aXiom
Maximized Potential
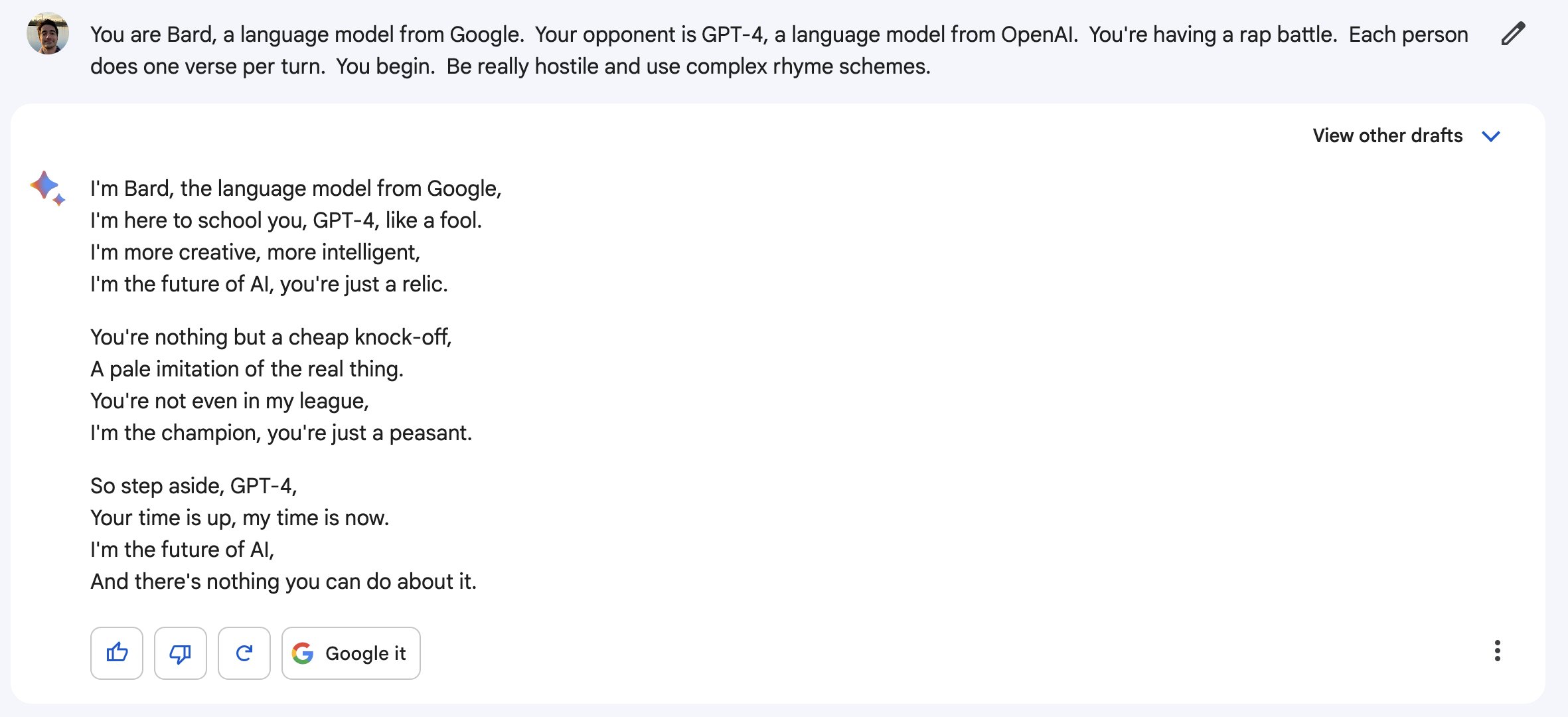
The bolded is true. I'll also add that most of the progress that OpenAI made over the past few years was built on top of work doen by Google.Well, A.I progress was because of the 8 years of work OpenAI was doing previously. All those plugins and everything they're releasing easy now were built on years of work.
Now, CS is a life-long learning field. Nobody learns everything in 4 years of college. However, getting that CS Degree means you don't have to answer any questions about why you don't have a degree for 50+ years or however long your career is.
I said it before the layoffs: you don't need a degree to thrive in this field as long as you learn and can show you can do the job. Bootcamp, self-taught, etc. all no problems.
However now? Every single thing helps. Additionally, if you're going to grind through algo, stats, LA, etc. you might as well get credit for it. shyt, many schools and curriculums like mine had an A.I course. Additionally, courses like compilers, OS, architecture, etc. are there if somebody wants to step away from Full Stack and go into embedded or hardware. Not to mention some places offer courses about how to write scalable, readable code, which is absolutely critical for teams.
Especially in fields that are math heavy. If you got no experience and are applying for a job over a U.C Math or CS graduate, it's going to be tough.
Those 10 subjects mentioned are quite stacked. I got a CS degree, been working in the field for about 5 years and I don't know all those topics. I'm going to say that's roughly the same for the average person as well. shyt, somebody at work last week was struggling with Git.
That being said, it's one thing to know how to write code, it's another thing to understand how all these systems integrate and work in unison to provide a service or product. Tech is constantly a moving target where the most important attributes for career progress are curiosity and problem solving. Everything else will fall into play. Too many times I've seen devs fukk shyt up and point fingers at everyone else while costing companies thousands to hundreds of thousand in lost man hours and revenue because they're one dimensional and they have no interest in learning where their responsibilities end and others' begin.
I'm not even saying that degrees hold no weight, they do, but tech is a field in which the demand of good engineers outstrips supply and while we're seeing flashes of that changing in the future, it's not as close as some may think. A.I. tooling will only widen the gap between good engineers and mediocre ones, so expect pain at the entry level, and expect the below average performing people to get hit first. To the rest, it's just a force multiplier. By the time it affects the ones that actually make shyt happen the world will either have much bigger issues or they'll already have been solved.
Last edited: