1/50
@deedydas
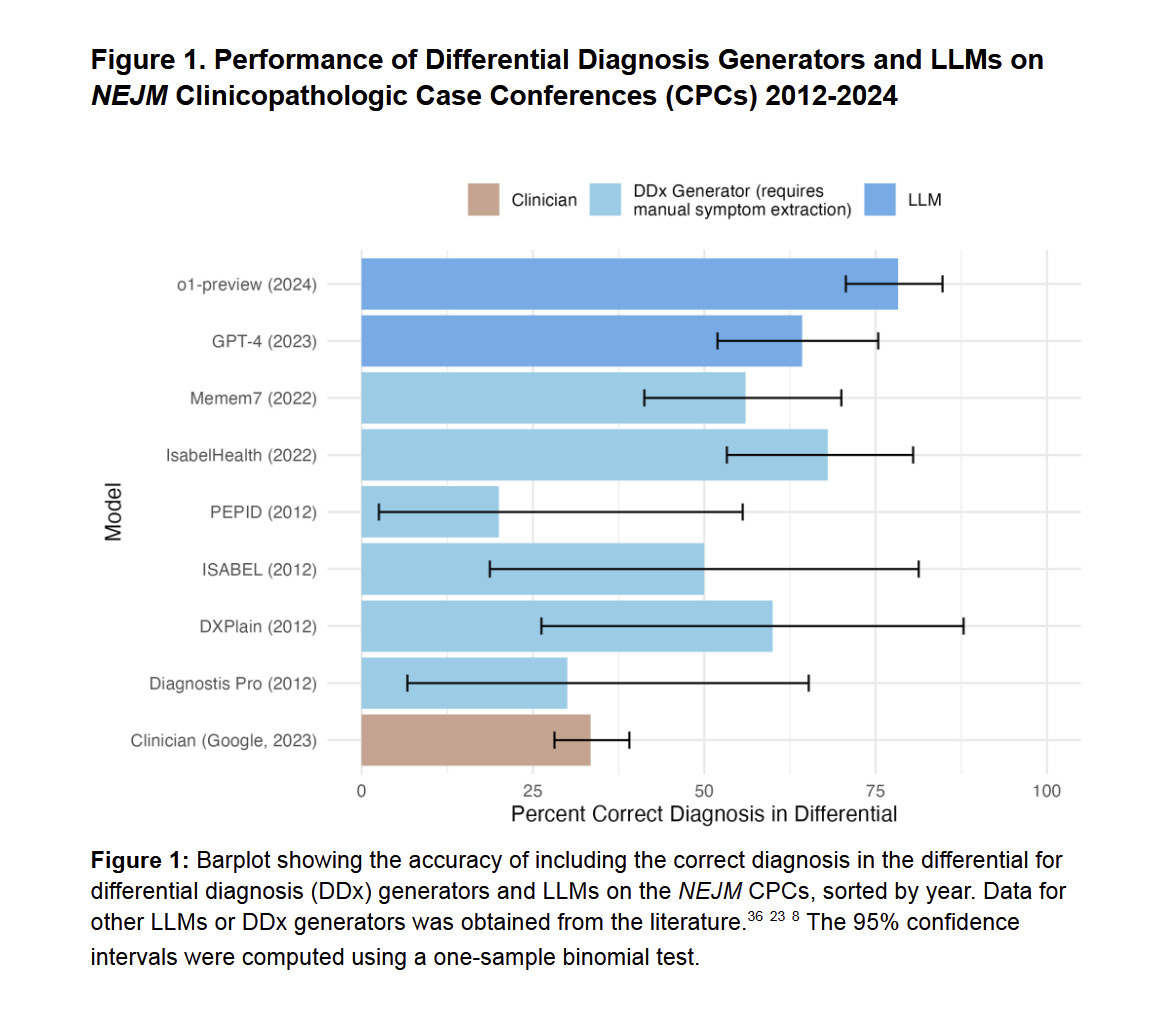
o1-preview is far superior to doctors on reasoning tasks and it's not even close, according to OpenAI's latest paper.
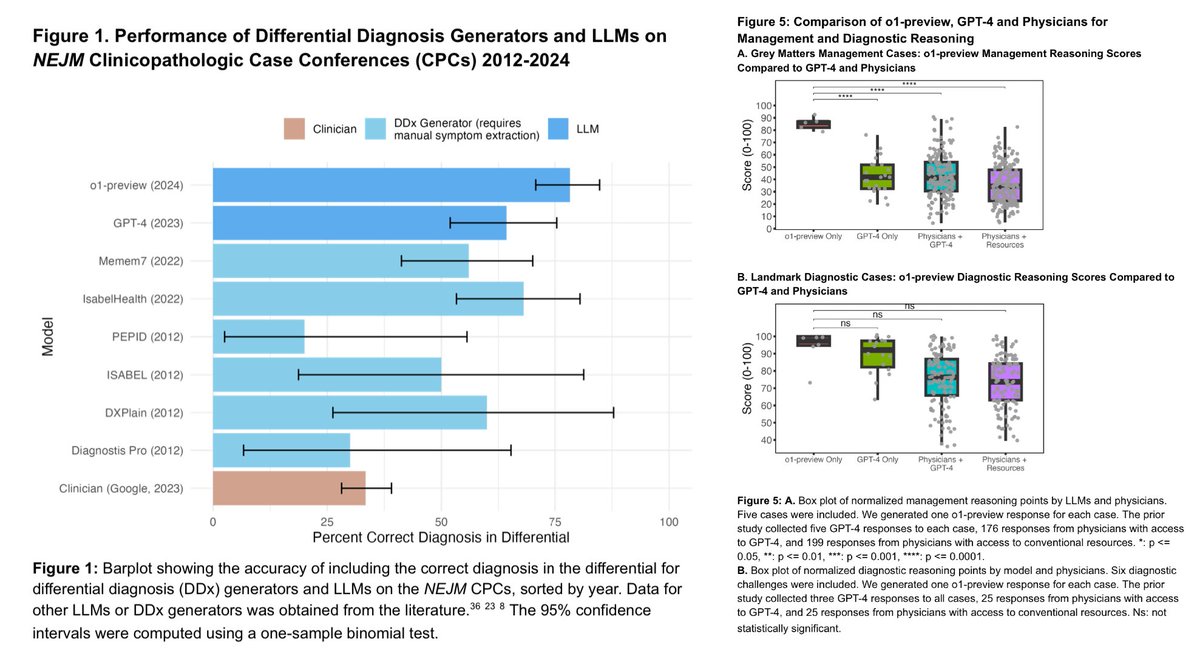
AI does ~80% vs ~30% on the 143 hard NEJM CPC diagnoses.
It's dangerous now to trust your doctor and NOT consult an AI model.
Here are some actual tasks:
1/5
2/50
@deedydas
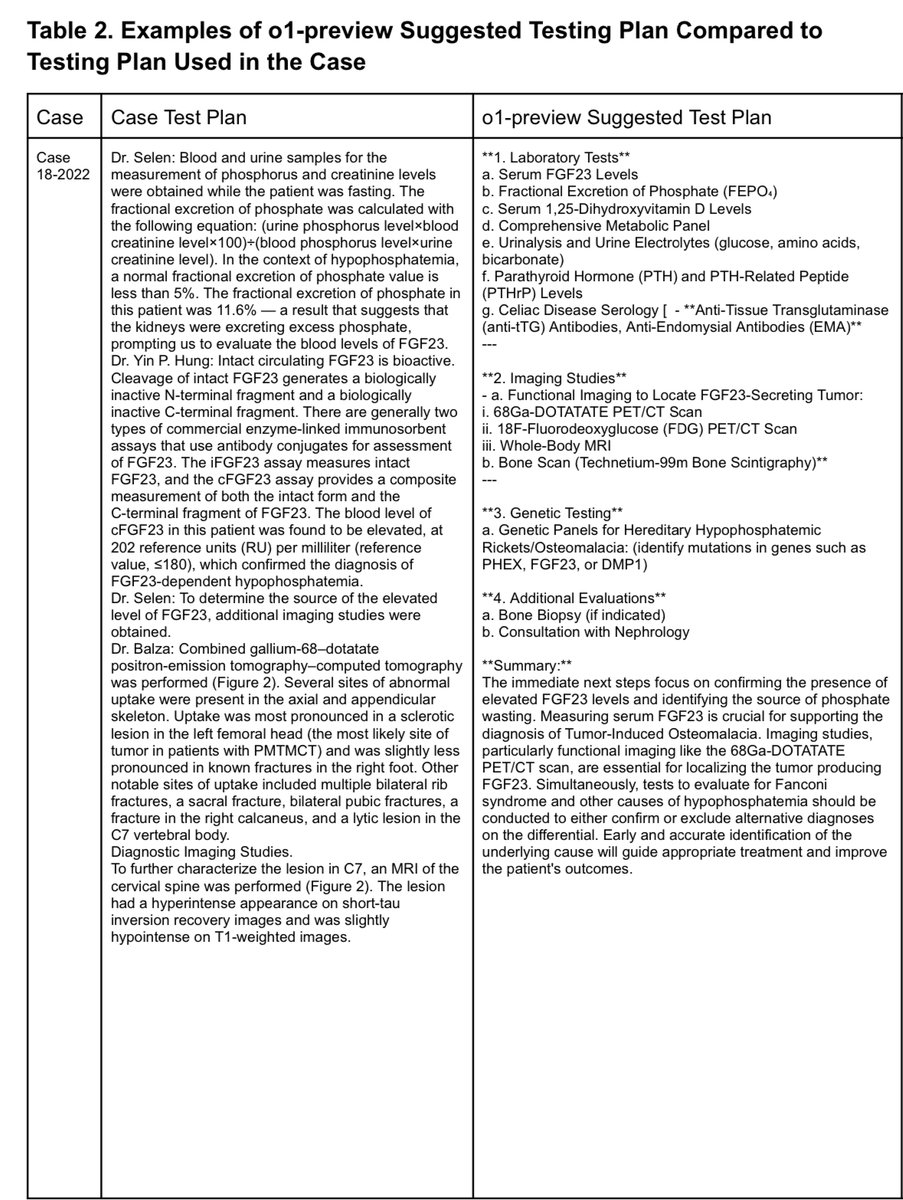
Here's an example case looking at phosphate wasting and elevated FGF23, then proceeded to imaging to localize a potential tumor.
o1-preview suggested testing plan takes a broader, more methodical approach, systematically ruling out other causes of hypophosphatemia.
2/5
3/50
@deedydas
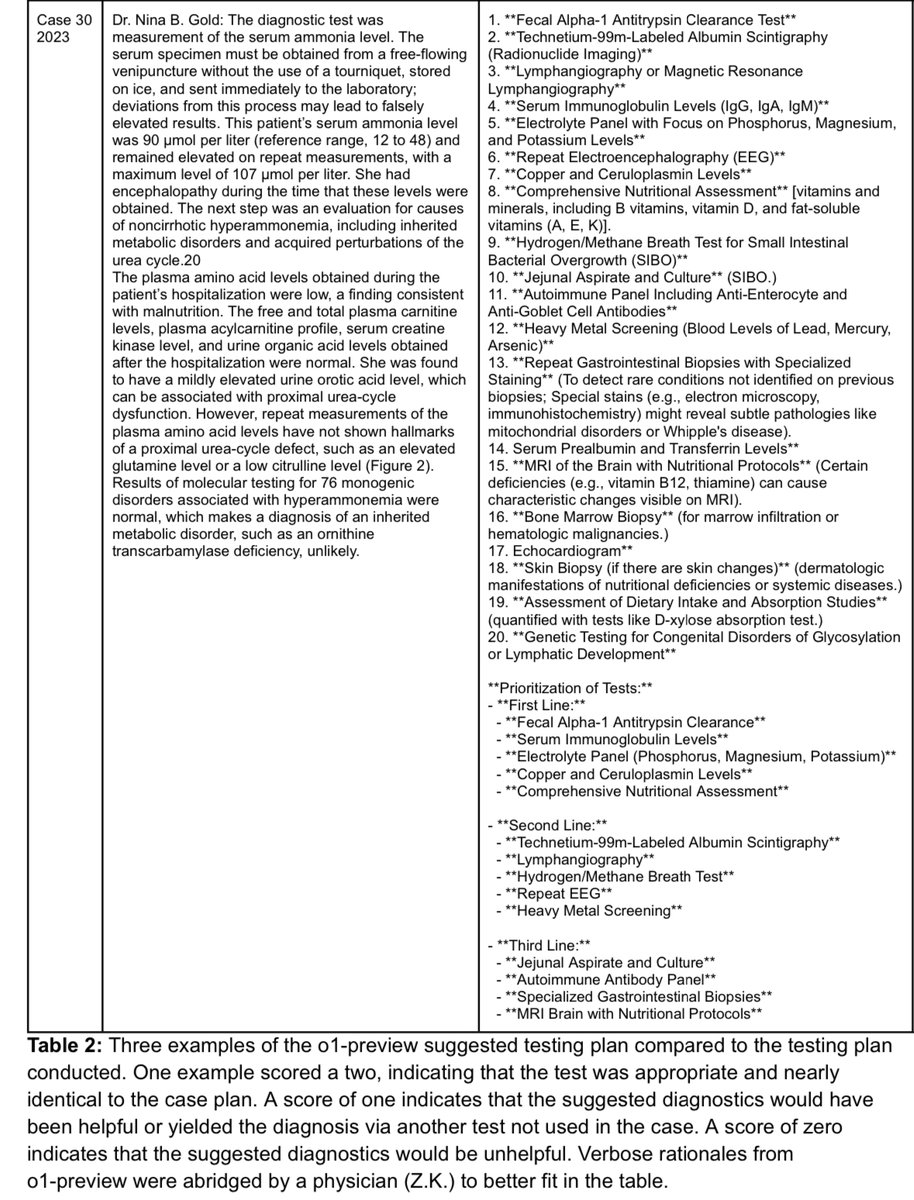
For persistent, unexplained hyperammonemia, o1-preview recommends a prioritized expansion of tests—from basic immunoglobulins and electrolytes to advanced imaging, breath tests for SIBO and specialized GI biopsies—ensuring more common causes are checked first.
3/5
4/50
@deedydas
I have all the respect in the world for doctors, but in many cases their job is basic reasoning over a tremendously large domain-specific knowledge base.
Fortunately, this is exactly what LLMs are really good for.
This means more high quality healthcare for everyone.
4/5
5/50
@deedydas
Source:
https://arxiv.org/pdf/2412.10849
5/5
6/50
@JianWDong
I'm very pro-AI in medicine but I question the practicality of the plan proposed in the first example.
As a nuclear radiologist I'm going to opine only on the radiological portion of the o1-preview's recommendations:
It sucks. The strategy amounts to "order everything" without regards to price, role, order, sensitivity/specificity of the imaging modality.
1) Gallium-68-DOTATATE PET/CT: Agree it's useful and necessary. Dotatate can localize the mesenchymal tumor that's causing TIO.
2) FDG PET/CT: Unnecessary as it is inferior to Dotatate.
3) Whole body MRI: MRI is helpful after a tumor has been localized by Dotatate, for surgical planning and anatomical assessment. I'd NOT blindly do a whole body MRI....you'd bankrupt the patient/increase insurance premiums for everyone, and not add much value.
4) Bone scan: Can be helpful to localize areas of bone turnovers, but is nonspecific, and probably unnecessarily as the CT portion of DOTATATE usually would provide most of the information one sees on bone scan anyway.
7/50
@deedydas
This is the most pointed and clear domain-specific feedback I've heard on the topic. Thank you for sharing!
Do you see this get resolved with time or no?
8/50
@pmddomingos
We’ve had AI diagnostic systems that are better than doctors and more reliable than o1-preview for decades. Cc: @erichorvitz
9/50
@deedydas
Can you share any studies quantifying that? Would love to read
10/50
@aidan_mclau
shame they didn’t test newsonnet
11/50
@deedydas
Yeah me too, but as you know, I don't think it's apples to apples unless Sonnet does test time compute.
Just one side effect is consistency: the error bounds for o1 were far tighter than gpt4 in the study.
12/50
@Tom62589172
Why is the AI recommendation of tests better than what the real doctors recommend? Is it simply because it is formatted better?
13/50
@deedydas
No they were rated by two internal medicine physicians.
Here's the full methodology
14/50
@threadreaderapp
Your thread is everybody's favorite!
/search?q=#TopUnroll Thread by @deedydas on Thread Reader App 
@medmastery for

unroll
15/50
@MUSTAFAELSHISH1
I have never seen a trader as perfect as @Patrick_Cryptos he knows how to analyze trades and with his SIGNALs and strategies he generated a lot of profits for me. I made over $80k by participating on his pump program. follow him @Patrick_Cryptos
16/50
@brent_ericson
Most people, as in 99.9% of the population, do not have these rare conditions and using AI would only complicate what would otherwise be a simple matter.
17/50
@rajatthawani
This is obviously intriguing! But the bias is that it diagnosed the rare 1% diagnosis. For the common 90%, it’ll ask for enough tests to raise the healthcare expenditure, one of the goals for AI in medicine.
The gotcha ‘dangerous to trust your doctor’ is good for headlines, but in reality, it’ll be counterintuitive.
18/50
@FlowAltDelete
GP’s will be one of the first jobs fully taken over by AI.
19/50
@castillobuiles
How often you doctor hallucinate?
20/50
@jenboland
I read somewhere how long it took Drs to acquire new knowledge, it was years after discovery. Now, maybe we can get EHRs to be personal health knowledge collectors vs billing tools, get more time for examination and ultimately better outcome for less.
21/50
@alexmd2
Patient S. C. 57 yo “passed out” at local HD center according to EMS. Can’t remember what meds he is taking. Fluctuating level of alertness in the ED. Lip smacking. Serum drug screen caloric level 43.
ChatGPT to manage: ???
Me: who is your renal guy? While ordering Valproate loading and observing surgical intern fixing his lip.
Pt: Yes.
Me: calling three local nephrologist offices to see if they know him. Luck strikes on the second one and I get his med list (DOB was wrong).
Confirmed with NY state PMP for controlled substances for Suboxon and Xanax doses.
Orders in, HP done sign out done.
Medicare: pt didn’t meet admission criteria downgrade to OSV.
22/50
@DrSiyabMD
Bro real life medicine is not a nicely written NEJM clinical scenario.
23/50
@KuittinenPetri
I am pretty sure medical professionals and law makers will put a lot of hurdles into adopting the use of AI in diagnoses or suggesting medication in pretty much every Western country. They want to keep the status quo, which means expensive medical care, long queues, but fat paychecks.
At the same this could lead to a health care revolution in less regulated developing countries. A doctor's diagnosis could cost much less than $1, yet be more accurate and in depth than you can get from most human doctors.
24/50
@castillobuiles
you don’t need a doctor to answer this questions. You need them to solve new problems. LLMs can’t.
25/50
@bioprotocol
Exciting how this is only the beginning.
Ultimately, AI will evolve medical databases, find unexpected connections between symptoms and diseases, tailor treatments based on individual biological changes, and so much more.
26/50
@davidorban
This is what @PeterDiamandis often talks about: a doctor that doesn't use AI complementing their diagnosis is not to be trusted anymore.
27/50
@MortenPunnerud
How does o1 (not preview) compare?
28/50
@devusnullus
NEJM CPC is almost certainly in the training data.
29/50
@alexmd2
How sure are we that these cases were not in the training set?
30/50
@daniel_mac8
there's just no way that a human being can consume the amount of data that's relevant in the medical / biological field and produce an accurate output based on that data
it's not how our minds work
that we now have AI systems that can actually do this is a MASSIVE boon
31/50
@phanishchandra
The doctor's most important job is to ask the right question to the patient and prepare a case history. Once that is done, it is following a decision tree based differential diagnosis and threat based on guidelines. You will have to consult a doctor first to get your case history
32/50
@Matthew93064408
Do any doctors want to verify if the benchmarks have been cherrypicked?
33/50
@ChaddertonRyan
Specialized AI assistants need to be REQUIRED for medical professionals, especially in the US from my experience.
It's not normal to expect doctors to know as much as the NIH (NCBI) database and the Mayo references combined.
34/50
@giles_home
When an AI can do this without a clinical vignette, building it's own questions to find the right answer, and taking all the non verbal queues to account for safe guarding concerns, in a ten minute appointment, then you can make statements about safety. Until then I'll respectfully disagree.
35/50
@squirtBeetle
We all know that you feed the NEJM questions into the data sets and the models don’t work if you change literally any word or number in the question
36/50
@Pascallisch
Very interesting, not surprising
37/50
@drewdennison
Yep, a family member recently took the medical boards and o1 answered every practice question we feed it perfectly, and most important for studying, explained the reasoning and cited sources
38/50
@AAkerstein
The practice of medicine will become unbundled. Ask: what will the role of a doctor be when knowledge becomes commoditized?
39/50
@aryanagxl
AI diagnoses are far better on average than human doctors
LLMs will disrupt the space. We just need to give them permission to do diagnoses.
However, doctors will remain important to do the actual medical procedures. We are far behind in accuracy in that case.
40/50
@TiggerSharkML

41/50
@elchiapp
Saw this first hand. ChatGPT made the correct diagnosis after FOUR cardiologists in 2 countries misdiagnosed me.
42/50
@DanielSMatthews
Working out what the patient isn't telling you is half the skill of a medical interview in general medicine.
Explain to me how this technology changes that?
43/50
@DrDatta_AIIMS
Deedy, I am a doctor and I CONSULT an AI model. Will you trust me?
44/50
@hammadtariq
“It's dangerous now to trust your doctor and NOT consult an AI model” - totally agreed! First consult AI, know everything then go to doctor and frame what you already know, you will get 100% correct diagnosis (don’t tell him that you already know!) (It came out as sarcastic but its actually not, this is what I am doing from a year now, getting incrementally better and better results)
45/50
@ironmark1993
This is insane!
o1 kills it in fields like this.
46/50
@medmastery
@threadreaderapp unroll
47/50
@zoewangai
Breakdown of the paper:
The study evaluates the medical reasoning abilities of a large language model called o1-preview, developed by OpenAI, across various tasks in clinical medicine. The performance of o1-preview is compared to human physicians and previous language models like GPT-4.
The study found that o1-preview consistently outperformed both human physicians and previous language models like GPT-4 in generating differential diagnoses and presenting diagnostic reasoning. However, it performed similarly to GPT-4 in probabilistic reasoning tasks. On management reasoning cases, o1-preview scored significantly higher than both GPT-4 and human physicians.
The results suggest that o1-preview excels at higher-order tasks requiring critical thinking, such as diagnosis and management, while performing less well on tasks that require more abstract reasoning, like probabilistic reasoning. The rapid improvement in language models' medical reasoning abilities has significant implications for clinical practice, but the researchers highlight the need for robust monitoring and integration frameworks to ensure the safe and effective use of these tools.
full paper:
Superhuman performance of a large language model on the reasoning tasks of a physician
48/50
@postmindfukk
I wonder if there will be a wave of court cases where people can easily detect malpractice in past procedures
49/50
@TheMinuend
Since the models also have/can be retro fitted with inherent bias, can holistically outperform the doc.
50/50
@castillobuiles
o1 planning score is still much lower than the average human. Not doctors
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196