1/27
@nrehiew_
How to train a State-of-the-art reasoner.
Let's talk about the DeepSeek-R1 paper and how DeepSeek trained a model that is at frontier Sonnet/o1 level.
2/27
@nrehiew_
Quick overview on what has been done to train an o1-like model:
- Process and Outcome Reward Models. This approach does RL and trains these 2 models to give reward/signal at the step or answer level. Given that Qwen trained a SOTA PRM, we can assume they do this.
- LATRO (
https://arxiv.org/pdf/2411.04282) basically treats the CoT as a latent. Given prompt + cot, a good cot will lead to high likelihood of the correct answer
- SFT on reasoning traces.
DeepSeek gets rid of all this complexity and simply does RL on questions with verifiable rewards. TULU 3 style (
Tulu 3: Pushing Frontiers in Open Language Model Post-Training)
3/27
@nrehiew_
They start by trying to improve the Base Model without any supervised data.
They use Group Relative Policy Optimization (
https://arxiv.org/pdf/2402.03300) with the advantage function just being the normalized outcome rewards
For the reward models, they use simple accuracy reminders (check answer within \boxed, run test cases) + they encourage the model to put its thinking process between <think/> tags
4/27
@nrehiew_
The GRPO algorithm here. Again the advantage estimation is just the outcome reward. Check out the paper linked above for more details
5/27
@nrehiew_
1st interesting thing of the paper:
> neural reward model may suffer from reward hacking in the large-scale reinforcement learning process, and retraining the reward model needs additional training resources and it complicates the whole training pipeline.
not much else for me to add here
6/27
@nrehiew_
They say that they use a really simple prompt because they are more interested in observing the evolution in model outputs
7/27
@nrehiew_
Notice that they went straight from Base -> RL without an intermediate SFT/Instruct tuning stage as is common. They call this model R1-Zero
8/27
@nrehiew_
Why is this interesting?
Notice how simple the entire setup is. It is extremely easy to generate synthetic prompts with deterministic answers. And with literally nothing else, it is possible to go from 0.2->0.85 AIME scores.
Training the base model directly also directly extracts that ability without having its distribution disturbed by SFT
Again, at no point did they provide reference answers or instructions. The model realizes that to achieve higher reward, it needs to CoT longer
9/27
@nrehiew_
With this extremely straightforward setup, the network learns to reflect/reevaluate its own answers. Again, this is done completely without supervision
10/27
@nrehiew_
The problem with RL on the base model is that the reasoning process/CoT is not really readable. So, they introduce a small amount of high quality user-friendly data before the RL process such that the final model isnt a "base model" but rather something more "assistant" like
11/27
@nrehiew_
Their entire pipeline is as follows:
1) Take a few thousand samples of high quality data of the format COT + Summary and SFT the base model
2) Repeat the R1 Zero process. They notice the language mixing problem still remains so they add a reward accounting for the proportion of target language words in the COT. (Interesting Note: This worsens performance slightly)
3) Collect 800k accurate samples from the trained model -600K STEm, 200K general purpose. (Note: These were the samples used to FT the other open models like Qwen, Llama etc)
4) They have 1 last RL stage where they combine the verifiable rewards + preference tuning that was done for DeepSeek v3 (for alignment purposes)
12/27
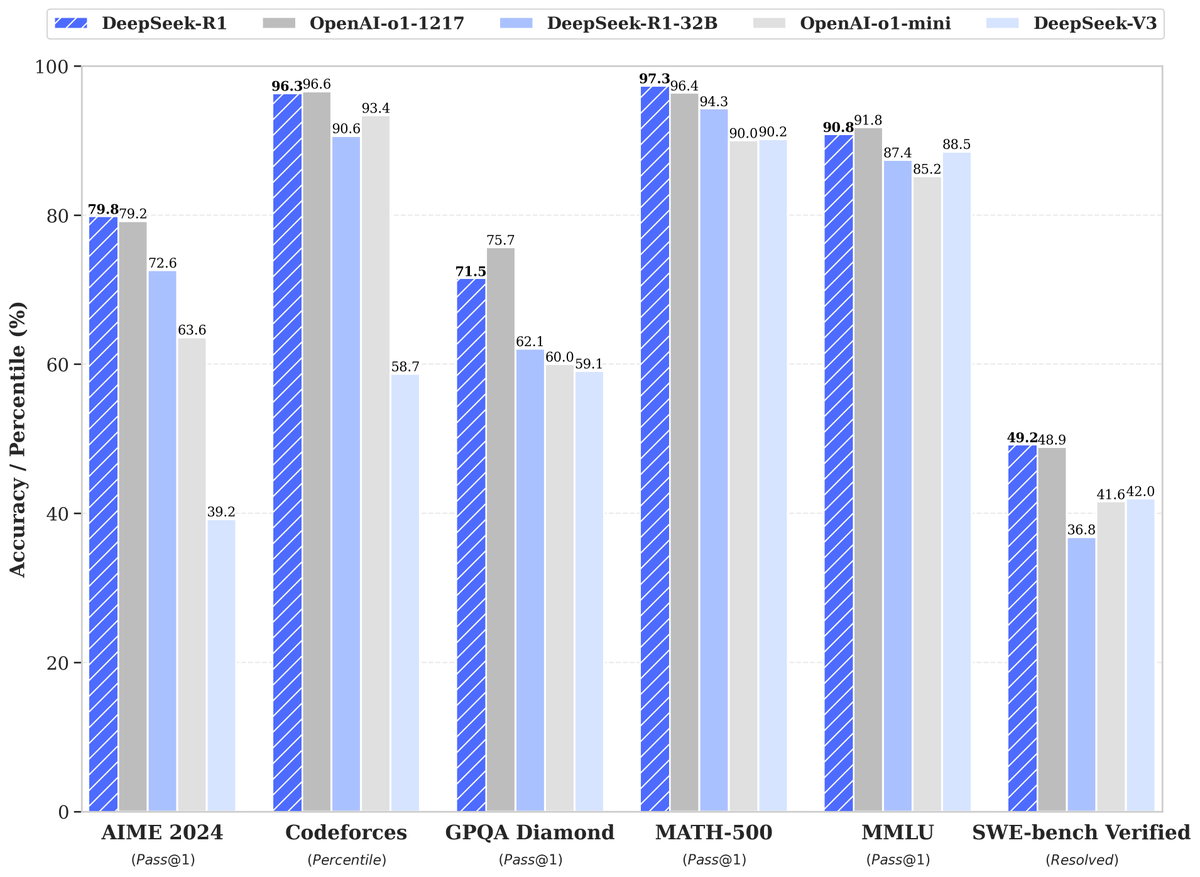
@nrehiew_
By now, you should have seen/heard all the results. So I will just say 1 thing. I really do think this is an o1 level model. If i had to guess its ~ the same as o1 (reasoning_effort = medium)
13/27
@nrehiew_
They also evaluate on the distilled models and distillation really just works. They even beat Qwen's very own QwQ.
At 8B parameters, it is matching Sonnet and has surpassed GPT-4o
14/27
@nrehiew_
Now they have a section on the effectiveness of distillation. They train a Qwen32B model using RL and compare it with the distilled version.
The finding that this RL version is worse off (~ the same as QwQ) shows that the way forward is to RL a huge model and distill it down.
This also gives insight to the impressive performance of o1-mini. It looks like it really is just extremely well engineered distillation
15/27
@nrehiew_
They also have a section on their unsuccessfully attempt which i find extremely commendable to share.
tldr: PRMs are hard to train and can be hacked. It should only be used for guided search rather than learning. MCTS was also not working and was too complicated
16/27
@nrehiew_
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
GitHub - deepseek-ai/DeepSeek-R1
17/27
@nrehiew_
Some thoughts:
I think this is 1 of the most important papers in a while because its the first open model that is genuinely at the frontier and not just riding on the goodwill of being open.
The paper is really really simple as you can probably tell from the thread because the approach is really really simple. It really is exactly what OpenAI is good at - doing simple things but executing at an extremely high level
Personally, I'm surprised (maybe i shouldn't be) that just RL on verifiable rewards (credits to the TULU3 team for the term) works. Now that we know this recipe, we also would have something that can match o3 soon.
Also worth noting that they did alignment tuning + language consistency tuning. This hurts performance which indicates that the model could be even better. Really interesting to think about the tradeoffs here.
The way i see it there are 2 open research areas:
- Can we improve inference time performance. Search? What is o1-pro mode doing? How is the reasoning_effort in o1 controlled?
- What does this unhackable ground truth reward look like for normal domains without deterministic ground truths. I think its just LLM-as-a-Judge but done extremely well (Sonnet probably does this)
18/27
@srivsesh
best follow in a while. can you remind me what the base mode architecture is?
19/27
@nrehiew_
deepseek v3
20/27
@threadreaderapp
Your thread is very popular today!
/search?q=#TopUnroll Thread by @nrehiew_ on Thread Reader App 
@ssfd____ for

unroll
21/27
@fyhao
I am asking o1 and deepthink.
Question:
117115118110113
Deepthink:
22/27
@AbelIonadi
Value packed thread.
23/27
@moss_aidamax
@readwise save thread
24/27
@raphaelmansuy
DeepSeek R1 in Quantalogic ReAct agent: We are thrilled to announce that with the release of v0.2.26, the Quantalogic ReAct agent now offers support for the DeepSeek R1 model! This enhancement empowers our users with advanced reasoning capabilities, making it easier to harness the power of AI for your projects. You can now utilize DeepSeek R1 seamlessly through the following commands:

`quantalogic --model-name deepseek/deepseek-reasoner` or

`quantalogic --model-name openrouter/deepseek/deepseek-r1` This integration marks a significant step forward for our community, enhancing the versatility and potential applications of the Quantalogic platform. Join us in exploring the possibilities that this powerful model brings to the table!
25/27
@DrRayZha
very valuable thread! BTW R1 seems sensitive to the input prompt and few-shot prompting would degrade the performance, it may be a promising direction to make it more robust to input prompts
26/27
@ethan53896137
great post!!!
27/27
@ssfd____
@UnrollHelper
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196



















 !
!
 DeepSeek-R1 is here!
DeepSeek-R1 is here! Performance on par with OpenAI-o1
Performance on par with OpenAI-o1 Fully open-source model & technical report
Fully open-source model & technical report MIT licensed: Distill & commercialize freely!
MIT licensed: Distill & commercialize freely! Website & API are live now! Try DeepThink at chat.deepseek.com today!
Website & API are live now! Try DeepThink at chat.deepseek.com today! 1/n
1/n




 Deepseek
Deepseek 

