/cdn.vox-cdn.com/uploads/chorus_asset/file/24956945/23_Meta_Connect___Imagine.jpg)
Meta is putting AI chatbots everywhere
The Meta AI assistant is coming to WhatsApp, Messenger, and Instagram, along with dozens of AI characters based on celebrities like MrBeast and Charli D’Amelio.
Meta is putting AI chatbots everywhere
The Meta AI assistant is coming to WhatsApp, Messenger, and Instagram, along with dozens of AI characters based on celebrities like MrBeast and Charli D’Amelio.
By Alex Heath, a deputy editor and author of the Command Line newsletter. He’s covered the tech industry for over a decade at The Information and other outlets.Sep 27, 2023, 5:30 PM UTC
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/24956945/23_Meta_Connect___Imagine.jpg "A screenshot of Meta AI image generation.")
An example of what Meta’s AI assistant can do. Meta
Meta is officially entering the AI chatbot wars, starting with its own assistant and a slew of AI characters it’s releasing in WhatsApp, Instagram, and Messenger.
For anyone who has used OpenAI’s ChatGPT, or other chatbots like Anthropic’s Claude, Meta’s AI will immediately feel familiar. Meta sees it as a general-purpose assistant for everything from planning a trip with friends in a group chat to answering questions you’d normally ask a search engine. On that latter piece, Meta is announcing a partnership with Microsoft’s Bing to provide real-time web results, which sets Meta AI apart from a lot of the other free AIs out there that don’t have super recent information.
Another big aspect of the Meta AI is its ability to generate images like Midjourney or OpenAI’s DALL-E via the prompt “/imagine.” In my brief demo, it produced compelling high-res photos in a few seconds. Like all of Meta’s AI features being announced this week, this image generation is totally free to use.
Ahmad Al-Dahle, Meta’s VP of generative AI who has been leading the assistant’s development, wouldn’t tell me exactly what it’s trained on. He described it as a “custom-made” large language model that is “based on a lot of the core principles behind Llama 2,” Meta’s latest quasi-open source model that is being quickly adopted across various industries.
The rapid adoption of Llama 2 has helped Meta refine how its own assistant works, he says. “We just saw huge demand for the models, and then we saw an incredible amount of innovation happening on the models that really helped us understand their performance, understand their weaknesses, and help us iterate and leverage some of those components directly into product.”
In terms of how Meta AI differs from Llama 2, Al-Dahle says his team spent time “refining additional data sets for conversations so that we can create a tone that is conversational and friendly in the way that the assistant responds. A lot of existing AIs can be like robotic or bland.” Meta expanded the model’s context window, or the ability to leverage previous interactions to generate what the model produces next, “so that we can build a deeper, more capable back and forth” with users. He says Meta AI has also been tuned to give “very concise” answers.
Some of Meta’s AI characters are familiar faces. Image: Meta
Alongside Meta’s assistant, the company is beginning to roll out an initial roster of 28 AI characters across its messaging apps. Many of them are based on celebrities like Charli D’Amelio, Dwyane Wade, Kendall Jenner, MrBeast, Snoop Dogg, and Paris Hilton. Others are themed to specific use cases like a travel agent.
An interesting twist is an aspect of these characters that Al-Dahle calls “embodiments.” As you chat with one of them, their profile image subtly animates based on the conversation. The effect is more immersive than the 2D chatbots I’ve interacted with to date.
Related
- Mark Zuckerberg on Threads, the future of AI, and Quest 3
- Facebook and Instagram will soon get a slew of AI-powered creator tools
During my brief time trying Meta AI last week, I tried getting it to slip up and say something bad. It told me that covid vaccines are safe and that it can’t help me make a dirty bomb. It wouldn’t give me advice on how to break up with someone, which suggests that Meta has added a lot of safeguards to avoid as many PR disasters as it can. Al-Dahle says the company spent 6,000 hours red-teaming the model to find problematic use cases and that employees have been creating thousands of conversations with it daily in the run-up to release.
Image: Meta
For now, Meta AI isn’t trained on public user data across Instagram and Facebook, though it sounds like that is coming. It’s easy to imagine asking it to “show me reels from the south of Italy” and that being a compelling use case that other chatbots can’t replicate. “We see a long roadmap for us to tie in some of our own social integrations as part of the assistant to make it even more useful,” says Al-Dahle.
“We see a long roadmap for us to tie in some of our own social integrations”
After talking with Al-Dahle and other Meta execs, it’s clear that the company sees its unrivaled distribution — billions of daily users across its messaging apps — as a key competitive edge against ChatGPT and others. The assistant is “right there inside of your chat context, and our chat applications are quite popular,” says Al-Dahle. “You don’t have to pull yourself out of context to interact or engage or get the assistant to help you.”
OpenAI may have kick-started the chatbot race, but given Meta’s immense scale through its social networks, its assistant may actually be the AI that most people use for the first time.







/cloudfront-us-east-2.images.arcpublishing.com/reuters/ETDD3VEQT5IWFE6WDAARZUNSUQ.jpg)


/cdn.vox-cdn.com/uploads/chorus_asset/file/24390406/STK149_AI_03.jpg)
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/24390406/STK149_AI_03.jpg "A rendition of OpenAI’s logo, which looks like a stylized whirlpool.")
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/24957310/IMG_8CA945372C16_1.jpeg "A screenshot of a ChatGPT transcript.")



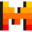







 Strongest <20B pretrained model
Strongest <20B pretrained model On par with many models of 30B params
On par with many models of 30B params Does decently in code tasks (code llama 7B quality)
Does decently in code tasks (code llama 7B quality) Thanks to windowed attention, you can use up to 200K tokens of context (using Rope, using 4 A10G GPUs)
Thanks to windowed attention, you can use up to 200K tokens of context (using Rope, using 4 A10G GPUs) Integrated into transformers, vllm, tgi, and more!
Integrated into transformers, vllm, tgi, and more! Thanks to the small size, you can host on a server or locally
Thanks to the small size, you can host on a server or locally