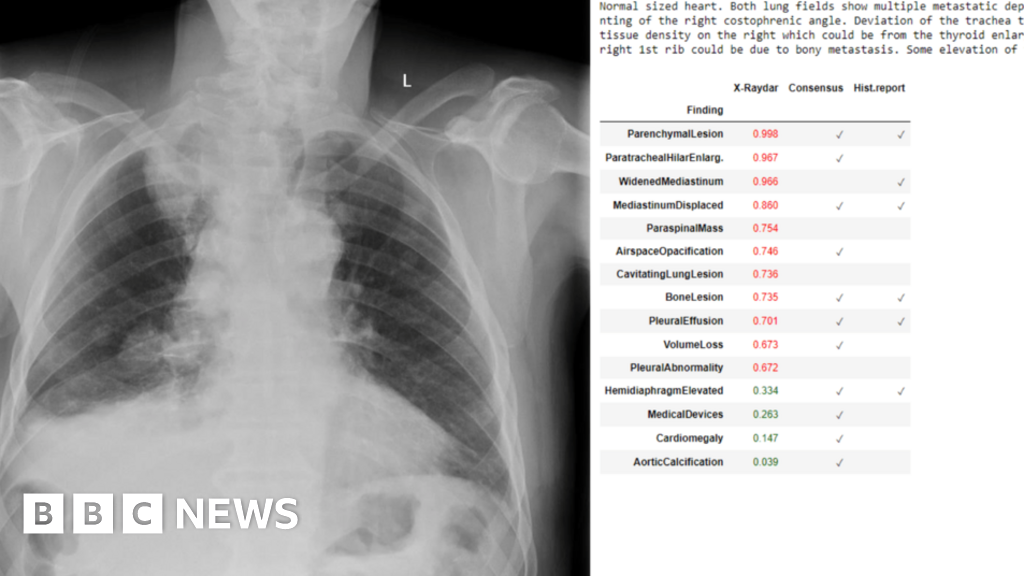
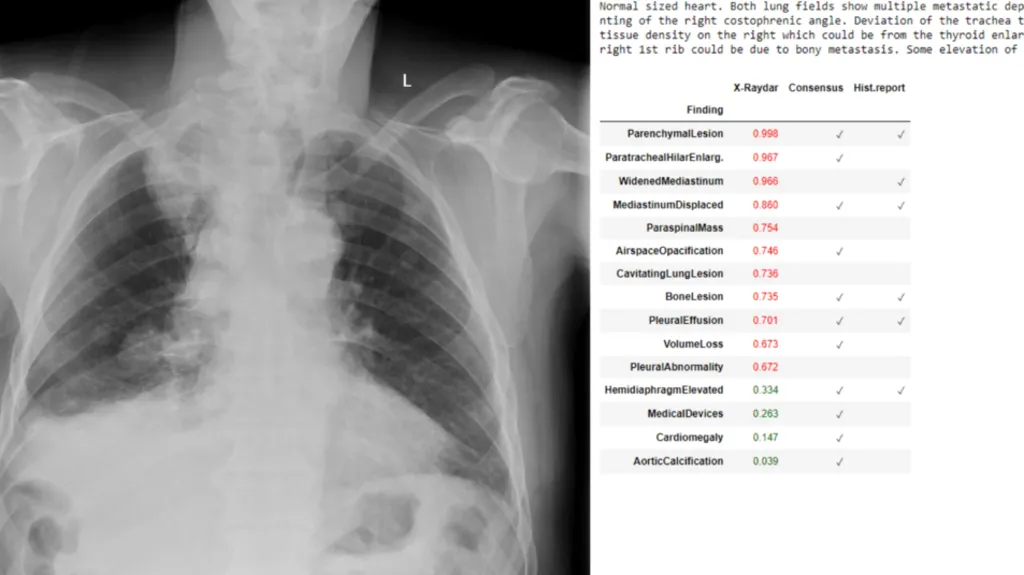
Photorealistic Video Generation with Diffusion Models
Agrim Gupta1,2,*, Lijun Yu2, Kihyuk Sohn2, Xiuye Gu2, Meera Hahn2, Li Fei-Fei1,Irfan Essa2, 3, Lu Jiang2, José Lezama2
1Stanford; 2Google Research; 3Georgia Institute of Teechnology
*Work partially done during an internship at Google.
arXiv PDF More samples
Text-to-Video Examples
Abstract
We present W.A.L.T, a transformer-based approach for photorealistic video generation via diffusion modeling. Our approach has two key design decisions. First, we use a causal encoder to jointly compress images and videos within a unified latent space, enabling training and generation across modalities. Second, for memory and training efficiency, we use a window attention architecture tailored for joint spatial and spatiotemporal generative modeling. Taken together these design decisions enable us to achieve state-of-the-art performance on established video (UCF-101 and Kinetics-600) and image (ImageNet) generation benchmarks without using classifier free guidance. Finally, we also train a cascade of three models for the task of text-to-video generation consisting of a base latent video diffusion model, and two video super-resolution diffusion models to generate videos of 512 x 896 resolution at 8 frames per second.
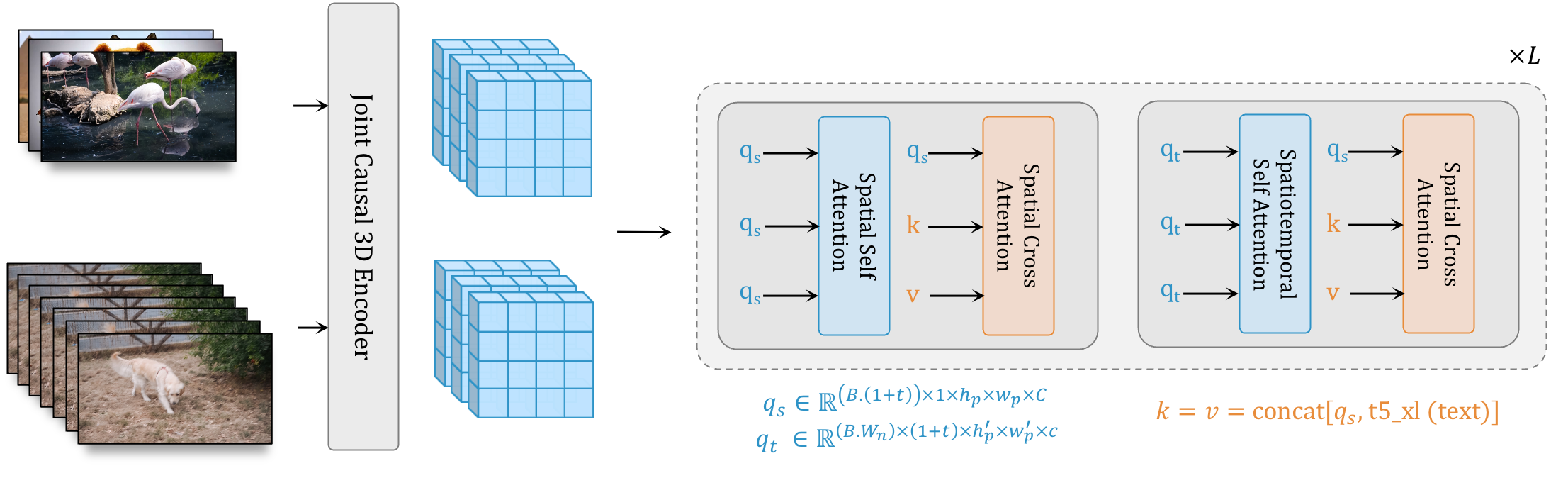
W.A.L.T: We encode images and videos into a shared latent space. The transformer backbone processes these latents with blocks having two layers of window-restricted attention: spatial layers capture spatial relations in both images and video, while spatiotemporal layers model temporal dynamics in videos and passthrough images via identity attention mask. Text conditioning is done via spatial cross-attention.







 and Phi-1.5 (with 1.3B parameters) on common sense reasoning, language understanding, math, coding, and the Bigbench-hard benchmark. Phi-2 outperforms Phi1.5 in all categories. The commonsense reasoning tasks are PIQA, WinoGrande, ARC easy and challenge, and SIQA. The language understanding tasks are HellaSwag, OpenBookQA, MMLU, SQuADv2, and BoolQ. The math task is GSM8k, and coding includes the HumanEval and MBPP benchmarks.")




/2023/12/13/image/png/dvLnZmdtmjtSYuEfkAeYvH2vyNxXxUg0ze05iXXp.jpg "An artist’s impression of the DeepSouth supercomputer")









")