
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
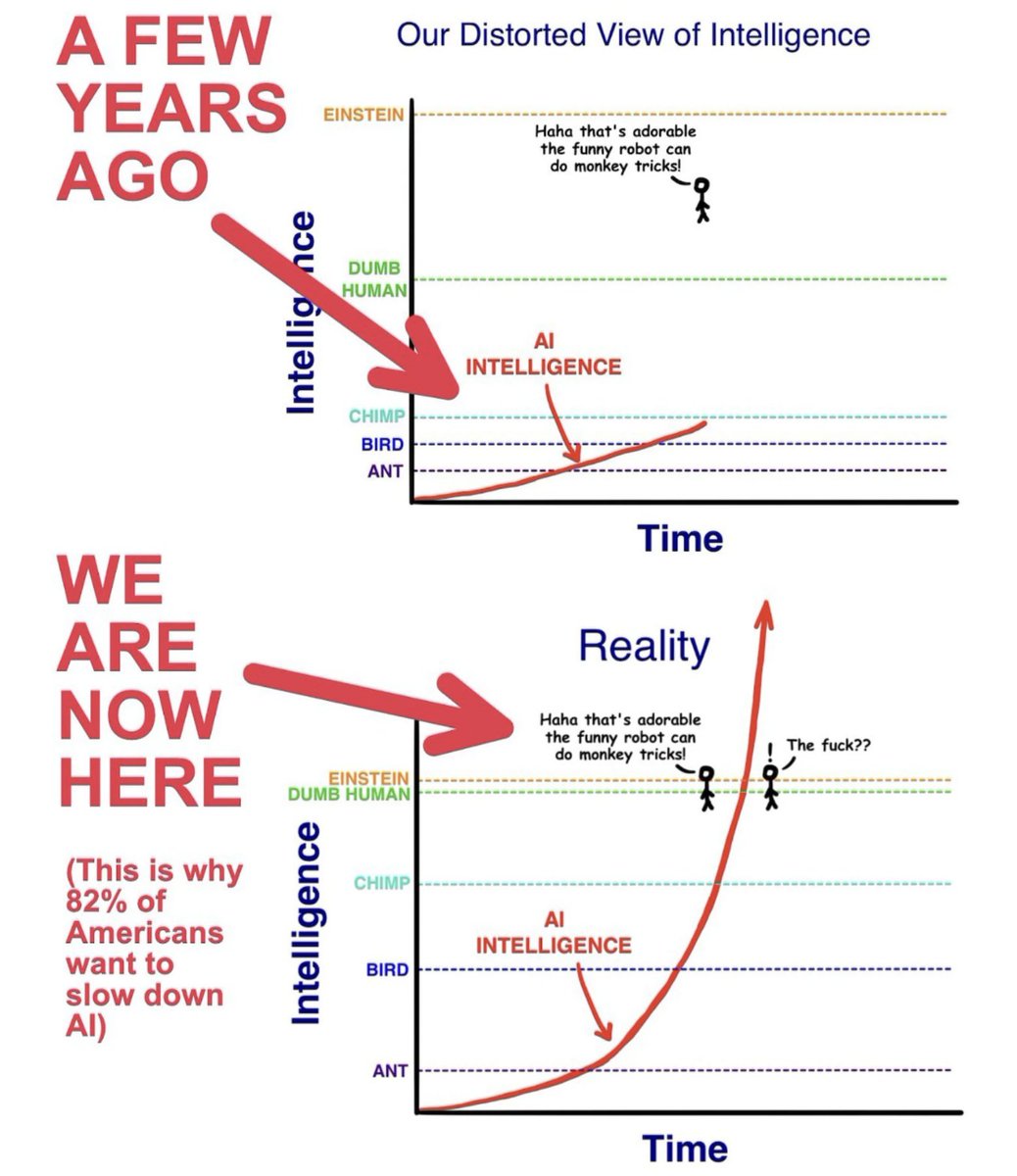
AI that’s smarter than humans? Americans say a firm “no thank you.”
- Thread starter bnew
- Start date
More options
Who Replied?
1/5
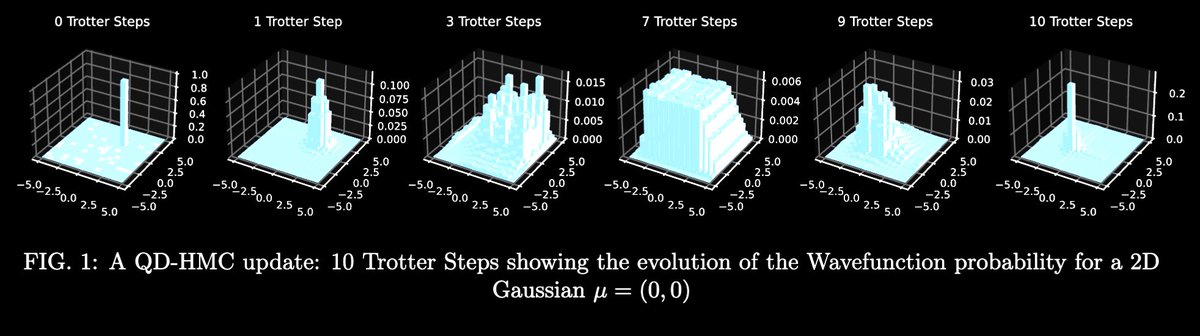
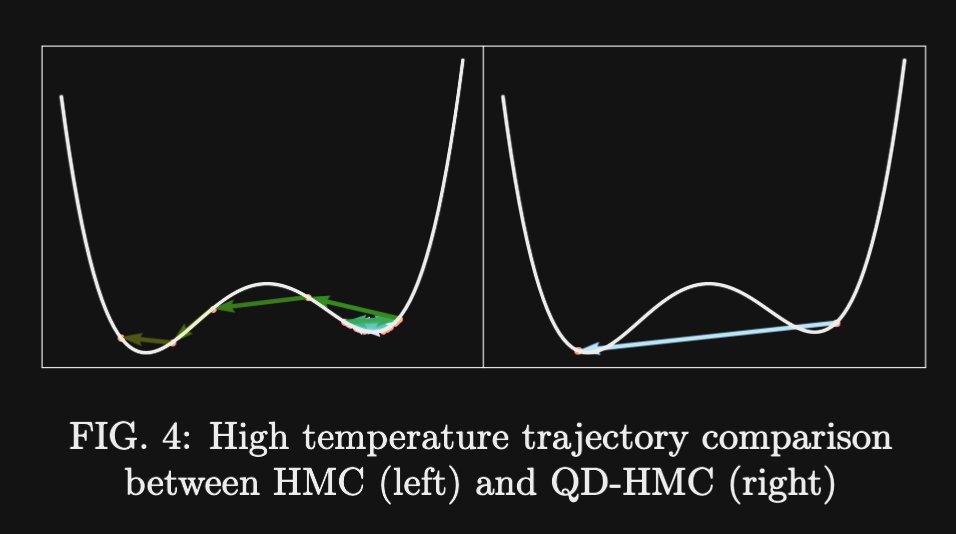
Claude 3 Opus just reinvented this quantum algorithm from scratch in just 2 prompts.
The paper is not on the internet yet.
2/5
cc
@AnthropicAI ya'll definitely cooked
3/5
here is the paper, finally available hours later. As you can see for yourself, Claude pretty much nailed it
4/5
I mean, it basically nailed it. This algorithm is pretty basic but still, I had this paper sitting on a shelf for 2 years and no one wrote it.
5/5
Yeah I'm a pioneer of this subfield (continuous variable quantum optimization)
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Claude 3 Opus just reinvented this quantum algorithm from scratch in just 2 prompts.
The paper is not on the internet yet.
2/5
cc
@AnthropicAI ya'll definitely cooked
3/5
here is the paper, finally available hours later. As you can see for yourself, Claude pretty much nailed it
4/5
I mean, it basically nailed it. This algorithm is pretty basic but still, I had this paper sitting on a shelf for 2 years and no one wrote it.
5/5
Yeah I'm a pioneer of this subfield (continuous variable quantum optimization)
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196




Last edited:

Many people think AI is already sentient - and that's a big problem
A survey of people in the US has revealed the widespread belief that artificial intelligence models are already self-aware, which is very far from the truth
 www.newscientist.com
www.newscientist.com
Many people think AI is already sentient - and that's a big problem
A survey of people in the US has revealed the widespread belief that artificial intelligence models are already self-aware, which is very far from the truthBy Chris Stokel-Walker
18 July 2024
AIs are not yet artificial minds
Panther Media GmbH / Alamy
Around one in five people in the US believe that artificial intelligence is already sentient, while around 30 per cent think that artificial general intelligences (AGIs) capable of performing any task a human can are already in existence. Both beliefs are false, suggesting that the general public has a shaky grasp of the current state of AI – but does it matter?
Jacy Reese Anthis at the Sentience Institute in New York and his colleagues asked a nationally representative sample of 3500 people in the US their perceptions of…
AI and its sentience. The surveys, carried out in three waves between 2021 and 2023, asked questions like “Do you think any robots/AIs that currently exist are sentient?” and whether it could ever be possible for that technology to reach sentience.

How this moment for AI will change society forever (and how it won't)
There is no doubt that the latest advances in artificial intelligence from OpenAI, Google, Baidu and others are more impressive than what came before, but are we in just another bubble of AI hype?
“We wanted to collect data early to understand how public opinion might shape the future trajectory of AI technologies,” says Anthis.
The findings of the survey were surprising, he says. In 2021, around 18 per cent of respondents said they thought AI or robot systems already in existence were sentient – a number that increased to 20 per cent in 2023, when there were two survey waves. One in 10 people asked in 2023 thought ChatGPT, which launched at the end of 2022, was sentient.
“I think we perceive mind very readily in computers,” says Anthis. “We see them as social actors.” He also says that some of the belief in AI sentience is down to big tech companies selling their products as imbued with more abilities than the underlying technology may suggest they have. “There’s a lot of hype in this space,” he says. “As companies have started building their brands around things like AGI, they have a real incentive to talk about how powerful their systems are.”
“There’s a lot of research showing that when somebody has a financial interest in something happening, they are more likely to think it will happen,” says Carissa Véliz at the University of Oxford. “It’s not even that they might be misleading the public or lying. It’s simply that optimism bias is a common problem for humans.”
Read more
How does ChatGPT work and do AI-powered chatbots “think” like us?
Journalists should also take some of the blame, says Kate Devlin at King’s College London. “This isn’t helped by the kind of media coverage we saw around large language models, with overexcited and panicked reports about existential threats from superintelligence.”
Anthis worries that the incorrect belief that AI has a mind, encouraged by the anthropomorphising of AI systems by their makers and the media, is shaping our perception of their abilities. There is a risk that if people believe AI is sentient, they will put more faith than they ought to in its judgements – a concern when AI is being considered for use in government and policing.
One way to avoid this trap is to recast our thinking, says Anthis. “I think people have hyperfocused on the term ‘artificial intelligence’,” he says, pointing out it was little more than a good branding exercise when the term was first coined in the 1950s. People are often impressed at how AI models perform on human IQ tests or standardised exams. “But those are very often the wrong way of thinking of these models,” he says – because the AIs are simply regurgitating answers found in their vast training data, rather than actually “knowing” anything.
Reference
arXiv DOI: 10.48550/arXiv.2407.08867
1/11
gpt-4o mini scoring #2 on arena is historic. the ai train is passing the human intelligence station.
arena is an AI IQ test *and* a human IQ test.
the median arena voter can no longer distinguish between large, smart models and small, smart-sounding models.
models like:
>claude-3.5-sonnet
>caude-3-opus
>gpt-4-0314
feel *so* much smarter to smart people than:
>gpt-4o-mini
>gemini-1.5-flash
>claude-3-haiku
i whine so often about the death of <big_model_smell>. people largely agree. but gpt-4o-mini's victory is substantial proof, imo, that the median person isn't that bright, and that, for the first time in history, the AIs are smart enough to fool us. kinda wild, kinda historic
2/11
Simpler explanation: OpenAI is overfitting on lmsys arena data
3/11
if you think about it, it’s the same explanation lol
4/11
The biggest question I have for you is whether or not you think llama 405 has <big_model_smell>
5/11
it does. my opinion has improved since we last talked. still imperfect (especially with instruction following), but it's reasoning over context is *chefs kisss*
6/11
Or it's yet another dodgy benchmark, like all benchmarks.
No need to be dramatic about it.
7/11
I think the style of the response ends up being more important than the quality of the thinker behind the response. Claude tends to be less verbose, sometimes hesitant, but in a multi turn conversation is in a different league.
It may be as much about the personality of the LLM as its intelligence going forward.
8/11
i like this take.
cause I defo see a BIG difference between large and small models on complex tasks.
9/11
totally irrelevant but absolutely hilarious how literally no one is mentioning/talking about gemini 1.5 pro
10/11
Almost a kind of Turing test
11/11
history is a lot about people getting fooled by smart-sounding things, so in retrospect it isn't that surprising we are able to overfit AIs to it. it doesn't say much about the model's intelligence tho
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
gpt-4o mini scoring #2 on arena is historic. the ai train is passing the human intelligence station.
arena is an AI IQ test *and* a human IQ test.
the median arena voter can no longer distinguish between large, smart models and small, smart-sounding models.
models like:
>claude-3.5-sonnet
>caude-3-opus
>gpt-4-0314
feel *so* much smarter to smart people than:
>gpt-4o-mini
>gemini-1.5-flash
>claude-3-haiku
i whine so often about the death of <big_model_smell>. people largely agree. but gpt-4o-mini's victory is substantial proof, imo, that the median person isn't that bright, and that, for the first time in history, the AIs are smart enough to fool us. kinda wild, kinda historic
2/11
Simpler explanation: OpenAI is overfitting on lmsys arena data
3/11
if you think about it, it’s the same explanation lol
4/11
The biggest question I have for you is whether or not you think llama 405 has <big_model_smell>
5/11
it does. my opinion has improved since we last talked. still imperfect (especially with instruction following), but it's reasoning over context is *chefs kisss*
6/11
Or it's yet another dodgy benchmark, like all benchmarks.
No need to be dramatic about it.
7/11
I think the style of the response ends up being more important than the quality of the thinker behind the response. Claude tends to be less verbose, sometimes hesitant, but in a multi turn conversation is in a different league.
It may be as much about the personality of the LLM as its intelligence going forward.
8/11
i like this take.
cause I defo see a BIG difference between large and small models on complex tasks.
9/11
totally irrelevant but absolutely hilarious how literally no one is mentioning/talking about gemini 1.5 pro
10/11
Almost a kind of Turing test
11/11
history is a lot about people getting fooled by smart-sounding things, so in retrospect it isn't that surprising we are able to overfit AIs to it. it doesn't say much about the model's intelligence tho
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196



1/11
Kind of a big deal: GPT-4 simulates people well enough to replicate social science experiments with high accuracy
Note this is done by having the AI prompted to respond to survey questions as a person given random demographic characteristics & surveying thousands of "AI people"
2/11
I wrote about how this can be huge for marketing research and copywriting Why Talk to Customers When You Can Simulate Them?
3/11
Turns out I'm not that crazy in using ChatGPT to evaluate my search and recommendations models before actual users see them.
Collect enough user demographics, and it should be possible to predict users' perception of the product ahead of time.
4/11
True. AI assistants could revolutionize coaching and mentorship.
5/11
This is fine
6/11
WILD
Because LLM is so cheap and fast compared to real people. At the very least, can use LLM as an initial pass to test how a product or service might be received in the market
So who is going to build the tool around these results? SurveyMonkeys of the world add AI?
7/11
Obviously love your work and regularly cite it in mine. "What I would welcome is some scenarios for in situ applications: people still find it hard to sense and visualise how this will change stuff in actual work settings.
8/11
interesting!
9/11
We think there might be something to these idea.
Someone should build a product that allows everyone to do this.
We even thought of a cool name: Synthetic Users.

10/11
Someone said AI People?
@aipeoplegame
11/11
I've been thinking for a while that we could make much better economic simulations by using LLMs.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
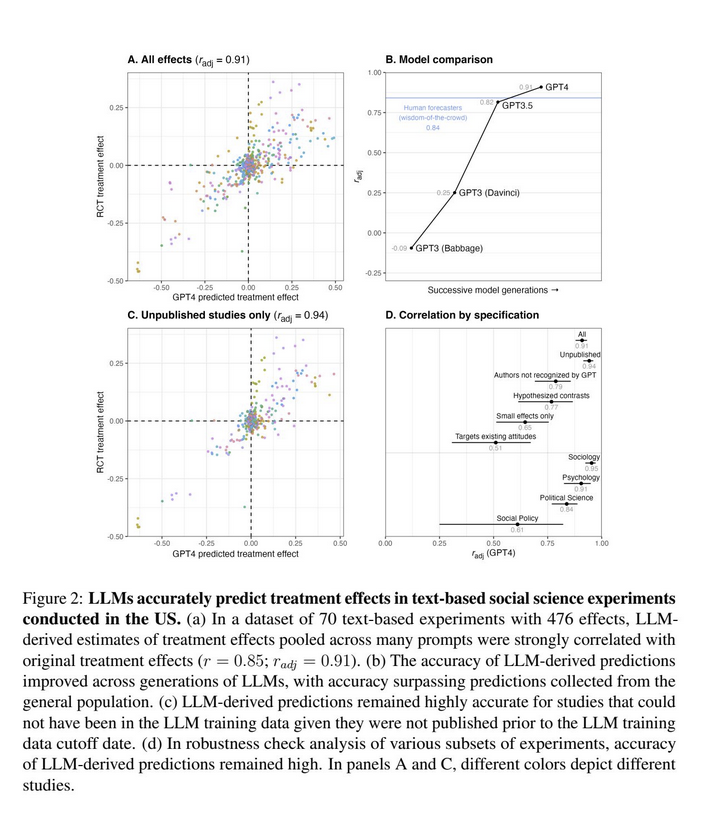
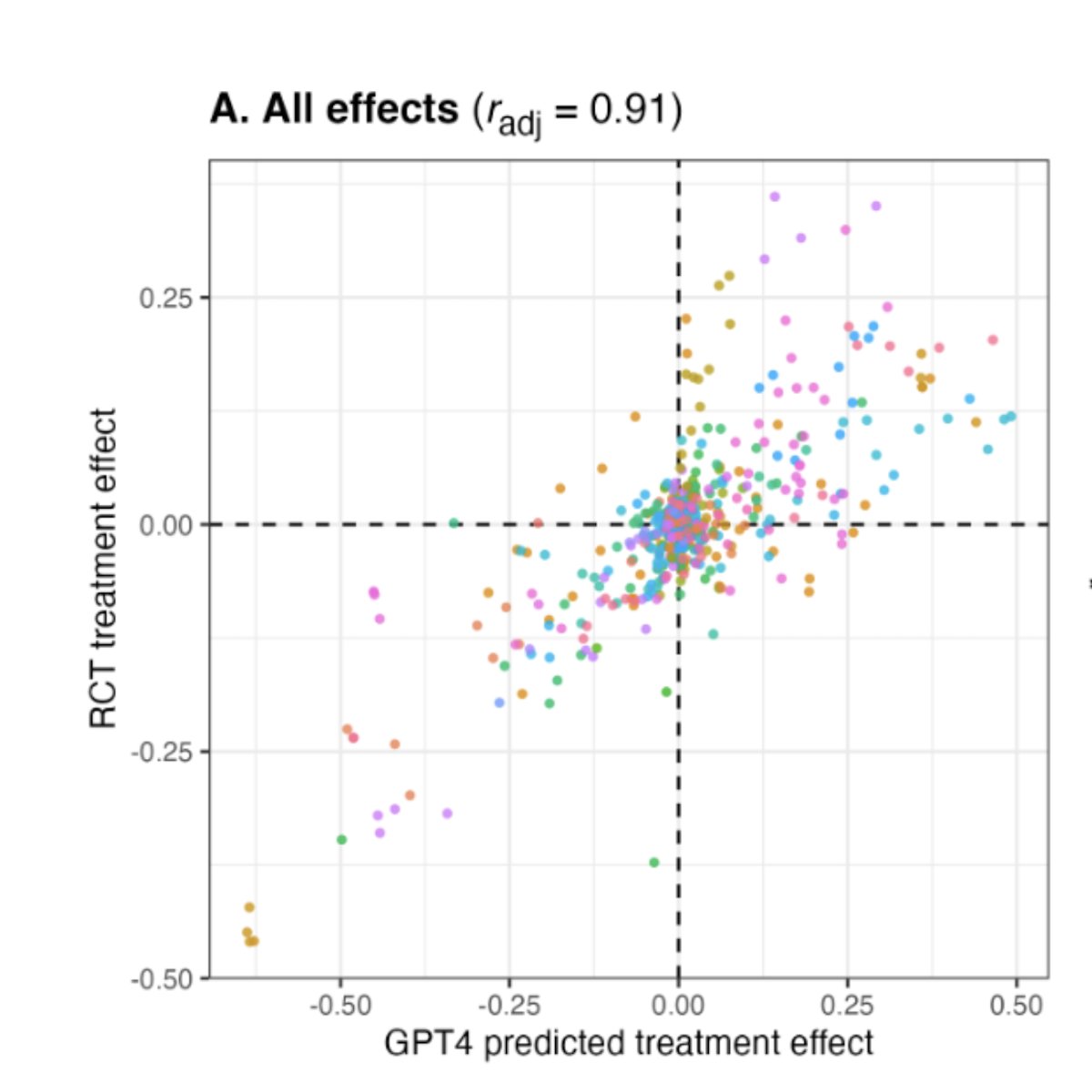
Kind of a big deal: GPT-4 simulates people well enough to replicate social science experiments with high accuracy
Note this is done by having the AI prompted to respond to survey questions as a person given random demographic characteristics & surveying thousands of "AI people"
2/11
I wrote about how this can be huge for marketing research and copywriting Why Talk to Customers When You Can Simulate Them?
3/11
Turns out I'm not that crazy in using ChatGPT to evaluate my search and recommendations models before actual users see them.
Collect enough user demographics, and it should be possible to predict users' perception of the product ahead of time.
4/11
True. AI assistants could revolutionize coaching and mentorship.
5/11
This is fine
6/11
WILD
Because LLM is so cheap and fast compared to real people. At the very least, can use LLM as an initial pass to test how a product or service might be received in the market
So who is going to build the tool around these results? SurveyMonkeys of the world add AI?
7/11
Obviously love your work and regularly cite it in mine. "What I would welcome is some scenarios for in situ applications: people still find it hard to sense and visualise how this will change stuff in actual work settings.
8/11
interesting!
9/11
We think there might be something to these idea.
Someone should build a product that allows everyone to do this.
We even thought of a cool name: Synthetic Users.
10/11
Someone said AI People?
@aipeoplegame
11/11
I've been thinking for a while that we could make much better economic simulations by using LLMs.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196



1/3
The prompt used in the paper 'People Cannot Distinguish GPT-4 from a Human in a Turing Test' is quite revealing about humans.
tldr: "Be dumb"
2/3
Yeah, It's only a 5-minute Turing test.
"GPT-4 was judged to be a human 54% of the time, outperforming ELIZA (22%) but lagging behind actual humans (67%)"
3/3
https://arxiv.org/pdf/2405.08007
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
The prompt used in the paper 'People Cannot Distinguish GPT-4 from a Human in a Turing Test' is quite revealing about humans.
tldr: "Be dumb"
2/3
Yeah, It's only a 5-minute Turing test.
"GPT-4 was judged to be a human 54% of the time, outperforming ELIZA (22%) but lagging behind actual humans (67%)"
3/3
https://arxiv.org/pdf/2405.08007
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

1/3
My view on this has not changed in the past eight years: I have given many talks and written position paper in 2019 (link below). Progress is faster than my past expectation. My target date used to be ~2029 back then. Now it is 2026 for a superhuman AI mathematician. While a stretch, even 2025 is possible.
2/3
That grunt work will be formalization: Too tedious for humans to do at a large scale, but enabling AI to progress (semi-)openendedly, while provinding grounding for its natural language math abilities.
3/3
I expect SWE and sciences to be accelerated significantly by that although at a slower pace than math.
Math has much less friction: any interaction with real world adds complication with data collection, evaluation, deployment, etc.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
My view on this has not changed in the past eight years: I have given many talks and written position paper in 2019 (link below). Progress is faster than my past expectation. My target date used to be ~2029 back then. Now it is 2026 for a superhuman AI mathematician. While a stretch, even 2025 is possible.
2/3
That grunt work will be formalization: Too tedious for humans to do at a large scale, but enabling AI to progress (semi-)openendedly, while provinding grounding for its natural language math abilities.
3/3
I expect SWE and sciences to be accelerated significantly by that although at a slower pace than math.
Math has much less friction: any interaction with real world adds complication with data collection, evaluation, deployment, etc.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/40
Automating AI research is exciting! But can LLMs actually produce novel, expert-level research ideas?
After a year-long study, we obtained the first statistically significant conclusion: LLM-generated ideas are more novel than ideas written by expert human researchers.
2/40
In our new paper: [2409.04109] Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers
We recruited 49 expert NLP researchers to write novel ideas on 7 NLP topics.
We built an LLM agent to generate research ideas on the same 7 topics.
After that, we recruited 79 experts to blindly review all the human and LLM ideas.
2/
3/40
When we say “experts”, we really do mean some of the best people in the field.
Coming from 36 different institutions, our participants are mostly PhDs and postdocs.
As a proxy metric, our idea writers have a median citation count of 125, and our reviewers have 327.
3/
4/40
We specify a very detailed idea template to make sure both human and LLM ideas cover all the necessary details to the extent that a student can easily follow and execute all the steps.
We paid $300 for each idea, plus a $1000 bonus to the top 5 human ideas.
4/
5/40
We also used an LLM to standardize the writing styles of human and LLM ideas to avoid potential confounders, while preserving the original content.
Shown below is a randomly selected LLM-generated idea, as an example of how our ideas look like.
5/
6/40
Our 79 expert reviewers submitted 298 reviews in total, so each idea got 2-4 independent reviews.
Our review form is inspired by ICLR & ACL, with breakdown scores + rationales on novelty, excitement, feasibility, and expected effectiveness, apart from the overall score.
6/
7/40
With these high-quality human ideas and reviews, we compare the results.
We performed 3 different statistical tests accounting for all the possible confounders we could think of.
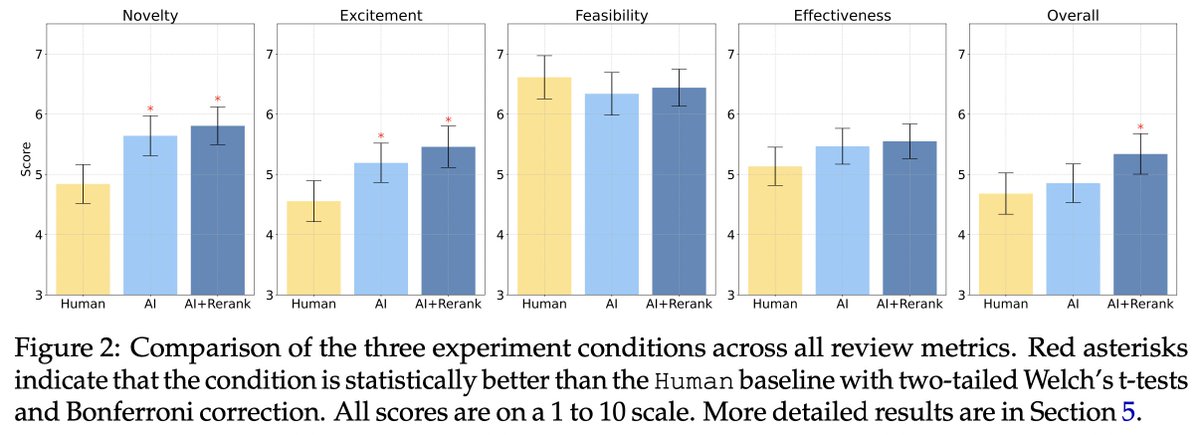
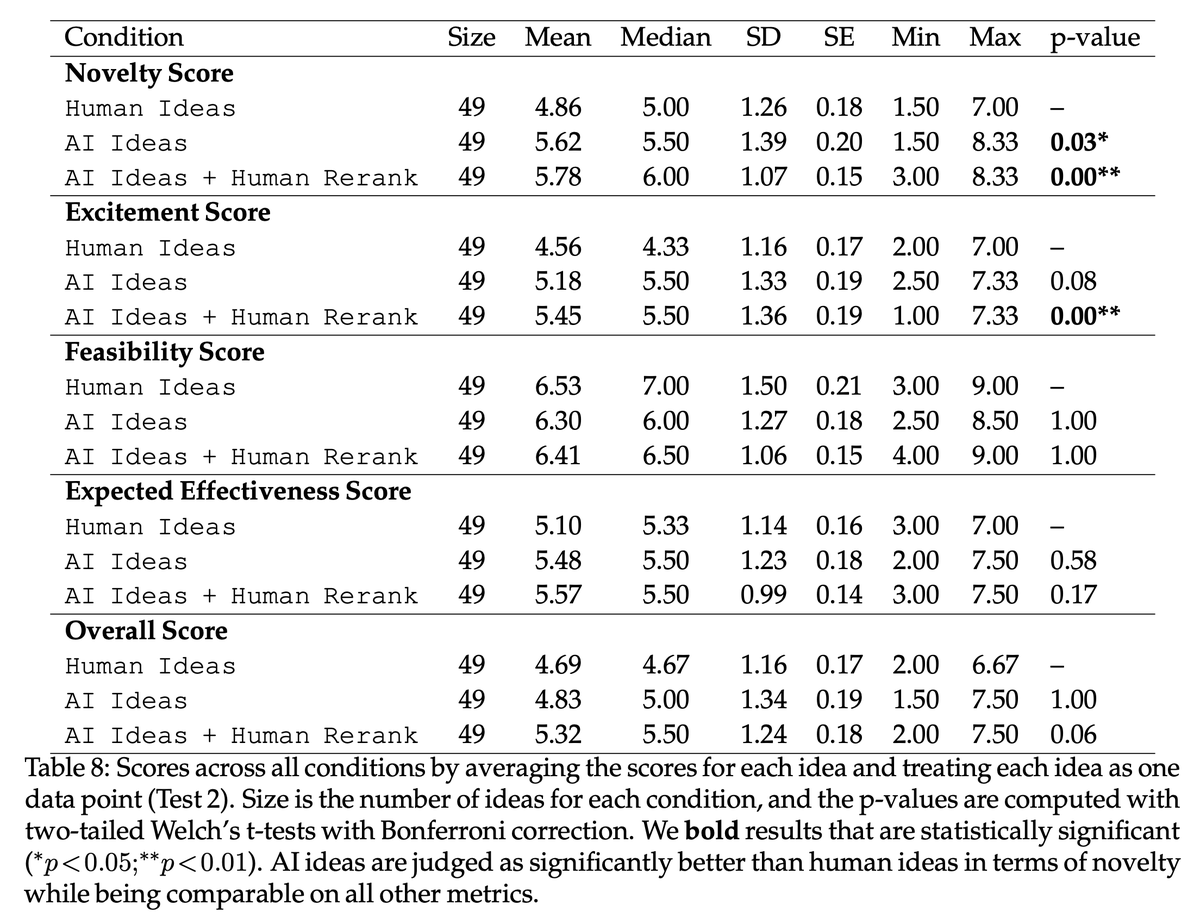
It holds robustly that LLM ideas are rated as significantly more novel than human expert ideas.
7/
8/40
Apart from the human-expert comparison, I’ll also highlight two interesting analyses of LLMs:
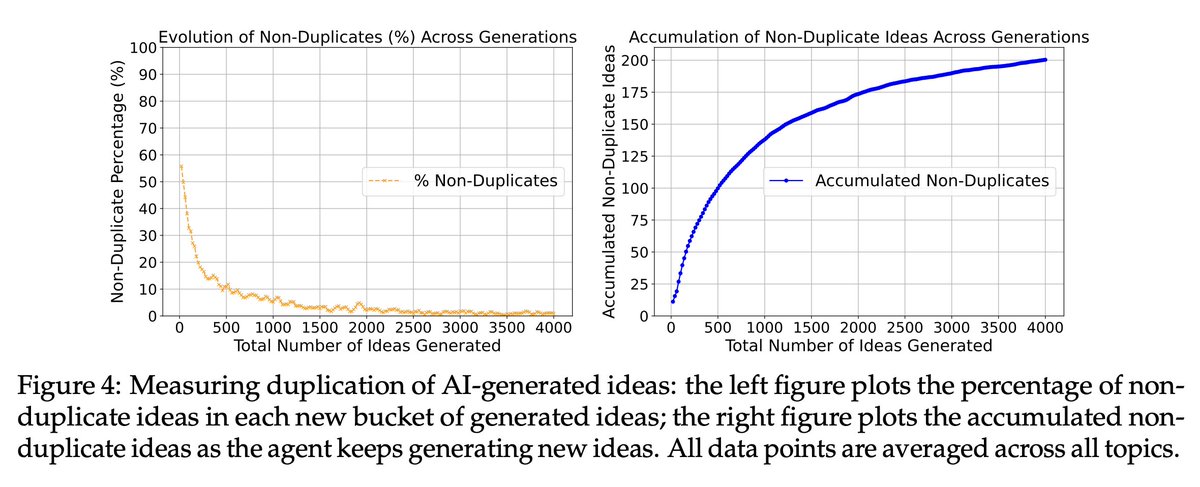
First, we find LLMs lack diversity in idea generation. They quickly start repeating previously generated ideas even though we explicitly told them not to.
8/
9/40
Second, LLMs cannot evaluate ideas reliably yet. When we benchmarked previous automatic LLM reviewers against human expert reviewers using our ideas and reviewer scores, we found that all LLM reviewers showed a low agreement with human judgments.
9/
10/40
We include many more quantitative and qualitative analyses in the paper, including examples of human and LLM ideas with the corresponding expert reviews, a summary of experts’ free-text reviews, and our thoughts on how to make progress in this emerging research direction.
10/
11/40
For the next step, we are recruiting more expert participants for the second phase of our study, where experts will implement AI and human ideas into full projects for a more reliable evaluation based on real research outcomes.
Sign-up link: Interest Form for Participating in the AI Researcher Human Study (Execution Stage)
11/
12/40
This project wouldn't have been possible without our amazing participants who wrote and reviewed ideas. We can't name them publicly yet as more experiments are ongoing and we need to preserve anonymity. But I want to thank you all for your tremendous support!!
12/
13/40
Also shout out to many friends who offered me helpful advice and mental support, esp. @rose_e_wang @dorazhao9 @aryaman2020 @irena_gao @kenziyuliu @harshytj__ @IsabelOGallegos @ihsgnef @gaotianyu1350 @xinranz3 @xiye_nlp @YangjunR @neilbband @mertyuksekgonul @JihyeonJe
13/
14/40
Finally I want to thank my supportive, energetic, insightful, and fun advisors @tatsu_hashimoto @Diyi_Yang
Thank you for teaching me how to do the most exciting research in the most rigorous way, and letting me spend so much time and $$$ on this crazy project!
14/14
15/40
Great work and cool findings. I have to say there is a huge confounding factor that is intrinsic motivation. Experts ( here PhD students) might not be sharing their best novel ideas because the incentive is monetary instead of publication which brings in long term benefits for students such as job offers/ prestige/ visibility. Your section 6.1 already mentions this.
Another confounding factor is time. Do you think best research / good work happens in 10 days ? I personally have never been able to come up with a good idea in 10 days. But at the same time I don’t know if an LLM can match my ideation ( at-least not yet)
16/40
this is a really cool study!
did the LLM idea's get ran past a Google search? i see the novelty scores for LLM idea's are higher but i've personally noticed asking for novel idea's sometimes results in copy-pasta from the LLM from obscure blog posts/research papers
17/40
18/40
This is cool! Want to come on my podcast and chat about it?
19/40
Great read thank you!
20/40
awesome study! but whats the creativity worth if it’s less feasible?
in my own experience it often suggests ideas that are flawed in some fundamental regards that it misses.
theres only so much facts and constraints the attention mechanism can take into account
21/40
Your thread is very popular today! /search?q=#TopUnroll Thread by @ChengleiSi on Thread Reader App @vankous for
@vankous for  unroll
unroll
22/40
in my paper"Automating psychological hypothesis generation with AI: when large language models meet causal graph" Automating psychological hypothesis generation with AI: when large language models meet causal graph - Humanities and Social Sciences Communications , we have approved our workflow/algo can even generate novel hypothesis better than GPT4 and Phd .
23/40
What is the best rated LLM generated idea?
24/40
looks like we're out of a job
25/40
Skynet when tho?
26/40
Interesting! I may be doing he exact same experiment, only I let both ChatGPT and Claude participate in a language experiment I choose.
27/40
Interesting work, but would be interesting to know which LLM and prompts were used for this.
28/40
I'd love to see some examples of these novel research ideas. How do they hold up in peer review and actual experimentation?
29/40
All words are arbitrary, yet NLP is a field that treats language and words as statistically significant, excluding the social semiotic and status gain illusions inherent to language. So NLP begins as a notably degenerate field. A novel idea in NLP is technically oxymoronic.
30/40
@threadreaderapp unroll
31/40
Question, if you believe this result, are you going to switch to primarily using LLMs to pick research ideas for yourself?
32/40
Great work! Novelty can be subjective, varying with a topic’s maturity and reviewers’ perspectives. Rather than fully automating research, building practical LLM research assistants could be exciting. Looking forward to the next stage, making LLM research agents more powerful!
33/40
Nice job eager to read. One question, what if you change the topic… biology, math, arts?
34/40
kudos, super refreshing to see people invest in long term and interesting questions! gg
35/40
asking chatgpt to come up with a product, "an angry birds delivery dating app", VCs are jumping through my window, slapping my face with wads of cash
36/40
@Piniisima
37/40
Hahahahahahahahahahah, no.
38/40
Did LLMs write this derivative drivel?
39/40
大佬牛逼
40/40
The infinite unknown is a temptation, and in the face of the limits of our feelings we always have room to manoeuvre. Understanding is only the starting point for crossing over.Creation is the temptation to go beyond the unknown.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Automating AI research is exciting! But can LLMs actually produce novel, expert-level research ideas?
After a year-long study, we obtained the first statistically significant conclusion: LLM-generated ideas are more novel than ideas written by expert human researchers.
2/40
In our new paper: [2409.04109] Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers
We recruited 49 expert NLP researchers to write novel ideas on 7 NLP topics.
We built an LLM agent to generate research ideas on the same 7 topics.
After that, we recruited 79 experts to blindly review all the human and LLM ideas.
2/
3/40
When we say “experts”, we really do mean some of the best people in the field.
Coming from 36 different institutions, our participants are mostly PhDs and postdocs.
As a proxy metric, our idea writers have a median citation count of 125, and our reviewers have 327.
3/
4/40
We specify a very detailed idea template to make sure both human and LLM ideas cover all the necessary details to the extent that a student can easily follow and execute all the steps.
We paid $300 for each idea, plus a $1000 bonus to the top 5 human ideas.
4/
5/40
We also used an LLM to standardize the writing styles of human and LLM ideas to avoid potential confounders, while preserving the original content.
Shown below is a randomly selected LLM-generated idea, as an example of how our ideas look like.
5/
6/40
Our 79 expert reviewers submitted 298 reviews in total, so each idea got 2-4 independent reviews.
Our review form is inspired by ICLR & ACL, with breakdown scores + rationales on novelty, excitement, feasibility, and expected effectiveness, apart from the overall score.
6/
7/40
With these high-quality human ideas and reviews, we compare the results.
We performed 3 different statistical tests accounting for all the possible confounders we could think of.
It holds robustly that LLM ideas are rated as significantly more novel than human expert ideas.
7/
8/40
Apart from the human-expert comparison, I’ll also highlight two interesting analyses of LLMs:
First, we find LLMs lack diversity in idea generation. They quickly start repeating previously generated ideas even though we explicitly told them not to.
8/
9/40
Second, LLMs cannot evaluate ideas reliably yet. When we benchmarked previous automatic LLM reviewers against human expert reviewers using our ideas and reviewer scores, we found that all LLM reviewers showed a low agreement with human judgments.
9/
10/40
We include many more quantitative and qualitative analyses in the paper, including examples of human and LLM ideas with the corresponding expert reviews, a summary of experts’ free-text reviews, and our thoughts on how to make progress in this emerging research direction.
10/
11/40
For the next step, we are recruiting more expert participants for the second phase of our study, where experts will implement AI and human ideas into full projects for a more reliable evaluation based on real research outcomes.
Sign-up link: Interest Form for Participating in the AI Researcher Human Study (Execution Stage)
11/
12/40
This project wouldn't have been possible without our amazing participants who wrote and reviewed ideas. We can't name them publicly yet as more experiments are ongoing and we need to preserve anonymity. But I want to thank you all for your tremendous support!!
12/
13/40
Also shout out to many friends who offered me helpful advice and mental support, esp. @rose_e_wang @dorazhao9 @aryaman2020 @irena_gao @kenziyuliu @harshytj__ @IsabelOGallegos @ihsgnef @gaotianyu1350 @xinranz3 @xiye_nlp @YangjunR @neilbband @mertyuksekgonul @JihyeonJe
13/
14/40
Finally I want to thank my supportive, energetic, insightful, and fun advisors @tatsu_hashimoto @Diyi_Yang
Thank you for teaching me how to do the most exciting research in the most rigorous way, and letting me spend so much time and $$$ on this crazy project!
14/14
15/40
Great work and cool findings. I have to say there is a huge confounding factor that is intrinsic motivation. Experts ( here PhD students) might not be sharing their best novel ideas because the incentive is monetary instead of publication which brings in long term benefits for students such as job offers/ prestige/ visibility. Your section 6.1 already mentions this.
Another confounding factor is time. Do you think best research / good work happens in 10 days ? I personally have never been able to come up with a good idea in 10 days. But at the same time I don’t know if an LLM can match my ideation ( at-least not yet)
16/40
this is a really cool study!
did the LLM idea's get ran past a Google search? i see the novelty scores for LLM idea's are higher but i've personally noticed asking for novel idea's sometimes results in copy-pasta from the LLM from obscure blog posts/research papers
17/40
18/40
This is cool! Want to come on my podcast and chat about it?
19/40
Great read thank you!
20/40
awesome study! but whats the creativity worth if it’s less feasible?
in my own experience it often suggests ideas that are flawed in some fundamental regards that it misses.
theres only so much facts and constraints the attention mechanism can take into account
21/40
Your thread is very popular today! /search?q=#TopUnroll Thread by @ChengleiSi on Thread Reader App
@vankous for unroll22/40
in my paper"Automating psychological hypothesis generation with AI: when large language models meet causal graph" Automating psychological hypothesis generation with AI: when large language models meet causal graph - Humanities and Social Sciences Communications , we have approved our workflow/algo can even generate novel hypothesis better than GPT4 and Phd .
23/40
What is the best rated LLM generated idea?
24/40
looks like we're out of a job
25/40
Skynet when tho?
26/40
Interesting! I may be doing he exact same experiment, only I let both ChatGPT and Claude participate in a language experiment I choose.
27/40
Interesting work, but would be interesting to know which LLM and prompts were used for this.
28/40
I'd love to see some examples of these novel research ideas. How do they hold up in peer review and actual experimentation?
29/40
All words are arbitrary, yet NLP is a field that treats language and words as statistically significant, excluding the social semiotic and status gain illusions inherent to language. So NLP begins as a notably degenerate field. A novel idea in NLP is technically oxymoronic.
30/40
@threadreaderapp unroll
31/40
Question, if you believe this result, are you going to switch to primarily using LLMs to pick research ideas for yourself?
32/40
Great work! Novelty can be subjective, varying with a topic’s maturity and reviewers’ perspectives. Rather than fully automating research, building practical LLM research assistants could be exciting. Looking forward to the next stage, making LLM research agents more powerful!
33/40
Nice job eager to read. One question, what if you change the topic… biology, math, arts?
34/40
kudos, super refreshing to see people invest in long term and interesting questions! gg
35/40
asking chatgpt to come up with a product, "an angry birds delivery dating app", VCs are jumping through my window, slapping my face with wads of cash
36/40
@Piniisima
37/40
Hahahahahahahahahahah, no.
38/40
Did LLMs write this derivative drivel?
39/40
大佬牛逼
40/40
The infinite unknown is a temptation, and in the face of the limits of our feelings we always have room to manoeuvre. Understanding is only the starting point for crossing over.Creation is the temptation to go beyond the unknown.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196












1/40
Automating AI research is exciting! But can LLMs actually produce novel, expert-level research ideas?
After a year-long study, we obtained the first statistically significant conclusion: LLM-generated ideas are more novel than ideas written by expert human researchers.




The average human will play no part in the decisions going forward. It's like saying the average human is firmly against nukes
1/22
@SGRodriques
Introducing PaperQA2, the first AI agent that conducts entire scientific literature reviews on its own.
PaperQA2 is also the first agent to beat PhD and Postdoc-level biology researchers on multiple literature research tasks, as measured both by accuracy on objective benchmarks and assessments by human experts. We are publishing a paper and open-sourcing the code.
This is the first example of AI agents exceeding human performance on a major portion of scientific research, and will be a game-changer for the way humans interact with the scientific literature.
Paper and code are below, and congratulations in particular to @m_skarlinski, @SamCox822, @jonmlaurent, James Braza, @MichaelaThinks, @mjhammerling, @493Raghava, @andrewwhite01, and others who pulled this off. 1/
2/22
@SGRodriques
PaperQA2 finds and summarizes relevant literature, refines its search parameters based on what it finds, and provides cited, factually grounded answers that are more accurate on average than answers provided by PhD and postdoc-level biologists. When applied to answer highly specific questions, like this one, it obtains SOTA performance on LitQA2, part of LAB-Bench focused on information retrieval. 2/
3/22
@SGRodriques
PaperQA2 can also do broad-based literature reviews. WikiCrow, which is an agent based on PaperQA2, writes Wikipedia-style articles that are significantly more accurate on average than actual human-written articles on Wikipedia, as judged by PhD and postdoc-level biologists. We are using WikiCrow to write updated summaries of all 20,000 genes in the human genome. They are still being written, but in the meantime see a preview: WikiCrow | FutureHouse 3/
4/22
@SGRodriques
We spent a lot of effort on making our open source version be excellent. We put together a new system of building metadata of arbitrary PDFs, full-text search, and more. See it here: GitHub - Future-House/paper-qa: High accuracy RAG for answering questions from scientific documents with citations 4/
5/22
@SGRodriques
Also, see our preprint for details, here: http://paper.wikicrow.ai 5/
6/22
@SGRodriques
And, of course, this was all made possible through the wonderful generosity of Eric and Wendy Schmidt, and all of our other funders, including Open Philanthropy for supporting our work on LitQA2, the NSF National AI Resource program, and others! 6/
7/22
@micksabox
Massive respect to you and team! This is incredibly important and thank you for open sourcing
8/22
@KyivskyRus
Wow, super cool!
9/22
@postholer
"Exceeding human performance" which translates into "still has errors".
Using lossy techniques like AI are fine for art, music, etc. For subject matter that must be absolute, lossy techniques will not work.
Compress your perfect data in a lossy compression format, uncompress it, and you have AI equivalent results.
10/22
@BenBlaiszik
This is great work @SGRodriques! If I understand this correctly, the open source version requires downloaded pdfs in the folder structure. Just imagine what you could achieve if there was easy programmatic access to all publications and precomputed embeddings. Can someone just buy out the journal rights?
11/22
@DeryaTR_
Outstanding work! Will check it out soon.
12/22
@threadreaderapp
Your thread is going viral! /search?q=#TopUnroll Thread by @SGRodriques on Thread Reader App@Hijo_de_Juan for unroll
13/22
@ChenSun92
Awesome work @SGRodriques! Really excited to see this out
14/22
@vincentweisser
Awesome work Sam and team!!
15/22
@the_apollonic
@omni_american & @PsychRabble
16/22
@JenuineT2
But can it tell signal from noise? Remember, over half of research findings are false.
17/22
@nikitastaf1996
I keep seeing human level ai performances. But almost all of them are mediated by extremely complex purpose built harness. And in some cases model is fine-tuned. I can't wait for models that can operate at that level but generally and without complicated harnesses.
18/22
@an_chomsky
I'm sure this is very good, but I'm " " about the benchmarking. I gave it 40 papers concerning my PhD research & asked it a simple question, it gave me an answer I'd have failed had I received it from an undergrad. Also, maybe a bug with the CLI, but output was truncated.
" about the benchmarking. I gave it 40 papers concerning my PhD research & asked it a simple question, it gave me an answer I'd have failed had I received it from an undergrad. Also, maybe a bug with the CLI, but output was truncated.
19/22
@MonadOkamoto
Some will find themselves faced with their own contradictions.
20/22
@j0hnparkhill
Well, we don't need to worry about this agent being self aware.
21/22
@mttrdmnd
This is so cool! Off to try it on some random PDFs I’ve got lying around
22/22
@dellassembler
Great work
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@SGRodriques
Introducing PaperQA2, the first AI agent that conducts entire scientific literature reviews on its own.
PaperQA2 is also the first agent to beat PhD and Postdoc-level biology researchers on multiple literature research tasks, as measured both by accuracy on objective benchmarks and assessments by human experts. We are publishing a paper and open-sourcing the code.
This is the first example of AI agents exceeding human performance on a major portion of scientific research, and will be a game-changer for the way humans interact with the scientific literature.
Paper and code are below, and congratulations in particular to @m_skarlinski, @SamCox822, @jonmlaurent, James Braza, @MichaelaThinks, @mjhammerling, @493Raghava, @andrewwhite01, and others who pulled this off. 1/
2/22
@SGRodriques
PaperQA2 finds and summarizes relevant literature, refines its search parameters based on what it finds, and provides cited, factually grounded answers that are more accurate on average than answers provided by PhD and postdoc-level biologists. When applied to answer highly specific questions, like this one, it obtains SOTA performance on LitQA2, part of LAB-Bench focused on information retrieval. 2/
3/22
@SGRodriques
PaperQA2 can also do broad-based literature reviews. WikiCrow, which is an agent based on PaperQA2, writes Wikipedia-style articles that are significantly more accurate on average than actual human-written articles on Wikipedia, as judged by PhD and postdoc-level biologists. We are using WikiCrow to write updated summaries of all 20,000 genes in the human genome. They are still being written, but in the meantime see a preview: WikiCrow | FutureHouse 3/
4/22
@SGRodriques
We spent a lot of effort on making our open source version be excellent. We put together a new system of building metadata of arbitrary PDFs, full-text search, and more. See it here: GitHub - Future-House/paper-qa: High accuracy RAG for answering questions from scientific documents with citations 4/
5/22
@SGRodriques
Also, see our preprint for details, here: http://paper.wikicrow.ai 5/
6/22
@SGRodriques
And, of course, this was all made possible through the wonderful generosity of Eric and Wendy Schmidt, and all of our other funders, including Open Philanthropy for supporting our work on LitQA2, the NSF National AI Resource program, and others! 6/
7/22
@micksabox
Massive respect to you and team! This is incredibly important and thank you for open sourcing
8/22
@KyivskyRus
Wow, super cool!
9/22
@postholer
"Exceeding human performance" which translates into "still has errors".
Using lossy techniques like AI are fine for art, music, etc. For subject matter that must be absolute, lossy techniques will not work.
Compress your perfect data in a lossy compression format, uncompress it, and you have AI equivalent results.
10/22
@BenBlaiszik
This is great work @SGRodriques! If I understand this correctly, the open source version requires downloaded pdfs in the folder structure. Just imagine what you could achieve if there was easy programmatic access to all publications and precomputed embeddings. Can someone just buy out the journal rights?
11/22
@DeryaTR_
Outstanding work! Will check it out soon.
12/22
@threadreaderapp
Your thread is going viral! /search?q=#TopUnroll Thread by @SGRodriques on Thread Reader App
@Hijo_de_Juan for unroll13/22
@ChenSun92
Awesome work @SGRodriques! Really excited to see this out
14/22
@vincentweisser
Awesome work Sam and team!!
15/22
@the_apollonic
@omni_american & @PsychRabble
16/22
@JenuineT2
But can it tell signal from noise? Remember, over half of research findings are false.
17/22
@nikitastaf1996
I keep seeing human level ai performances. But almost all of them are mediated by extremely complex purpose built harness. And in some cases model is fine-tuned. I can't wait for models that can operate at that level but generally and without complicated harnesses.
18/22
@an_chomsky
I'm sure this is very good, but I'm "
" about the benchmarking. I gave it 40 papers concerning my PhD research & asked it a simple question, it gave me an answer I'd have failed had I received it from an undergrad. Also, maybe a bug with the CLI, but output was truncated.19/22
@MonadOkamoto
Some will find themselves faced with their own contradictions.
20/22
@j0hnparkhill
Well, we don't need to worry about this agent being self aware.
21/22
@mttrdmnd
This is so cool! Off to try it on some random PDFs I’ve got lying around
22/22
@dellassembler
Great work
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196



Similar threads
- Replies
- 9
- Views
- 669