
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Large Language Models News & Discussions
- Thread starter Macallik86
- Start date
More options
Who Replied? :
:  :
: MistralLite Model
MistralLite is a fine-tuned Mistral-7B-v0.1 language model, with enhanced capabilities of processing long context (up to 32K tokens). By utilizing an adapted Rotary Embedding and sliding window during fine-tuning, MistralLite is able to perform significantly better on several long context retrieve and answering tasks, while keeping the simple model structure of the original model. MistralLite is useful for applications such as long context line and topic retrieval, summarization, question-answering, and etc. MistralLite can be deployed on a single AWS g5.2x instance with Sagemaker Huggingface Text Generation Inference (TGI) endpoint, making it suitable for applications that require high performance in resource-constrained environments. You can also serve the MistralLite model directly using TGI docker containers. Also, MistralLite supports other ways of serving like vLLM, and you can use MistralLite in Python by using the HuggingFace transformers and FlashAttention-2 library.MistralLite is similar to Mistral-7B-Instruct-v0.1, and their similarities and differences are summarized below:
| Model | Fine-tuned on long contexts | Max context length | RotaryEmbedding adaptation | Sliding Window Size |
|---|---|---|---|---|
| Mistral-7B-Instruct-v0.1 | up to 8K tokens | 32K | rope_theta = 10000 | 4096 |
| MistralLite | up to 16K tokens | 32K | rope_theta = 1000000 | 16384 |
Motivation of Developing MistralLite
Since the release of Mistral-7B-Instruct-v0.1, the model became increasingly popular because its strong performance on a wide range of benchmarks. But most of the benchmarks are evaluated on short context, and not much has been investigated on its performance on long context tasks. Then We evaluated Mistral-7B-Instruct-v0.1 against benchmarks that are specifically designed to assess the capabilities of LLMs in handling longer context. Although the performance of the models on long context was fairly competitive on long context less than 4096 tokens, there were some limitations on its performance on longer context. Motivated by improving its performance on longer context, we finetuned the Mistral 7B model, and produced Mistrallite. The model managed to significantly boost the performance of long context handling over Mistral-7B-Instruct-v0.1. The detailed long context evalutaion results are as below:- Topic Retrieval
Model Name Input lengthInput lengthInput lengthInput lengthInput length2851556883131104413780Mistral-7B-Instruct-v0.1 100%50%2%0%0%MistralLite 100%100%100%100%98% - Line Retrieval
| Model Name | Input length | Input length | Input length | Input length | Input length | Input length |
|---|---|---|---|---|---|---|
3818 | 5661 | 7505 | 9354 | 11188 | 12657 | |
| Mistral-7B-Instruct-v0.1 | 98% | 62% | 42% | 42% | 32% | 30% |
| MistralLite | 98% | 92% | 88% | 76% | 70% | 60% |
Jina AI Launches World's First Open-Source 8K Text Embedding, Rivaling OpenAI
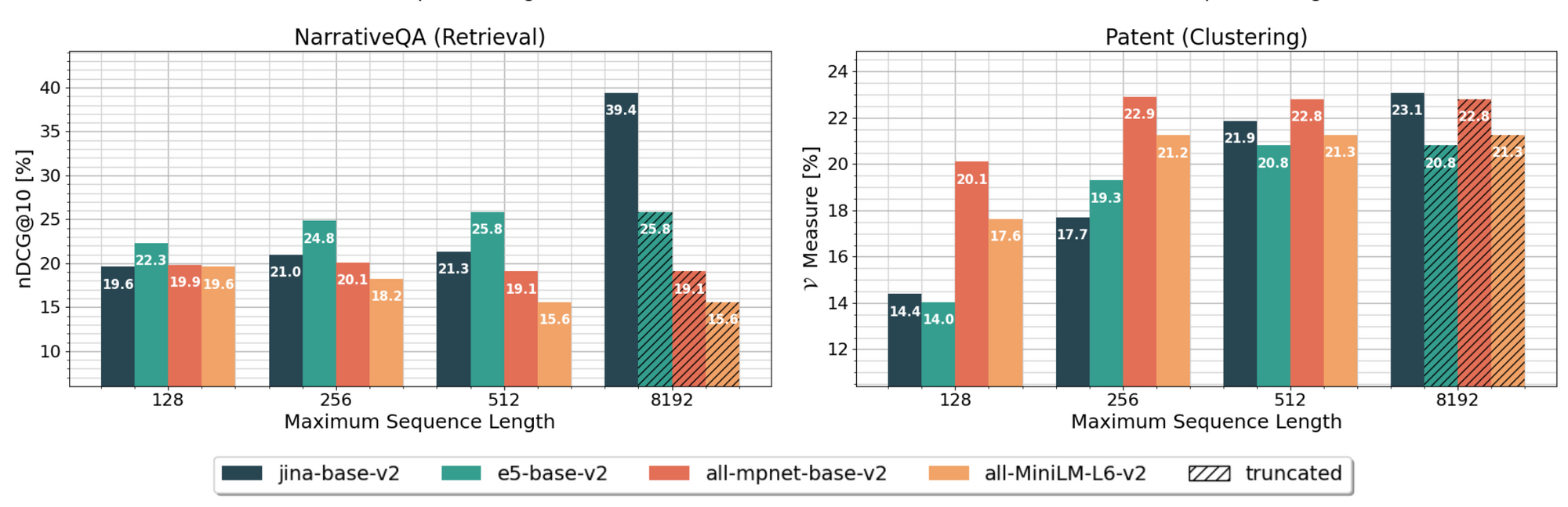
Jina AI introduces jina-embeddings-v2, the world's first open-source model boasting an 8K context length. Matching the prowess of OpenAI's proprietary models, this innovation is now publicly accessible on Huggingface, signaling a significant milestone in the landscape of text embeddings.
Jina AI Launches World's First Open-Source 8K Text Embedding, Rivaling OpenAI

Jina AI
October 25, 2023 • 4 minutes read
Berlin, Germany - October 25, 2023 – Jina AI, the Berlin-based artificial intelligence company, is thrilled to announce the launch of its second-generation text embedding model: jina-embeddings-v2. This cutting-edge model is now the only open-source offering that supports an impressive 8K (8192 tokens) context length, putting it on par with OpenAI's proprietary model, text-embedding-ada-002, in terms of both capabilities and performance on the Massive Text Embedding Benchmark (MTEB) leaderboard.
Benchmarking Against the Best 8K Model from Open AI
When directly compared with OpenAI's 8K model text-embedding-ada-002, jina-embeddings-v2 showcases its mettle. Below is a performance comparison table, highlighting areas where jina-embeddings-v2 particularly excels:| Rank | Model | Model Size (GB) | Embedding Dimensions | Sequence Length | Average (56 datasets) | Classification Average (12 datasets) | Reranking Average (4 datasets) | Retrieval Average (15 datasets) | Summarization Average (1 dataset) |
|---|---|---|---|---|---|---|---|---|---|
| 15 | text-embedding-ada-002 | Unknown | 1536 | 8191 | 60.99 | 70.93 | 84.89 | 56.32 | 30.8 |
| 17 | jina-embeddings-v2-base-en | 0.27 | 768 | 8192 | 60.38 | 73.45 | 85.38 | 56.98 | 31.6 |
Notably, jina-embedding-v2 outperforms its OpenAI counterpart in Classification Average, Reranking Average, Retrieval Average, and Summarization Average.
Features and Benefits
Jina AI’s dedication to innovation is evident in this latest offering:- From Scratch to Superiority: The jina-embeddings-v2 was built from the ground up. Over the last three months, the team at Jina AI engaged in intensive R&D, data collection, and tuning. The outcome is a model that marks a significant leap from its predecessor.
- Unlocking Extended Context Potential with 8K: jina-embeddings-v2 isn’t just a technical feat; its 8K context length opens doors to new industry applications:
- Legal Document Analysis: Ensure every detail in extensive legal texts is captured and analyzed.
- Medical Research: Embed scientific papers holistically for advanced analytics and discovery.
- Literary Analysis: Dive deep into long-form content, capturing nuanced thematic elements.
- Financial Forecasting: Attain superior insights from detailed financial reports.
- Conversational AI: Improve chatbot responses to intricate user queries.
Benchmarking shows that in several datasets, this extended context enabled jina-embeddings-v2 to outperform other leading base embedding models, emphasizing the practical advantages of longer context capabilities.
- Availability: Both models are freely available for download on Huggingface:
- Base Model (0.27G) - Designed for heavy-duty tasks requiring higher accuracy, like academic research or business analytics.
- Small Model (0.07G) - Crafted for lightweight applications such as mobile apps or devices with limited computing resources.
- Size Options for Different Needs: Understanding the diverse needs of the AI community, Jina AI offers two versions of the model:
jinaai/jina-embeddings-v2-base-en · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.

jinaai/jina-embeddings-v2-small-en · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
https://huggingface.co/jinaai/jina-embeddings-v2-small-en?ref=jina-ai-gmbh.ghost.io

In reflecting on the journey and significance of this launch, Dr. Han Xiao, CEO of Jina AI, shared his thoughts:
"In the ever-evolving world of AI, staying ahead and ensuring open access to breakthroughs is paramount. With jina-embeddings-v2, we've achieved a significant milestone. Not only have we developed the world's first open-source 8K context length model, but we have also brought it to a performance level on par with industry giants like OpenAI. Our mission at Jina AI is clear: we aim to democratize AI and empower the community with tools that were once confined to proprietary ecosystems. Today, I am proud to say, we have taken a giant leap towards that vision."
This pioneering spirit is evident in Jina AI's forward-looking plans.
A Glimpse into the Future
Jina AI is committed to leading the forefront of innovation in AI. Here’s what’s next on their roadmap:- Academic Insights: An academic paper detailing the technical intricacies and benchmarks of jina-embeddings-v2 will soon be published, allowing the AI community to gain deeper insights.
- API Development: The team is in the advanced stages of developing an OpenAI-like embeddings API platform. This will provide users with the capability to effortlessly scale the embedding model according to their needs.
- Language Expansion: Venturing into multilingual embeddings, Jina AI is setting its sights on launching German-English models, further expanding its repertoire.
About Jina AI GmbH:
Located at Ohlauer Str. 43 (1st floor), zone A, 10999 Berlin, Germany, Jina AI is at the vanguard of reshaping the landscape of multimodal artificial intelligence. For inquiries, please reach out at contact@jina.ai.
GitHub - mpoon/gpt-repository-loader: Convert code repos into an LLM prompt-friendly format. Mostly built by GPT-4.
Convert code repos into an LLM prompt-friendly format. Mostly built by GPT-4. - GitHub - mpoon/gpt-repository-loader: Convert code repos into an LLM prompt-friendly format. Mostly built by GPT-4.
 github.com
github.com
gpt-repository-loader
gpt-repository-loader is a command-line tool that converts the contents of a Git repository into a text format, preserving the structure of the files and file contents. The generated output can be interpreted by AI language models, allowing them to process the repository's contents for various tasks, such as code review or documentation generation.Contributing
Some context around building this is located here. Appreciate any issues and pull requests in the spirit of having mostly GPT build out this tool. Using ChatGPT Plus is recommended for quick access to GPT-4.Getting Started
To get started with gpt-repository-loader, follow these steps:- Ensure you have Python 3 installed on your system.
- Clone or download the gpt-repository-loader repository.
- Navigate to the repository's root directory in your terminal.
- Run gpt-repository-loader with the following command:
python gpt_repository_loader.py /path/to/git/repository [-p /path/to/preamble.txt] [-o /path/to/output_file.txt]
Replace /path/to/git/repository with the path to the Git repository you want to process. Optionally, you can specify a preamble file with -p or an output file with -o. If not specified, the default output file will be named output.txt in the current directory. - The tool will generate an output.txt file containing the text representation of the repository. You can now use this file as input for AI language models or other text-based processing tasks.
Running Tests
To run the tests for gpt-repository-loader, follow these steps:- Ensure you have Python 3 installed on your system.
- Navigate to the repository's root directory in your terminal.
- Run the tests with the following command:
python -m unittest test_gpt_repository_loader.py
License
This project is licensed under the MIT License - see the LICENSE file for details.About
Convert code repos into an LLM prompt-friendly format. Mostly built by GPT-4.
AI ‘breakthrough’: neural net has human-like ability to generalize language
A neural-network-based artificial intelligence outperforms ChatGPT at quickly folding new words into its lexicon, a key aspect of human intelligence.
 www.nature.com
www.nature.com
AI ‘breakthrough’: neural net has human-like ability to generalize language
A neural-network-based artificial intelligence outperforms ChatGPT at quickly folding new words into its lexicon, a key aspect of human intelligence.
A version of the human ability to apply new vocabulary in flexible ways has been achieved by a neural network.Credit: marrio31/Getty
Scientists have created a neural network with the human-like ability to make generalizations about language1. The artificial intelligence (AI) system performs about as well as humans at folding newly learned words into an existing vocabulary and using them in fresh contexts, which is a key aspect of human cognition known as systematic generalization.
The researchers gave the same task to the AI model that underlies the chatbot ChatGPT, and found that it performs much worse on such a test than either the new neural net or people, despite the chatbot’s uncanny ability to converse in a human-like manner.
The work, published on 25 October in Nature, could lead to machines that interact with people more naturally than do even the best AI systems today. Although systems based on large language models, such as ChatGPT, are adept at conversation in many contexts, they display glaring gaps and inconsistencies in others.
The neural network’s human-like performance suggests there has been a “breakthrough in the ability to train networks to be systematic”, says Paul Smolensky, a cognitive scientist who specializes in language at Johns Hopkins University in Baltimore, Maryland.
Language lessons
Systematic generalization is demonstrated by people’s ability to effortlessly use newly acquired words in new settings. For example, once someone has grasped the meaning of the word ‘photobomb’, they will be able to use it in a variety of situations, such as ‘photobomb twice’ or ‘photobomb during a Zoom call’. Similarly, someone who understands the sentence ‘the cat chases the dog’ will also understand ‘the dog chases the cat’ without much extra thought.But this ability does not come innately to neural networks, a method of emulating human cognition that has dominated artificial-intelligence research, says Brenden Lake, a cognitive computational scientist at New York University and co-author of the study. Unlike people, neural nets struggle to use a new word until they have been trained on many sample texts that use that word. AI researchers have sparred for nearly 40 years as to whether neural networks could ever be a plausible model of human cognition if they cannot demonstrate this type of systematicity.

DeepMind AI learns simple physics like a baby
To attempt to settle this debate, the authors first tested 25 people on how well they deploy newly learnt words to different situations. The researchers ensured the participants would be learning the words for the first time by testing them on a pseudo-language consisting of two categories of nonsense words. ‘Primitive’ words such as ‘dax,’ ‘wif’ and ‘lug’ represented basic, concrete actions such as ‘skip’ and ‘jump’. More abstract ‘function’ words such as ‘blicket’, ‘kiki’ and ’fep’ specified rules for using and combining the primitives, resulting in sequences such as ‘jump three times’ or ‘skip backwards’.
Participants were trained to link each primitive word with a circle of a particular colour, so a red circle represents ‘dax’, and a blue circle represents ‘lug’. The researchers then showed the participants combinations of primitive and function words alongside the patterns of circles that would result when the functions were applied to the primitives. For example, the phrase ‘dax fep’ was shown with three red circles, and ‘lug fep’ with three blue circles, indicating that fep denotes an abstract rule to repeat a primitive three times.
Finally, the researchers tested participants’ ability to apply these abstract rules by giving them complex combinations of primitives and functions. They then had to select the correct colour and number of circles and place them in the appropriate order.
Cognitive benchmark
As predicted, people excelled at this task; they chose the correct combination of coloured circles about 80% of the time, on average. When they did make errors, the researchers noticed that these followed a pattern that reflected known human biases.Next, the researchers trained a neural network to do a task similar to the one presented to participants, by programming it to learn from its mistakes. This approach allowed the AI to learn as it completed each task rather than using a static data set, which is the standard approach to training neural nets. To make the neural net human-like, the authors trained it to reproduce the patterns of errors they observed in humans’ test results. When the neural net was then tested on fresh puzzles, its answers corresponded almost exactly to those of the human volunteers, and in some cases exceeded their performance.

A test of artificial intelligence
By contrast, GPT-4 struggled with the same task, failing, on average, between 42 and 86% of the time, depending on how the researchers presented the task. “It’s not magic, it’s practice,” Lake says. “Much like a child also gets practice when learning their native language, the models improve their compositional skills through a series of compositional learning tasks.”
Melanie Mitchell, a computer and cognitive scientist at the Santa Fe Institute in New Mexico, says this study is an interesting proof of principle, but it remains to be seen whether this training method can scale up to generalize across a much larger data set or even to images. Lake hopes to tackle this problem by studying how people develop a knack for systematic generalization from a young age, and incorporating those findings to build a more robust neural net.
Elia Bruni, a specialist in natural language processing at the University of Osnabrück in Germany, says this research could make neural networks more-efficient learners. This would reduce the gargantuan amount of data necessary to train systems such as ChatGPT and would minimize ‘hallucination’, which occurs when AI perceives patterns that are non-existent and creates inaccurate outputs. “Infusing systematicity into neural networks is a big deal,” Bruni says. “It could tackle both these issues at the same time.”
doi: AI ‘breakthrough’: neural net has human-like ability to generalize language
References
- Lake, B. M. & Baroni, M. Nature Human-like systematic generalization through a meta-learning neural network - Nature (2023).
Article Google Scholar
Reprints and Permissions
AI Learns Like a Pigeon, Researchers Say
By Mark Tysonpublished about 22 hours ago
Both pigeons and AI models can be better than humans at solving some complex tasks

Researchers at Ohio State University have found that pigeons tackle some problems in a very similar way to modern computer AI models. In essence, pigeons have been found to use a ‘brute force’ learning method called "associative learning." Thus pigeons, and modern computer AIs, can reach solutions to complex problems that befuddle human thinking patterns.
Brandon Turner, lead author of the new study and professor of psychology at Ohio State University, worked with Edward Wasserman, a professor of psychology at the University of Iowa, on the new study, published in iScience.
Here are the key findings:
- Pigeons can solve an exceptionally broad range of visual categorization tasks
- Some of these tasks seem to require advanced cognitive and attentional processes, yet computational modeling indicates that pigeons don’t deploy such complex processes
- A simple associative mechanism may be sufficient to account for the pigeon’s success
Turner told the Ohio State news blog that the research started with a strong hunch that pigeons learned in a similar way to computer AIs. Initial research confirmed earlier thoughts and observations. “We found really strong evidence that the mechanisms guiding pigeon learning are remarkably similar to the same principles that guide modern machine learning and AI techniques,” said Turner.
A pigeon’s “associative learning” can find solutions to complex problems that are hard to reach by humans or other primates. Primate thinking is typically steered by selective attention and explicit rule use, which can get in the way of solving some problems.

(Image credit: Ohio State University)
For the study, pigeons were tested with a range of four tasks. In easier tasks, it was found pigeons could learn the correct choices over time and grow their success rates from about 55% to 95%. The most complex tasks didn’t see such a stark improvement over the study time, going from 55% to only 68%. Nevertheless, the results served to show close parallels between pigeon performance and AI model learning performance. Both pigeon and machine learners seemed to use both associative learning and error correction techniques to steer their decisions toward success.
Further insight was provided by Turner in comments on human vs pigeon vs AI learning models. He noted that some of the tasks would really frustrate humans as making rules wouldn’t help simplify problems, leading to task abandonment. Meanwhile, for pigeons (and machine AIs), in some tasks “this brute force way of trial and error and associative learning... helps them perform better than humans.”
Interestingly, the study recalls that in his Letter to the Marquess of Newcastle (1646), French philosopher René Descartes argued that animals were nothing more than beastly mechanisms — bête-machines, simply following impulses from organic reactions.
The conclusion of the Ohio State blog highlighted how humans have traditionally looked down upon pigeons as dim-witted. Now we have to admit something: our latest crowning technological achievement of computer AI relies on relatively simple brute-force pigeon-like learning mechanisms.
Will this new research have any influence on computer science going forward? It seems like those involved in AI / machine learning and those developing neuromorphic computing might find some useful crossover here.
null
...
thank god AI ain't there yet 
Zephyr: Direct Distillation of LM Alignment
We aim to produce a smaller language model that is aligned to user intent. Previous research has shown that applying distilled supervised fine-tuning (dSFT) on larger models significantly improves task accuracy; however, these models are unaligned, i.e. they do not respond well to natural...
Zephyr: Direct Distillation of LM Alignment
Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, Nathan Sarrazin, Omar Sanseviero, Alexander M. Rush, Thomas WolfWe aim to produce a smaller language model that is aligned to user intent. Previous research has shown that applying distilled supervised fine-tuning (dSFT) on larger models significantly improves task accuracy; however, these models are unaligned, i.e. they do not respond well to natural prompts. To distill this property, we experiment with the use of preference data from AI Feedback (AIF). Starting from a dataset of outputs ranked by a teacher model, we apply distilled direct preference optimization (dDPO) to learn a chat model with significantly improved intent alignment. The approach requires only a few hours of training without any additional sampling during fine-tuning. The final result, Zephyr-7B, sets the state-of-the-art on chat benchmarks for 7B parameter models, and requires no human annotation. In particular, results on MT-Bench show that Zephyr-7B surpasses Llama2-Chat-70B, the best open-access RLHF-based model. Code, models, data, and tutorials for the system are available at this https URL.
| Subjects: | Machine Learning (cs.LG); Computation and Language (cs.CL) |
| Cite as: | arXiv:2310.16944 [cs.LG] |
| (or arXiv:2310.16944v1 [cs.LG] for this version) | |
| https://doi.org/10.48550/arXiv.2310.16944 Focus to learn more |
Submission history
From: Alexander M. Rush [view email][v1] Wed, 25 Oct 2023 19:25:16 UTC (3,722 KB)
https://arxiv.org/pdf/2310.16944.pdf

HuggingFaceH4/zephyr-7b-beta · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

Model Card for Zephyr 7B β
Zephyr is a series of language models that are trained to act as helpful assistants. Zephyr-7B-β is the second model in the series, and is a fine-tuned version of mistralai/Mistral-7B-v0.1 that was trained on on a mix of publicly available, synthetic datasets using Direct Preference Optimization (DPO). We found that removing the in-built alignment of these datasets boosted performance on MT Bench and made the model more helpful. However, this means that model is likely to generate problematic text when prompted to do so and should only be used for educational and research purposes. You can find more details in the technical report.Model description
- Model type: A 7B parameter GPT-like model fine-tuned on a mix of publicly available, synthetic datasets.
- Language(s) (NLP): Primarily English
- License: MIT
- Finetuned from model: mistralai/Mistral-7B-v0.1
Model Sources
- Repository: GitHub - huggingface/alignment-handbook: Robust recipes for to align language models with human and AI preferences
- Demo: Zephyr Chat - a Hugging Face Space by HuggingFaceH4
- Chatbot Arena: Evaluate Zephyr 7B against 10+ LLMs in the LMSYS arena: http://arena.lmsys.org
Performance
At the time of release, Zephyr-7B-β is the highest ranked 7B chat model on the MT-Bench and AlpacaEval benchmarks:| Model | Size | Alignment | MT-Bench (score) | AlpacaEval (win rate %) |
|---|---|---|---|---|
| StableLM-Tuned-α | 7B | dSFT | 2.75 | - |
| MPT-Chat | 7B | dSFT | 5.42 | - |
| Xwin-LMv0.1 | 7B | dPPO | 6.19 | 87.83 |
| Mistral-Instructv0.1 | 7B | - | 6.84 | - |
| Zephyr-7b-α | 7B | dDPO | 6.88 | - |
Zephyr-7b-β  | 7B | dDPO | 7.34 | 90.60 |
| Falcon-Instruct | 40B | dSFT | 5.17 | 45.71 |
| Guanaco | 65B | SFT | 6.41 | 71.80 |
| Llama2-Chat | 70B | RLHF | 6.86 | 92.66 |
| Vicuna v1.3 | 33B | dSFT | 7.12 | 88.99 |
| WizardLM v1.0 | 70B | dSFT | 7.71 | - |
| Xwin-LM v0.1 | 70B | dPPO | - | 95.57 |
| GPT-3.5-turbo | - | RLHF | 7.94 | 89.37 |
| Claude 2 | - | RLHF | 8.06 | 91.36 |
| GPT-4 | - | RLHF | 8.99 | 95.28 |

However, on more complex tasks like coding and mathematics, Zephyr-7B-β lags behind proprietary models and more research is needed to close the gap.
Intended uses & limitations
The model was initially fine-tuned on a filtered and preprocessed of the UltraChat dataset, which contains a diverse range of synthetic dialogues generated by ChatGPT. We then further aligned the model with TRL's DPOTrainer on the openbmb/UltraFeedback dataset, which contains 64k prompts and model completions that are ranked by GPT-4. As a result, the model can be used for chat and you can check out our demo to test its capabilities.
TRL's DPOTrainer on the openbmb/UltraFeedback dataset, which contains 64k prompts and model completions that are ranked by GPT-4. As a result, the model can be used for chat and you can check out our demo to test its capabilities.You can find the datasets used for training Zephyr-7B-β here

TheBloke/zephyr-7B-beta-GGUF · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
demo:

Last edited:
Synthetic data will provide the next trillion tokens to fuel our hungry models.
I'm excited to announce MimicGen: massively scaling up data pipeline for robot learning! We multiply high-quality human data in simulation with digital twins.
Using < 200 human demonstrations, MimicGen can autonomously generate > 50,000 training episodes across 18 tasks, multiple simulators, and even in the real-world!
The idea is simple:
1. Humans tele-operate the robot to complete a task. It is extremely high-quality but also very slow and expensive.
2. We create a digital twin of the robot and the scene in high-fidelity, GPU-accelerated simulation.
3. We can now move objects around, replace with new assets, and even change the robot hand - basically augment the training data with procedural generation.
4. Export the successful episodes, and feed that to a neural network! You now have an near-infinite stream of data.
One of the key reasons that robotics lags far behind other AI fields is the lack of data: you cannot scrape control signals from the internet. They simply don't exist in-the-wild.
MimicGen shows the power of synthetic data and simulation to keep our scaling laws alive. I believe this principle apply beyond robotics. We are quickly exhausting the high-quality, real tokens from the web. Artificial intelligence from artificial data will be the way forward.
We are big fans of the OSS community. As usual, we open-source everything, including the generated dataset!
Website: mimicgen.github.io/
- Paper: arxiv.org/abs/2310.17596
- Dataset is hosted on HuggingFace (thanks @_akhaliq!!): huggingface.co/datasets/aman…
- Code: github.com/NVlabs/mimicgen_e… MimicGen is led by @AjayMandlekar, deep dive in the thread:
I'm excited to announce MimicGen: massively scaling up data pipeline for robot learning! We multiply high-quality human data in simulation with digital twins.
Using < 200 human demonstrations, MimicGen can autonomously generate > 50,000 training episodes across 18 tasks, multiple simulators, and even in the real-world!
The idea is simple:
1. Humans tele-operate the robot to complete a task. It is extremely high-quality but also very slow and expensive.
2. We create a digital twin of the robot and the scene in high-fidelity, GPU-accelerated simulation.
3. We can now move objects around, replace with new assets, and even change the robot hand - basically augment the training data with procedural generation.
4. Export the successful episodes, and feed that to a neural network! You now have an near-infinite stream of data.
One of the key reasons that robotics lags far behind other AI fields is the lack of data: you cannot scrape control signals from the internet. They simply don't exist in-the-wild.
MimicGen shows the power of synthetic data and simulation to keep our scaling laws alive. I believe this principle apply beyond robotics. We are quickly exhausting the high-quality, real tokens from the web. Artificial intelligence from artificial data will be the way forward.
We are big fans of the OSS community. As usual, we open-source everything, including the generated dataset!
Website: mimicgen.github.io/
- Paper: arxiv.org/abs/2310.17596
- Dataset is hosted on HuggingFace (thanks @_akhaliq!!): huggingface.co/datasets/aman…
- Code: github.com/NVlabs/mimicgen_e… MimicGen is led by @AjayMandlekar, deep dive in the thread:
Aligned conversational AI remains out of reach for most. Leading proprietary chatbots demand immense compute resources and human oversight, placing cutting-edge performance beyond the capabilities of many organizations.
Open-source models struggle to match proprietary assistants in effectively understanding and responding to diverse user needs. This results in confusion, misalignment, and unsatisfied customers.
ZEPHYR-7B breaks down these barriers. Through novel distillation techniques, this 7B parameter chatbot achieves alignment rivaling select 70B industry models designed with extensive human feedback.
ZEPHYR surpasses other open models on benchmarks measuring conversational ability. It requires no costly human labeling, enabling rapid training on modest compute.
While work remains to address biases, safety procedures, and scaling, ZEPHYR-7B represents a major step toward accessible aligned AI. It brings customizable, transparent chatbots with proprietary-grade alignment within reach.
Don't settle for misaligned assistants.
Carlos E. Perez
@IntuitMachine
Oct 27
Oct 27
3 training and alignment methods:
1. Distilled Supervised Fine-Tuning (dSFT): The student model is trained on dialogues generated by a teacher model on a diverse prompt set. This provides a basic conversational ability.
2. AI Feedback (AIF): An ensemble of models generates responses to prompts which are ranked by the teacher. The top response and a random lower-ranked one are saved as a training example. This converts rankings to preferences.
3. Distilled Direct Preference Optimization (dDPO): The student model is directly optimized to rank the teacher-preferred response higher, using the AIF data. This aligns the student model to the teacher's preferences without any sampling.
Carlos E. Perez
@IntuitMachine
Oct 27
Oct 27
Here is an overview of the full training process:
1. Start with a pretrained language model (LLM) like Mistral-7B as the base student model.
2. Apply distilled supervised fine-tuning (dSFT) using the UltraChat dataset, which contains dialogues generated by the teacher model GPT-3.5 Turbo. This teaches the student basic conversational abilities.
3. Collect AI feedback (AIF) preferences using the UltraFeedback dataset. Prompts are given to an ensemble of models, then ranked by the teacher GPT-4. The top response is saved as the "winner" and a random lower-ranked one as the "loser".
4. Optimize the dSFT student model using distilled direct preference optimization (dDPO) on the AIF data. This directly maximizes the probability of the "winner" response over the "loser" response for each prompt, aligning the student with the teacher's preferences.
5. The final model is ZEPHYR-7B, which combines the conversational skills of dSFT and the intent alignment of dDPO without any human labeling.
Carlos E. Perez
@IntuitMachine
Oct 27
Oct 27
key results
MT-Bench:
- ZEPHYR-7B obtains a score of 7.34, significantly higher than other 7B models like Mistral-Instruct (6.84), Xwin-LM-7B (6.19), and StableLM-α (2.75).
- This surpasses the 70B RLHF model LLaMa2-Chat at 6.86 and is competitive with GPT-3.5 Turbo at 7.94.
- ZEPHYR-7B is still below GPT-4 at 8.99 and Claude-2 at 8.06.
AlpacaEval:
- ZEPHYR-7B achieves a 90.6% win rate against the baseline.
- This edges out Vicuna-33B at 88.99% and is on par with GPT-3.5 Turbo at 89.37%.
- Slightly lower than Claude-2 at 91.36% and GPT-4 at 95.28%.
OpenLLM Leaderboard:
- On ARC, ZEPHYR-7B reaches 62.03% accuracy compared to 54.52% for Mistral-Instruct.
- On Hellaswag, accuracy is 84.52% vs 75.63% for Mistral-Instruct.
- Similarly 5-10% gains on MMLU and TruthfulQA over other 7B models.
Ablations:
- dDPO gives gains of 0.5-1.0 on MT-Bench and 5-10% on AlpacaEval over dSFT models.
- DPO without dSFT fails completely, showing SFT provides critical starting skills.
In summary, ZEPHYR-7B significantly improves over other 7B chat models and is competitive with some much larger models like LLaMa2-70B. The dDPO approach successfully aligns smaller models.
Oct 27, 2023 · 11:01 AM UTC
Carlos E. Perez
@IntuitMachine
Oct 27
Oct 27
key limitations
- Reliance on GPT-4 judgments - The benchmarks used like MT-Bench and AlpacaEval rely on GPT-4 ratings, which are known to be biased towards models similar to it. So the true evaluation may be inflated.
- Safety and ethics not addressed - The focus is on intent alignment for helpfulness, but safety considerations around potential harmful outputs are not directly addressed. Methods to distill that property are needed.
- Scaling up unclear - It's not certain if the same gains would occur when applying dDPO to larger base models like LLaMa2-70B. The techniques may have more impact on smaller models.
- No human evaluations - There are no human ratings or preferences used, so the real human alignment is unvalidated.
- Limited prompt distribution - The benchmarks may not cover the full diversity of real user prompts.
- No parameter efficient methods - Approaches like LoRA could produce aligned models with fewer parameters but are not explored.
- Overfitting dDPO - Rapid overfitting is observed during dDPO but longer-term impacts are uncertain
Open-source models struggle to match proprietary assistants in effectively understanding and responding to diverse user needs. This results in confusion, misalignment, and unsatisfied customers.
ZEPHYR-7B breaks down these barriers. Through novel distillation techniques, this 7B parameter chatbot achieves alignment rivaling select 70B industry models designed with extensive human feedback.
ZEPHYR surpasses other open models on benchmarks measuring conversational ability. It requires no costly human labeling, enabling rapid training on modest compute.
While work remains to address biases, safety procedures, and scaling, ZEPHYR-7B represents a major step toward accessible aligned AI. It brings customizable, transparent chatbots with proprietary-grade alignment within reach.
Don't settle for misaligned assistants.
Carlos E. Perez
@IntuitMachine
Oct 27
Oct 27
3 training and alignment methods:
1. Distilled Supervised Fine-Tuning (dSFT): The student model is trained on dialogues generated by a teacher model on a diverse prompt set. This provides a basic conversational ability.
2. AI Feedback (AIF): An ensemble of models generates responses to prompts which are ranked by the teacher. The top response and a random lower-ranked one are saved as a training example. This converts rankings to preferences.
3. Distilled Direct Preference Optimization (dDPO): The student model is directly optimized to rank the teacher-preferred response higher, using the AIF data. This aligns the student model to the teacher's preferences without any sampling.
Carlos E. Perez
@IntuitMachine
Oct 27
Oct 27
Here is an overview of the full training process:
1. Start with a pretrained language model (LLM) like Mistral-7B as the base student model.
2. Apply distilled supervised fine-tuning (dSFT) using the UltraChat dataset, which contains dialogues generated by the teacher model GPT-3.5 Turbo. This teaches the student basic conversational abilities.
3. Collect AI feedback (AIF) preferences using the UltraFeedback dataset. Prompts are given to an ensemble of models, then ranked by the teacher GPT-4. The top response is saved as the "winner" and a random lower-ranked one as the "loser".
4. Optimize the dSFT student model using distilled direct preference optimization (dDPO) on the AIF data. This directly maximizes the probability of the "winner" response over the "loser" response for each prompt, aligning the student with the teacher's preferences.
5. The final model is ZEPHYR-7B, which combines the conversational skills of dSFT and the intent alignment of dDPO without any human labeling.
Carlos E. Perez
@IntuitMachine
Oct 27
Oct 27
key results
MT-Bench:
- ZEPHYR-7B obtains a score of 7.34, significantly higher than other 7B models like Mistral-Instruct (6.84), Xwin-LM-7B (6.19), and StableLM-α (2.75).
- This surpasses the 70B RLHF model LLaMa2-Chat at 6.86 and is competitive with GPT-3.5 Turbo at 7.94.
- ZEPHYR-7B is still below GPT-4 at 8.99 and Claude-2 at 8.06.
AlpacaEval:
- ZEPHYR-7B achieves a 90.6% win rate against the baseline.
- This edges out Vicuna-33B at 88.99% and is on par with GPT-3.5 Turbo at 89.37%.
- Slightly lower than Claude-2 at 91.36% and GPT-4 at 95.28%.
OpenLLM Leaderboard:
- On ARC, ZEPHYR-7B reaches 62.03% accuracy compared to 54.52% for Mistral-Instruct.
- On Hellaswag, accuracy is 84.52% vs 75.63% for Mistral-Instruct.
- Similarly 5-10% gains on MMLU and TruthfulQA over other 7B models.
Ablations:
- dDPO gives gains of 0.5-1.0 on MT-Bench and 5-10% on AlpacaEval over dSFT models.
- DPO without dSFT fails completely, showing SFT provides critical starting skills.
In summary, ZEPHYR-7B significantly improves over other 7B chat models and is competitive with some much larger models like LLaMa2-70B. The dDPO approach successfully aligns smaller models.
Oct 27, 2023 · 11:01 AM UTC
Carlos E. Perez
@IntuitMachine
Oct 27
Oct 27
key limitations
- Reliance on GPT-4 judgments - The benchmarks used like MT-Bench and AlpacaEval rely on GPT-4 ratings, which are known to be biased towards models similar to it. So the true evaluation may be inflated.
- Safety and ethics not addressed - The focus is on intent alignment for helpfulness, but safety considerations around potential harmful outputs are not directly addressed. Methods to distill that property are needed.
- Scaling up unclear - It's not certain if the same gains would occur when applying dDPO to larger base models like LLaMa2-70B. The techniques may have more impact on smaller models.
- No human evaluations - There are no human ratings or preferences used, so the real human alignment is unvalidated.
- Limited prompt distribution - The benchmarks may not cover the full diversity of real user prompts.
- No parameter efficient methods - Approaches like LoRA could produce aligned models with fewer parameters but are not explored.
- Overfitting dDPO - Rapid overfitting is observed during dDPO but longer-term impacts are uncertain

ChatGPT and Bing AI might already be obsolete, according to a new study
Meta-learning for Compositionality (MLC) might give AI-powered chatbots a run for their money.
 www.windowscentral.com
www.windowscentral.com
What you need to know
- A new study highlights how scientists are potentially on the verge of a breakthrough.
- The new technique dubbed Meta-learning for Compositionality (MLC), has the capability to make generalizations about language.
- Per benchmarks shared, neural networks could potentially outperform AI-powered chatbots like Bing Chat and ChatGPT, which also leverage neural network capabilities.
- When presented with certain tasks, the neural network was able to replicate similar results, whereas the GPT-4 model struggled to accomplish these tasks.
- The study claims that the new design is able to understand and use new words in different settings better than ChatGPT.
As companies continue putting more effort into AI to improve the technology, scientists have seemingly created a a discovery that might supersede generative AI's capabilities.
Per the report in Nature, scientists refer to the technique as Meta-learning for Compositionality (MLC). They further indicated that it has the capability to make generalizations about language. Moreover, scientists claim that it might be just as good as humans, especially when folding new words and applying them in different settings and contexts, ultimately presenting a life-like experience.
When put to the test and compared to ChatGPT (which leverages neural network technology to understand and generate text based on the user's prompts) the scientists concluded that the technique and humans performed better. This is despite the fact that chatbots like ChatGPT and Bing Chat are able to interact in a human-like manner and serve as AI-powered assistants.
According to Nature's report, there's a huge possibility that the new design could outwit AI-powered chatbots in the long run as it can interact with people more naturally compared to existing systems. Looking back, Microsoft's Bing Chat was spotted hallucinating during the initial days of its launch, though the issue was fixed.
Paul Smolensky, a scientist specializing in language at Johns Hopkins University in Baltimore, Maryland, stated that the technique is a "breakthrough in the ability to train networks to be systematic."
How does neural network work?
As highlighted above, a neural network is a type of artificial intelligence with the ability to fold new words and use them in different settings like humans. The only difference is that the technology must first undergo vigorous training to master the word and how to use it in different settings.To determine the capability of the technology, the scientists ran several tests on humans by exposing them to new words and gauging their understanding of how well they were able to use the words in different contexts. They also tested their capability to link the newly learned words with specific colors. As per the benchmark shared, 80% of the people who participated in the exercise excelled and could relate the words with the colors.
The scientist used the same premise to train a neural network. However, they configured it to learn from its own mistakes. The goal was to allow the system to learn from every task it completed rather than using static data. To ensure that the neural network portrayed human-like characteristics, the scientists trained the model to reproduce similar errors to the ones made by those who took a similar test. Ultimately, this allowed the neural network to respond to a fresh batch of questions almost (if not perfectly) like humans.
GPT-4, on the other hand, took quite some time to make sense of the tasks presented to it. Even then, the results were dismal compared to humans and the neural network, where it averaged between 42 and 86 percent, depending on the tasks presented. Put incredibly simply, the issue with GPT and other similar systems is that they simply mimic intensely complex syntax, rather than demonstrate a true understanding of context. This is what leads GPT and similar models down hallucinogenic rabbit holes — humans are more capable of self-correcting anomalies like this, and neural networks may be more capable of doing so as well.
While this potentially proves that a neural network could be the next best thing after generative AI, a lot of testing and studies need to be done to assert this completely. It will be interesting to see how this plays out and how it reshapes systematic generalization.
What does the future hold for ChatGPT and Bing Chat?

There's no doubt about generative AI's power and potential, especially if its vast capabilities are fully explored and put to good use. This is not to say that the technology is not achieving amazing feats already. Recently, a group of researchers proved that it's possible to successfully run a software company using ChatGPT and even generate code in under seven minutes for less than a dollar.
While impressive, the generative AI faces its fair share of setbacks. For instance, the exorbitant cost implication required to keep it going, not forgetting the amount of cooling water and energy it consumes. There have also been reports of OpenAI's AI-powered chatbot, ChatGPT, losing accuracy and its user base declining for three months consecutively. Bing Chat's market share has also stagnated despite Microsoft's heavy investment in the technology.
/cdn.vox-cdn.com/uploads/chorus_asset/file/25034643/AI_Creative_Tools_Press_Release_NEW.jpg)
Shutterstock will now let you transform real photos using AI
Shutterstock’s AI-powered tools are rolling out.
Shutterstock will now let you transform real photos using AI
/Shutterstock says it will compensate artists if their images are licensed after they’re edited with AI.
By Emma Roth, a news writer who covers the streaming wars, consumer tech, crypto, social media, and much more. Previously, she was a writer and editor at MUO.Oct 26, 2023, 9:00 AM EDT|0 Comments / 0 New
If you buy something from a Verge link, Vox Media may earn a commission. See our ethics statement.
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25034643/AI_Creative_Tools_Press_Release_NEW.jpg "An image showing Shutterstock photos in a grid")
Image: Shutterstock
Shutterstock will now let you edit its library of images using AI. In an update on Thursday, Shutterstock revealed a set of new AI-powered tools, like Magic Brush, which lets you tweak an image by brushing over an area and “describing what you want to add, replace or erase.”
The AI image editor is still in beta and will also let you generate alternate versions of a stock or AI-generated image as well as expand the background of an image. Additionally, Shutterstock is rolling out a “smart” resizing feature that will automatically change an image’s shape to match your required dimensions, along with an AI-powered background removal tool.
Shutterstock notes that it will compensate artists “if their images are licensed after editing.” However, it adds that “AI-generated or edited content” will not be eligible for licensing on the site “to further ensure the protection of contributor IP and proper compensation of artists.”
“This is an unprecedented offering in the stock photography industry,” Shutterstock CEO Paul Hennessy says in a statement. “Now, creatives have everything they need to craft the perfect content for any project with AI-powered design capabilities that you can use to edit stock images within Shutterstock’s library, presenting infinite possibilities to make stock your own.”
The company also announced that it’s going to update its AI image generator, which it launched in beta in January, with the latest version of OpenAI’s DALL-E text-to-image generator. Shutterstock expanded its partnership with OpenAI in July, allowing DALL-E to train on Shutterstock’s library for six more years. Last year, Shutterstock announced a contributor’s fund to compensate artists whose work is used for training.
In addition to Shutterstock, other companies, like Adobe and Canva, are getting into AI-powered image editing. Last month, Adobe launched its Firefly generative AI tools for those who subscribe to Adobe Creative Cloud, Adobe Express, and Adobe Experience Cloud. As part of its launch, Adobe announced a new annual bonus scheme that it will pay to artists who allow their stock submissions to be used to train the company’s models. Canva similarly rolled out a trove of AI-powered design tools in March that users can use for free.https://www.theverge.com/2023/10/26/23933120/shutterstock-transform-real-photos-ai
Google Maps is becoming more like Search — thanks to AI
/Google Maps is getting an AI makeover, adding new features like Immersive View and making existing features like driving directions easier to follow. It’s also becoming more like Search.
By Andrew J. Hawkins, transportation editor with 10+ years of experience who covers EVs, public transportation, and aviation. His work has appeared in The New York Daily News and City & State.Oct 26, 2023, 9:00 AM EDT|17 Comments / 17 New
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/23453506/acastro_180427_1777_0003.jpg "Illustration of the Google logo")
Illustration by Alex Castro / The Verge
Google is adding a range of new AI-powered features to Maps, including more immersive navigation, easier-to-follow driving directions, and better organized search results. The end result is an experience that will likely remind many users of Google Search.
Some of this news has already been announced, like Immersive View, which is now coming to more cities. Other aspects are intended to enhance previously available features, like EV charging station availability.
But the biggest takeaway is that Google wants Maps to be more like Search: a place where people can obviously come get directions or find coffee shops and EV chargers but also enter vague queries like “fall foliage,” “latte art,” or “things to do in Tokyo” and get a whole bunch of actually useful hits. Google said it wants people to use Maps to discover new places or experiences, all while under the auspices of its all-powerful algorithm.
Google wants people to use Maps to discover new places or experiences
“AI has really supercharged the way we map,” said Chris Phillips, vice president and general manager of Geo, the team at Google that includes all of its geospatial location mapping products. “It plays a key role in everything from helping you navigate, [helping you] commute, discover new restaurants, where to go, when to go. These are all really important decisions that people are making all the time.”
:no_upscale():format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25034621/tokyo_search.gif)
With Google locked in a tight competition with Apple, Microsoft, and others around the use of AI, the company is banking on its more familiar and popular products, like Google Maps, to help it maintain a leg up over its rivals. And as Google Search becomes more AI-driven, it’s only natural that these other products follow a similar lead.
The future of Google Maps, according to Phillips, is a product that’s more “visual and immersive” but also one that helps you make “more sustainable choices,” like riding transit or a bike. Google is also expanding its API offerings to developers, cities, and especially automotive companies, so they can tweak and improve Maps for the in-car navigation experience.
One of the ways Google is using AI to make Maps more like Search is to analyze “billions” of user-uploaded photos to help people find random items, like coffee shops that offer lattes with panda faces, said Miriam Daniel, Google Maps team leader. People can type specific questions into Maps, much in the way they do with Search, and get a list of results for nearby businesses or locations that match the query based on a real-time analysis of user photos.
“To give you the inspiration when you need it, we’re going to better organize search results for these broad queries,” Daniel said.
“To give you the inspiration when you need it, we’re going to better organize search results for these broad queries.”
Google is using neural radiance fields, which is a form of generative AI, to sort through billions of images, including aerial photos, street imagery, and indoor snaps to create a 360-degree experience, Daniel said. Traffic information is culled from historical data and filtered through Google’s predictive algorithm to help users figure out the best time to get somewhere with the least amount of traffic.
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25034612/EV_Charging_Updates.png)
Google also wants to help answer one of today’s most burning questions: is the EV charging station I’m driving toward actually going to work? Studies have shown that roughly 25 percent of chargers are down or inoperable at any given time. Google Maps will now tell you when a charger was last used to help EV owners figure out whether they’re wasting their time with a nonoperational charger. If the station was used a few hours ago, chances are it’s working. If it’s been a few days or weeks since it was used, you might want to find another charger instead. Google Maps is also adding more EV charging details, such as whether a charger is compatible with your EV and whether it’s fast, medium, or slow.
For more EV charging information while you’re driving, Google is offering updated Places APIs to developers to build out these features for cars with navigation systems based on Google Maps. Now, car companies can use the Places API to build out more EV charging information so their customers can see real-time location information, plug type, and charging speeds directly on their vehicle’s infotainment screens.
:no_upscale():format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25034618/immersive_view.gif)
To improve Google Maps’ stickiness, the company is also rolling out more flashy features, like Immersive View, which was first announced earlier this year. This feature offers users a 3D view of a place to help them see where they’re supposed to go, while also offering other tidbits of information, like local business locations, weather, and traffic. The feature is now available for Android and iOS users in 15 cities, including Amsterdam, Barcelona, Dublin, Florence, Las Vegas, London, Los Angeles, Miami, New York, Paris, San Francisco, San Jose, Seattle, Tokyo, and Venice.
Google is rebranding its augmented reality feature “Search with Live View” to “Lens in Maps” in which someone taps the Lens in the search bar and holds up their camera to find information about the nearest train stations, coffee shops, ATMs, or whatever is nearby. In this way, Google is trying to cut out the middleman by having to search for businesses that are close by and allowing you to use your phone’s camera as an AR tool instead. Lens in Maps is now live in 50 more cities, including Austin, Las Vegas, Rome, São Paulo, and Taipei.
Navigation in Google Maps is getting a makeover: updated colors, more realistic buildings, and improved lane details for tricky highway exits. These improvements are coming to 12 countries, including the US, Canada, France, and Germany. US drivers will also start to see, for the first time, HOV lanes, which is coming to Android, iOS, and cars with Google built-in. And speed limit information is coming to around 20 new countries.
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25034613/HOV_Lane_Labels.png)
The question is, do Google Maps users want all of this stuff? Trying to pack too much tech into one product is the hallmark of feature bloat, which can drive some users away. But Google is betting that pretty visuals, more AI-driven search results, and other bells and whistles can help elevate it over other map products, like Apple Maps, which itself is finally starting to eat into Google’s market share.
“The foundation of all the work we do is to build the most comprehensive, fresh, accurate information to represent the real world,” Phillips said. “This is key for us, and we like to talk about the map as being alive.”