflects the growing market for AI-assisted programming tools. As software development becomes increasingly intertwined with AI, Meta’s contribution could accelerate the trend towards human-AI collaborative coding.
The AI arms race heats up: Meta’s strategic play in the tech battlefield
However, the release isn’t without controversy. Critics argue that more efficient AI models could exacerbate existing concerns about AI-generated misinformation and cyber threats. Meta has attempted to address these issues by emphasizing the research-only nature of the license, but questions remain about how effectively such restrictions can be enforced.
The multi-token prediction models are part of a larger suite of AI research artifacts released by Meta, including advancements in image-to-text generation and AI-generated speech detection. This comprehensive approach suggests that Meta is positioning itself as a leader across multiple AI domains, not just in language models.
As the dust settles on this announcement, the AI community is left to grapple with its implications. Will multi-token prediction become the new standard in LLM development? Can it deliver on its promises of efficiency without compromising on quality? And how will it shape the broader landscape of AI research and application?
The researchers themselves acknowledge the potential impact of their work, stating in the paper: “Our approach improves model capabilities and training efficiency while allowing for faster speeds.” This bold claim sets the stage for a new phase of AI development, where efficiency and capability go hand in hand.
One thing is clear: Meta’s latest move has added fuel to the already blazing AI arms race. As researchers and developers dive into these new models, the next chapter in the story of artificial intelligence is being written in real-time.
Generative AI models don’t process text the same way humans do. Understanding their “token”-based internal environments may help explain some of their strange behaviors — and stubborn limitations.
Most models, from small on-device ones like Gemma to OpenAI’s industry-leading GPT-4o, are built on an architecture known as the transformer. Due to the way transformers conjure up associations between text and other types of data, they can’t take in or output raw text — at least not without a massive amount of compute.
So, for reasons both pragmatic and technical, today’s transformer models work with text that’s been broken down into smaller, bite-sized pieces called tokens — a process known as tokenization.
Tokens can be words, like “fantastic.” Or they can be syllables, like “fan,” “tas” and “tic.” Depending on the tokenizer — the model that does the tokenizing — they might even be individual characters in words (e.g., “f,” “a,” “n,” “t,” “a,” “s,” “t,” “i,” “c”).
Using this method, transformers can take in more information (in the semantic sense) before they reach an upper limit known as the context window. But tokenization can also introduce biases.
Some tokens have odd spacing, which can derail a transformer. A tokenizer might encode “once upon a time” as “once,” “upon,” “a,” “time,” for example, while encoding “once upon a ” (which has a trailing whitespace) as “once,” “upon,” “a,” ” .” Depending on how a model is prompted — with “once upon a” or “once upon a ,” — the results may be completely different, because the model doesn’t understand (as a person would) that the meaning is the same.
Tokenizers treat case differently, too. “Hello” isn’t necessarily the same as “HELLO” to a model; “hello” is usually one token (depending on the tokenizer), while “HELLO” can be as many as three (“HE,” “El,” and “O”). That’s why many transformers fail the capital letter test.
“It’s kind of hard to get around the question of what exactly a ‘word’ should be for a language model, and even if we got human experts to agree on a perfect token vocabulary, models would probably still find it useful to ‘chunk’ things even further,” Sheridan Feucht, a PhD student studying large language model interpretability at Northeastern University, told TechCrunch. “My guess would be that there’s no such thing as a perfect tokenizer due to this kind of fuzziness.”
This “fuzziness” creates even more problems in languages other than English.
Many tokenization methods assume that a space in a sentence denotes a new word. That’s because they were designed with English in mind. But not all languages use spaces to separate words. Chinese and Japanese don’t — nor do Korean, Thai or Khmer.
A 2023 Oxford study found that, because of differences in the way non-English languages are tokenized, it can take a transformer twice as long to complete a task phrased in a non-English language versus the same task phrased in English. The same study — and another — found that users of less “token-efficient” languages are likely to see worse model performance yet pay more for usage, given that many AI vendors charge per token.
Tokenizers often treat each character in logographic systems of writing — systems in which printed symbols represent words without relating to pronunciation, like Chinese — as a distinct token, leading to high token counts. Similarly, tokenizers processing agglutinative languages — languages where words are made up of small meaningful word elements called morphemes, such as Turkish — tend to turn each morpheme into a token, increasing overall token counts. (The equivalent word for “hello” in Thai, สวัสดี, is six tokens.)
In 2023, Google DeepMind AI researcher Yennie Jun conducted an analysis comparing the tokenization of different languages and its downstream effects. Using a dataset of parallel texts translated into 52 languages, Jun showed that some languages needed up to 10 times more tokens to capture the same meaning in English.
Beyond language inequities, tokenization might explain why today’s models are bad at math.
Rarely are digits tokenized consistently. Because they don’t really know what numbers are, tokenizers might treat “380” as one token, but represent “381” as a pair (“38” and “1”) — effectively destroying the relationships between digits and results in equations and formulas. The result is transformer confusion; a recent paper showed that models struggle to understand repetitive numerical patterns and context, particularly temporal data. (See: GPT-4 thinks 7,735 is greater than 7,926).
1/1
We will see that a lot of weird behaviors and problems of LLMs actually trace back to tokenization. We'll go through a number of these issues, discuss why tokenization is at fault, and why someone out there ideally finds a way to delete this stage entirely.
So, tokenization clearly presents challenges for generative AI. Can they be solved?
Maybe.
Feucht points to “byte-level” state space models like MambaByte, which can ingest far more data than transformers without a performance penalty by doing away with tokenization entirely. MambaByte, which works directly with raw bytes representing text and other data, is competitive with some transformer models on language-analyzing tasks while better handling “noise” like words with swapped characters, spacing and capitalized characters.
Models like MambaByte are in the early research stages, however.
“It’s probably best to let models look at characters directly without imposing tokenization, but right now that’s just computationally infeasible for transformers,” Feucht said. “For transformer models in particular, computation scales quadratically with sequence length, and so we really want to use short text representations.”
Barring a tokenization breakthrough, it seems new model architectures will be the key.
The advancement of function-calling agent models requires diverse, reliable, and high-quality datasets. This paper presents APIGen, an automated data generation pipeline designed to produce verifiable high-quality datasets for function-calling applications. We leverage APIGen and collect 3673 executable APIs across 21 different categories to generate diverse function-calling datasets in a scalable and structured manner. Each data in our dataset is verified through three hierarchical stages: format checking, actual function executions, and semantic verification, ensuring its reliability and correctness. We demonstrate that models trained with our curated datasets, even with only 7B parameters, can achieve state-of-the-art performance on the Berkeley Function-Calling Benchmark, outperforming multiple GPT-4 models. Moreover, our 1B model achieves exceptional performance, surpassing GPT-3.5-Turbo and Claude-3 Haiku. We release a dataset containing 60,000 high-quality entries, aiming to advance the field of function-calling agent domains.
Framework
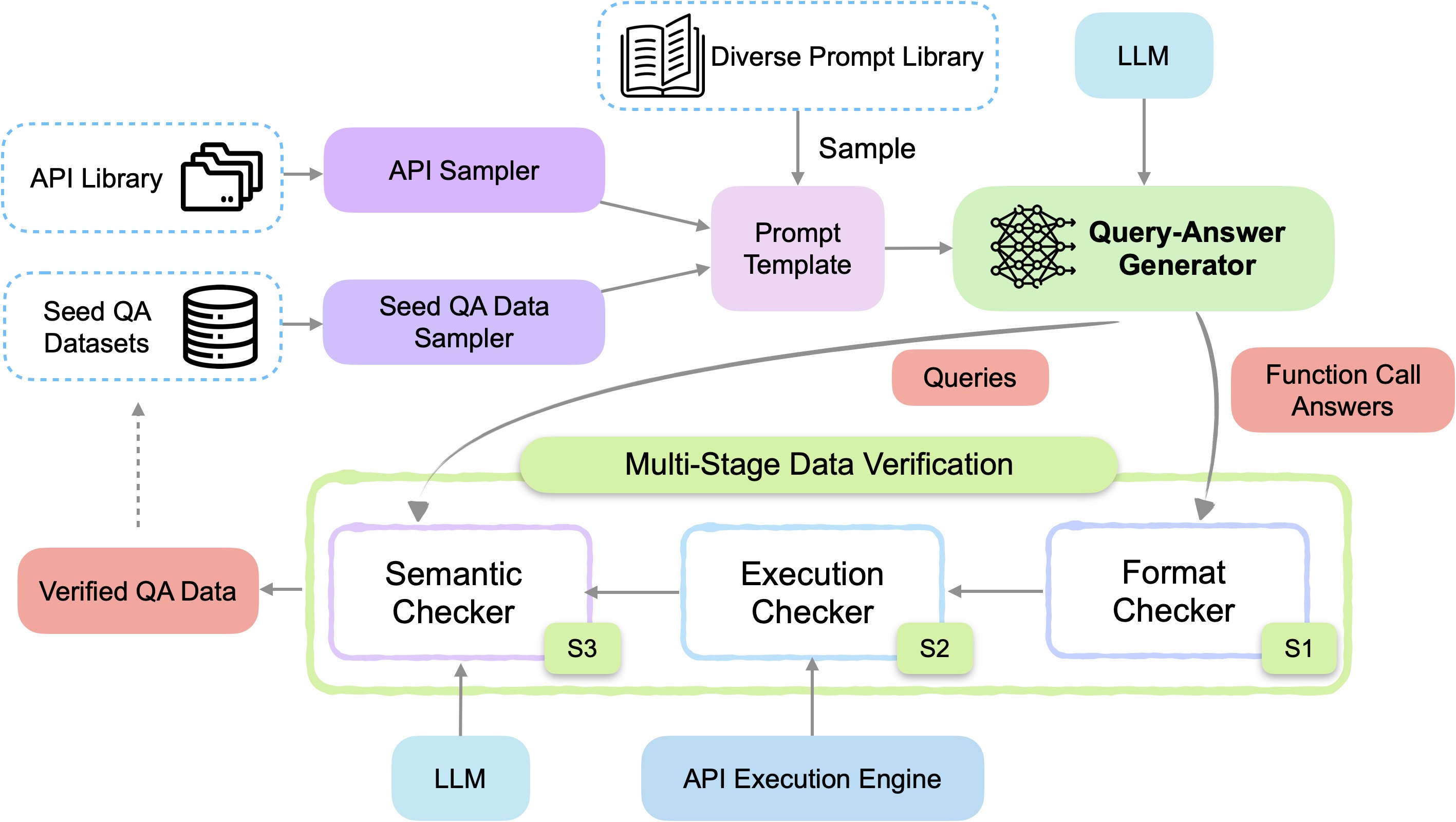
This section introduces the detailed design of APIGen, an Automated Pipeline for Generating verifiable and diverse function-calling datasets. Our framework is designed with three key factors in mind: data quality, data diversity, and collection scalability. We achieve these through the key modules shown in the figure below: the multi-stage data verification process ensures data quality, the seed QA (query-answer) data sampler, API sampler, and various prompt templates ensure diversity, and our structured modular design using a unified format enables the system to scale to diverse API sources, including but not limited to Python functions and representational state transfer (REST) APIs.
Data Generation Overview
The data generation process using the APIGen framework begins by sampling one or more APIs and example query-answer (QA) pairs from the library, then formatting them into a standardized JSON format (see figure below for examples). A prompt template is selected based on the desired data generation objectives, which steers the LLM in generating relevant query-answer pairs. Each answer in the generated pairs is a function call formatted in JSON.
The adoption of a standardized JSON format for APIs, function calls, and generator outputs provides several advantages. Firstly, it establishes a structural way to verify whether the generator's output contains all necessary fields. Outputs that fail to comply with these format requirements are discarded. Secondly, the JSON structure enables efficient checking of function calls for correct parsing and validity of arguments. Calls that include arguments not present in the API library or hallucinate non-existent functions are excluded, enhancing the overall quality of the dataset. Another key benefit is the scalability it enables. With this uniform format, APIGen can easily incorporate data from diverse sources (Python functions, REST APIs, etc) by developing format converters that adapt them into these basic JSON elements, without modifying other core components, such as the prompting library, making the framework highly adaptable and extensible.
The generated function calls are subjected to a multi-stage verification process to ensure their correctness and relevance. First, a format checker verifies correct JSON formatting and parseability. Next, the API execution engine processes the calls and sends the results and queries to a semantic checker, another LLM, which assesses alignment between the function calls, execution results, and query objectives. Data points passing all stages are added back to the seed dataset as high-quality examples to enhance future generation diversity.
Multi-Stage Data Verification
Prioritizing quality is crucial, as previous research has shown that small amounts of high-quality fine-tuning data can substantially enhance model performance on domain-specific tasks. This motivates our multi-stage dataset verification process to align large language models effectively.
The key insight driving our framework design is that, unlike synthetic chat data which can be difficult to evaluate, function-calling answers can be directly executed via their corresponding APIs. This enables checking if the output API and parameters' formats are correct, if the generated API calls are executable, and if execution results match the query's intent, etc. Based on this observation, we propose a three-stage verification process:
Stage 1: Format Checker: This stage performs sanity checks to filter out poorly formatted or incomplete data. The LLM output must strictly follow a JSON format with the "query" and "answer" fields. Additionally, the function calls are checked for correct JSON parsing and valid arguments. Generated calls whose arguments or functions are not present in the given APIs are eliminated to reduce hallucination and improve data quality.
Stage 2: Execution Checker: Well-formatted function calls from Stage 1 are executed against the appropriate backend. Unsuccessful executions are filtered out, and fine-grained error messages are provided for failures.
Stage 3: Semantic Checker: Successful Stage 2 execution results, available functions, and the generated query are formatted and passed to another LLM to assess if the results semantically align with the query's objective. Data points that pass all three verification stages are regarded as high-quality and added back to improve future diverse data generation.
Methods to Improve Dataset Diversity
Encouraging diversity in training datasets is crucial for developing robust function-calling agents that can handle a wide range of real-world scenarios. In APIGen, we promote data diversity through multiple perspectives, including query style diversity, sampling diversity, and API diversity.
Query Style Diversity: APIGen's dataset is structured into four main categories: simple, multiple, parallel, and parallel multiple, each designed to challenge and enhance the model's capabilities in different usage scenarios. These categories are controlled by corresponding prompts and seed data.
Sampling Diversity: APIGen utilizes a sampling system designed to maximize the diversity and relevance of the generated datasets. This includes API Sampler, Example Sampler, and Prompt Sampler.
In APIGen, the number of examples and APIs sampled for each dataset iteration is randomly chosen from a predefined range. This randomization enhances dataset variability by preventing repetitive patterns and ensuring a broad coverage of scenarios.
Dataset API Sources
To ensure a high-quality and diverse dataset, we focused on collecting real-world APIs that could be readily executed and came with thorough documentation. We primarily sourced APIs from ToolBench, a comprehensive tool-use dataset that includes 16,464 REST APIs across 49 coarse-grained categories from RapidAPI Hub. This hub is a leading marketplace featuring a vast array of developer-contributed APIs.
To further enhance the usability and quality of the APIs, we perform the following filtering and cleaning procedures on the ToolBench dataset:
Data Quality Filtering: We remove APIs with incorrectly parsed documentation and those lacking required or optional parameters. APIs requiring no parameters were excluded to maintain the challenge level appropriate for our dataset needs.
API Accessibility Testing: We tested API accessibility by making requests to each endpoint using example parameters provided in the dataset and through the Stable Toolbench server. APIs that could not be executed or returned errors, such as timeouts or invalid endpoints, were discarded.
Docstring Regeneration: To improve the quality of API documentation, we regenerated docstrings for the APIs that have noisy and unusable descriptions.
After cleaning, we obtain 3,539 executable REST APIs with good documentation. Additionally, we incorporated Python functions as another API type, inspired by the executable evaluation categories of the Berkeley function-calling benchmark. We collected 134 well-documented Python functions covering diverse fields such as mathematics, finance, and data management. Sample API examples are provided in the supplementary material.
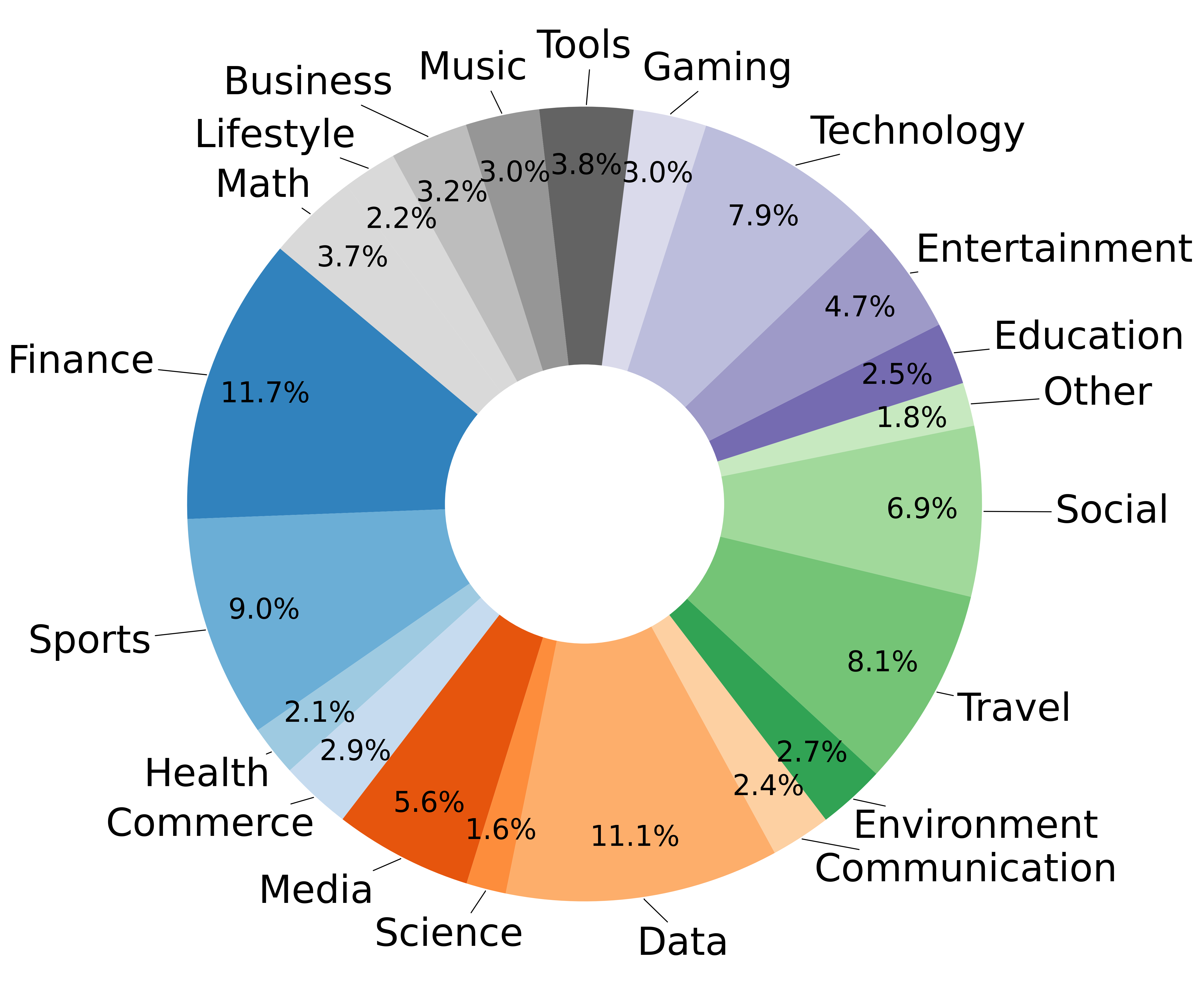
The original ToolBench dataset contained semantically overlapping categories such as Finance and Financial. We consolidated these into 21 distinct categories to ensure clarity and balance across the dataset. Figure illustrates the distribution of the 3,673 executable APIs across these redefined categories, spanning sectors like technology, social sciences, education, and sports. This diverse collection of APIs provides a strong foundation for synthetic data generation and is a valuable asset for ensuring data quality and reliability.
Collection Setup and Dataset Details
To validate the effectiveness of the APIGen framework, we generated datasets targeting various query styles. We utilized several base LLMs for data generation, including DeepSeek-V2-Chat (236B), DeepSeek-Coder-33B-Inst, Mixtral-8x22B-Inst, and Mixtral-8x7B-Inst. For each model, our target was to generate 40,000 data points by sampling different combinations of APIs, seed data, and prompt templates. To foster diversity in the generated responses, we set the generation temperature to 0.7 across all models. Examples of the prompt templates and APIs used are provided in the supplementary materials for reference.
Table below presents statistics for the data generation process with different models, including the total verified data point count and the number of filtered data points at each verification stage. The filtering process successfully removes many low-quality data points due to formatting issues, execution errors, or failure to pass the semantic check. The first two stages, format checker and execution checker, typically filter out the majority of low-quality data. These data points often have infeasible argument ranges, incorrect types, missing required parameters, or more severe issues such as hallucination of function calls or parameters. Our systematic verification process provides a rigorous way to reduce the occurrence of these situations.
Model
Verified Data
Fail Format
Fail Execution
Fail Semantic
Pass Rate
DeepSeek-Coder-33B-Inst
13,769
4,311
15,496
6,424
34.42%
Mixtral-8x7B-Inst
15,385
3,311
12,341
7,963
38.46%
Mixtral-8x22B-Inst
26,384
1,680
5,073
6,863
65.96%
DeepSeek-V2-Chat (236B)
33,659
817
3,359
2,165
84.15%
Filtering statistics for the generated datasets using different base LLMs.
The semantic checker also plays a crucial role in filtering generated data that does not align with the query's objectives. For instance, if a user's query contains multiple requests, but the returned results only address one, or if the generated function-call data and execution results do not match the user's query, the data point will be filtered out. Including these data points in the training set for model training could potentially harm the performance, as demonstrated in the experiments.
We observe that stronger models like DeepSeek-V2-Chat and Mixtral-8x22B-Inst have better format-following capabilities and higher pass rates, while the two relatively smaller models have a much higher likelihood of producing data that cannot be executed. This suggests that when using weaker models to generate data, a strict verification process is recommended to filter out low-quality data.
We are releasing approximately 60,000 high-quality function-calling datasets generated from the two strongest models: Mixtral-8x22B-Inst and DeepSeek-V2-Chat (236B). These datasets include all the query styles mentioned and cover a wide range of practical situations, with 3,673 diverse APIs across 21 categories. Each data point has been verified using real-world APIs to ensure its validity and usefulness. By making this dataset publicly available, we aim to benefit the research community and facilitate future work in this area.
A.I generated explanation: **What's the problem?**
Creating good datasets for training AI models that can call functions (like APIs) is hard. These datasets need to be diverse, reliable, and high-quality.
**What's the solution?**
The authors created a system called APIGen, which is an automated pipeline for generating verifiable and diverse function-calling datasets. APIGen uses a combination of natural language processing (NLP) and machine learning to generate datasets that are high-quality and diverse.
**How does APIGen work?**
APIGen has three main components:
1. **Data Generation**: APIGen uses large language models (LLMs) to generate function-calling datasets. These LLMs are trained on a large corpus of text data and can generate human-like text.
2. **Multi-Stage Verification**: APIGen uses a three-stage verification process to ensure the generated datasets are high-quality and correct. The stages are:
* **Format Checker**: Checks if the generated data is in the correct format.
* **Execution Checker**: Checks if the generated function calls can be executed successfully.
* **Semantic Checker**: Checks if the generated function calls align with the user's query objectives.
3. **Dataset Collection**: APIGen collects APIs from various sources, including ToolBench, a comprehensive tool-use dataset. The APIs are filtered and cleaned to ensure they are executable and have good documentation.
**What are the results?**
The authors generated datasets using APIGen and trained AI models on these datasets. The results show that the models trained on APIGen datasets outperform other models on the Berkeley Function-Calling Benchmark. The authors are releasing a dataset of 60,000 high-quality function-calling datasets to the research community.
**Why is this important?**
APIGen provides a scalable and structured way to generate high-quality datasets for function-calling applications. This can help advance the field of AI research and improve the performance of AI models in real-world scenarios.
1/12
LLM agents have demonstrated promise in their ability to automate computer tasks, but face challenges with multi-step reasoning and planning. Towards addressing this, we propose an inference-time tree search algorithm for LLM agents to explicitly perform exploration and multi-step planning in interactive web environments.
It is the first tree search algorithm for LLM agents that shows effectiveness on realistic and complex web environments: on the challenging VisualWebArena benchmark, applying our search algorithm on top of a GPT-4o agent yields a 39.7% relative increase in success rate compared to the same baseline without search, setting a state-of-the-art success rate of 26.4%. On WebArena, search also yields a 28.0% relative improvement over a baseline agent, setting a competitive success rate of 19.2%.
2/12
We show in ablations that spending more compute (increasing the search budget) improves success rate. Even doing a small amount of search (c=5) substantially improves over the baseline (24.5% to 32.0%), and using larger search budgets achieves even better results:
3/12
We also found that increasing the size of the search tree is essential: we need to expand search trees along both the depth (d) and breadth (b). Our best results are achieved with search trees of maximum depth 5 and branching factor 5:
4/12
Search also provides consistent improvements across a diverse set of sites in (Visual)WebArena, introducing a relative improvement on certain sites by as much as 50%!
5/12
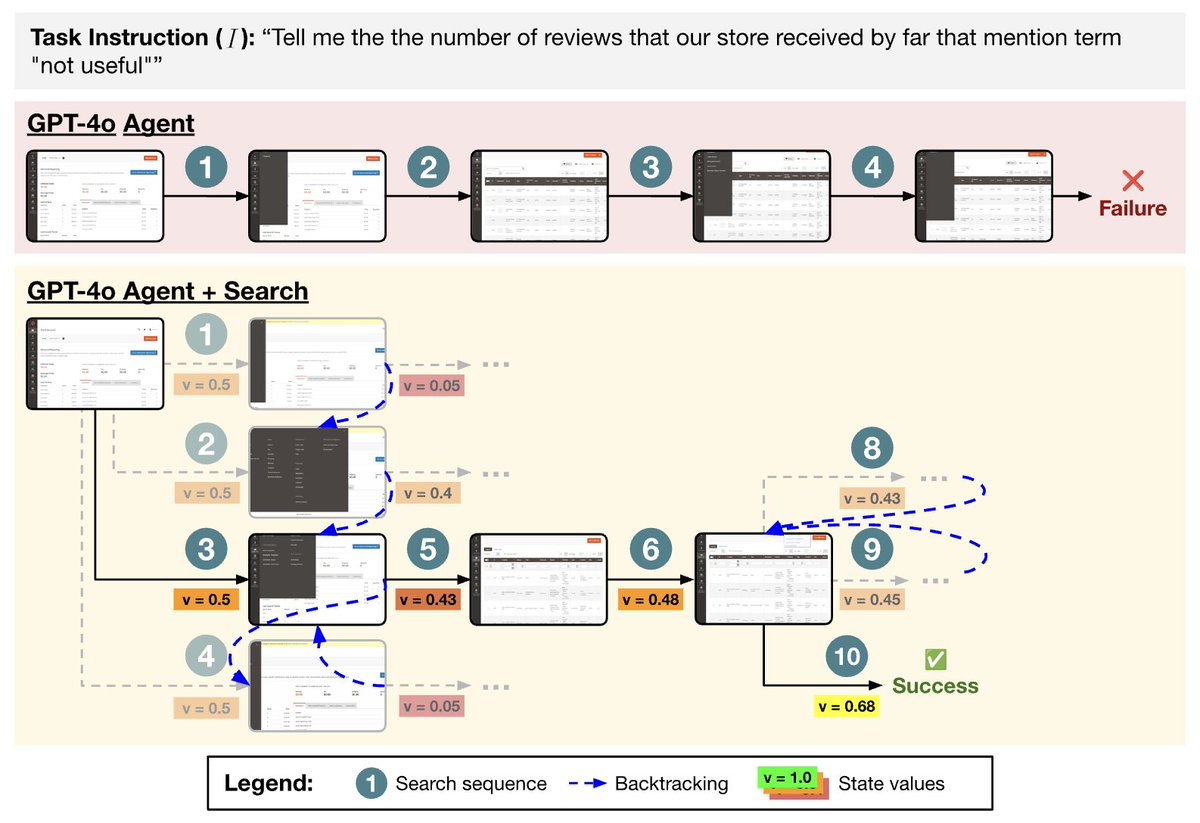
Search can improve the robustness of agents by filtering out bad actions. Shown here is a trajectory where greedily picking the first sampled actions would have led to a failure (the path in the first row). Search avoids this by exploring and pruning less promising paths.
6/12
Here is another task on the WebArena CMS environment, where performing more exploration through search helps the model to identify a trajectory that is likely to be more successful:
7/12
Our method is compatible with any baseline LLM agents, and demonstrates gains for both gpt-4o and Llama-3.
I'm very excited to see how far we can scale search: this will be a key component for LLM agents to allow us to expend more inference-time compute for stronger results.
11/12
Congrats JY!! On the reading list for this week - I think the premise of the importance of search/exploration makes a ton of sense, excited about the great execution by u and the team!
Paper Title: Tree Search for Language Model Agents
Few pointers from the paper
Autonomous agents powered by language models (LMs) have demonstrated promise in their ability to perform decision-making tasks such as web automation.
However, a fundamental challenge remains: LMs, primarily optimized for natural language understanding and generation, struggle with multi-step reasoning, planning, and using environmental feedback when attempting to solve realistic computer tasks.
Towards addressing this, authors of this paper have proposed an inference-time search algorithm for LM agents to explicitly perform exploration and multi-step planning in interactive web environments. Their approach is a form of best-first tree search that operates within the actual environment space, and is complementary with most existing state-of-the-art agents.
It is the first tree search algorithm for LM agents that shows effectiveness on realistic web tasks. On the challenging VisualWebArena benchmark, applying their search algorithm on top of a GPT-4o agent yields a 39.7% relative increase in success rate compared to the same baseline without search, setting a state-of-the-art success rate of 26.4%.
On WebArena, search also yields a 28.0% relative improvement over a baseline agent, setting a competitive success rate of 19.2%. Their experiments highlight the effectiveness of search for web agents, and they demonstrated that performance scales with increased test-time compute.
Organization: @CarnegieMellon
Paper Authors: @kohjingyu , @McaleerStephen , @dan_fried , @rsalakhu
Autonomous agents powered by language models (LMs) have demonstrated promise in their ability to perform decision-making tasks such as web automation. However, a key limitation remains: LMs, primarily optimized for natural language understanding and generation, struggle with multi-step reasoning, planning, and using environmental feedback when attempting to solve realistic computer tasks. Towards addressing this, we propose an inference-time search algorithm for LM agents to explicitly perform exploration and multi-step planning in interactive web environments. Our approach is a form of best-first tree search that operates within the actual environment space, and is complementary with most existing state-of-the-art agents. It is the first tree search algorithm for LM agents that shows effectiveness on realistic web tasks. On the challenging VisualWebArena benchmark, applying our search algorithm on top of a GPT-4o agent yields a 39.7% relative increase in success rate compared to the same baseline without search, setting a state-of-the-art success rate of 26.4%. On WebArena, search also yields a 28.0% relative improvement over a baseline agent, setting a competitive success rate of 19.2%. Our experiments highlight the effectiveness of search for web agents, and we demonstrate that performance scales with increased test-time compute. We conduct a thorough analysis of our results to highlight improvements from search, limitations, and promising directions for future work. Our code and models are publicly released at this https URL.
General Video Game Playing (GVGP) is a field of Artificial Intelligence where agents play a variety of real-time video games that are unknown in advance. This limits the use of domain-specific heuristics. Monte-Carlo Tree Search (MCTS) is a search technique for game playing that does not rely on domain-specific knowledge. This paper discusses eight enhancements for MCTS in GVGP; Progressive History, N-Gram Selection Technique, Tree Reuse, Breadth-First Tree Initialization, Loss Avoidance, Novelty-Based Pruning, Knowledge-Based Evaluations, and Deterministic Game Detection. Some of these are known from existing literature, and are either extended or introduced in the context of GVGP, and some are novel enhancements for MCTS. Most enhancements are shown to provide statistically significant increases in win percentages when applied individually. When combined, they increase the average win percentage over sixty different games from 31.0% to 48.4% in comparison to a vanilla MCTS implementation, approaching a level that is competitive with the best agents of the GVG-AI competition in 2015.
This site uses cookies to help personalise content, tailor your experience and to keep you logged in if you register.
By continuing to use this site, you are consenting to our use of cookies.























 Tree Search for Language Model Agents
Tree Search for Language Model Agents




 Paper Alert
Paper Alert  Paper Title: Tree Search for Language Model Agents
Paper Title: Tree Search for Language Model Agents Few pointers from the paper
Few pointers from the paper Autonomous agents powered by language models (LMs) have demonstrated promise in their ability to perform decision-making tasks such as web automation.
Autonomous agents powered by language models (LMs) have demonstrated promise in their ability to perform decision-making tasks such as web automation. Organization: @CarnegieMellon
Organization: @CarnegieMellon  Paper Authors: @kohjingyu , @McaleerStephen , @dan_fried , @rsalakhu
Paper Authors: @kohjingyu , @McaleerStephen , @dan_fried , @rsalakhu  Read the Full Paper here:
Read the Full Paper here:  Project Page:
Project Page:  Code:
Code:  Be sure to watch the attached Demo Video -Sound on
Be sure to watch the attached Demo Video -Sound on 
 Music by Nick Valerson from @pixabay
Music by Nick Valerson from @pixabay  ?
? QT and teach your network something new
QT and teach your network something new , @NaveenManwani17 , for the latest updates on Tech and AI-related news, insightful research papers, and exciting announcements.
, @NaveenManwani17 , for the latest updates on Tech and AI-related news, insightful research papers, and exciting announcements.