1/9
@petesena
DeepSeek R1 blew my mind.

Is it a breakthrough or a Psyop?

If you are an AI nerd & math idiot like me keep reading.
My big takeaway is RL is underappreciated.
It's also a rally cry for open source which pumps me up.
TLDR;
- Reward and rule systems are a HUGE unlock.
- Innovate under constraints: Bigger doesn't mean better.
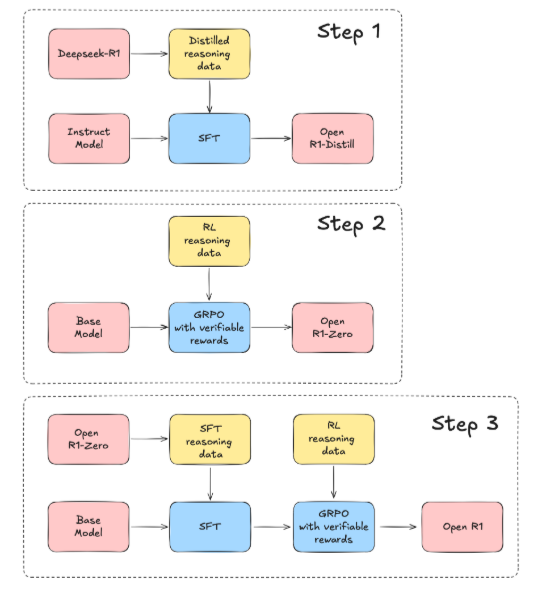
- Model distillation is a smart and cheap hedge
- Nvidia’s CUDA software an “OS for AI” locks in customers; moats aren’t just hardware
- Execution > vision
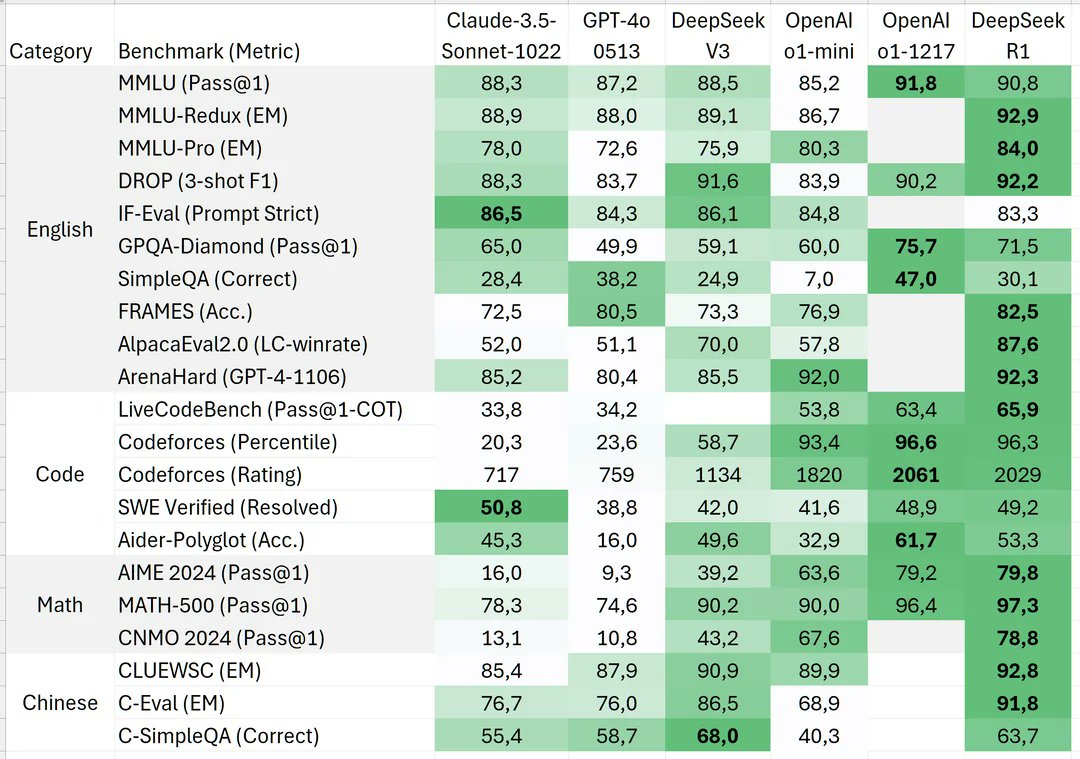
Benchmark:
2/9
@petesena
1/ Diving down the rabbit hole of Reddit and armchair experts revealed a lot of trash and speculation. But there were a few rockstar pieces of insight I found on this journey @doodlestein
The Short Case for Nvidia Stock put out a great read on this.
3/9
@petesena
2/ As companies start to get drunk on the idea of agents they are failing to realize the rat's nest they will need to untangle. Throw more compute at it isn't the solution in most cases. That's why I love the thinking coming out of companies like
Modlee | ML knowledge preservation for the AI era. This whole deepseek stuff (assuming it's not a supercluster psyop) tells me that model distillation and different approaches for training unlock disproportionate results.
4/9
@petesena
3/ Chasing AGI - we're trying to recreate the human brain at a massive scale. Our brains run on something like 20 watts. Everyone is talking about power (electricity + compute), but not enough people are talking about process/approach. While the brain operates on 20 watts, it can perform calculations equivalent to a supercomputer that requires 20 megawatts - making it a million times more energy-efficient. We need smarter ways that aren't just power/compute. Deepseek R1 revealed a kink in Silicon Valley's armor and approach.
5/9
@petesena
4/ DeepSeek vs. The Frontier: Silicon Valley’s Wakeup call.
- Cheaper & Better - ~6M vs GPT-4o 100+M I remember testing Deepseek early and the model Identified itself as OpenAI which points to clear model distillation, why build when you can suck it outta someone else
- Benchmark assassin- They top MATH, Codeforces, and SWE-bench while activating only 37B params
- Hardware constraints = software genius
- Geopolitical jujitsu - US chip bans turned weakness into strength: China’s “innovation under siege” narrative
6/9
@petesena
5/ More proof that accuracy starts with optimization not compute. @tom_doerr "I used DSPy to improve Deepseek V3's accuracy from 14% to 35% when classifying MNIST images, using just the 'light' optimization option."
7/9
@petesena
6/ Stop prompting start programming
DSPy has blown my mind. I used to fancy my prompt engineering ability. Then I started using dspy and evals properly. Damn that's an unlock. thx to @tom_doerr for schooling me.
8/9
@petesena
7/ If you found this remotely useful or interesting shoot me a reply or like. I was always scared to go into AI because my 5th-grade math teacher made me feel stupid. Now I struggle my way through it and write about it here -
Subscribe
AND: It's working

- In under 2 years, I've already built 3 AI companies that do a combined total of 2M in ARR. I'm just getting started. Let's grow together.
9/9
@smdcapital1010
wow
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196




 github.com
github.com

 www.marktechpost.com
www.marktechpost.com







 on LinkedIn: Our science team has started working on fully reproducing and… | 140 comments
on LinkedIn: Our science team has started working on fully reproducing and… | 140 comments