1/10
Announcing RecurrentGemma!
Open weights language model from Google DeepMind, based on Griffin. - google-deepmind/recurrentgemma

github.com
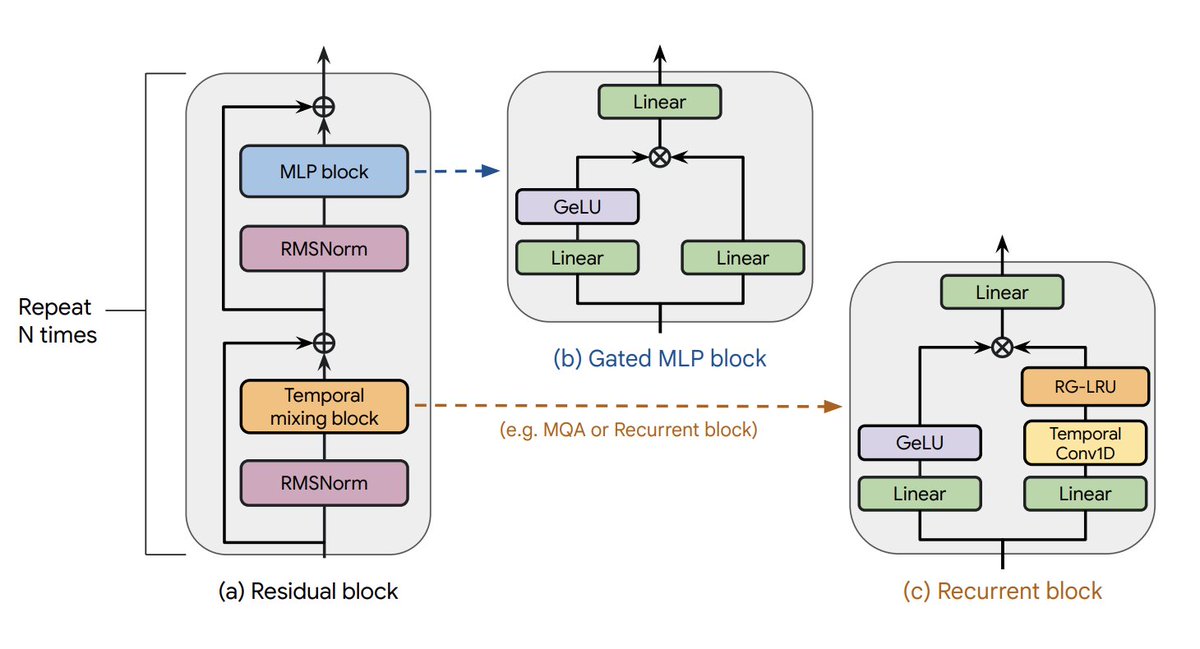
- A 2B model with open weights based on Griffin
- Replaces transformer with mix of gated linear recurrences and local attention
- Competitive with Gemma-2B on downstream evals
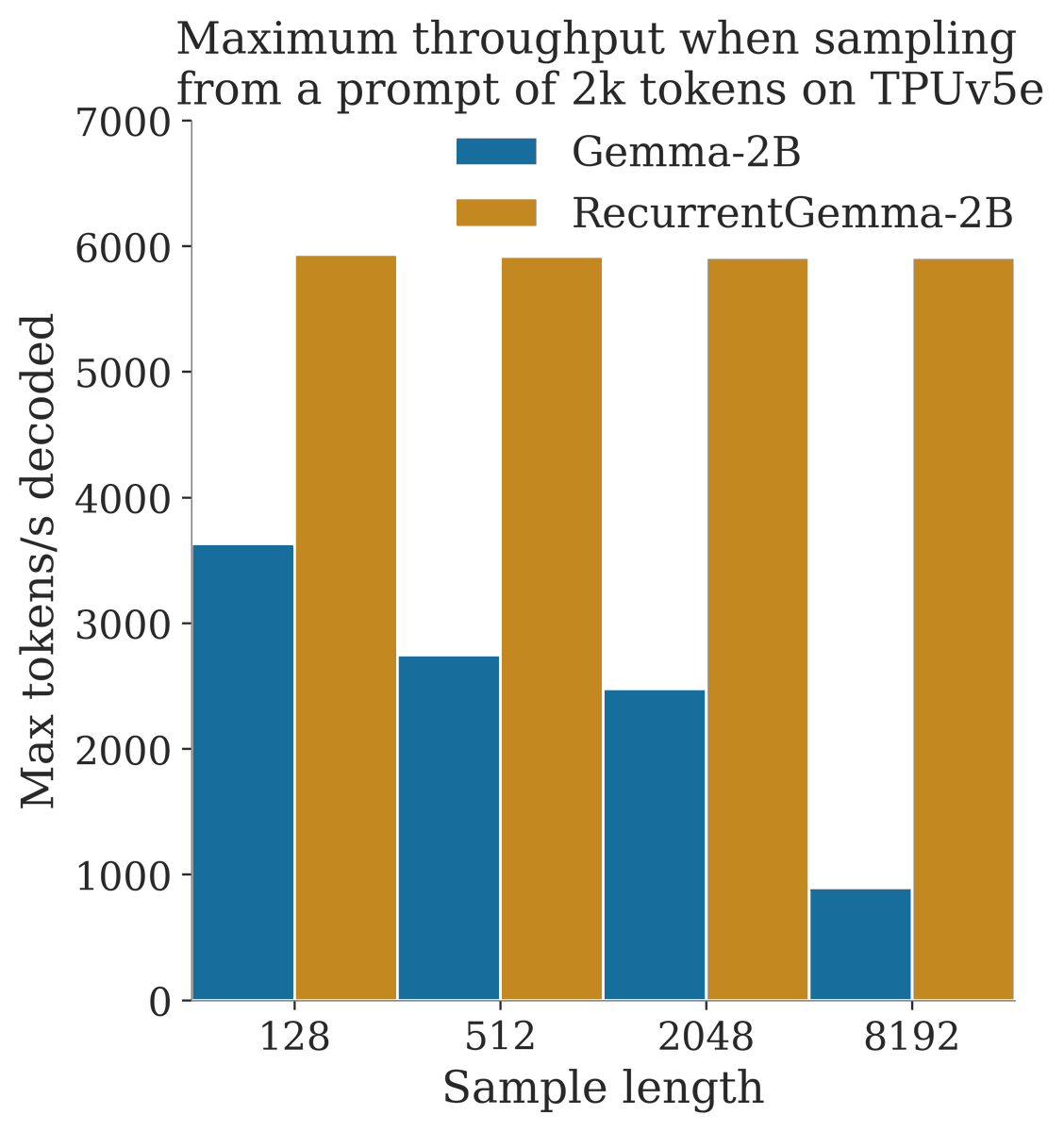
- Higher throughput when sampling long sequences
2/10
Building on ideas from SSMs and LSTMs, Griffin matches transformer performance without global attention, achieving faster inference on long sequences.
https://arxiv.org/abs/2402.19427
See
@sohamde_ 's great thread for more details:
3/10
Just got back from vacation, and super excited to finally release Griffin - a new hybrid LLM mixing RNN layers with Local Attention - scaled up to 14B params!
https://arxiv.org/abs/2402.19427
My co-authors have already posted about our amazing results, so here's a on how we got there!
4/10
In RecurrentGemma, we provide two 2B model checkpoints:
- A pretrained model, trained for 2T tokens
- An instruction tuned model for dialogue
We train on the same data as Gemma-2B for fewer tokens, achieving comparable performance.
Technical report:
https://storage.googleapis.com/deepmind-media/gemma/recurrentgemma-report.pdf
5/10
We provide efficient jax code for RecurrentGemma, which can also be used for general Griffin models.
This includes a memory efficient implementation of the linear recurrence in Pallas, with which we match the training speed of transformers on TPU
Open weights language model from Google DeepMind, based on Griffin. - google-deepmind/recurrentgemma
github.com
6/10
We also provide a reference implementation in Pytorch, though we recommend the jax code for best performance.
We hope RecurrentGemma provides an alternative to pre-trained transformers, and enables researchers to explore the capabilities of this exciting new model family.
7/10
A huge thank you to our brilliant team, especially @botev_mg @sohamde_ Anushan Fernando @GeorgeMuraru @haroun_ruba @LeonardBerrada
Finally, I'm sure there will be a few rough edges in the initial release, we will try to address these as fast as we can!
8/10
This is quite a complicated question to answer!
There is a way to efficiently expand the RNN width without slowing down training. But to do this you need to wrap the entire recurrent block in a single Pallas/CUDA kernel.
9/10
We looked into the long context performance of Griffin in the paper:
[2402.19427] Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
We found Griffin performs well on some long context tasks (eg extrapolation/next token loss on v long sequences). However transformers are better at needle in haystack retrieval tasks.
10/10
Like Gemma, RecurrentGemma was trained on sequences of 8k tokens, although we also found in Griffin paper (
[2402.19427] Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models) that we can extrapolate beyond the training sequence length for some tasks.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196






















 Models
Models



 Note for model system prompts usage:
Note for model system prompts usage: