Hugging Face is hoping to lower the barrier to entry for developing AI apps.

www.theverge.com
Hugging Face is sharing $10 million worth of compute to help beat the big AI companies
ZeroGPU gives everyone the chance to create AI apps without the burden of GPU costs.
By
Kylie Robison, a senior AI reporter working with The Verge's policy and tech teams. She previously worked at Fortune Magazine and Business Insider.
May 16, 2024, 9:00 AM EDT
3 Comments
Image: The Verge / Getty Images
Hugging Face, one of the biggest names in machine learning, is committing $10 million in free shared GPUs to help developers create new AI technologies. The goal is to help small developers, academics, and startups counter the centralization of AI advancements.
“We are lucky to be in a position where we can invest in the community,” Hugging Face CEO Clem Delangue told
The Verge. Delangue said the investment is possible because Hugging Face is “profitable, or close to profitable” and recently
raised $235 million in funding, valuing the company at $4.5 billion.
Delangue is concerned about AI startups’ ability to compete with the tech giants. Most significant advancements in artificial intelligence — like GPT-4, the algorithms behind Google Search, and Tesla’s Full Self-Driving system — remain hidden within the confines of major tech companies. Not only are these corporations financially incentivized to keep their models proprietary, but with billions of dollars at their disposal for computational resources, they can compound those gains and race ahead of competitors, making it impossible for startups to keep up.
“If you end up with a few organizations who are dominating too much, then it’s going to be harder to fight it later on.”
Hugging Face aims to make state-of-the-art AI technologies accessible to everyone, not just the tech giants. I spoke with Delangue during Google I/O, the tech giant’s flagship conference, where Google executives unveiled numerous AI features for their proprietary products and
even a family of open-source models called Gemma. For Delangue, the proprietary approach is not the future he envisions.
“If you go the open source route, you go towards a world where most companies, most organizations, most nonprofits, policymakers, regulators, can actually do AI too. So, a much more decentralized way without too much concentration of power which, in my opinion, is a better world,” Delangue said.
How it works
Access to compute poses a significant challenge to constructing large language models, often favoring companies like
OpenAI and
Anthropic, which secure deals with cloud providers for substantial computing resources. Hugging Face aims to level the playing field by donating these shared GPUs to the community through a new program called ZeroGPU.
The shared GPUs are accessible to multiple users or applications concurrently, eliminating the need for each user or application to have a dedicated GPU. ZeroGPU will be available via Hugging Face’s Spaces, a hosting platform for publishing apps, which has over 300,000 AI demos created so far on CPU or paid GPU, according to the company.
“It’s very difficult to get enough GPUs from the main cloud providers”
Access to the shared GPUs is determined by usage, so if a portion of the GPU capacity is not actively utilized, that capacity becomes available for use by someone else. This makes them cost-effective, energy-efficient, and ideal for community-wide utilization. ZeroGPU uses Nvidia A100 GPU devices to power this operation — which offer about
half the computation speed of the popular and more expensive H100s.
“It’s very difficult to get enough GPUs from the main cloud providers, and the way to get them—which is creating a high barrier to entry—is to commit on very big numbers for long periods of times,” Delangue said.
Typically, a company would commit to a cloud provider like Amazon Web Services for one or more years to secure GPU resources. This arrangement disadvantages small companies, indie developers, and academics who build on a small scale and can’t predict if their projects will gain traction. Regardless of usage, they still have to pay for the GPUs.
“It’s also a prediction nightmare to know how many GPUs and what kind of budget you need,” Delangue said.
Open-source AI is catching up
With AI rapidly advancing behind closed doors, the goal of Hugging Face is to allow people to build more AI tech in the open.
“If you end up with a few organizations who are dominating too much, then it’s going to be harder to fight it later on,” Delangue said.
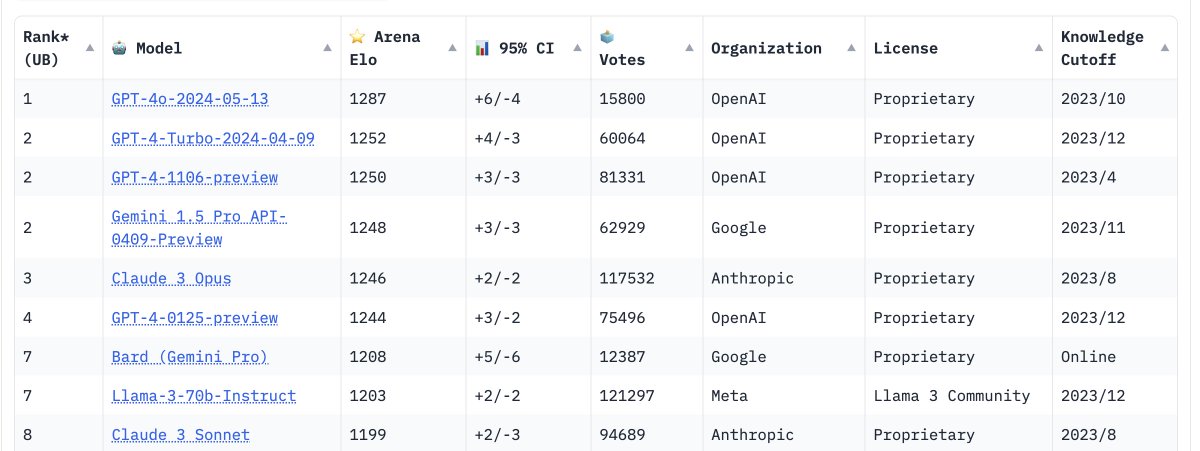
Andrew Reed, a machine learning engineer at Hugging Face,
even spun up an app that visualizes the progress of proprietary and open-source LLMs over time as scored by the
LMSYS Chatbot Arena, which shows the gap between the two inching closer together.
Over 35,000 variations of Meta’s open-source AI model Llama have been shared on Hugging Face since Meta’s first version a year ago, ranging from “quantized and merged models to specialized models in biology and Mandarin,” according to the company.
“AI should not be held in the hands of the few. With this commitment to open-source developers, we’re excited to see what everyone will cook up next in the spirit of collaboration and transparency,” Delangue said in a press release.











/cdn.vox-cdn.com/uploads/chorus_asset/file/25449118/STK267_HUGGING_FACE_E.jpg)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25449118/STK267_HUGGING_FACE_E.jpg "Photo illustration of Clément Delangue of Hugging Face in front of the Hugging Face logo.")










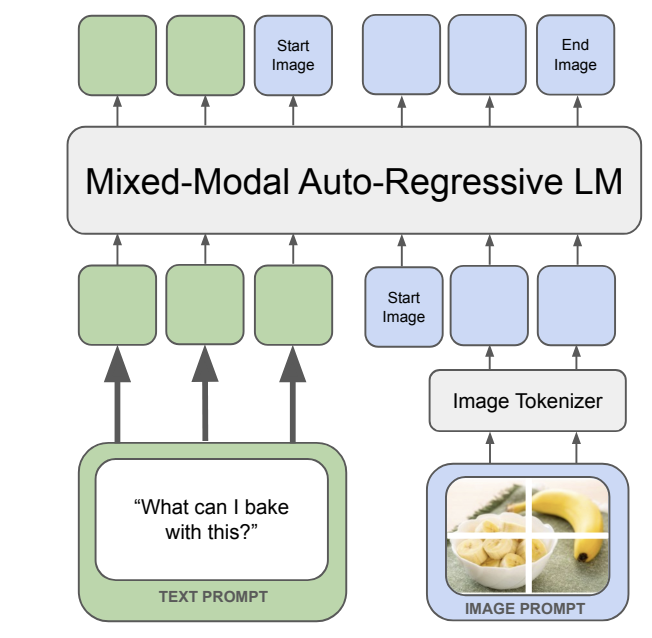

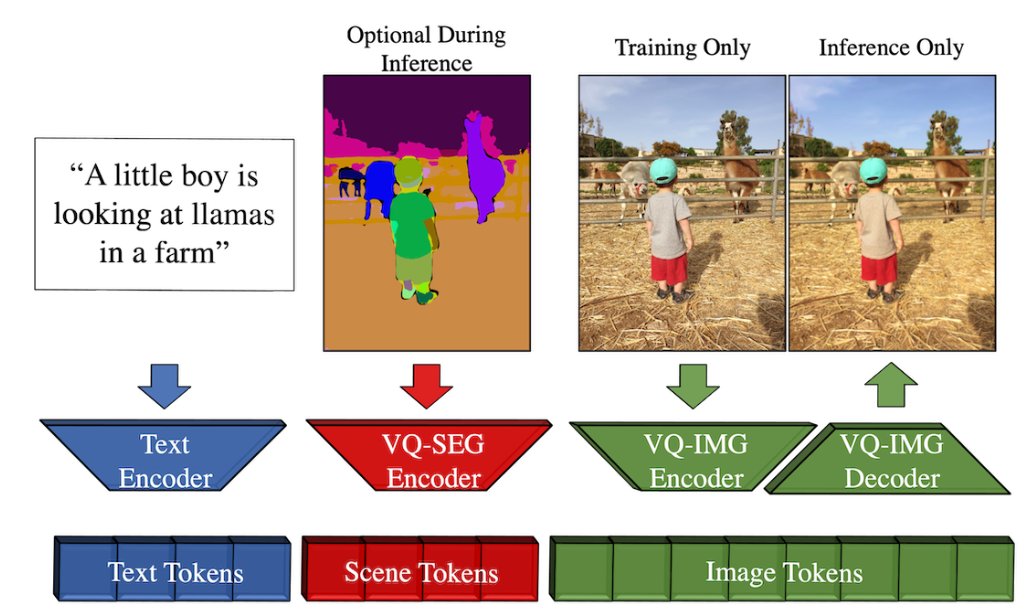



 HuggingFace
HuggingFace