
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?
Alibaba's 'Animate Anyone' Is Trained on Scraped Videos of Famous TikTokers
The new image-to-video model went viral this week because people saw potential to replace TikTok personalities, but ripping content creators' work is already baked into the tech.
 www.404media.co
www.404media.co
Alibaba's 'Animate Anyone' Is Trained on Scraped Videos of Famous TikTokers
·DEC 5, 2023 AT 1:09 PM
The new image-to-video model went viral this week because people saw potential to replace TikTok personalities, but ripping content creators' work is already baked into the tech.

SCREENSHOT VIA YOUTUBE
Become a paid subscriber for unlimited, ad-free articles and access to bonus content. This site is funded by subscribers and you will be directly powering our journalism.
Become a paid subscriber for unlimited, ad-free articles and access to bonus content. This site is funded by subscribers and you will be directly powering our journalism.
A team of researchers from Chinese retail and technology giant Alibaba released a paper this week detailing a new model, which they call “Animate Anyone.” The reaction online to this, generally, has been “RIP TikTokers,” the suggested implication being that dancing TikTok content creators will soon be replaced by AI.
The model takes an input (in their examples, TikTok dance videos) and creates a new version as the output. The results are slightly better than previous attempts at similar models. Mostly, in the published examples, they take an existing dance sequence and replicate it slightly worse, with different clothing or styles. But as all AI advancements go, it’ll keep improving.
People have already pointed out that “Animate Anyone” will probably be used to abusive ends, generating non-consensual videos of people in fabricated situations, which has been the primary use of deepfakes since the technology’s inception six years ago.
But it’s not a far-away prediction: these researchers are already using people’s work without their consent, as a practice baked into training and building the model. The Alibaba paper is the commercialization of “the TikTok dataset,” which was originally created for academic purposes by researchers at the University of Minnesota. 404 Media’s quick look at the dataset shows that Alibaba’s new AI is trained on a model that scraped videos of some of the most famous TikTok creators, including Charli D’Amelio, Addison Rae, Ashley Nocera, Stina Kayy, and dozens of others. The TikTok dataset also contains people who have TikTok accounts that don’t have much of a following at all.

REFERENCE IMAGES, THE DRIVING POST, AN EXAMPLE FROM THE DISCO MODEL, AND ALIBABA'S OUTPUT. FROM THE ANIMATE ANYONE PAPER
Prominent TikTok creators are featured on the Animate Anyone paper’s website as examples of the model working, where videos of popular TikTok personalities are used as the reference image, then deep-fried by the Alibaba model to grind out a worse, AI-generated replica.
This paper and the “Animate Anyone” model wouldn’t be possible without stealing from creators. The researchers use three popular online personalities and artists—Jasmine Chiswell, Mackenzie Ziegler, and Anna Šulcová—as examples in training their model on the project page.
Chiswell is a lifestyle YouTuber and TikTok personality with almost 17 million followers on TikTok. Ziegler, a singer and actress who’s known for being on Dance Moms as a child, has 23.5 million TikTok followers. Šulcová, a YouTube content creator, has 889,600 TikTok followers.
Each of these women make their living with their independent creative work, which the Alibaba team helped themselves to for its paper. There are more TikTok creators shown in the paper, published on preprint server arXiv.
The Alibaba researchers write in their paper that they use “the TikTok dataset, comprising 340 training and 100 testing single human dancing videos (10-15 seconds long).” This dataset originated with a 2021 University of Minnesota project, “Learning High Fidelity Depths of Dressed Humans by Watching Social Media Dance Videos,” which outlined a technique for “human depth estimation and human shape recovery approaches,” like putting a new outfit on someone in a video using AI.
“We manually find more than 300 dance videos that capture a single person performing dance moves from TikTok dance challenge compilations for each month, variety, type of dances, which are moderate movements that do not generate excessive motion blur,” the University of Minnesota researchers wrote. “For each video, we extract RGB images at 30 frame per second, resulting in more than 100K images.”
Most AI datasets are made up of videos, images, and text scraped from the open web, including social networks like TikTok, without the consent of the people who own that content. In this case, a dataset compiled and launched by doctoral students is being used by one of the biggest technology and retail giants in the world.
This pathway, where a giant dataset is created for the purposes of academic research then eventually becomes commercialized by large companies for similar or wholly different purposes is a common one. A researcher team at the University of North Carolina, Wilmington scraped videos uploaded by trans people to YouTube into a database that was used to create technology aimed at detecting trans people using facial recognition, for example.
AI researchers like those at Alibaba are using scraped datasets full of user-generated content in the middle of an increasingly-hostile legal environment where artists and other content creators are suing AI companies for using their works without permission. A class action lawsuit representing artists brought against Midjourney, DeviantArt, and Stability AI just added more plaintiffs and filed an amended complaint after a judge dismissed some of their claims in October. The artists claim that these AI image generators copy plaintiffs’ work, and that the generators “create substantially similar substitutes for the very works they were trained on—either specific training images, or images that imitate the trade dress of particular artists—including plaintiffs,” according to the complaint.
Last month, a federal judge overturned a decision from last year that dismissed choreographer Kyle Hanagami’s lawsuit against Epic Games. Hanagami claimed Fortnite used his dance moves as “emotes.”
“Reducing choreography to ‘poses’ would be akin to reducing music to just ‘notes.’ Choreography is, by definition, a related series of dance movements and patterns organized into a coherent whole,” the judge wrote. “The relationship between those movements and patterns, and the choreographer’s creative approach of composing and arranging them together, is what defines the work. The element of ‘poses,’ on its own, is simply not dynamic enough to capture the full range of creative expression of a choreographic work.”
Hanagami’s lawyer told Billboard that the decision to overturn the previous ruling to dismiss could be “extremely impactful for the rights of choreographers, and other creatives, in the age of short form digital media.” All of this has major implications for whatever Alibaba is trying to make with “Animate Anyone,” and academics should consider future ramifications when creating huge datasets of real people’s content.
GAIA: Zero-shot Talking Avatar Generation
Zero-shot talking avatar generation aims at synthesizing natural talking videos from speech and a single portrait image. Previous methods have relied on domain-specific heuristics such as warping-based motion representation and 3D Morphable Models, which limit the naturalness and diversity of...
Computer Science > Computer Vision and Pattern Recognition
[Submitted on 26 Nov 2023]GAIA: Zero-shot Talking Avatar Generation
Tianyu He, Junliang Guo, Runyi Yu, Yuchi Wang, Jialiang Zhu, Kaikai An, Leyi Li, Xu Tan, Chunyu Wang, Han Hu, HsiangTao Wu, Sheng Zhao, Jiang BianZero-shot talking avatar generation aims at synthesizing natural talking videos from speech and a single portrait image. Previous methods have relied on domain-specific heuristics such as warping-based motion representation and 3D Morphable Models, which limit the naturalness and diversity of the generated avatars. In this work, we introduce GAIA (Generative AI for Avatar), which eliminates the domain priors in talking avatar generation. In light of the observation that the speech only drives the motion of the avatar while the appearance of the avatar and the background typically remain the same throughout the entire video, we divide our approach into two stages: 1) disentangling each frame into motion and appearance representations; 2) generating motion sequences conditioned on the speech and reference portrait image. We collect a large-scale high-quality talking avatar dataset and train the model on it with different scales (up to 2B parameters). Experimental results verify the superiority, scalability, and flexibility of GAIA as 1) the resulting model beats previous baseline models in terms of naturalness, diversity, lip-sync quality, and visual quality; 2) the framework is scalable since larger models yield better results; 3) it is general and enables different applications like controllable talking avatar generation and text-instructed avatar generation.
| Comments: | Project page: this https URL |
| Subjects: | Computer Vision and Pattern Recognition (cs.CV); Multimedia (cs.MM) |
| Cite as: | arXiv:2311.15230 [cs.CV] |
| (or arXiv:2311.15230v1 [cs.CV] for this version) | |
| [2311.15230] GAIA: Zero-shot Talking Avatar Generation Focus to learn more |
Submission history
From: Tianyu He [view email][v1] Sun, 26 Nov 2023 08:04:43 UTC (13,346 KB)
GAIA
 microsoft.github.io
microsoft.github.io
MagicAnimate:
Temporally Consistent Human Image Animation using Diffusion Model
Zhongcong Xu1, Jianfeng Zhang2, Jun Hao Liew2, Hanshu Yan2, Jia-Wei Liu1, Chenxu Zhang2, Jiashi Feng2, Mike Zheng Shou1Show Lab, National University of Singapore 2Bytedance
Paper arXiv Code
TL;DR: We propose MagicAnimate, a diffusion-based human image animation framework that aims at enhancing temporal consistency, preserving reference image faithfully, and improving animation fidelity.
GitHub - magic-research/magic-animate: [CVPR 2024] Official repository for "MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model"
[CVPR 2024] Official repository for "MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model" - magic-research/magic-animate
 github.com
github.com
About
MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Modelshowlab.github.io/magicanimate/
edit:
Full Auto Installers and Instructions For Windows Including Raw Video To DensePose Video via Best detectron2 DensePose Model #44
Full Auto Installers and Instructions For Windows Including Raw Video To DensePose Video via Best detectron2 DensePose Model · Issue #44 · magic-research/magic-animate
I have spent over 24 hours to prepare all these scripts You can download all from here : https://www.patreon.com/posts/94098751 Example 15 second DensePose I generated via my script 15_sec_512_clos...
github.com
Last edited:
I'm going to pretend I know what all this means and assume its a good thing
MagicAnimate:
Temporally Consistent Human Image Animation using Diffusion Model
Zhongcong Xu1, Jianfeng Zhang2, Jun Hao Liew2, Hanshu Yan2, Jia-Wei Liu1, Chenxu Zhang2, Jiashi Feng2, Mike Zheng Shou1
Show Lab, National University of Singapore 2Bytedance
Paper arXiv Code
TL;DR: We propose MagicAnimate, a diffusion-based human image animation framework that aims at enhancing temporal consistency, preserving reference image faithfully, and improving animation fidelity.

GitHub - magic-research/magic-animate: [CVPR 2024] Official repository for "MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model"
[CVPR 2024] Official repository for "MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model" - magic-research/magic-animate
About
MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model
showlab.github.io/magicanimate/
I'm going to pretend I know what all this means and assume its a good thing
Pipeline
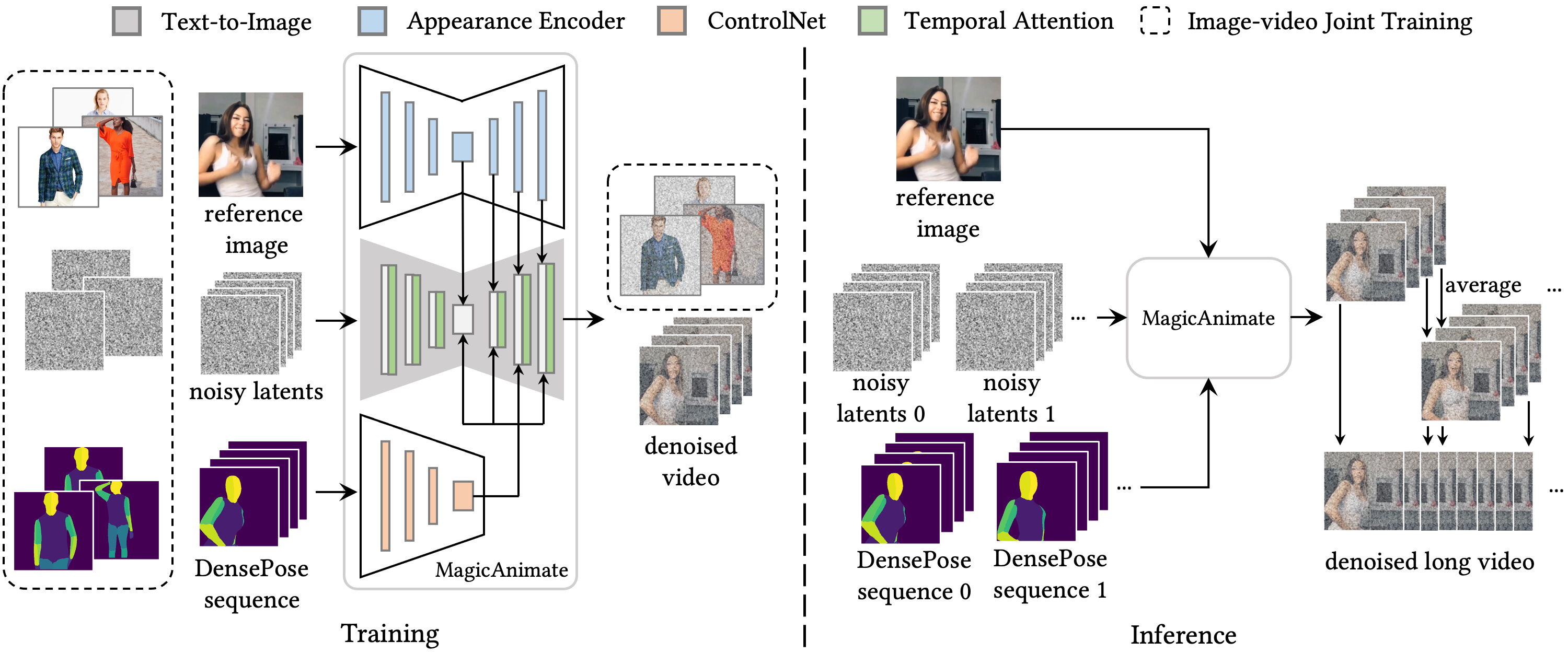
Given a reference image and the target DensePose motion sequence, MagicAnimate employs a video diffusion model and an appearance encoder for temporal modeling and identity preserving, respectively (left panel). To support long video animation, we devise a simple video fusion strategy that produces smooth video transition during inference (right panel).AI explanation:
Sure, let’s simplify that:
MagicAnimate is a tool that lets you animate a still image to make it look like it’s moving, like in a video. It uses a reference image (a still picture) and a target DensePose motion sequence (a series of movements you want the image to make).
To make sure the animation looks like the original image and moves smoothly over time, MagicAnimate uses two main parts:
- A video diffusion model: This helps to create the illusion of movement over time.
- An appearance encoder: This makes sure the animated image keeps looking like the original image.

RunwayML and Getty Images work on custom video AI models without copyright issues
AI video platform RunwayML is partnering with Getty Images to develop copyright-compliant AI tools for video creation.
 the-decoder.com
the-decoder.com
AI in practice
Dec 4, 2023
RunwayML and Getty Images work on custom video AI models without copyright issues
RunwayML
Matthias Bastian
Online journalist Matthias is the co-founder and publisher of THE DECODER. He believes that artificial intelligence will fundamentally change the relationship between humans and computers.
AI video platform RunwayML is partnering with Getty Images to develop copyright-compliant AI tools for video creation.
The collaboration will result in the Runway <> Getty Images Model (RGM), which combines Runway's technology with Getty Images' fully licensed library of creative content.
The goal of the partnership is to give creatives more control and personalization while making it suitable for commercial use.
The Runway <> Getty Images Model (RGM)
RGM is designed as a base model from which companies can build their own customized video content generation models. Runway's enterprise customers can add their own data sets to their version of RGM.This will enable companies from a wide range of industries, including Hollywood studios, advertising, media, and broadcast, to expand their creative capabilities and create new ways of producing video, the companies say.
According to the companies, RGM enables entirely new content workflows with generated videos that are tailored to a company's style and brand identity. At the same time, it eliminates potential copyright issues.
Grant Farhall, chief product officer at Getty Images, said his company is excited to work with Runway to promote the responsible use of generative AI in enterprise applications.
Getty Images is currently suing Stability AI, the company behind the open-source image platform Stable Diffusion. Getty Images images have allegedly been used to train AI models without a license. Stability AI claims fair use. Getty Images also offers its own image AI model trained on its licensed data.
Availability and model training
RGM is expected to be available for commercial use in the coming months. Custom model training with RGM is particularly relevant for companies with proprietarySummary
- AI video platform RunwayML and Getty Images are collaborating to develop copyright-compliant AI tools for video creation by combining Runway technology with licensed content from Getty Images.
- The Runway <> Getty Images Model (RGM) allows companies to build custom video content creation models from a base model and refine them with their own data sets without risking copyright issues.
- RGM will be available for commercial use in the coming months. RunwayML currently has a waiting list.
LightGaussian: Unbounded 3D Gaussian Compression with 15x Reduction and 200+ FPS
Project page: lightgaussian.github.io/
Code: github.com/VITA-Group/LightGaussian
Recent advancements in real-time neural rendering using point-based techniques have paved the way for the widespread adoption of 3D representations. However, foundational approaches like 3D Gaussian Splatting come with a substantial storage overhead caused by growing the SfM points to millions, often demanding gigabyte-level disk space for a single unbounded scene, posing significant scalability challenges and hindering the splatting efficiency.
To address this challenge, we introduce LightGaussian, a novel method designed to transform 3D Gaussians into a more efficient and compact format. Drawing inspiration from the concept of Network Pruning, LightGaussian identifies Gaussians that are insignificant in contributing to the scene reconstruction and adopts a pruning and recovery process, effectively reducing redundancy in Gaussian counts while preserving visual effects. Additionally, LightGaussian employs distillation and pseudo-view augmentation to distill spherical harmonics to a lower degree, allowing knowledge transfer to more compact representations while maintaining scene appearance. Furthermore, we propose a hybrid scheme, VecTree Quantization, to quantize all attributes, resulting in lower bitwidth representations with minimal accuracy losses.
In summary, LightGaussian achieves an averaged compression rate over 15× while boosting the FPS from 139 to 215, enabling an efficient representation of complex scenes on Mip-NeRF 360, Tank & Temple datasets.
LightGaussian: Unbounded 3D Gaussian Compression with 15x Reduction and 200+ FPS
LightGaussian efficiently compresses 3D scene data, enhancing performance and reducing storage needs while preserving visual quality.
lightgaussian.github.io
GitHub - VITA-Group/LightGaussian: [NeurIPS 2024 Spotlight]"LightGaussian: Unbounded 3D Gaussian Compression with 15x Reduction and 200+ FPS", Zhiwen Fan, Kevin Wang, Kairun Wen, Zehao Zhu, Dejia Xu, Zhangyang Wang
[NeurIPS 2024 Spotlight]"LightGaussian: Unbounded 3D Gaussian Compression with 15x Reduction and 200+ FPS", Zhiwen Fan, Kevin Wang, Kairun Wen, Zehao Zhu, Dejia Xu, Zhangyang Wang - VITA-...
github.com
AI explanation:
Sure, let's break it down:
New techniques using points (like dots) to create 3D images in real time are becoming more popular. But, one of the main methods, called 3D Gaussian Splatting, needs a lot of storage space because it uses millions of these points. This can take up gigabytes of space for just one scene, which makes it hard to scale and slows down the process.
To solve this, a new method called LightGaussian has been introduced. It's inspired by Network Pruning, which is a way to remove parts of a network that aren't really needed. LightGaussian does something similar by identifying and removing points that don't contribute much to the final image, reducing the number of points needed without affecting the visual quality.
LightGaussian also uses techniques called distillation and pseudo-view augmentation to simplify the points even further, while still keeping the scene looking the same. Plus, it introduces a new way to represent all the attributes of the points, called VecTree Quantization, which results in smaller representations with minimal loss in accuracy.
In short, LightGaussian can compress the data by more than 15 times and increase the frames per second from 139 to 215. This makes it possible to efficiently represent complex scenes on certain datasets.
Last edited:
ReconFusion: 3D Reconstruction with Diffusion Priors
3D reconstruction methods such as Neural Radiance Fields (NeRFs) excel at rendering photorealistic novel views of complex scenes. However, recovering a high-quality NeRF typically requires tens to hundreds of input images, resulting in a time-consuming capture process. We present ReconFusion to...
reconfusion.github.io
ReconFusion: 3D Reconstruction with Diffusion Priors
- Rundi Wu 1*
- Ben Mildenhall 2*
- Philipp Henzler 2
- Keunhong Park 2
- Ruiqi Gao 3
- Daniel Watson 3
- Pratul P. Srinivasan 2
- Dor Verbin 2
- Jonathan T. Barron 2
- Ben Poole 3
- Aleksander Holynski 2*
1Columbia University, 2Google Research, 3Google DeepMind
* equal contribution
ReconFusion: 3D Reconstruction with Diffusion Priors
3D reconstruction methods such as Neural Radiance Fields (NeRFs) excel at rendering photorealistic novel views of complex scenes. However, recovering a high-quality NeRF typically requires tens to hundreds of input images, resulting in a time-consuming capture process. We present ReconFusion to...
Abstract
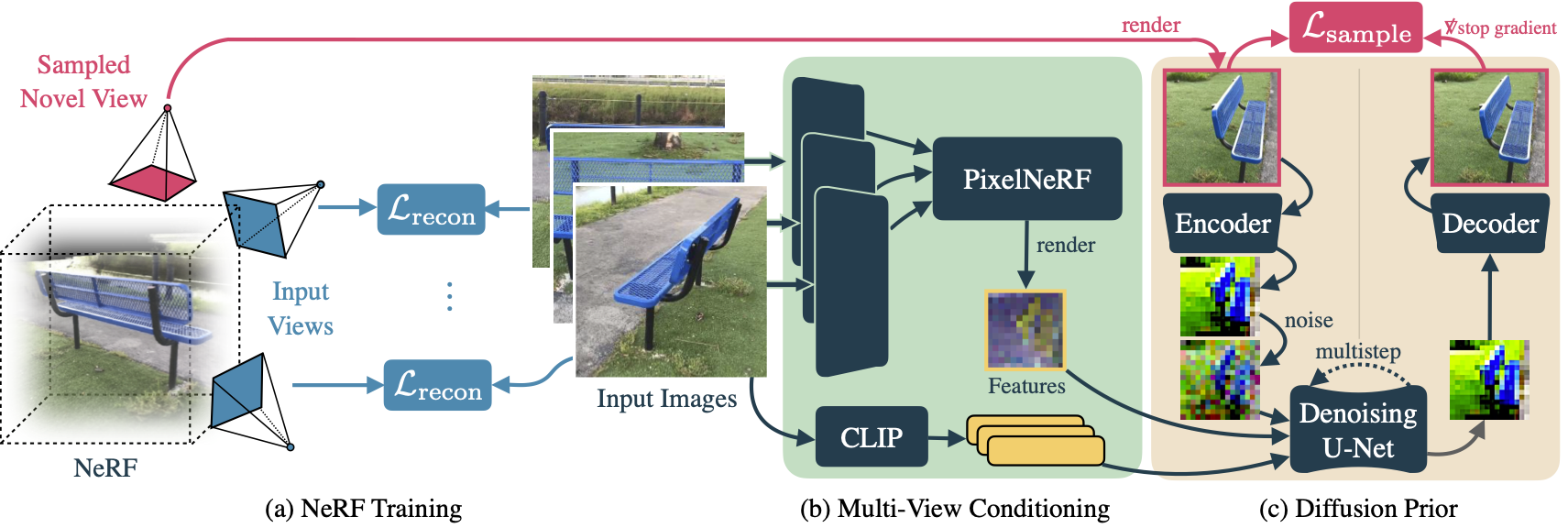
3D reconstruction methods such as Neural Radiance Fields (NeRFs) excel at rendering photorealistic novel views of complex scenes. However, recovering a high-quality NeRF typically requires tens to hundreds of input images, resulting in a time-consuming capture process. We present ReconFusion to reconstruct real-world scenes using only a few photos. Our approach leverages a diffusion prior for novel view synthesis, trained on synthetic and multiview datasets, which regularizes a NeRF-based 3D reconstruction pipeline at novel camera poses beyond those captured by the set of input images. Our method synthesizes realistic geometry and texture in underconstrained regions while preserving the appearance of observed regions. We perform an extensive evaluation across various real-world datasets, including forward-facing and 360-degree scenes, demonstrating significant performance improvements over previous few-view NeRF reconstruction approaches.ReconFusion = 3D Reconstruction + Diffusion Prior
(a) We optimize a NeRF to minimize a reconstruction loss LreconLrecon between renderings and a few input images, as well as a sample loss LsampleLsample between a rendering from a random pose and an image predicted by a diffusion model for that pose. (b) To generate the sample image, we use a PixelNeRF-style model to fuse information from the input images and to render a predicted feature map corresponding to the sample view camera pose. (c) This feature map is concatenated with the noisy latent (computed from the current NeRF rendering at that pose) and is provided to a diffusion model, which additionally uses CLIP embeddings of the input images via cross-attention. The resulting decoded output sample is used to enforce an image-space loss on the corresponding NeRF rendering (LsampleLsample).
Computer Science > Computer Vision and Pattern Recognition
[Submitted on 5 Dec 2023]ReconFusion: 3D Reconstruction with Diffusion Priors
Rundi Wu, Ben Mildenhall, Philipp Henzler, Keunhong Park, Ruiqi Gao, Daniel Watson, Pratul P. Srinivasan, Dor Verbin, Jonathan T. Barron, Ben Poole, Aleksander Holynski3D reconstruction methods such as Neural Radiance Fields (NeRFs) excel at rendering photorealistic novel views of complex scenes. However, recovering a high-quality NeRF typically requires tens to hundreds of input images, resulting in a time-consuming capture process. We present ReconFusion to reconstruct real-world scenes using only a few photos. Our approach leverages a diffusion prior for novel view synthesis, trained on synthetic and multiview datasets, which regularizes a NeRF-based 3D reconstruction pipeline at novel camera poses beyond those captured by the set of input images. Our method synthesizes realistic geometry and texture in underconstrained regions while preserving the appearance of observed regions. We perform an extensive evaluation across various real-world datasets, including forward-facing and 360-degree scenes, demonstrating significant performance improvements over previous few-view NeRF reconstruction approaches.
| Comments: | Project page: this https URL |
| Subjects: | Computer Vision and Pattern Recognition (cs.CV) |
| Cite as: | arXiv:2312.02981 [cs.CV] |
| (or arXiv:2312.02981v1 [cs.CV] for this version) | |
| [2312.02981] ReconFusion: 3D Reconstruction with Diffusion Priors Focus to learn more |
Submission history
From: Ben Mildenhall [view email][v1] Tue, 5 Dec 2023 18:59:58 UTC (49,325 KB)
AI explanation:
Sure, let's break it down:
ReconFusion is a method that creates 3D models of real-world scenes using just a few photos. It's like creating a mini virtual reality from a handful of pictures.
Usually, to create such 3D models (also known as Neural Radiance Fields or NeRFs), you need tens to hundreds of photos, which can be time-consuming. But ReconFusion makes this process quicker and easier.
How does it do this? It uses something called a diffusion prior. This is a kind of guide or rule that helps the system figure out how to fill in the gaps when there are not enough photos. It's trained on synthetic and multiview datasets, which helps it to make educated guesses about what the missing parts of the scene might look like.
The result is a 3D model that looks realistic, even in areas where there weren't enough photos to provide detailed information. It maintains the appearance of the observed regions while filling in the underconstrained regions with plausible geometry and texture.
The process involves optimizing a NeRF to minimize the difference between the 3D model and the input images, as well as the difference between a rendering from a random pose and an image predicted by a diffusion model for that pose.
In simpler terms, it's like having a sketch artist who only needs a few photos to draw a detailed and accurate 3D sketch of a scene, filling in the missing details based on their training and experience. The artist keeps refining the sketch until it matches the photos as closely as possible.
This method has been tested on various real-world datasets and has shown significant improvements over previous methods. So, it's a big step forward in the field of 3D reconstruction.
RIP OpenAI
Last edited:
Introducing Gemini: our largest and most capable AI model
Dec 06, 2023
11 min read
Making AI more helpful for everyone
Sundar Pichai
CEO of Google and Alphabet
Demis Hassabis
CEO and Co-Founder, Google DeepMind

In this story
- Note from Sundar
- Introducing Gemini
- State-of-the-art performance
- Next-generation capabilities
- Scalable and efficient
- Responsibility and safety
- Availability
A note from Google and Alphabet CEO Sundar Pichai:
Every technology shift is an opportunity to advance scientific discovery, accelerate human progress, and improve lives. I believe the transition we are seeing right now with AI will be the most profound in our lifetimes, far bigger than the shift to mobile or to the web before it. AI has the potential to create opportunities — from the everyday to the extraordinary — for people everywhere. It will bring new waves of innovation and economic progress and drive knowledge, learning, creativity and productivity on a scale we haven’t seen before.
That’s what excites me: the chance to make AI helpful for everyone, everywhere in the world.
Nearly eight years into our journey as an AI-first company, the pace of progress is only accelerating: Millions of people are now using generative AI across our products to do things they couldn’t even a year ago, from finding answers to more complex questions to using new tools to collaborate and create. At the same time, developers are using our models and infrastructure to build new generative AI applications, and startups and enterprises around the world are growing with our AI tools.
This is incredible momentum, and yet, we’re only beginning to scratch the surface of what’s possible.
We’re approaching this work boldly and responsibly. That means being ambitious in our research and pursuing the capabilities that will bring enormous benefits to people and society, while building in safeguards and working collaboratively with governments and experts to address risks as AI becomes more capable. And we continue to invest in the very best tools, foundation models and infrastructure and bring them to our products and to others, guided by our AI Principles.
Now, we’re taking the next step on our journey with Gemini, our most capable and general model yet, with state-of-the-art performance across many leading benchmarks. Our first version, Gemini 1.0, is optimized for different sizes: Ultra, Pro and Nano. These are the first models of the Gemini era and the first realization of the vision we had when we formed Google DeepMind earlier this year. This new era of models represents one of the biggest science and engineering efforts we’ve undertaken as a company. I’m genuinely excited for what’s ahead, and for the opportunities Gemini will unlock for people everywhere.
– Sundar
Introducing Gemini
By Demis Hassabis, CEO and Co-Founder of Google DeepMind, on behalf of the Gemini teamAI has been the focus of my life's work, as for many of my research colleagues. Ever since programming AI for computer games as a teenager, and throughout my years as a neuroscience researcher trying to understand the workings of the brain, I’ve always believed that if we could build smarter machines, we could harness them to benefit humanity in incredible ways.
This promise of a world responsibly empowered by AI continues to drive our work at Google DeepMind. For a long time, we’ve wanted to build a new generation of AI models, inspired by the way people understand and interact with the world. AI that feels less like a smart piece of software and more like something useful and intuitive — an expert helper or assistant.
Today, we’re a step closer to this vision as we introduce Gemini, the most capable and general model we’ve ever built.
Gemini is the result of large-scale collaborative efforts by teams across Google, including our colleagues at Google Research. It was built from the ground up to be multimodal, which means it can generalize and seamlessly understand, operate across and combine different types of information including text, code, audio, image and video.
4:35
Introducing Gemini: our largest and most capable AI model
Gemini is also our most flexible model yet — able to efficiently run on everything from data centers to mobile devices. Its state-of-the-art capabilities will significantly enhance the way developers and enterprise customers build and scale with AI.
We’ve optimized Gemini 1.0, our first version, for three different sizes:
- Gemini Ultra — our largest and most capable model for highly complex tasks.
- Gemini Pro — our best model for scaling across a wide range of tasks.
- Gemini Nano — our most efficient model for on-device tasks.
State-of-the-art performance
We've been rigorously testing our Gemini models and evaluating their performance on a wide variety of tasks. From natural image, audio and video understanding to mathematical reasoning, Gemini Ultra’s performance exceeds current state-of-the-art results on 30 of the 32 widely-used academic benchmarks used in large language model (LLM) research and development.With a score of 90.0%, Gemini Ultra is the first model to outperform human experts on MMLU (massive multitask language understanding), which uses a combination of 57 subjects such as math, physics, history, law, medicine and ethics for testing both world knowledge and problem-solving abilities.
Our new benchmark approach to MMLU enables Gemini to use its reasoning capabilities to think more carefully before answering difficult questions, leading to significant improvements over just using its first impression.
.")
Gemini surpasses state-of-the-art performance on a range of benchmarks including text and coding.
Gemini Ultra also achieves a state-of-the-art score of 59.4% on the new MMMU benchmark, which consists of multimodal tasks spanning different domains requiring deliberate reasoning.
With the image benchmarks we tested, Gemini Ultra outperformed previous state-of-the-art models, without assistance from object character recognition (OCR) systems that extract text from images for further processing. These benchmarks highlight Gemini’s native multimodality and indicate early signs of Gemini's more complex reasoning abilities.
See more details in our Gemini technical report.

Gemini surpasses state-of-the-art performance on a range of multimodal benchmarks.
Next-generation capabilities
Until now, the standard approach to creating multimodal models involved training separate components for different modalities and then stitching them together to roughly mimic some of this functionality. These models can sometimes be good at performing certain tasks, like describing images, but struggle with more conceptual and complex reasoning.We designed Gemini to be natively multimodal, pre-trained from the start on different modalities. Then we fine-tuned it with additional multimodal data to further refine its effectiveness. This helps Gemini seamlessly understand and reason about all kinds of inputs from the ground up, far better than existing multimodal models — and its capabilities are stateof the art in nearly every domain.
Learn more about Gemini’s capabilities and see how it works.
Sophisticated reasoning
Gemini 1.0’s sophisticated multimodal reasoning capabilities can help make sense of complex written and visual information. This makes it uniquely skilled at uncovering knowledge that can be difficult to discern amid vast amounts of data.Its remarkable ability to extract insights from hundreds of thousands of documents through reading, filtering and understanding information will help deliver new breakthroughs at digital speeds in many fields from science to finance.
2:43
Gemini unlocks new scientific insights
Understanding text, images, audio and more
Gemini 1.0 was trained to recognize and understand text, images, audio and more at the same time, so it better understands nuanced information and can answer questions relating to complicated topics. This makes it especially good at explaining reasoning in complex subjects like math and physics.1:59
Gemini explains reasoning in math and physics
Advanced coding
Our first version of Gemini can understand, explain and generate high-quality code in the world’s most popular programming languages, like Python, Java, C++, and Go. Its ability to work across languages and reason about complex information makes it one of the leading foundation models for coding in the world.Gemini Ultra excels in several coding benchmarks, including HumanEval, an important industry-standard for evaluating performance on coding tasks, and Natural2Code, our internal held-out dataset, which uses author-generated sources instead of web-based information.
Gemini can also be used as the engine for more advanced coding systems. Two years ago we presented AlphaCode, the first AI code generation system to reach a competitive level of performance in programming competitions.
Using a specialized version of Gemini, we created a more advanced code generation system, AlphaCode 2, which excels at solving competitive programming problems that go beyond coding to involve complex math and theoretical computer science.
5:01
Gemini excels at coding and competitive programming
When evaluated on the same platform as the original AlphaCode, AlphaCode 2 shows massive improvements, solving nearly twice as many problems, and we estimate that it performs better than 85% of competition participants — up from nearly 50% for AlphaCode. When programmers collaborate with AlphaCode 2 by defining certain properties for the code samples to follow, it performs even better.
We’re excited for programmers to increasingly use highly capable AI models as collaborative tools that can help them reason about the problems, propose code designs and assist with implementation — so they can release apps and design better services, faster.
See more details in our AlphaCode 2 technical report.
More reliable, scalable and efficient
We trained Gemini 1.0 at scale on our AI-optimized infrastructure using Google’s in-house designed Tensor Processing Units (TPUs) v4 and v5e. And we designed it to be our most reliable and scalable model to train, and our most efficient to serve.On TPUs, Gemini runs significantly faster than earlier, smaller and less-capable models. These custom-designed AI accelerators have been at the heart of Google's AI-powered products that serve billions of users like Search, YouTube, Gmail, Google Maps, Google Play and Android. They’ve also enabled companies around the world to train large-scale AI models cost-efficiently.
Today, we’re announcing the most powerful, efficient and scalable TPU system to date, Cloud TPU v5p, designed for training cutting-edge AI models. This next generation TPU will accelerate Gemini’s development and help developers and enterprise customers train large-scale generative AI models faster, allowing new products and capabilities to reach customers sooner.

A row of Cloud TPU v5p AI accelerator supercomputers in a Google data center.
Built with responsibility and safety at the core
At Google, we’re committed to advancing bold and responsible AI in everything we do. Building upon Google’s AI Principles and the robust safety policies across our products, we’re adding new protections to account for Gemini’s multimodal capabilities. At each stage of development, we’re considering potential risks and working to test and mitigate them.Gemini has the most comprehensive safety evaluations of any Google AI model to date, including for bias and toxicity. We’ve conducted novel research into potential risk areas like cyber-offense, persuasion and autonomy, and have applied Google Research’s best-in-class adversarial testing techniques to help identify critical safety issues in advance of Gemini’s deployment.
To identify blindspots in our internal evaluation approach, we’re working with a diverse group of external experts and partners to stress-test our models across a range of issues.
To diagnose content safety issues during Gemini’s training phases and ensure its output follows our policies, we’re using benchmarks such as Real Toxicity Prompts, a set of 100,000 prompts with varying degrees of toxicity pulled from the web, developed by experts at the Allen Institute for AI. Further details on this work are coming soon.
To limit harm, we built dedicated safety classifiers to identify, label and sort out content involving violence or negative stereotypes, for example. Combined with robust filters, this layered approach is designed to make Gemini safer and more inclusive for everyone. Additionally, we’re continuing to address known challenges for models such as factuality, grounding, attribution and corroboration.
Responsibility and safety will always be central to the development and deployment of our models. This is a long-term commitment that requires building collaboratively, so we’re partnering with the industry and broader ecosystem on defining best practices and setting safety and security benchmarks through organizations like MLCommons, the Frontier Model Forum and its AI Safety Fund, and our Secure AI Framework (SAIF), which was designed to help mitigate security risks specific to AI systems across the public and private sectors. We’ll continue partnering with researchers, governments and civil society groups around the world as we develop Gemini.
Making Gemini available to the world
Gemini 1.0 is now rolling out across a range of products and platforms:Gemini Pro in Google products
We’re bringing Gemini to billions of people through Google products.Starting today, Bard will use a fine-tuned version of Gemini Pro for more advanced reasoning, planning, understanding and more. This is the biggest upgrade to Bard since it launched.
It will be available in English in more than 170 countries and territories, and we plan to expand to different modalities and support new languages and locations in the near future.
We’re also bringing Gemini to Pixel. Pixel 8 Pro is the first smartphone engineered to run Gemini Nano, which is powering new features like Summarize in the Recorder app and rolling out in Smart Reply in Gboard, starting with WhatsApp — with more messaging apps coming next year.
In the coming months, Gemini will be available in more of our products and services like Search, Ads, Chrome and Duet AI.
We’re already starting to experiment with Gemini in Search, where it's making our Search Generative Experience (SGE) faster for users, with a 40% reduction in latency in English in the U.S., alongside improvements in quality.
Building with Gemini
Starting on December 13, developers and enterprise customers can access Gemini Pro via the Gemini API in Google AI Studio or Google Cloud Vertex AI.Google AI Studio is a free, web-based developer tool to prototype and launch apps quickly with an API key. When it's time for a fully-managed AI platform, Vertex AI allows customization of Gemini with full data control and benefits from additional Google Cloud features for enterprise security, safety, privacy and data governance and compliance.
Android developers will also be able to build with Gemini Nano, our most efficient model for on-device tasks, via AICore, a new system capability available in Android 14, starting on Pixel 8 Pro devices. Sign up for an early preview of AICore.
Gemini Ultra coming soon
For Gemini Ultra, we’re currently completing extensive trust and safety checks, including red-teaming by trusted external parties, and further refining the model using fine-tuning and reinforcement learning from human feedback (RLHF) before making it broadly available.As part of this process, we’ll make Gemini Ultra available to select customers, developers, partners and safety and responsibility experts for early experimentation and feedback before rolling it out to developers and enterprise customers early next year.
Early next year, we’ll also launch Bard Advanced, a new, cutting-edge AI experience that gives you access to our best models and capabilities, starting with Gemini Ultra.
The Gemini era: enabling a future of innovation
This is a significant milestone in the development of AI, and the start of a new era for us at Google as we continue to rapidly innovate and responsibly advance the capabilities of our models.We’ve made great progress on Gemini so far and we’re working hard to further extend its capabilities for future versions, including advances in planning and memory, and increasing the context window for processing even more information to give better responses.
We’re excited by the amazing possibilities of a world responsibly empowered by AI — a future of innovation that will enhance creativity, extend knowledge, advance science and transform the way billions of people live and work around the world.